 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANet: Context Aware Network for 3D Brain Tumor Segmentation
Jul 15, 2020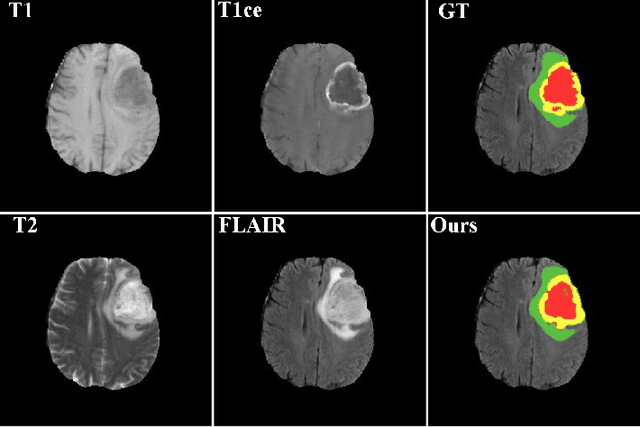
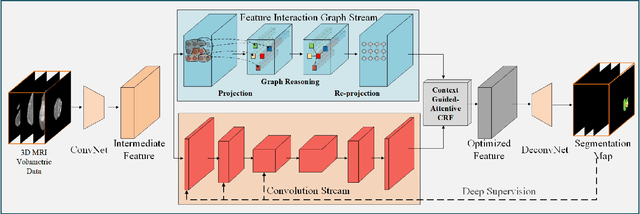
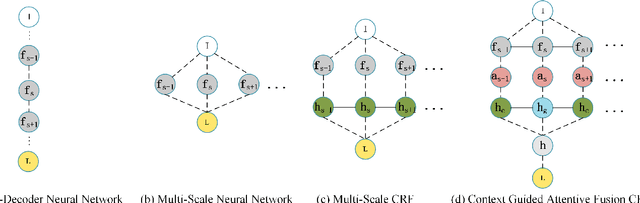
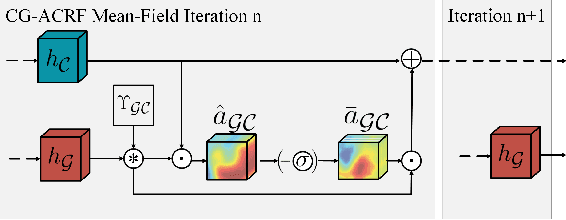
Automated segmentation of brain tumors in 3D magnetic resonance imaging plays an active role in tumor diagnosis, progression monitoring and surgery planning. Based on convolutional neural networks, especially fully convolutional networks, previous studies have shown some promising technologies for brain tumor segmentation. However, these approaches lack suitable strategies to incorporate contextual information to deal with local ambiguities, leading to unsatisfactory segmentation outcomes in challenging circumstances. In this work, we propose a novel Context-Aware Network (CANet) with a Hybrid Context Aware Feature Extractor (HCA-FE) and a Context Guided Attentive Conditional Random Field (CG-ACRF) for feature fusion. HCA-FE captures high dimensional and discriminative features with the contexts from both the convolutional space and feature interaction graphs. We adopt the powerful inference ability of probabilistic graphical models to learn hidden feature maps, and then use CG-ACRF to fuse the features of different contexts. We evaluate our proposed method on publicly accessible brain tumor segmentation datasets BRATS2017 and BRATS2018 against several state-of-the-art approaches using different segmentation metrics. The experimental results show that the proposed algorithm has better or competitive performance, compared to the standard approaches.
Inverse boosting pruning trees for depression detection on Twitter
Jun 02, 2019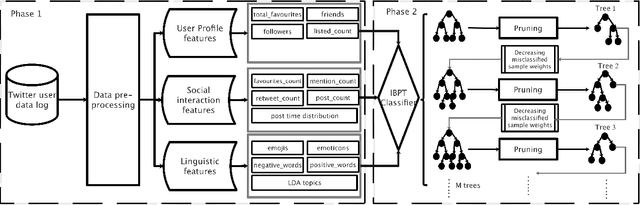
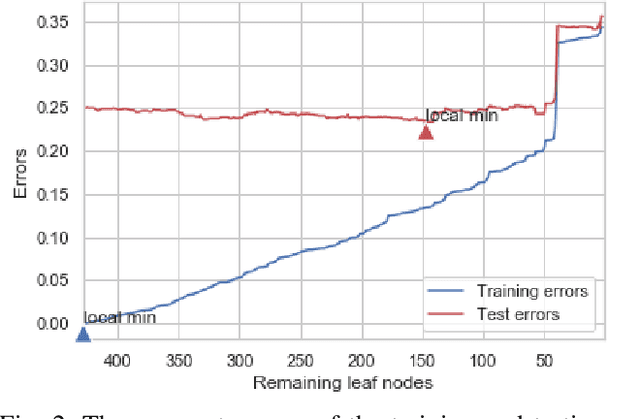

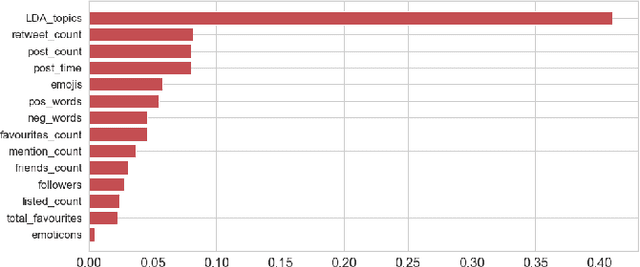
Depression is one of the most common mental health disorders, and a large number of depression people commit suicide each year. Potential depression sufferers do not consult psychological doctors because they feel ashamed or are unaware of any depression, which may result in severe delay of diagnosis and treatment. In the meantime, evidence shows that social media data provides valuable clues about physical and mental health conditions. In this paper, we argue that it is feasible to identify depression at an early stage by mining online social behaviours. Our approach, which is innovative to the practice of depression detection, does not rely on the extraction of numerous or complicated features to achieve accurate depression detection. Instead, we propose a novel classifier, namely, Inverse Boosting Pruning Trees (IBPT), which demonstrates a strong classification ability on a publicly accessible dataset with 7862 Twitter users. To comprehensively evaluate the classification capability of the IBPT, we use three real datasets from the UCI machine learning repository and the IBPT still obtains the best classification results against several state of the arts techniques. The results manifest that our proposed framework is promising for identifying social networks' users with depression.
US-net for robust and efficient nuclei instance segmentation
Jan 31, 2019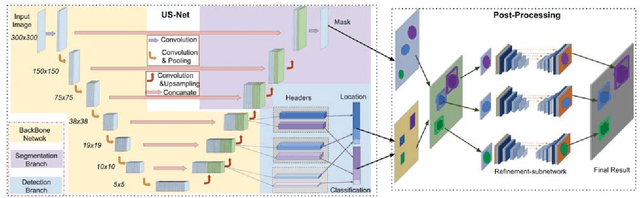
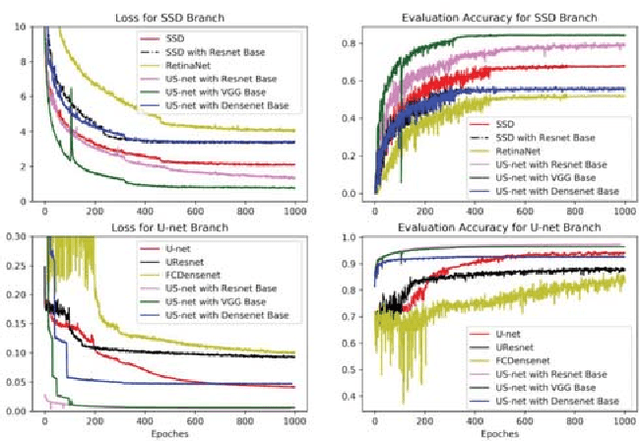
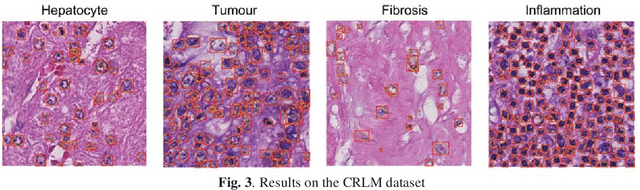
We present a novel neural network architecture, US-Net, for robust nuclei instance segmentation in histopathology images. The proposed framework integrates the nuclei detection and segmentation networks by sharing their outputs through the same foundation network, and thus enhancing the performance of both. The detection network takes into account the high-level semantic cues with contextual information, while the segmentation network focuses more on the low-level details like the edges. Extensive experiments reveal that our proposed framework can strengthen the performance of both branch networks in an integrated architecture and outperforms most of the state-of-the-art nuclei detection and segmentation networks.
GAN-based Virtual Re-Staining: A Promising Solution for Whole Slide Image Analysis
Jan 13, 2019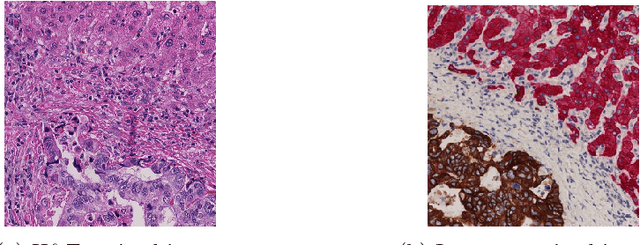
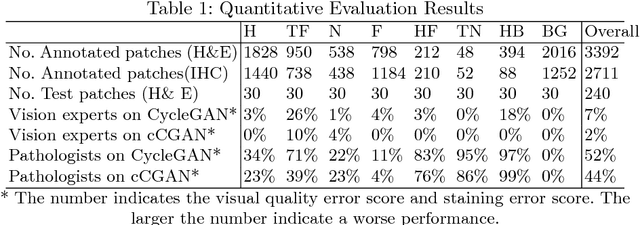
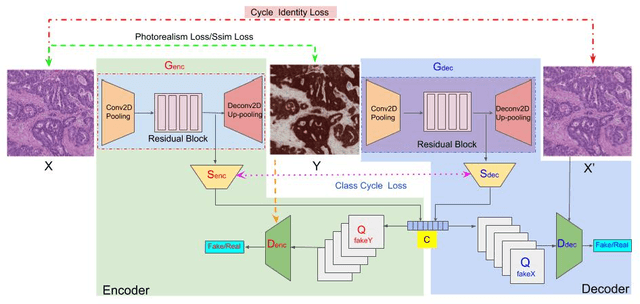
Histopathological cancer diagnosis is based on visual examination of stained tissue slides. Hematoxylin and eosin (H\&E) is a standard stain routinely employed worldwide. It is easy to acquire and cost effective, but cells and tissue components show low-contrast with varying tones of dark blue and pink, which makes difficult visual assessments, digital image analysis, and quantifications. These limitations can be overcome by IHC staining of target proteins of the tissue slide. IHC provides a selective, high-contrast imaging of cells and tissue components, but their use is largely limited by a significantly more complex laboratory processing and high cost. We proposed a conditional CycleGAN (cCGAN) network to transform the H\&E stained images into IHC stained images, facilitating virtual IHC staining on the same slide. This data-driven method requires only a limited amount of labelled data but will generate pixel level segmentation results. The proposed cCGAN model improves the original network \cite{zhu_unpaired_2017} by adding category conditions and introducing two structural loss functions, which realize a multi-subdomain translation and improve the translation accuracy as well. % need to give reasons here. Experiments demonstrate that the proposed model outperforms the original method in unpaired image translation with multi-subdomains. We also explore the potential of unpaired images to image translation method applied on other histology images related tasks with different staining techniques.
CUNet: A Compact Unsupervised Network for Image Classification
Jul 06, 2016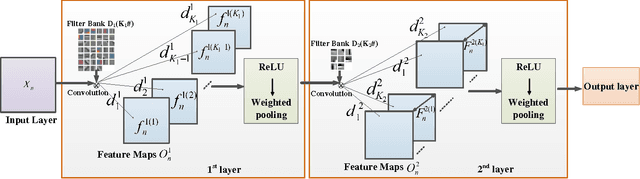
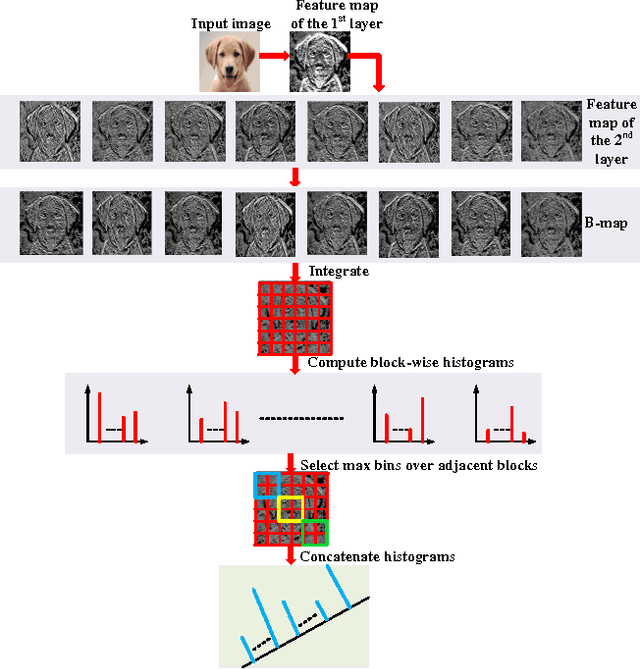


In this paper, we propose a compact network called CUNet (compact unsupervised network) to counter the image classification challenge. Different from the traditional convolutional neural networks learning filters by the time-consuming stochastic gradient descent, CUNet learns the filter bank from diverse image patches with the simple K-means, which significantly avoids the requirement of scarce labeled training images, reduces the training consumption, and maintains the high discriminative ability. Besides, we propose a new pooling method named weighted pooling considering the different weight values of adjacent neurons, which helps to improve the robustness to small image distortions. In the output layer, CUNet integrates the feature maps gained in the last hidden layer, and straightforwardly computes histograms in non-overlapped blocks. To reduce feature redundancy, we implement the max-pooling operation on adjacent blocks to select the most competitive features. Comprehensive experiments are conducted to demonstrate the state-of-the-art classification performances with CUNet on CIFAR-10, STL-10, MNIST and Caltech101 benchmark datasets.
A Distributed Deep Representation Learning Model for Big Image Data Classification
Jul 02, 2016
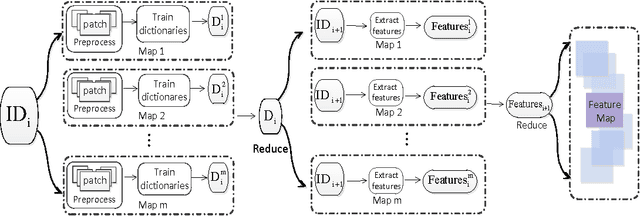
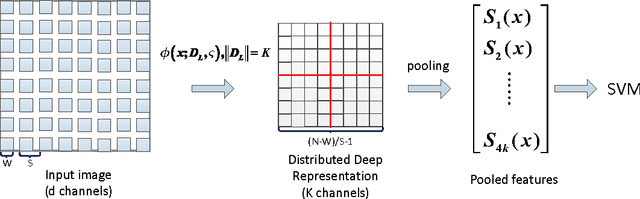

This paper describes an effective and efficient image classification framework nominated distributed deep representation learning model (DDRL). The aim is to strike the balance between the computational intensive deep learning approaches (tuned parameters) which are intended for distributed computing, and the approaches that focused on the designed parameters but often limited by sequential computing and cannot scale up. In the evaluation of our approach, it is shown that DDRL is able to achieve state-of-art classification accuracy efficiently on both medium and large datasets. The result implies that our approach is more efficient than the conventional deep learning approaches, and can be applied to big data that is too complex for parameter designing focused approaches. More specifically, DDRL contains two main components, i.e., feature extraction and selection. A hierarchical distributed deep representation learning algorithm is designed to extract image statistics and a nonlinear mapping algorithm is used to map the inherent statistics into abstract features. Both algorithms are carefully designed to avoid millions of parameters tuning. This leads to a more compact solution for image classification of big data. We note that the proposed approach is designed to be friendly with parallel computing. It is generic and easy to be deployed to different distributed computing resources. In the experiments, the largescale image datasets are classified with a DDRM implementation on Hadoop MapReduce, which shows high scalability and resilience.
NIST: An Image Classification Network to Image Semantic Retrieval
Jul 02, 2016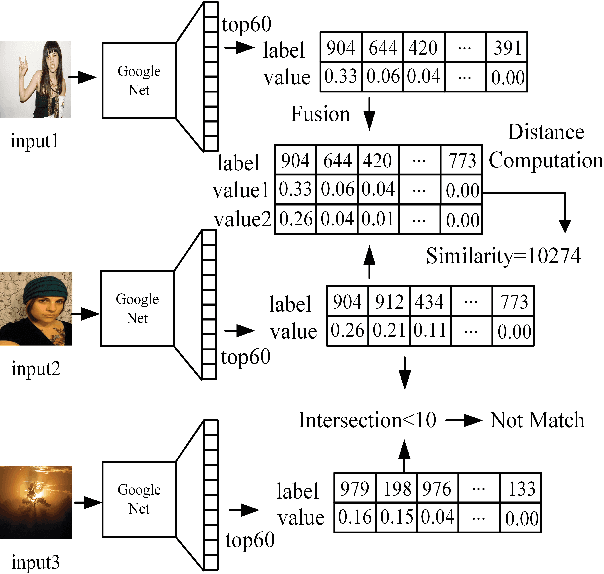


This paper proposes a classification network to image semantic retrieval (NIST) framework to counter the image retrieval challenge. Our approach leverages the successful classification network GoogleNet based on Convolutional Neural Networks to obtain the semantic feature matrix which contains the serial number of classes and corresponding probabilities. Compared with traditional image retrieval using feature matching to compute the similarity between two images, NIST leverages the semantic information to construct semantic feature matrix and uses the semantic distance algorithm to compute the similarity. Besides, the fusion strategy can significantly reduce storage and time consumption due to less classes participating in the last semantic distance computation. Experiments demonstrate that our NIST framework produces state-of-the-art results in retrieval experiments on MIRFLICKR-25K dataset.