 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Oct 01, 2024



Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover's Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
Training-Free Instance Segmentation from Semantic Image Segmentation Masks
Aug 02, 2023



In recent years, the development of instance segmentation has garnered significant attention in a wide range of applications. However, the training of a fully-supervised instance segmentation model requires costly both instance-level and pixel-level annotations. In contrast, weakly-supervised instance segmentation methods (i.e., with image-level class labels or point labels) struggle to satisfy the accuracy and recall requirements of practical scenarios. In this paper, we propose a novel paradigm for instance segmentation called training-free instance segmentation (TFISeg), which achieves instance segmentation results from image masks predicted using off-the-shelf semantic segmentation models. TFISeg does not require training a semantic or/and instance segmentation model and avoids the need for instance-level image annotations. Therefore, it is highly efficient. Specifically, we first obtain a semantic segmentation mask of the input image via a trained semantic segmentation model. Then, we calculate a displacement field vector for each pixel based on the segmentation mask, which can indicate representations belonging to the same class but different instances, i.e., obtaining the instance-level object information. Finally, instance segmentation results are obtained after being refined by a learnable category-agnostic object boundary branch. Extensive experimental results on two challenging datasets and representative semantic segmentation baselines (including CNNs and Transformers) demonstrate that TFISeg can achieve competitive results compared to the state-of-the-art fully-supervised instance segmentation methods without the need for additional human resources or increased computational costs. The code is available at: TFISeg
Learning to Reduce Information Bottleneck for Object Detection in Aerial Images
Apr 05, 2022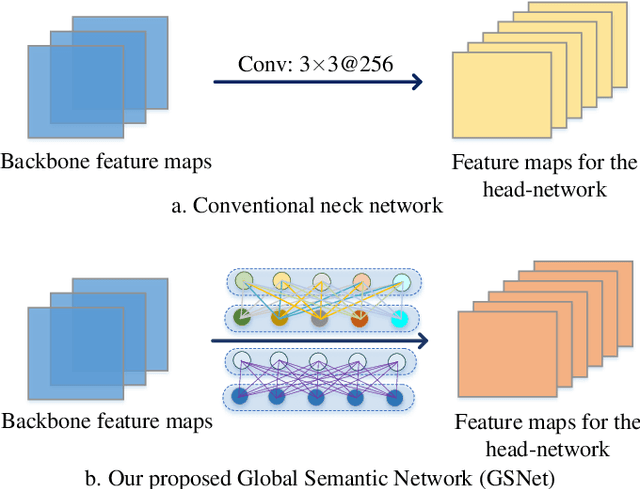
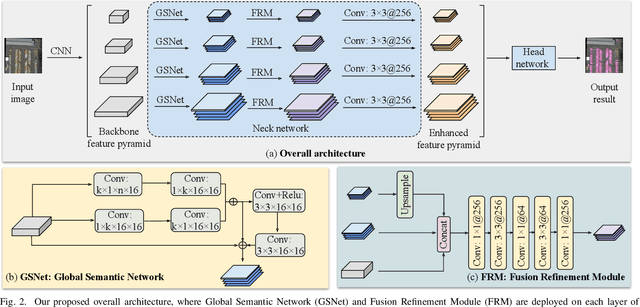
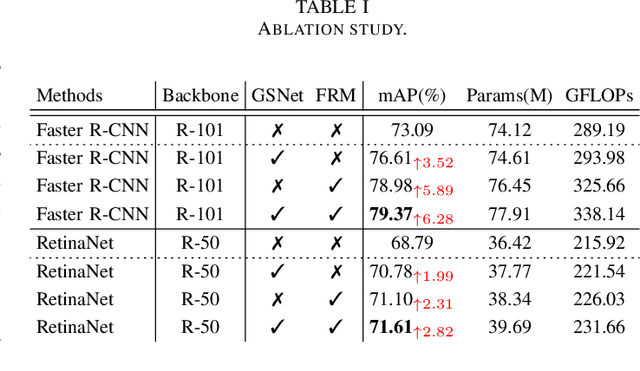
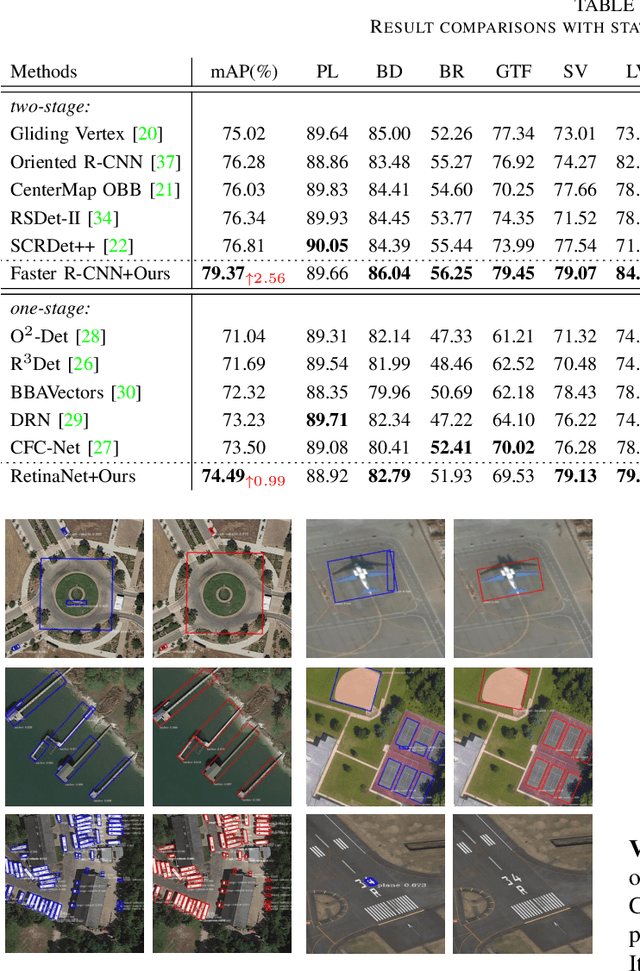
Object detection in aerial images is a fundamental research topic in the domain of geoscience and remote sensing. However, advanced progresses on this topic are mainly focused on the designment of backbone networks or header networks, but surprisingly ignored the neck ones. In this letter, we first analyse the importance of the neck network in object detection frameworks from the theory of information bottleneck. Then, to alleviate the information loss problem in the current neck network, we propose a global semantic network, which acts as a bridge from the backbone to the head network in a bidirectional global convolution manner. Compared to the existing neck networks, our method has advantages of capturing rich detailed information and less computational costs. Moreover, we further propose a fusion refinement module, which is used for feature fusion with rich details from different scales. To demonstrate the effectiveness and efficiency of our method, experiments are carried out on two challenging datasets (i.e., DOTA and HRSC2016). Results in terms of accuracy and computational complexity both can verify the superiority of our method.
Robust Triple-Matrix-Recovery-Based Auto-Weighted Label Propagation for Classification
Nov 20, 2019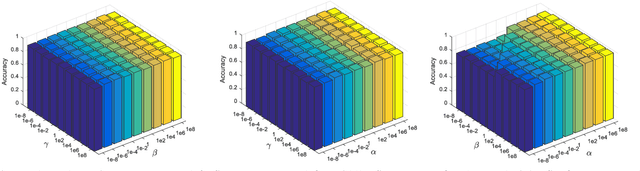

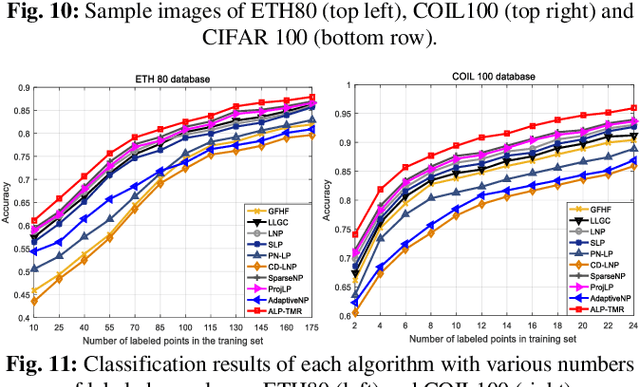
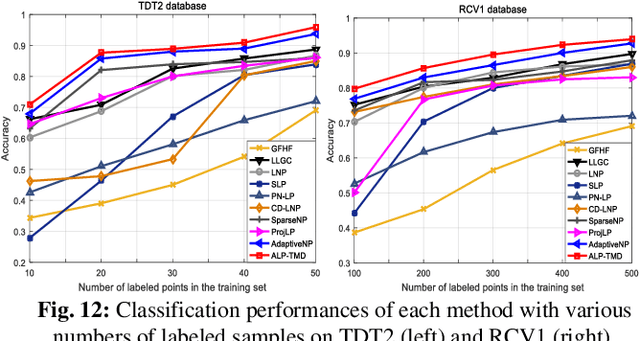
The graph-based semi-supervised label propagation algorithm has delivered impressive classification results. However, the estimated soft labels typically contain mixed signs and noise, which cause inaccurate predictions due to the lack of suitable constraints. Moreover, available methods typically calculate the weights and estimate the labels in the original input space, which typically contains noise and corruption. Thus, the en-coded similarities and manifold smoothness may be inaccurate for label estimation. In this paper, we present effective schemes for resolving these issues and propose a novel and robust semi-supervised classification algorithm, namely, the tri-ple-matrix-recovery-based robust auto-weighted label propa-gation framework (ALP-TMR). Our ALP-TMR introduces a triple matrix recovery mechanism to remove noise or mixed signs from the estimated soft labels and improve the robustness to noise and outliers in the steps of assigning weights and pre-dicting the labels simultaneously. Our method can jointly re-cover the underlying clean data, clean labels and clean weighting spaces by decomposing the original data, predicted soft labels or weights into a clean part plus an error part by fitting noise. In addition, ALP-TMR integrates the au-to-weighting process by minimizing reconstruction errors over the recovered clean data and clean soft labels, which can en-code the weights more accurately to improve both data rep-resentation and classification. By classifying samples in the recovered clean label and weight spaces, one can potentially improve the label prediction results. The results of extensive experiments demonstrated the satisfactory performance of our ALP-TMR.