 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTP-Seg: Task-Prototype Framework for Unified Medical Lesion Segmentation
Apr 01, 2026Building a unified model with a single set of parameters to efficiently handle diverse types of medical lesion segmentation has become a crucial objective for AI-assisted diagnosis. Existing unified segmentation approaches typically rely on shared encoders across heterogeneous tasks and modalities, which often leads to feature entanglement, gradient interference, and suboptimal lesion discrimination. In this work, we propose TP-Seg, a task-prototype framework for unified medical lesion segmentation. On one hand, the task-conditioned adapter effectively balances shared and task-specific representations through a dual-path expert structure, enabling adaptive feature extraction across diverse medical imaging modalities and lesion types. On the other hand, the prototype-guided task decoder introduces learnable task prototypes as semantic anchors and employs a cross-attention mechanism to achieve fine-grained modeling of task-specific foreground and background semantics. Without bells and whistles, TP-Seg consistently outperforms specialized, general and unified segmentation methods across 8 different medical lesion segmentation tasks covering multiple imaging modalities, demonstrating strong generalization, scalability and clinical applicability.
A Saliency Dataset of Head and Eye Movements for Augmented Reality
Dec 12, 2019
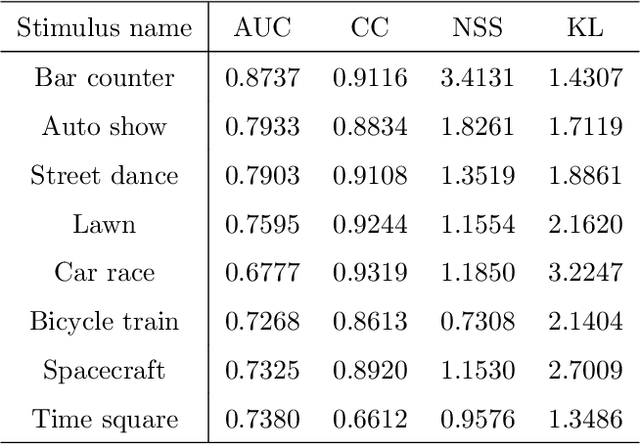

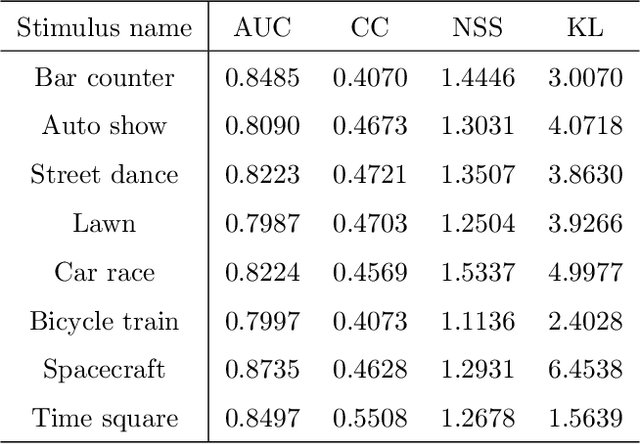
In augmented reality (AR), correct and precise estimations of user's visual fixations and head movements can enhance the quality of experience by allocating more computation resources for the analysing, rendering and 3D registration on the areas of interest. However, there is no research about understanding the visual exploration of users when using an AR system or modeling AR visual attention. To bridge the gap between the real-world scene and the scene augmented by virtual information, we construct the ARVR saliency dataset with 100 diverse videos evaluated by 20 people. The virtual reality (VR) technique is employed to simulate the real-world, and annotations of object recognition and tracking as augmented contents are blended into the omnidirectional videos. Users can get the sense of experiencing AR when watching the augmented videos. The saliency annotations of head and eye movements for both original and augmented videos are collected which constitute the ARVR dataset.