 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMT: Federated Learning with Mixed-type Labels
Oct 05, 2022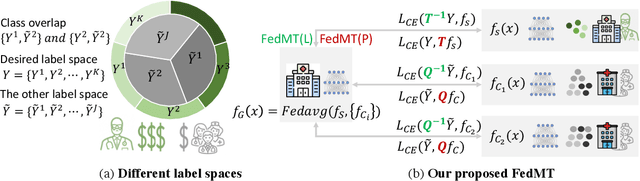
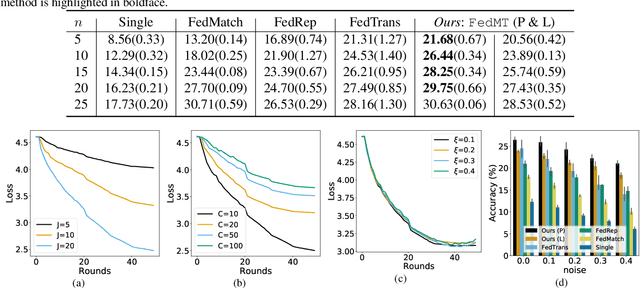
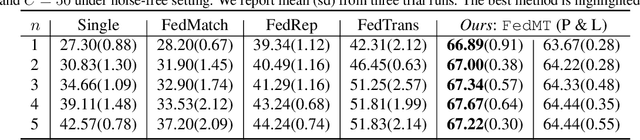

In federated learning (FL), classifiers (e.g., deep networks) are trained on datasets from multiple centers without exchanging data across them, and thus improves sample efficiency. In the classical setting of FL, the same labeling criterion is usually employed across all centers being involved in training. This constraint greatly limits the applicability of FL. For example, standards used for disease diagnosis are more likely to be different across clinical centers, which mismatches the classical FL setting. In this paper, we consider an important yet under-explored setting of FL, namely FL with mixed-type labels where different labeling criteria can be employed by various centers, leading to inter-center label space differences and challenging existing FL methods designed for the classical setting. To effectively and efficiently train models with mixed-type labels, we propose a theory-guided and model-agnostic approach that can make use of the underlying correspondence between those label spaces and can be easily combined with various FL methods such as FedAvg. We present convergence analysis based on over-parameterized ReLU networks. We show that the proposed method can achieve linear convergence in label projection, and demonstrate the impact of the parameters of our new setting on the convergence rate. The proposed method is evaluated and the theoretical findings are validated on benchmark and medical datasets.
Reinforced Structured State-Evolution for Vision-Language Navigation
Apr 20, 2022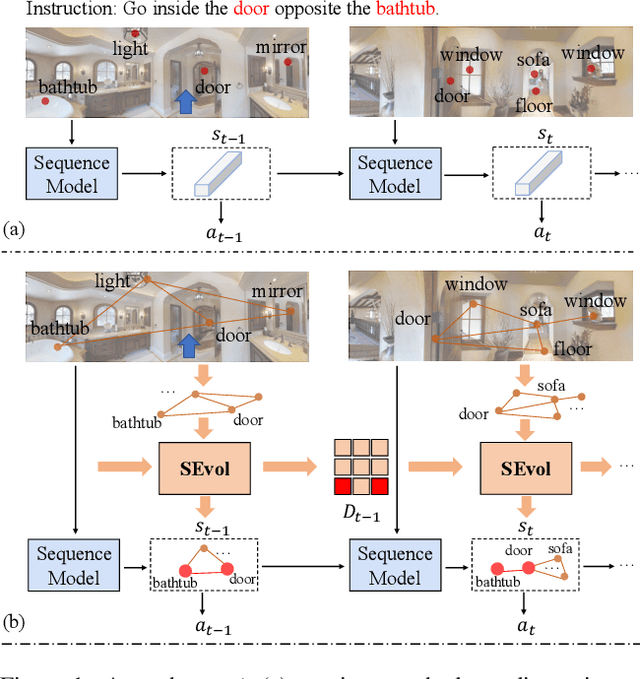
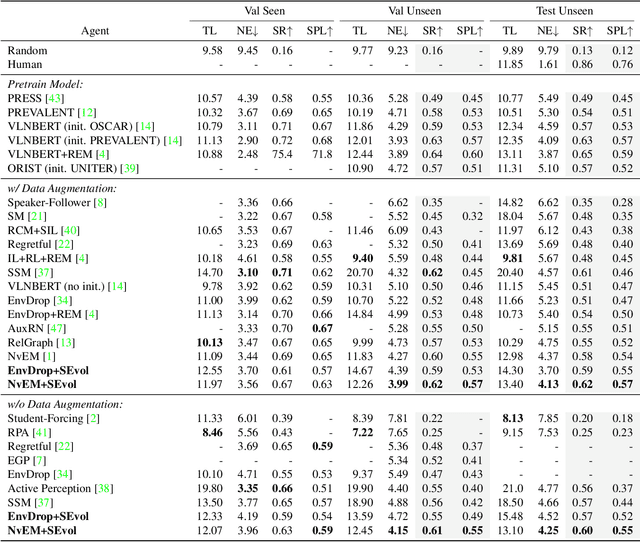
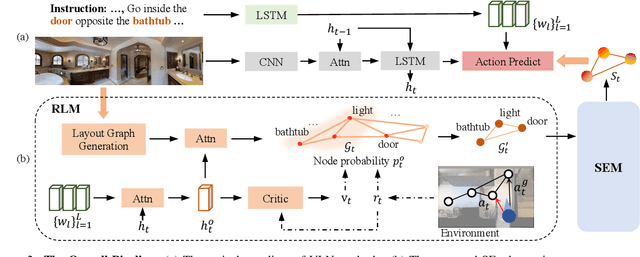
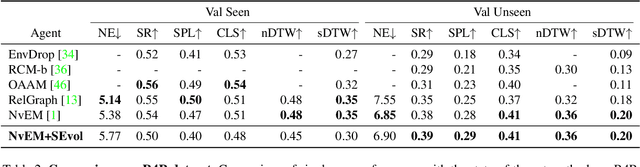
Vision-and-language Navigation (VLN) task requires an embodied agent to navigate to a remote location following a natural language instruction. Previous methods usually adopt a sequence model (e.g., Transformer and LSTM) as the navigator. In such a paradigm, the sequence model predicts action at each step through a maintained navigation state, which is generally represented as a one-dimensional vector. However, the crucial navigation clues (i.e., object-level environment layout) for embodied navigation task is discarded since the maintained vector is essentially unstructured. In this paper, we propose a novel Structured state-Evolution (SEvol) model to effectively maintain the environment layout clues for VLN. Specifically, we utilise the graph-based feature to represent the navigation state instead of the vector-based state. Accordingly, we devise a Reinforced Layout clues Miner (RLM) to mine and detect the most crucial layout graph for long-term navigation via a customised reinforcement learning strategy. Moreover, the Structured Evolving Module (SEM) is proposed to maintain the structured graph-based state during navigation, where the state is gradually evolved to learn the object-level spatial-temporal relationship. The experiments on the R2R and R4R datasets show that the proposed SEvol model improves VLN models' performance by large margins, e.g., +3% absolute SPL accuracy for NvEM and +8% for EnvDrop on the R2R test set.
Boosting the Generalization Capability in Cross-Domain Few-shot Learning via Noise-enhanced Supervised Autoencoder
Aug 11, 2021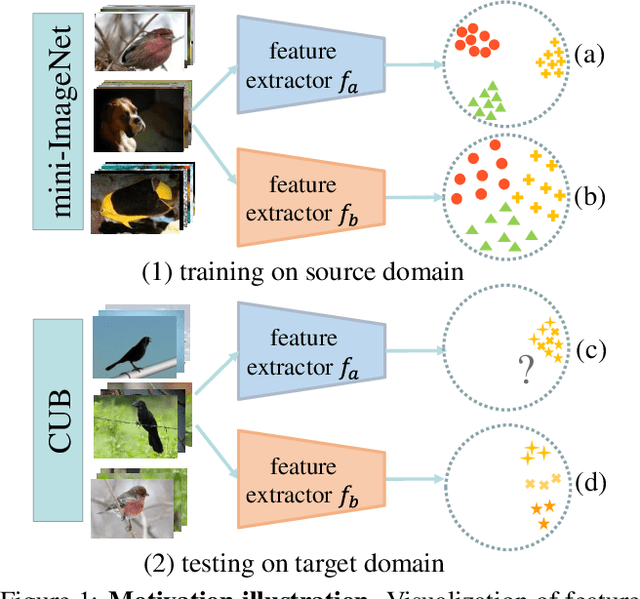
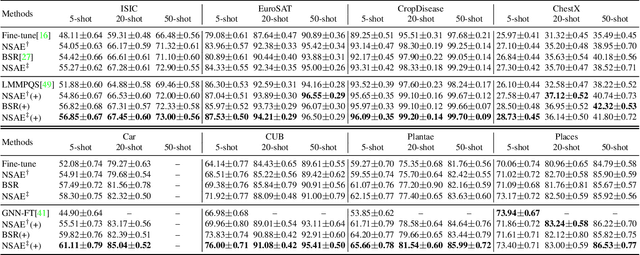
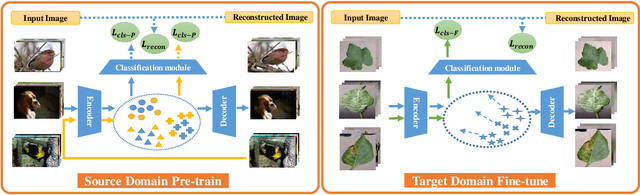
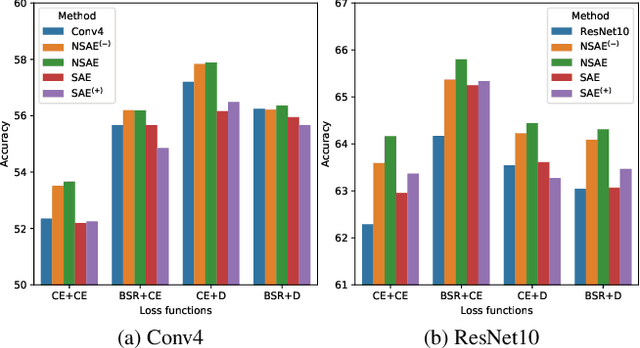
State of the art (SOTA) few-shot learning (FSL) methods suffer significant performance drop in the presence of domain differences between source and target datasets. The strong discrimination ability on the source dataset does not necessarily translate to high classification accuracy on the target dataset. In this work, we address this cross-domain few-shot learning (CDFSL) problem by boosting the generalization capability of the model. Specifically, we teach the model to capture broader variations of the feature distributions with a novel noise-enhanced supervised autoencoder (NSAE). NSAE trains the model by jointly reconstructing inputs and predicting the labels of inputs as well as their reconstructed pairs. Theoretical analysis based on intra-class correlation (ICC) shows that the feature embeddings learned from NSAE have stronger discrimination and generalization abilities in the target domain. We also take advantage of NSAE structure and propose a two-step fine-tuning procedure that achieves better adaption and improves classification performance in the target domain. Extensive experiments and ablation studies are conducted to demonstrate the effectiveness of the proposed method. Experimental results show that our proposed method consistently outperforms SOTA methods under various conditions.
Minimum Wasserstein Distance Estimator under Finite Location-scale Mixtures
Jul 03, 2021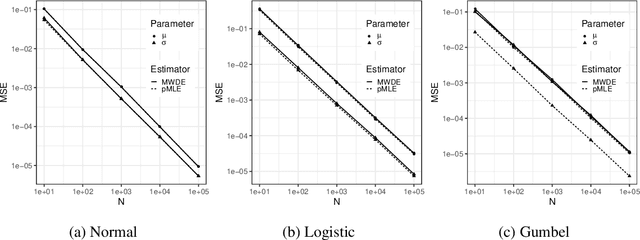
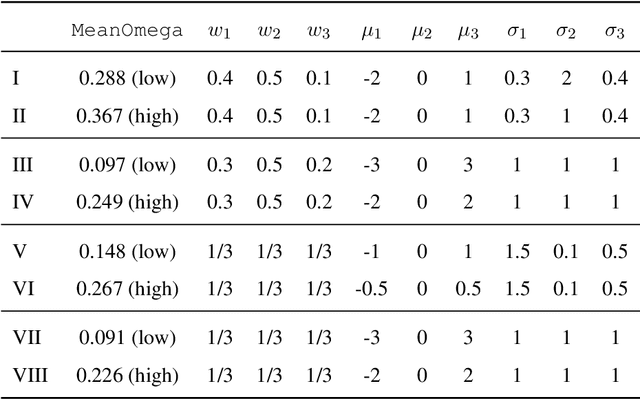
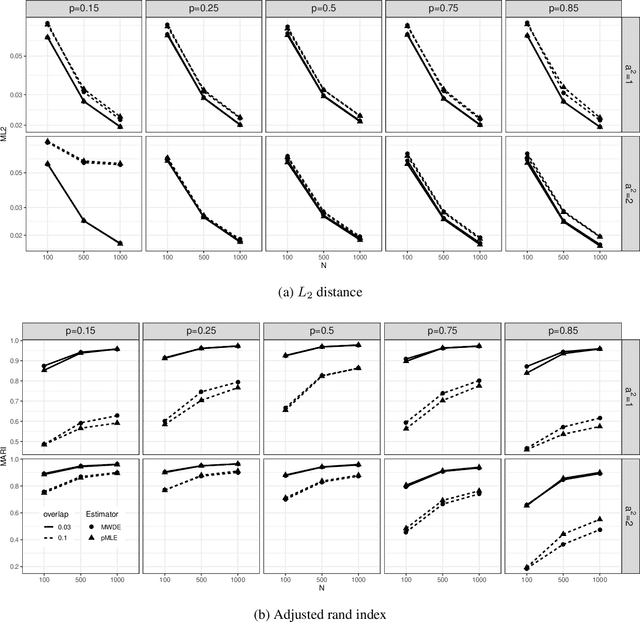
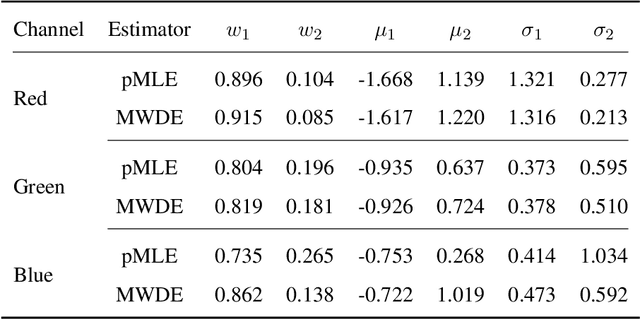
When a population exhibits heterogeneity, we often model it via a finite mixture: decompose it into several different but homogeneous subpopulations. Contemporary practice favors learning the mixtures by maximizing the likelihood for statistical efficiency and the convenient EM-algorithm for numerical computation. Yet the maximum likelihood estimate (MLE) is not well defined for the most widely used finite normal mixture in particular and for finite location-scale mixture in general. We hence investigate feasible alternatives to MLE such as minimum distance estimators. Recently, the Wasserstein distance has drawn increased attention in the machine learning community. It has intuitive geometric interpretation and is successfully employed in many new applications. Do we gain anything by learning finite location-scale mixtures via a minimum Wasserstein distance estimator (MWDE)? This paper investigates this possibility in several respects. We find that the MWDE is consistent and derive a numerical solution under finite location-scale mixtures. We study its robustness against outliers and mild model mis-specifications. Our moderate scaled simulation study shows the MWDE suffers some efficiency loss against a penalized version of MLE in general without noticeable gain in robustness. We reaffirm the general superiority of the likelihood based learning strategies even for the non-regular finite location-scale mixtures.
Classification Beats Regression: Counting of Cells from Greyscale Microscopic Images based on Annotation-free Training Samples
Oct 29, 2020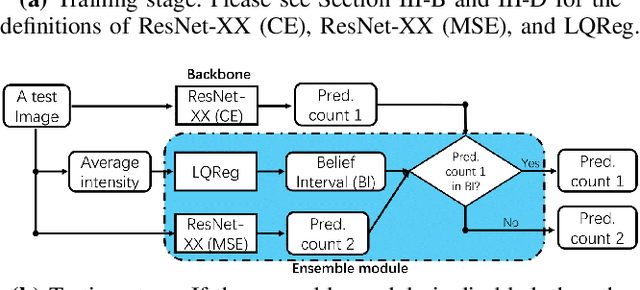

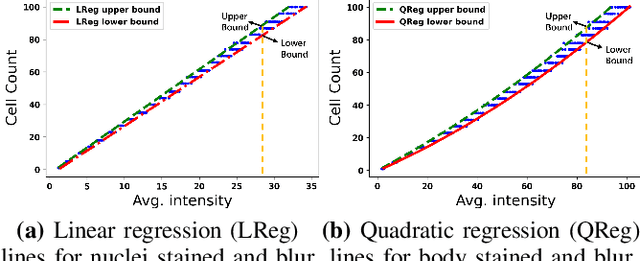

Modern methods often formulate the counting of cells from microscopic images as a regression problem and more or less rely on expensive, manually annotated training images (e.g., dot annotations indicating the centroids of cells or segmentation masks identifying the contours of cells). This work proposes a supervised learning framework based on classification-oriented convolutional neural networks (CNNs) to count cells from greyscale microscopic images without using annotated training images. In this framework, we formulate the cell counting task as an image classification problem, where the cell counts are taken as class labels. This formulation has its limitation when some cell counts in the test stage do not appear in the training data. Moreover, the ordinal relation among cell counts is not utilized. To deal with these limitations, we propose a simple but effective data augmentation (DA) method to synthesize images for the unseen cell counts. We also introduce an ensemble method, which can not only moderate the influence of unseen cell counts but also utilize the ordinal information to improve the prediction accuracy. This framework outperforms many modern cell counting methods and won the data analysis competition (Case Study 1: Counting Cells From Microscopic Images https://ssc.ca/en/case-study/case-study-1-counting-cells-microscopic-images) of the 47th Annual Meeting of the Statistical Society of Canada (SSC). Our code is available at https://github.com/anno2020/CellCount_TinyBBBC005.
Distributed Learning of Finite Gaussian Mixtures
Oct 20, 2020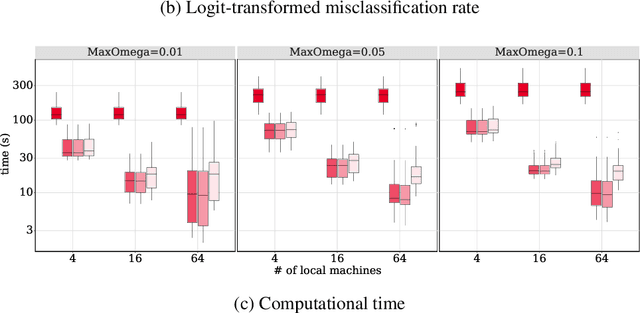

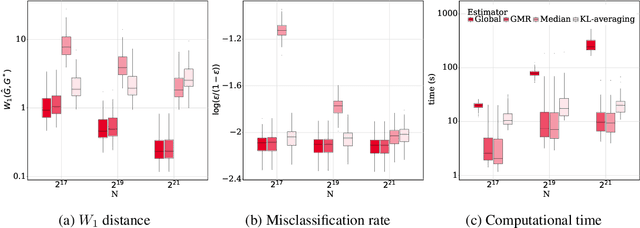
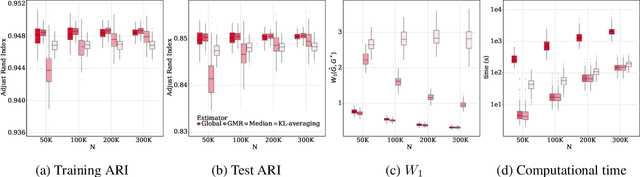
Advances in information technology have led to extremely large datasets that are often kept in different storage centers. Existing statistical methods must be adapted to overcome the resulting computational obstacles while retaining statistical validity and efficiency. Split-and-conquer approaches have been applied in many areas, including quantile processes, regression analysis, principal eigenspaces, and exponential families. We study split-and-conquer approaches for the distributed learning of finite Gaussian mixtures. We recommend a reduction strategy and develop an effective MM algorithm. The new estimator is shown to be consistent and retains root-n consistency under some general conditions. Experiments based on simulated and real-world data show that the proposed split-and-conquer approach has comparable statistical performance with the global estimator based on the full dataset, if the latter is feasible. It can even slightly outperform the global estimator if the model assumption does not match the real-world data. It also has better statistical and computational performance than some existing methods.
SemEval-2020 Task 5: Counterfactual Recognition
Aug 02, 2020
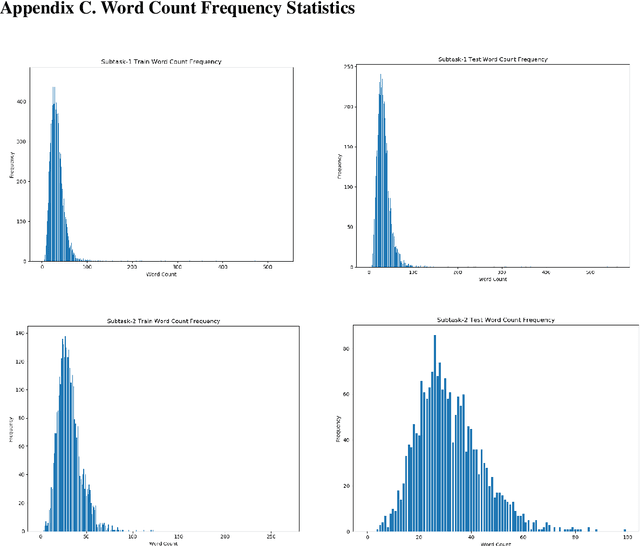

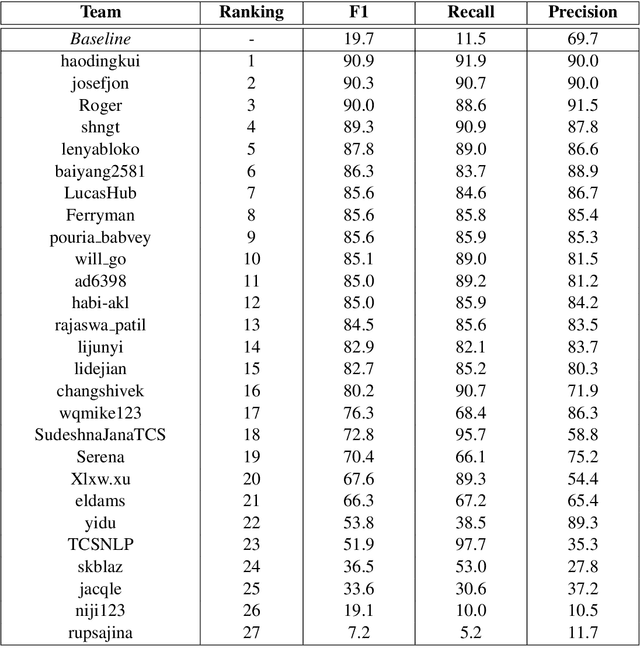
We present a counterfactual recognition (CR) task, the shared Task 5 of SemEval-2020. Counterfactuals describe potential outcomes (consequents) produced by actions or circumstances that did not happen or cannot happen and are counter to the facts (antecedent). Counterfactual thinking is an important characteristic of the human cognitive system; it connects antecedents and consequents with causal relations. Our task provides a benchmark for counterfactual recognition in natural language with two subtasks. Subtask-1 aims to determine whether a given sentence is a counterfactual statement or not. Subtask-2 requires the participating systems to extract the antecedent and consequent in a given counterfactual statement. During the SemEval-2020 official evaluation period, we received 27 submissions to Subtask-1 and 11 to Subtask-2. The data, baseline code, and leaderboard can be found at https://competitions.codalab.org/competitions/21691. The data and baseline code are also available at https://zenodo.org/record/3932442.
Robust Layout-aware IE for Visually Rich Documents with Pre-trained Language Models
May 22, 2020
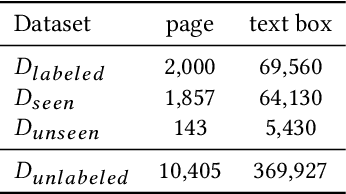
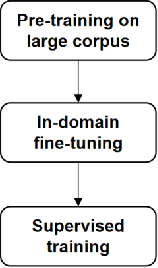
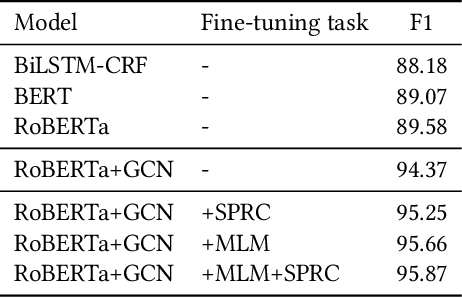
Many business documents processed in modern NLP and IR pipelines are visually rich: in addition to text, their semantics can also be captured by visual traits such as layout, format, and fonts. We study the problem of information extraction from visually rich documents (VRDs) and present a model that combines the power of large pre-trained language models and graph neural networks to efficiently encode both textual and visual information in business documents. We further introduce new fine-tuning objectives to improve in-domain unsupervised fine-tuning to better utilize large amount of unlabeled in-domain data. We experiment on real world invoice and resume data sets and show that the proposed method outperforms strong text-based RoBERTa baselines by 6.3% absolute F1 on invoices and 4.7% absolute F1 on resumes. When evaluated in a few-shot setting, our method requires up to 30x less annotation data than the baseline to achieve the same level of performance at ~90% F1.
Masking Orchestration: Multi-task Pretraining for Multi-role Dialogue Representation Learning
Feb 27, 2020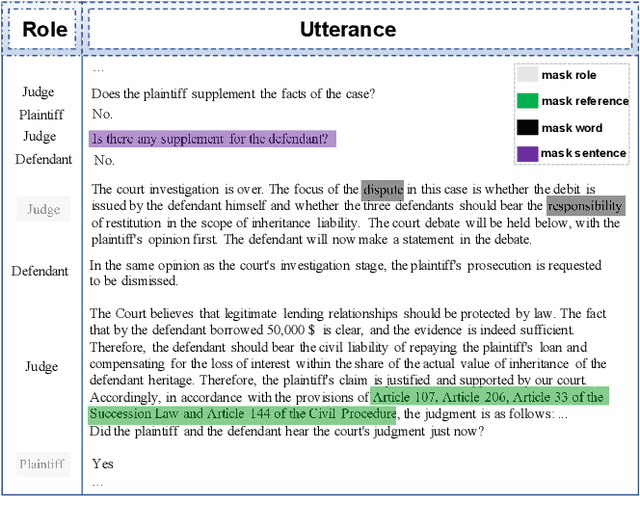
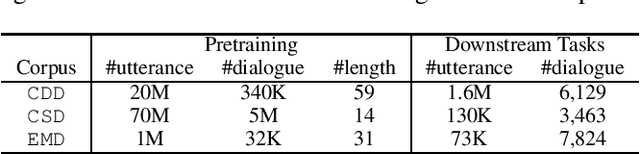
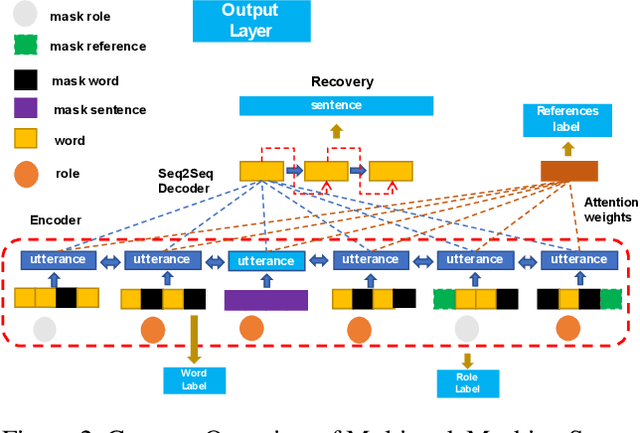

Multi-role dialogue understanding comprises a wide range of diverse tasks such as question answering, act classification, dialogue summarization etc. While dialogue corpora are abundantly available, labeled data, for specific learning tasks, can be highly scarce and expensive. In this work, we investigate dialogue context representation learning with various types unsupervised pretraining tasks where the training objectives are given naturally according to the nature of the utterance and the structure of the multi-role conversation. Meanwhile, in order to locate essential information for dialogue summarization/extraction, the pretraining process enables external knowledge integration. The proposed fine-tuned pretraining mechanism is comprehensively evaluated via three different dialogue datasets along with a number of downstream dialogue-mining tasks. Result shows that the proposed pretraining mechanism significantly contributes to all the downstream tasks without discrimination to different encoders.
A Unified Framework for Gaussian Mixture Reduction with Composite Transportation Distance
Feb 19, 2020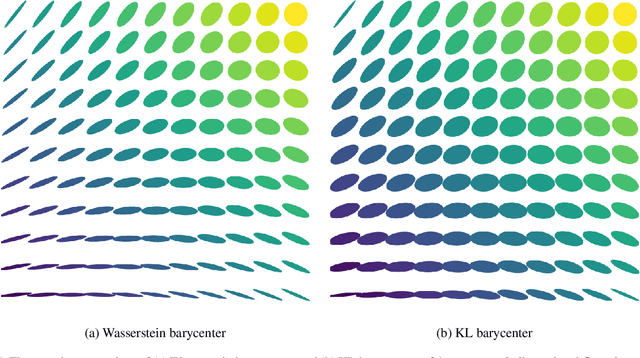

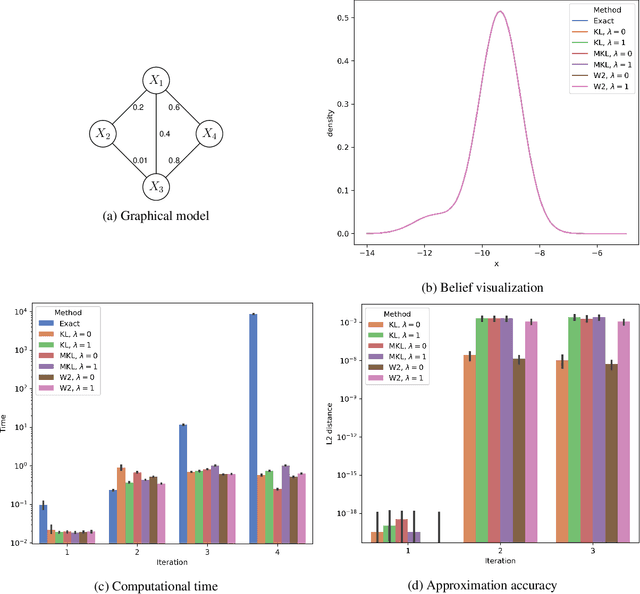
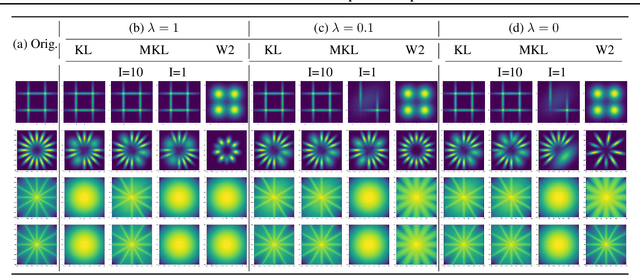
Gaussian mixture reduction (GMR) is the problem of approximating a finite Gaussian mixture by one with fewer components. It is widely used in density estimation, nonparametric belief propagation, and Bayesian recursive filtering. Although optimization and clustering-based algorithms have been proposed for GMR, they are either computationally expensive or lacking in theoretical supports. In this work, we propose to perform GMR by minimizing the entropic regularized composite transportation distance between two mixtures. We show our approach provides a unified framework for GMR that is both interpretable and computationally efficient. Our work also bridges the gap between optimization and clustering-based approaches for GMR. A Majorization-Minimization algorithm is developed for our optimization problem and its theoretical convergence is also established in this paper. Empirical experiments are also conducted to show the effectiveness of GMR. The effect of the choice of transportation cost on the performance of GMR is also investigated.