 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Federated GANs with Theoretical Guarantees: A Universal Aggregation Approach
Feb 09, 2021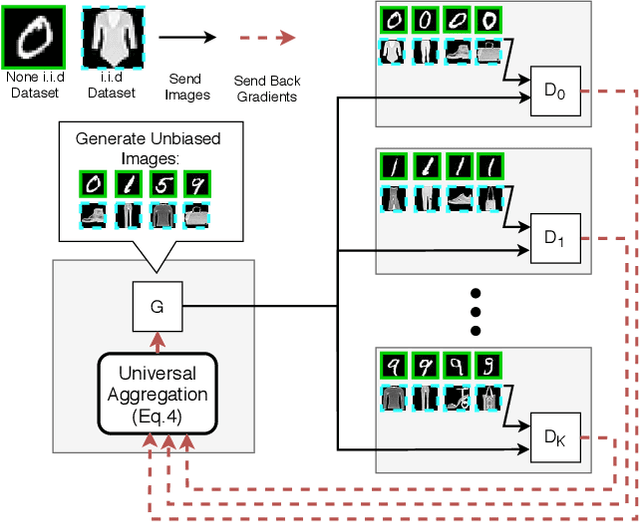
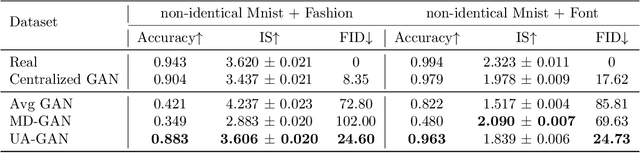
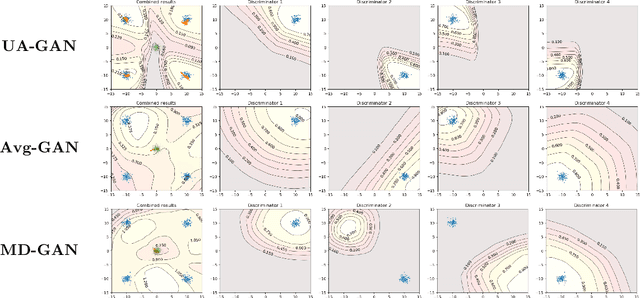
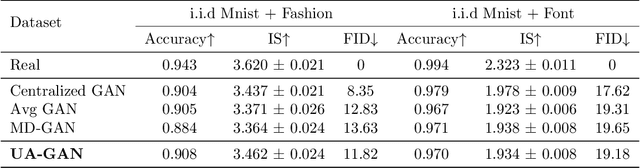
Recently, Generative Adversarial Networks (GANs) have demonstrated their potential in federated learning, i.e., learning a centralized model from data privately hosted by multiple sites. A federatedGAN jointly trains a centralized generator and multiple private discriminators hosted at different sites. A major theoretical challenge for the federated GAN is the heterogeneity of the local data distributions. Traditional approaches cannot guarantee to learn the target distribution, which isa mixture of the highly different local distributions. This paper tackles this theoretical challenge, and for the first time, provides a provably correct framework for federated GAN. We propose a new approach called Universal Aggregation, which simulates a centralized discriminator via carefully aggregating the mixture of all private discriminators. We prove that a generator trained with this simulated centralized discriminator can learn the desired target distribution. Through synthetic and real datasets, we show that our method can learn the mixture of largely different distributions where existing federated GAN methods fail.
Multi-modal AsynDGAN: Learn From Distributed Medical Image Data without Sharing Private Information
Dec 15, 2020As deep learning technologies advance, increasingly more data is necessary to generate general and robust models for various tasks. In the medical domain, however, large-scale and multi-parties data training and analyses are infeasible due to the privacy and data security concerns. In this paper, we propose an extendable and elastic learning framework to preserve privacy and security while enabling collaborative learning with efficient communication. The proposed framework is named distributed Asynchronized Discriminator Generative Adversarial Networks (AsynDGAN), which consists of a centralized generator and multiple distributed discriminators. The advantages of our proposed framework are five-fold: 1) the central generator could learn the real data distribution from multiple datasets implicitly without sharing the image data; 2) the framework is applicable for single-modality or multi-modality data; 3) the learned generator can be used to synthesize samples for down-stream learning tasks to achieve close-to-real performance as using actual samples collected from multiple data centers; 4) the synthetic samples can also be used to augment data or complete missing modalities for one single data center; 5) the learning process is more efficient and requires lower bandwidth than other distributed deep learning methods.
Learn distributed GAN with Temporary Discriminators
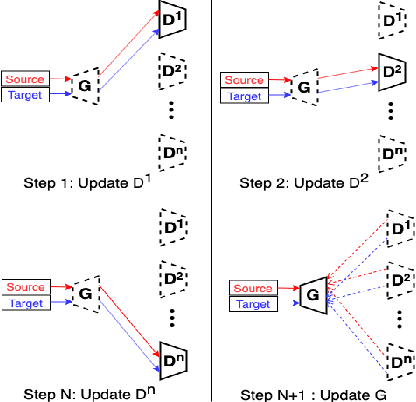
Jul 17, 2020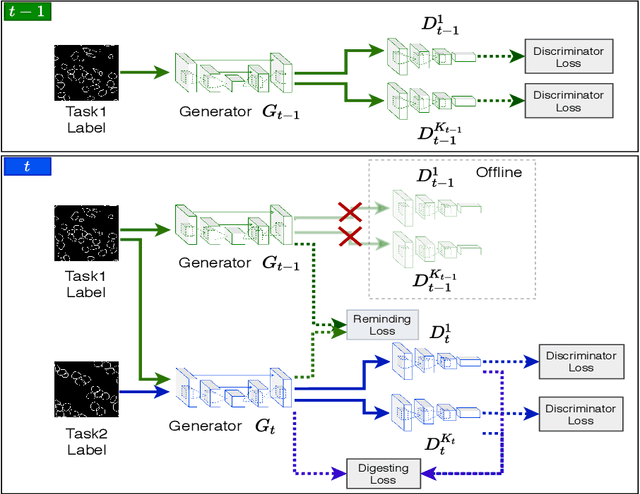
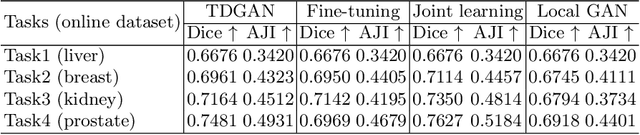

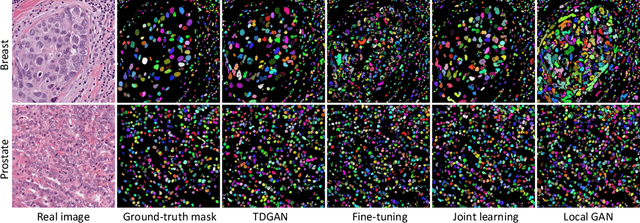
In this work, we propose a method for training distributed GAN with sequential temporary discriminators. Our proposed method tackles the challenge of training GAN in the federated learning manner: How to update the generator with a flow of temporary discriminators? We apply our proposed method to learn a self-adaptive generator with a series of local discriminators from multiple data centers. We show our design of loss function indeed learns the correct distribution with provable guarantees. The empirical experiments show that our approach is capable of generating synthetic data which is practical for real-world applications such as training a segmentation model.
Synthetic Learning: Learn From Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data
Jun 14, 2020

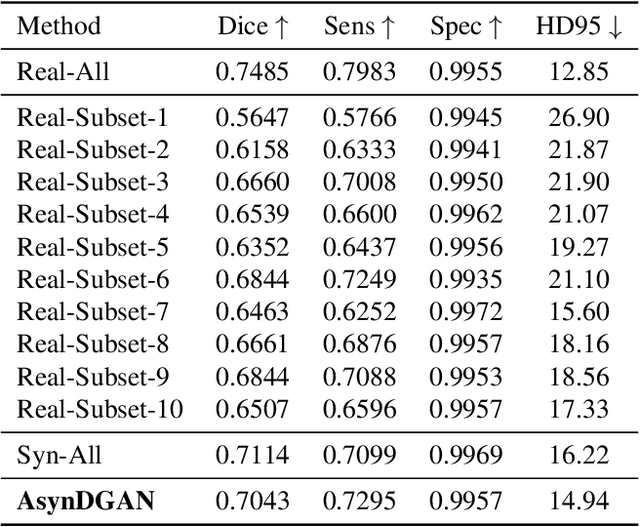
In this paper, we propose a data privacy-preserving and communication efficient distributed GAN learning framework named Distributed Asynchronized Discriminator GAN (AsynDGAN). Our proposed framework aims to train a central generator learns from distributed discriminator, and use the generated synthetic image solely to train the segmentation model.We validate the proposed framework on the application of health entities learning problem which is known to be privacy sensitive. Our experiments show that our approach: 1) could learn the real image's distribution from multiple datasets without sharing the patient's raw data. 2) is more efficient and requires lower bandwidth than other distributed deep learning methods. 3) achieves higher performance compared to the model trained by one real dataset, and almost the same performance compared to the model trained by all real datasets. 4) has provable guarantees that the generator could learn the distributed distribution in an all important fashion thus is unbiased.
Non-Local Graph-Based Prediction For Reversible Data Hiding In Images
Feb 20, 2018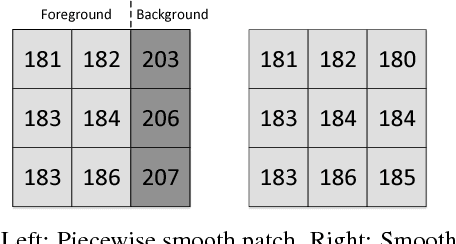
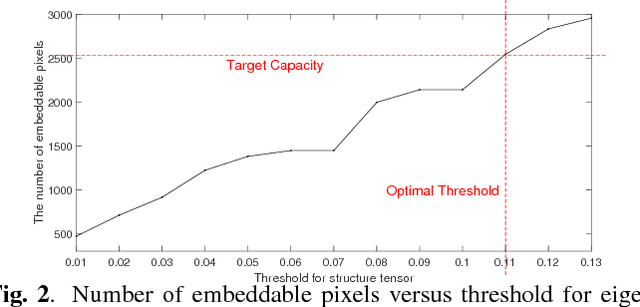
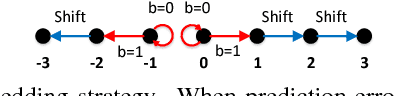
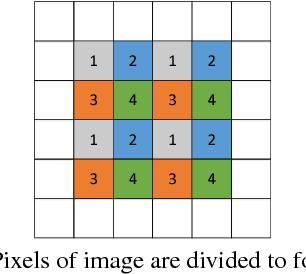
Reversible data hiding (RDH) is desirable in applications where both the hidden message and the cover medium need to be recovered without loss. Among many RDH approaches is prediction-error expansion (PEE), containing two steps: i) prediction of a target pixel value, and ii) embedding according to the value of prediction-error. In general, higher prediction performance leads to larger embedding capacity and/or lower signal distortion. Leveraging on recent advances in graph signal processing (GSP), we pose pixel prediction as a graph-signal restoration problem, where the appropriate edge weights of the underlying graph are computed using a similar patch searched in a semi-local neighborhood. Specifically, for each candidate patch, we first examine eigenvalues of its structure tensor to estimate its local smoothness. If sufficiently smooth, we pose a maximum a posteriori (MAP) problem using either a quadratic Laplacian regularizer or a graph total variation (GTV) term as signal prior. While the MAP problem using the first prior has a closed-form solution, we design an efficient algorithm for the second prior using alternating direction method of multipliers (ADMM) with nested proximal gradient descent. Experimental results show that with better quality GSP-based prediction, at low capacity the visual quality of the embedded image exceeds state-of-the-art methods noticeably.