 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-NeRF: Point-based Neural Radiance Fields
Jan 21, 2022
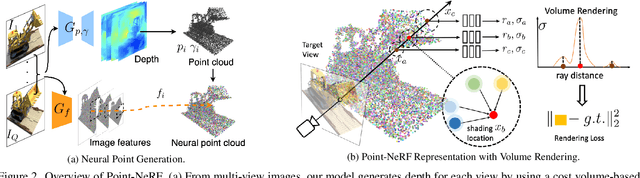

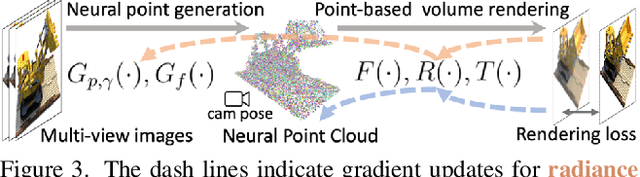
Volumetric neural rendering methods like NeRF generate high-quality view synthesis results but are optimized per-scene leading to prohibitive reconstruction time. On the other hand, deep multi-view stereo methods can quickly reconstruct scene geometry via direct network inference. Point-NeRF combines the advantages of these two approaches by using neural 3D point clouds, with associated neural features, to model a radiance field. Point-NeRF can be rendered efficiently by aggregating neural point features near scene surfaces, in a ray marching-based rendering pipeline. Moreover, Point-NeRF can be initialized via direct inference of a pre-trained deep network to produce a neural point cloud; this point cloud can be finetuned to surpass the visual quality of NeRF with 30X faster training time. Point-NeRF can be combined with other 3D reconstruction methods and handles the errors and outliers in such methods via a novel pruning and growing mechanism.
Behind the Curtain: Learning Occluded Shapes for 3D Object Detection
Dec 04, 2021
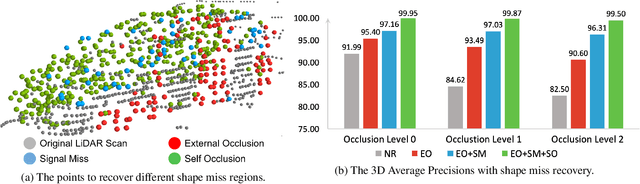
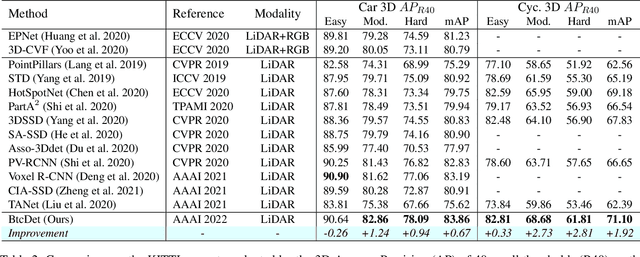
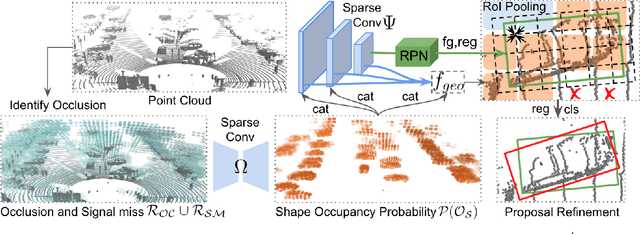
Advances in LiDAR sensors provide rich 3D data that supports 3D scene understanding. However, due to occlusion and signal miss, LiDAR point clouds are in practice 2.5D as they cover only partial underlying shapes, which poses a fundamental challenge to 3D perception. To tackle the challenge, we present a novel LiDAR-based 3D object detection model, dubbed Behind the Curtain Detector (BtcDet), which learns the object shape priors and estimates the complete object shapes that are partially occluded (curtained) in point clouds. BtcDet first identifies the regions that are affected by occlusion and signal miss. In these regions, our model predicts the probability of occupancy that indicates if a region contains object shapes. Integrated with this probability map, BtcDet can generate high-quality 3D proposals. Finally, the probability of occupancy is also integrated into a proposal refinement module to generate the final bounding boxes. Extensive experiments on the KITTI Dataset and the Waymo Open Dataset demonstrate the effectiveness of BtcDet. Particularly, for the 3D detection of both cars and cyclists on the KITTI benchmark, BtcDet surpasses all of the published state-of-the-art methods by remarkable margins. Code is released (https://github.com/Xharlie/BtcDet}{https://github.com/Xharlie/BtcDet).
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 20, 2021
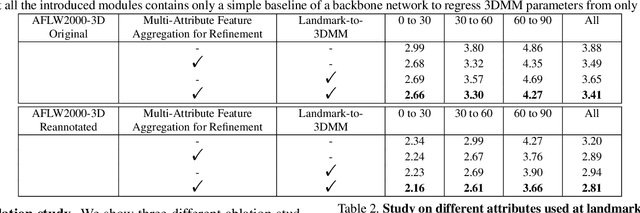
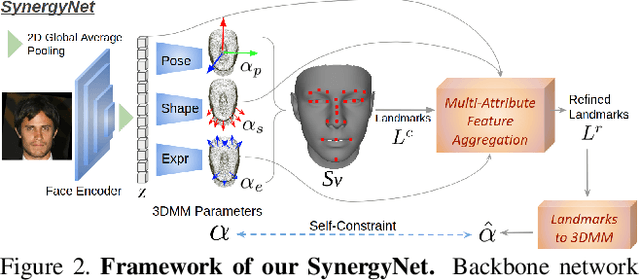
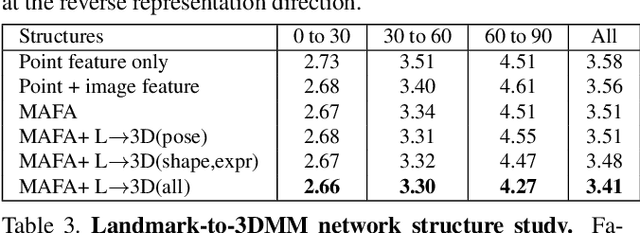
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation
Aug 15, 2021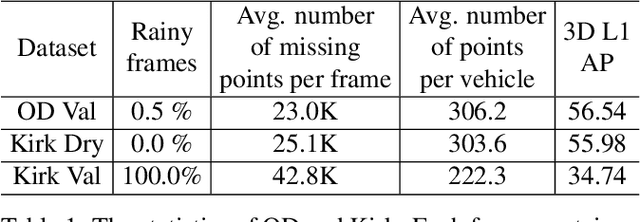

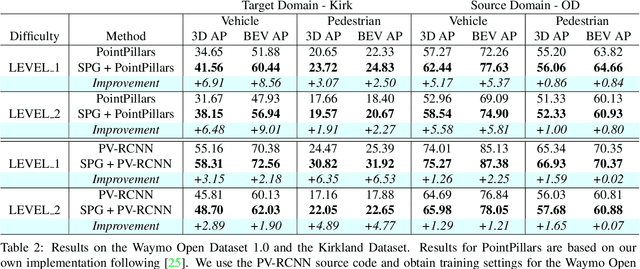
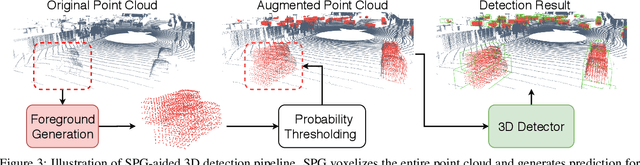
In autonomous driving, a LiDAR-based object detector should perform reliably at different geographic locations and under various weather conditions. While recent 3D detection research focuses on improving performance within a single domain, our study reveals that the performance of modern detectors can drop drastically cross-domain. In this paper, we investigate unsupervised domain adaptation (UDA) for LiDAR-based 3D object detection. On the Waymo Domain Adaptation dataset, we identify the deteriorating point cloud quality as the root cause of the performance drop. To address this issue, we present Semantic Point Generation (SPG), a general approach to enhance the reliability of LiDAR detectors against domain shifts. Specifically, SPG generates semantic points at the predicted foreground regions and faithfully recovers missing parts of the foreground objects, which are caused by phenomena such as occlusions, low reflectance or weather interference. By merging the semantic points with the original points, we obtain an augmented point cloud, which can be directly consumed by modern LiDAR-based detectors. To validate the wide applicability of SPG, we experiment with two representative detectors, PointPillars and PV-RCNN. On the UDA task, SPG significantly improves both detectors across all object categories of interest and at all difficulty levels. SPG can also benefit object detection in the original domain. On the Waymo Open Dataset and KITTI, SPG improves 3D detection results of these two methods across all categories. Combined with PV-RCNN, SPG achieves state-of-the-art 3D detection results on KITTI.
Accurate 3D Facial Geometry Prediction by Multi-Task, Multi-Modal, and Multi-Representation Landmark Refinement Network
Apr 16, 2021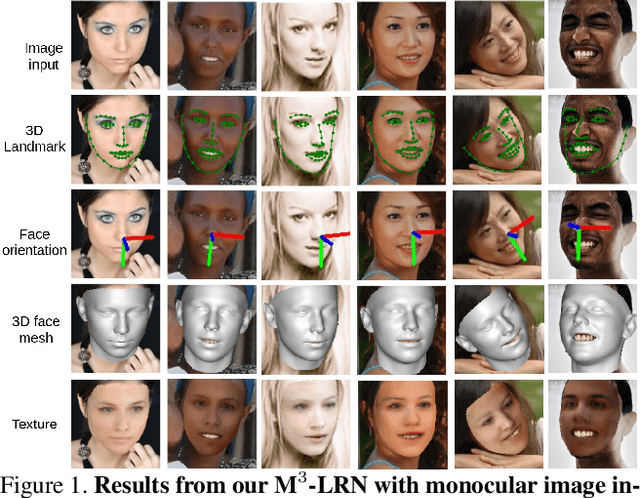
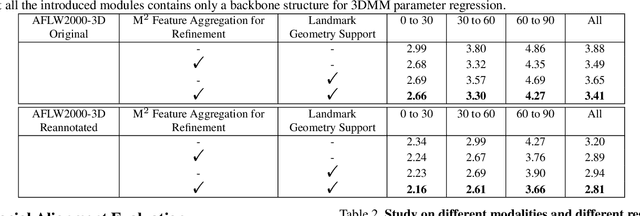
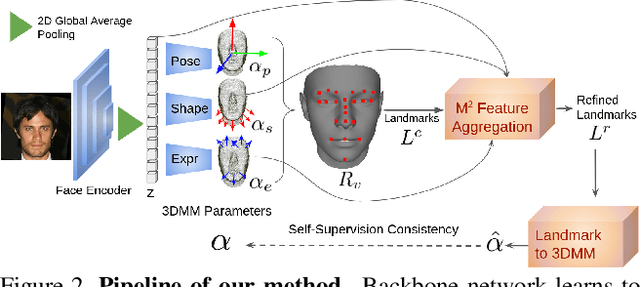
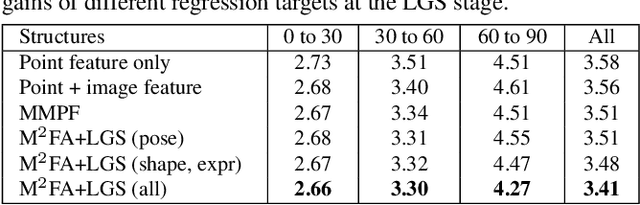
This work focuses on complete 3D facial geometry prediction, including 3D facial alignment via 3D face modeling and face orientation estimation using the proposed multi-task, multi-modal, and multi-representation landmark refinement network (M$^3$-LRN). Our focus is on the important facial attributes, 3D landmarks, and we fully utilize their embedded information to guide 3D facial geometry learning. We first propose a multi-modal and multi-representation feature aggregation for landmark refinement. Next, we are the first to study 3DMM regression from sparse 3D landmarks and utilize multi-representation advantage to attain better geometry prediction. We attain the state of the art from extensive experiments on all tasks of learning 3D facial geometry. We closely validate contributions of each modality and representation. Our results are robust across cropped faces, underwater scenarios, and extreme poses. Specially we adopt only simple and widely used network operations in M$^3$-LRN and attain a near 20\% improvement on face orientation estimation over the current best performance. See our project page here.
Geometry-Aware Instance Segmentation with Disparity Maps
Jun 14, 2020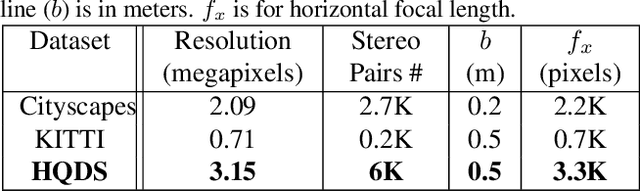
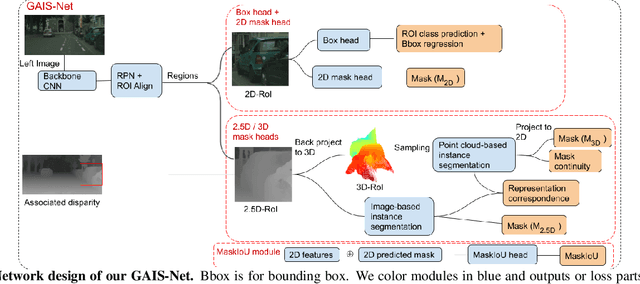
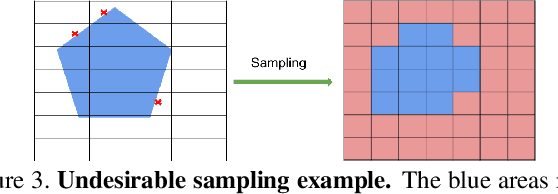
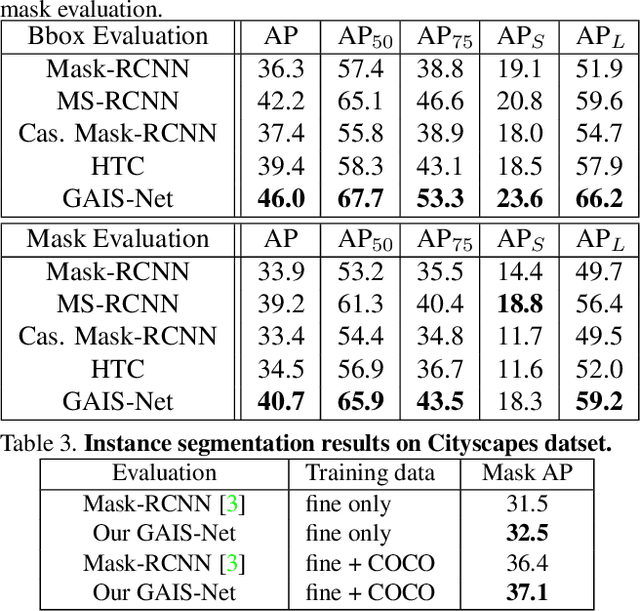
Most previous works of outdoor instance segmentation for images only use color information. We explore a novel direction of sensor fusion to exploit stereo cameras. Geometric information from disparities helps separate overlapping objects of the same or different classes. Moreover, geometric information penalizes region proposals with unlikely 3D shapes thus suppressing false positive detections. Mask regression is based on 2D, 2.5D, and 3D ROI using the pseudo-lidar and image-based representations. These mask predictions are fused by a mask scoring process. However, public datasets only adopt stereo systems with shorter baseline and focal legnth, which limit measuring ranges of stereo cameras. We collect and utilize High-Quality Driving Stereo (HQDS) dataset, using much longer baseline and focal length with higher resolution. Our performance attains state of the art. Please refer to our project page. The full paper is available here.
Grid-GCN for Fast and Scalable Point Cloud Learning
Dec 20, 2019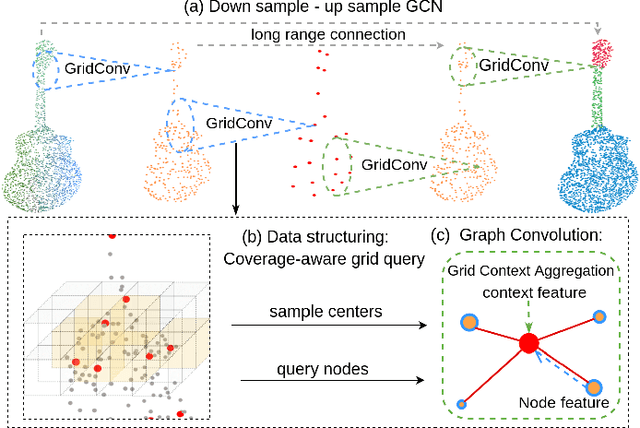

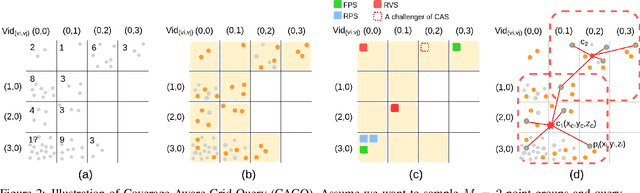
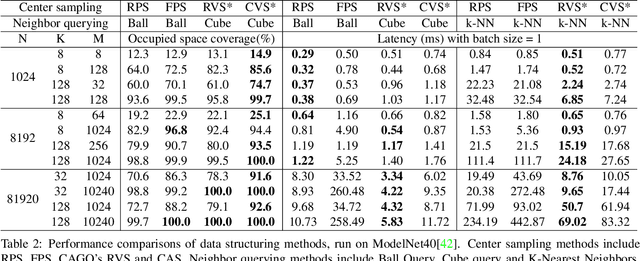
Due to the sparsity and irregularity of the point cloud data, methods that directly consume points have become popular. Among all point-based models, graph convolutional networks (GCN) lead to notable performance by fully preserving the data granularity and exploiting point interrelation. However, point-based networks spend a significant amount of time on data structuring (e.g., Farthest Point Sampling (FPS) and neighbor points querying), which limit the speed and scalability. In this paper, we present a method, named Grid-GCN, for fast and scalable point cloud learning. Grid-GCN uses a novel data structuring strategy, Coverage-Aware Grid Query (CAGQ). By leveraging the efficiency of grid space, CAGQ improves spatial coverage while reducing the theoretical time complexity. Compared with popular sampling methods such as Farthest Point Sampling (FPS) and Ball Query, CAGQ achieves up to 50X speed-up. With a Grid Context Aggregation (GCA) module, Grid-GCN achieves state-of-the-art performance on major point cloud classification and segmentation benchmarks with significantly faster runtime than previous studies. Remarkably, Grid-GCN achieves the inference speed of 50fps on ScanNet using 81920 points per scene as input.
DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction
May 26, 2019
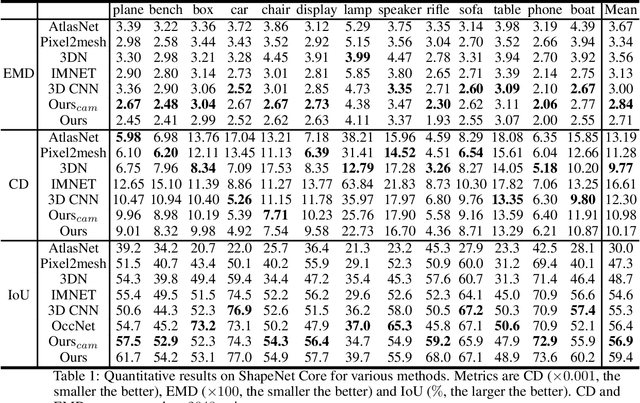
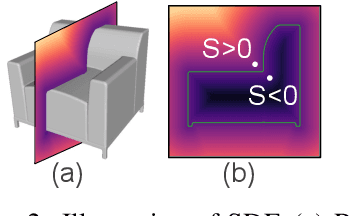
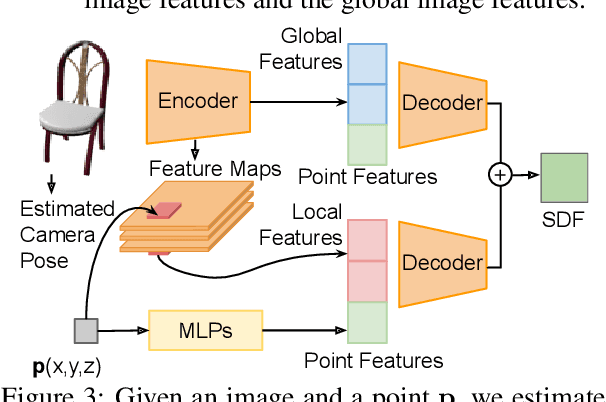
Reconstructing 3D shapes from single-view images has been a long-standing research problem and has attracted a lot of attention. In this paper, we present DISN, a Deep Implicit Surface Network that generates a high-quality 3D shape given an input image by predicting the underlying signed distance field. In addition to utilizing global image features, DISN also predicts the local image patch each 3D point sample projects onto and extracts local features from the patch. Combining global and local features significantly improves the accuracy of the predicted signed distance field. To the best of our knowledge, DISN is the first method that constantly captures details such as holes and thin structures present in 3D shapes from single-view images. DISN achieves state-of-the-art single-view reconstruction performance on a variety of shape categories reconstructed from both synthetic and real images. Code is available at github.com/laughtervv/DISN.
Stochastic Video Long-term Interpolation
Sep 07, 2018
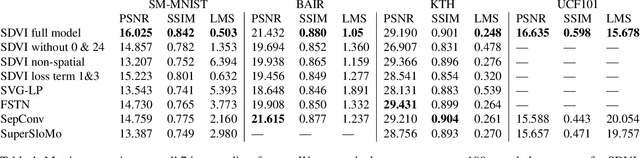
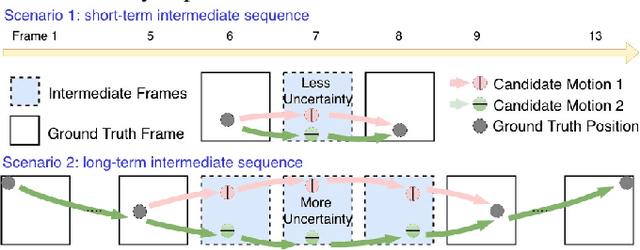
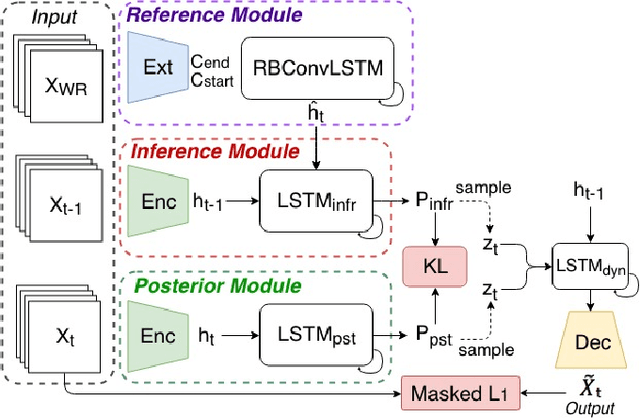
In this paper, we introduce a stochastic learning framework for long-term video interpolation. While most existing interpolation models require two reference frames with a short interval, our framework predicts a plausible intermediate sequence between a long interval. Our model consists of two parts: (1) a deterministic estimation to guarantee the spatial and temporal coherency among frames, (2) a stochastic sampling process to generate dynamics from inferred distributions. Experimental results show that our model is able to generate sharp and clear sequences with variations. Moreover, motions in the generated sequence are realistic and able to transfer smoothly from the referenced start frame to the end frame.
Generative Cooperative Net for Image Generation and Data Augmentation
Feb 08, 2018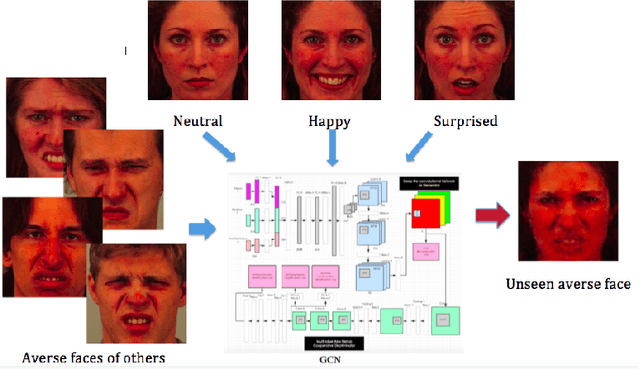
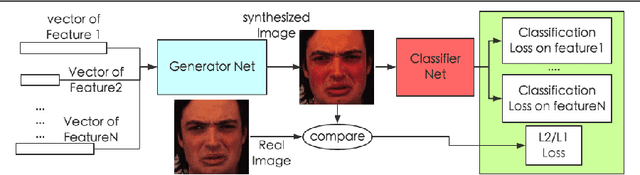
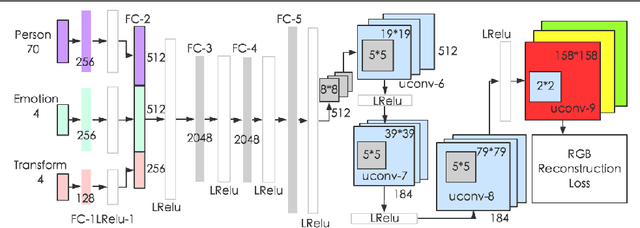
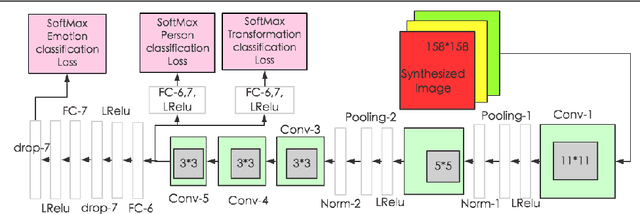
How to build a good model for image generation given an abstract concept is a fundamental problem in computer vision. In this paper, we explore a generative model for the task of generating unseen images with desired features. We propose the Generative Cooperative Net (GCN) for image generation. The idea is similar to generative adversarial networks except that the generators and discriminators are trained to work accordingly. Our experiments on hand-written digit generation and facial expression generation show that GCN's two cooperative counterparts (the generator and the classifier) can work together nicely and achieve promising results. We also discovered a usage of such generative model as an data-augmentation tool. Our experiment of applying this method on a recognition task shows that it is very effective comparing to other existing methods. It is easy to set up and could help generate a very large synthesized dataset.