 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Absolute Scores: Relative Edit-induced Difference for Generalizable Image Aesthetic Assessment
Jun 04, 2026Traditional Image Aesthetic Assessment (IAA) methods mainly rely on regressing absolute Mean Opinion Scores (MOS). However, such a paradigm overlooks the inherently dynamic nature of human aesthetic perception, which relies on subconscious comparison against implicit visual references. Consequently, the lack of causal reasoning regarding aesthetic differences prevents models from learning generalizable aesthetic principles, thus limiting their generalization across diverse scenarios. In this work, we rethink the IAA task and propose Relative Edit-induced Difference Aesthetic learning (RED-Aes), a novel framework that leverages controllable image editing models to simulate the human aesthetic reasoning process. Instead of fitting absolute score distributions, RED-Aes explicitly learns the visual factors that drive aesthetic changes. To support this paradigm, we construct the RED-20k dataset, which comprises editing-based image pairs, quantitative aesthetic differences, and Chain-of-Thought (CoT) reasoning. Furthermore, we introduce a three-stage training strategy guided by a relative ranking consistency reward, optimizing the model solely via relative supervision. Extensive experiments demonstrate that RED-Aes achieves state-of-the-art performance on multiple public benchmarks, exhibiting superior generalization capabilities.
Lego-Edit: A General Image Editing Framework with Model-Level Bricks and MLLM Builder
Sep 16, 2025Instruction-based image editing has garnered significant attention due to its direct interaction with users. However, real-world user instructions are immensely diverse, and existing methods often fail to generalize effectively to instructions outside their training domain, limiting their practical application. To address this, we propose Lego-Edit, which leverages the generalization capability of Multi-modal Large Language Model (MLLM) to organize a suite of model-level editing tools to tackle this challenge. Lego-Edit incorporates two key designs: (1) a model-level toolkit comprising diverse models efficiently trained on limited data and several image manipulation functions, enabling fine-grained composition of editing actions by the MLLM; and (2) a three-stage progressive reinforcement learning approach that uses feedback on unannotated, open-domain instructions to train the MLLM, equipping it with generalized reasoning capabilities for handling real-world instructions. Experiments demonstrate that Lego-Edit achieves state-of-the-art performance on GEdit-Bench and ImgBench. It exhibits robust reasoning capabilities for open-domain instructions and can utilize newly introduced editing tools without additional fine-tuning. Code is available: https://github.com/xiaomi-research/lego-edit.
Improving Neural ODEs via Knowledge Distillation
Mar 10, 2022
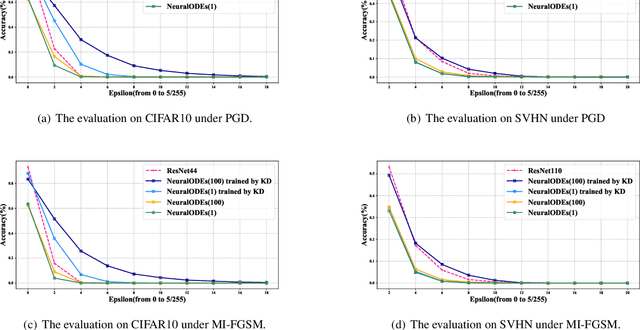
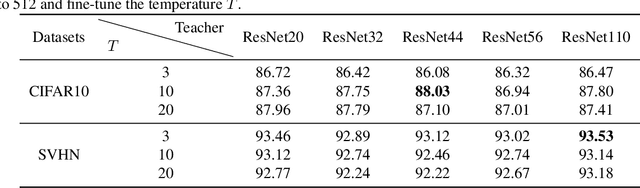

Neural Ordinary Differential Equations (Neural ODEs) construct the continuous dynamics of hidden units using ordinary differential equations specified by a neural network, demonstrating promising results on many tasks. However, Neural ODEs still do not perform well on image recognition tasks. The possible reason is that the one-hot encoding vector commonly used in Neural ODEs can not provide enough supervised information. We propose a new training based on knowledge distillation to construct more powerful and robust Neural ODEs fitting image recognition tasks. Specially, we model the training of Neural ODEs into a teacher-student learning process, in which we propose ResNets as the teacher model to provide richer supervised information. The experimental results show that the new training manner can improve the classification accuracy of Neural ODEs by 24% on CIFAR10 and 5% on SVHN. In addition, we also quantitatively discuss the effect of both knowledge distillation and time horizon in Neural ODEs on robustness against adversarial examples. The experimental analysis concludes that introducing the knowledge distillation and increasing the time horizon can improve the robustness of Neural ODEs against adversarial examples.
Naming Games in Spatially-Embedded Random Networks
May 07, 2007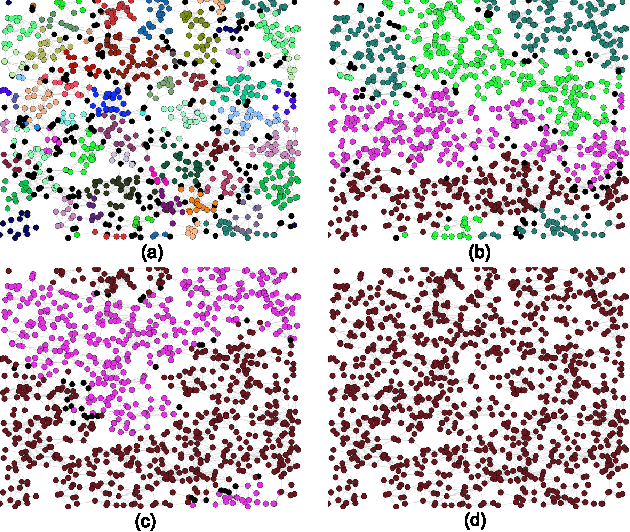
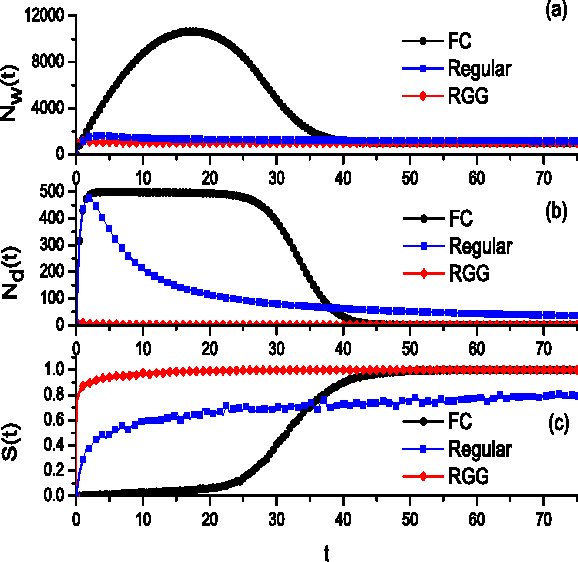
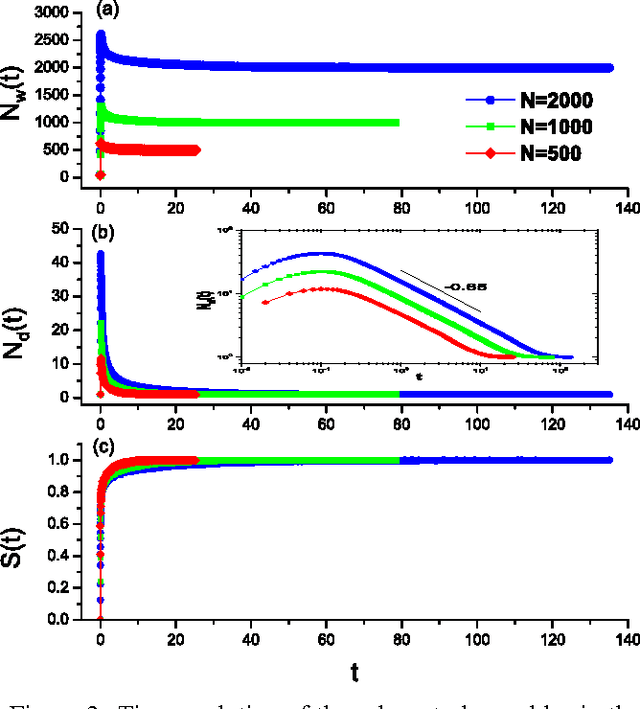
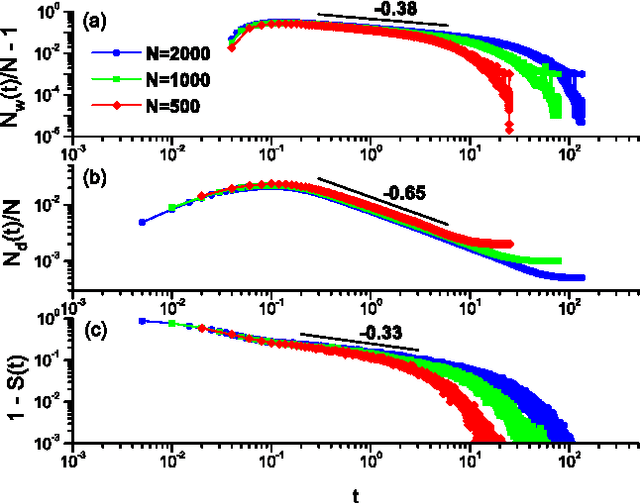
We investigate a prototypical agent-based model, the Naming Game, on random geometric networks. The Naming Game is a minimal model, employing local communications that captures the emergence of shared communication schemes (languages) in a population of autonomous semiotic agents. Implementing the Naming Games on random geometric graphs, local communications being local broadcasts, serves as a model for agreement dynamics in large-scale, autonomously operating wireless sensor networks. Further, it captures essential features of the scaling properties of the agreement process for spatially-embedded autonomous agents. We also present results for the case when a small density of long-range communication links are added on top of the random geometric graph, resulting in a "small-world"-like network and yielding a significantly reduced time to reach global agreement.
* We have found a programming error in our code used to generate the results of the earlier version. We have corrected the error, reran all simulations, and regenerated all data plots. While the qualitative behavior of the model has not changed, the numerical values of some of the scaling exponents did. 7 figures