 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Speech Recognition with Time-Depth Separable Convolutions
Apr 04, 2019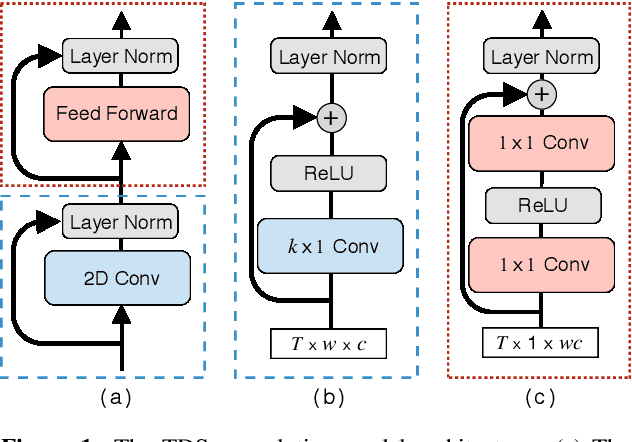
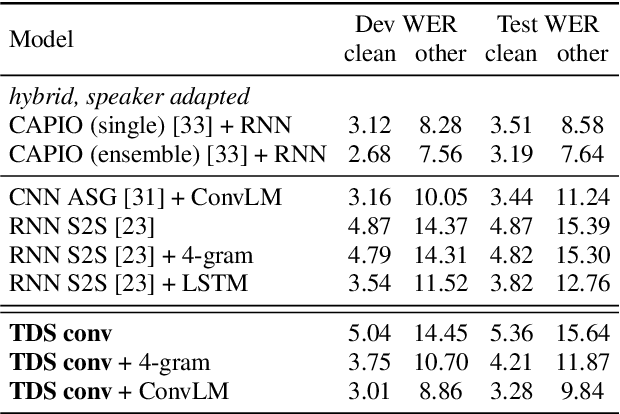
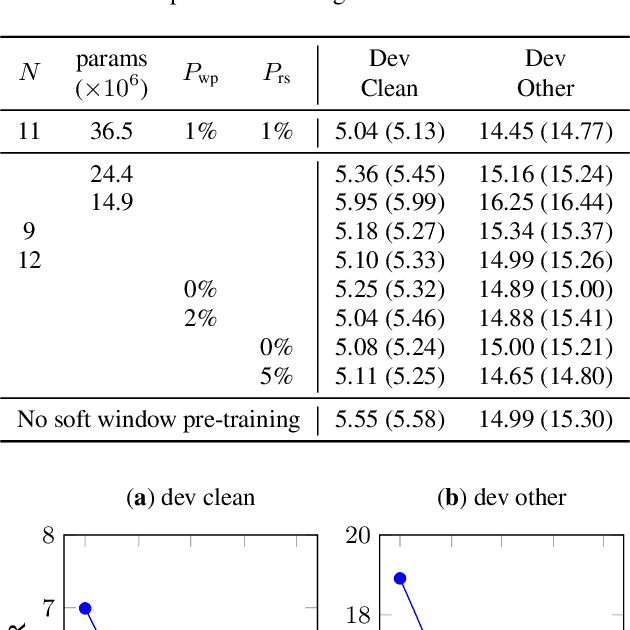
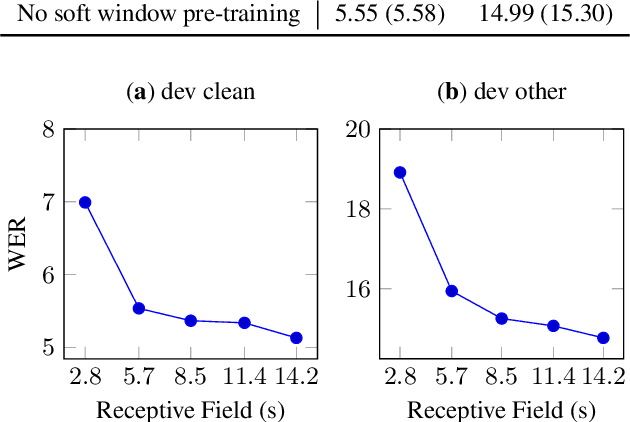
We propose a fully convolutional sequence-to-sequence encoder architecture with a simple and efficient decoder. Our model improves WER on LibriSpeech while being an order of magnitude more efficient than a strong RNN baseline. Key to our approach is a time-depth separable convolution block which dramatically reduces the number of parameters in the model while keeping the receptive field large. We also give a stable and efficient beam search inference procedure which allows us to effectively integrate a language model. Coupled with a convolutional language model, our time-depth separable convolution architecture improves by more than 22% relative WER over the best previously reported sequence-to-sequence results on the noisy LibriSpeech test set.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018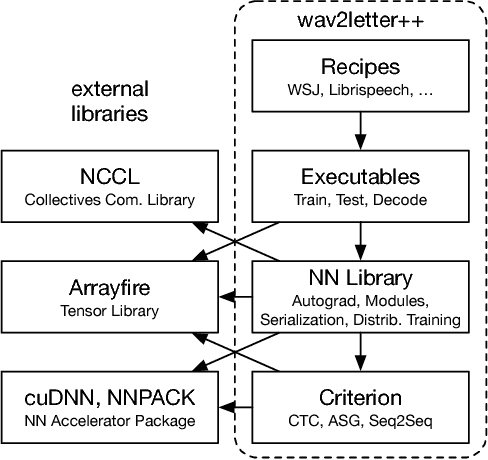
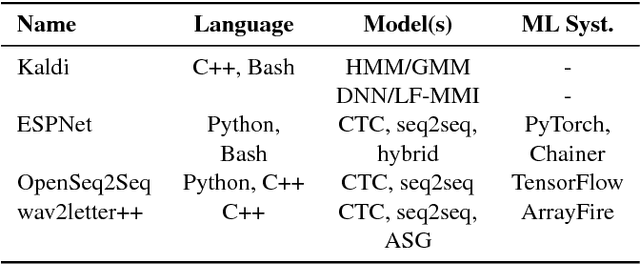

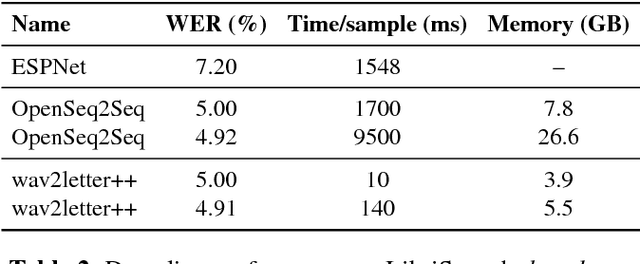
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
Fully Convolutional Speech Recognition
Dec 17, 2018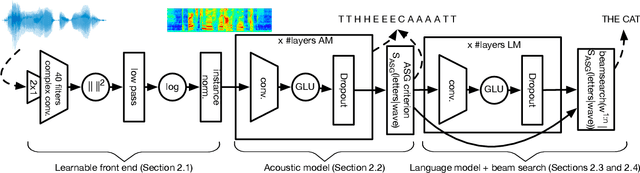

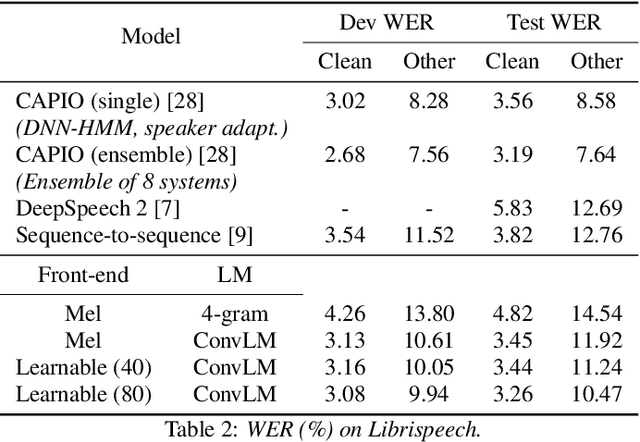
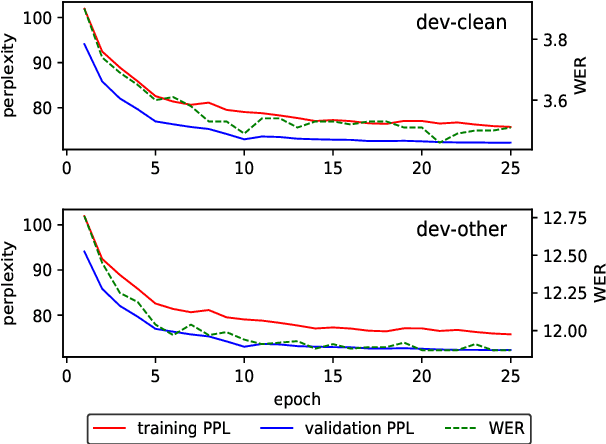
Current state-of-the-art speech recognition systems build on recurrent neural networks for acoustic and/or language modeling, and rely on feature extraction pipelines to extract mel-filterbanks or cepstral coefficients. In this paper we present an alternative approach based solely on convolutional neural networks, leveraging recent advances in acoustic models from the raw waveform and language modeling. This fully convolutional approach is trained end-to-end to predict characters from the raw waveform, removing the feature extraction step altogether. An external convolutional language model is used to decode words. On Wall Street Journal, our model matches the current state-of-the-art. On Librispeech, we report state-of-the-art performance among end-to-end models, including Deep Speech 2 trained with 12 times more acoustic data and significantly more linguistic data.
An empirical study on evaluation metrics of generative adversarial networks
Aug 17, 2018



Evaluating generative adversarial networks (GANs) is inherently challenging. In this paper, we revisit several representative sample-based evaluation metrics for GANs, and address the problem of how to evaluate the evaluation metrics. We start with a few necessary conditions for metrics to produce meaningful scores, such as distinguishing real from generated samples, identifying mode dropping and mode collapsing, and detecting overfitting. With a series of carefully designed experiments, we comprehensively investigate existing sample-based metrics and identify their strengths and limitations in practical settings. Based on these results, we observe that kernel Maximum Mean Discrepancy (MMD) and the 1-Nearest-Neighbor (1-NN) two-sample test seem to satisfy most of the desirable properties, provided that the distances between samples are computed in a suitable feature space. Our experiments also unveil interesting properties about the behavior of several popular GAN models, such as whether they are memorizing training samples, and how far they are from learning the target distribution.
Learning a Repression Network for Precise Vehicle Search
Aug 08, 2017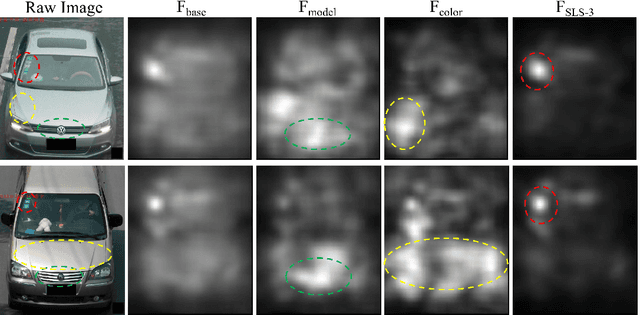
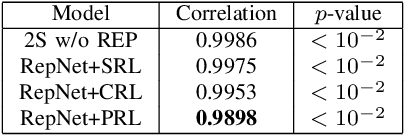
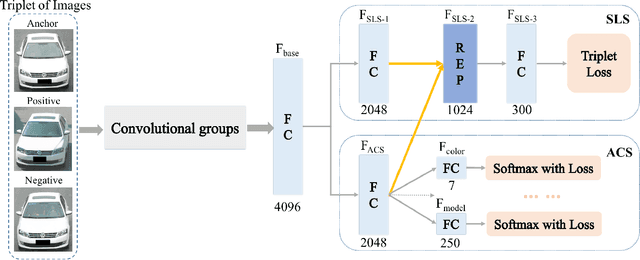
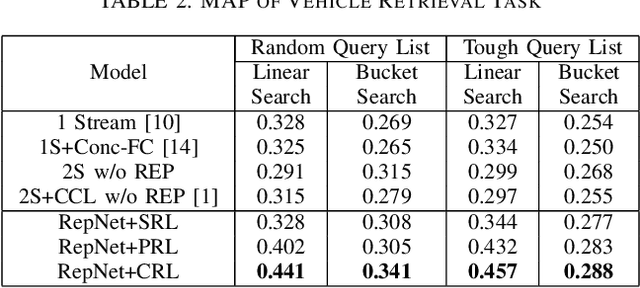
The growing explosion in the use of surveillance cameras in public security highlights the importance of vehicle search from large-scale image databases. Precise vehicle search, aiming at finding out all instances for a given query vehicle image, is a challenging task as different vehicles will look very similar to each other if they share same visual attributes. To address this problem, we propose the Repression Network (RepNet), a novel multi-task learning framework, to learn discriminative features for each vehicle image from both coarse-grained and detailed level simultaneously. Besides, benefited from the satisfactory accuracy of attribute classification, a bucket search method is proposed to reduce the retrieval time while still maintaining competitive performance. We conduct extensive experiments on the revised VehcileID dataset. Experimental results show that our RepNet achieves the state-of-the-art performance and the bucket search method can reduce the retrieval time by about 24 times.