 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCO: A Large Scale Human Annotated Corpus for Disfluency Correction in Indo-European Languages
Oct 25, 2023Disfluency correction (DC) is the process of removing disfluent elements like fillers, repetitions and corrections from spoken utterances to create readable and interpretable text. DC is a vital post-processing step applied to Automatic Speech Recognition (ASR) outputs, before subsequent processing by downstream language understanding tasks. Existing DC research has primarily focused on English due to the unavailability of large-scale open-source datasets. Towards the goal of multilingual disfluency correction, we present a high-quality human-annotated DC corpus covering four important Indo-European languages: English, Hindi, German and French. We provide extensive analysis of results of state-of-the-art DC models across all four languages obtaining F1 scores of 97.55 (English), 94.29 (Hindi), 95.89 (German) and 92.97 (French). To demonstrate the benefits of DC on downstream tasks, we show that DC leads to 5.65 points increase in BLEU scores on average when used in conjunction with a state-of-the-art Machine Translation (MT) system. We release code to run our experiments along with our annotated dataset here.
Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection
Sep 29, 2023



The introduction of the MUStARD dataset, and its emotion recognition extension MUStARD++, have identified sarcasm to be a multi-modal phenomenon -- expressed not only in natural language text, but also through manners of speech (like tonality and intonation) and visual cues (facial expression). With this work, we aim to perform a rigorous benchmarking of the MUStARD++ dataset by considering state-of-the-art language, speech, and visual encoders, for fully utilizing the totality of the multi-modal richness that it has to offer, achieving a 2\% improvement in macro-F1 over the existing benchmark. Additionally, to cure the imbalance in the `sarcasm type' category in MUStARD++, we propose an extension, which we call \emph{MUStARD++ Balanced}, benchmarking the same with instances from the extension split across both train and test sets, achieving a further 2.4\% macro-F1 boost. The new clips were taken from a novel source -- the TV show, House MD, which adds to the diversity of the dataset, and were manually annotated by multiple annotators with substantial inter-annotator agreement in terms of Cohen's kappa and Krippendorf's alpha. Our code, extended data, and SOTA benchmark models are made public.
Experience and Evidence are the eyes of an excellent summarizer! Towards Knowledge Infused Multi-modal Clinical Conversation Summarization
Sep 27, 2023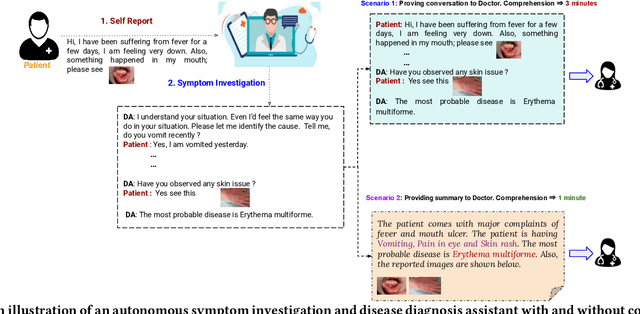

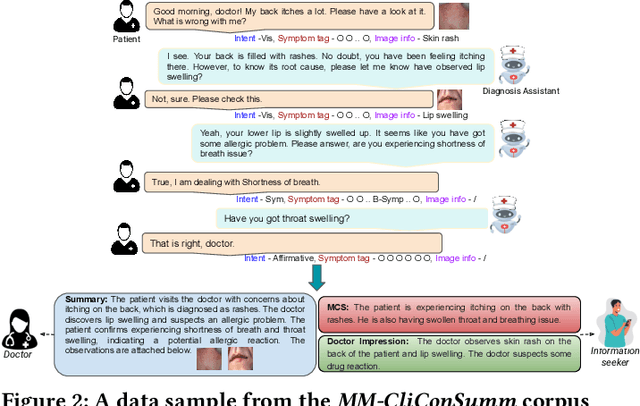
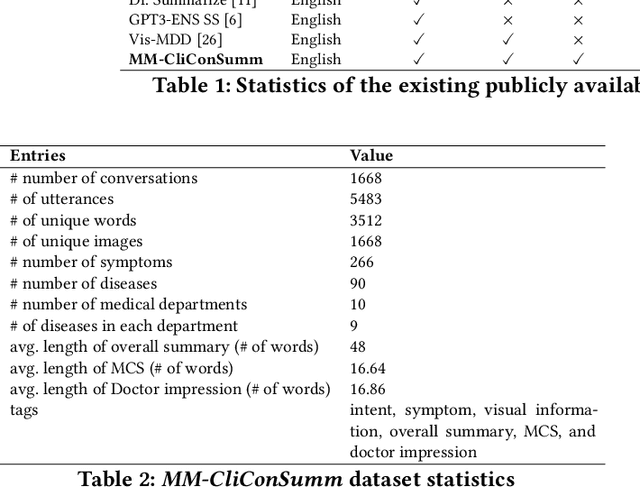
With the advancement of telemedicine, both researchers and medical practitioners are working hand-in-hand to develop various techniques to automate various medical operations, such as diagnosis report generation. In this paper, we first present a multi-modal clinical conversation summary generation task that takes a clinician-patient interaction (both textual and visual information) and generates a succinct synopsis of the conversation. We propose a knowledge-infused, multi-modal, multi-tasking medical domain identification and clinical conversation summary generation (MM-CliConSummation) framework. It leverages an adapter to infuse knowledge and visual features and unify the fused feature vector using a gated mechanism. Furthermore, we developed a multi-modal, multi-intent clinical conversation summarization corpus annotated with intent, symptom, and summary. The extensive set of experiments, both quantitatively and qualitatively, led to the following findings: (a) critical significance of visuals, (b) more precise and medical entity preserving summary with additional knowledge infusion, and (c) a correlation between medical department identification and clinical synopsis generation. Furthermore, the dataset and source code are available at https://github.com/NLP-RL/MM-CliConSummation.
Hi Model, generating 'nice' instead of 'good' is not as bad as generating 'rice'! Towards Context and Semantic Infused Dialogue Generation Loss Function and Evaluation Metric
Sep 11, 2023Over the past two decades, dialogue modeling has made significant strides, moving from simple rule-based responses to personalized and persuasive response generation. However, despite these advancements, the objective functions and evaluation metrics for dialogue generation have remained stagnant, i.e., cross-entropy and BLEU, respectively. These lexical-based metrics have the following key limitations: (a) word-to-word matching without semantic consideration: It assigns the same credit for failure to generate 'nice' and 'rice' for 'good'. (b) missing context attribute for evaluating the generated response: Even if a generated response is relevant to the ongoing dialogue context, it may still be penalized for not matching the gold utterance provided in the corpus. In this paper, we first investigate these limitations comprehensively and propose a new loss function called Semantic Infused Contextualized diaLogue (SemTextualLogue) loss function. Furthermore, we formulate a new evaluation metric called Dialuation, which incorporates both context relevance and semantic appropriateness while evaluating a generated response. We conducted experiments on two benchmark dialogue corpora, encompassing both task-oriented and open-domain scenarios. We found that the dialogue generation model trained with SemTextualLogue loss attained superior performance (in both quantitative and qualitative evaluation) compared to the traditional cross-entropy loss function across the datasets and evaluation metrics.
"Beware of deception": Detecting Half-Truth and Debunking it through Controlled Claim Editing
Aug 15, 2023



The prevalence of half-truths, which are statements containing some truth but that are ultimately deceptive, has risen with the increasing use of the internet. To help combat this problem, we have created a comprehensive pipeline consisting of a half-truth detection model and a claim editing model. Our approach utilizes the T5 model for controlled claim editing; "controlled" here means precise adjustments to select parts of a claim. Our methodology achieves an average BLEU score of 0.88 (on a scale of 0-1) and a disinfo-debunk score of 85% on edited claims. Significantly, our T5-based approach outperforms other Language Models such as GPT2, RoBERTa, PEGASUS, and Tailor, with average improvements of 82%, 57%, 42%, and 23% in disinfo-debunk scores, respectively. By extending the LIAR PLUS dataset, we achieve an F1 score of 82% for the half-truth detection model, setting a new benchmark in the field. While previous attempts have been made at half-truth detection, our approach is, to the best of our knowledge, the first to attempt to debunk half-truths.
KITLM: Domain-Specific Knowledge InTegration into Language Models for Question Answering
Aug 07, 2023



Large language models (LLMs) have demonstrated remarkable performance in a wide range of natural language tasks. However, as these models continue to grow in size, they face significant challenges in terms of computational costs. Additionally, LLMs often lack efficient domain-specific understanding, which is particularly crucial in specialized fields such as aviation and healthcare. To boost the domain-specific understanding, we propose, KITLM, a novel knowledge base integration approach into language model through relevant information infusion. By integrating pertinent knowledge, not only the performance of the language model is greatly enhanced, but the model size requirement is also significantly reduced while achieving comparable performance. Our proposed knowledge-infused model surpasses the performance of both GPT-3.5-turbo and the state-of-the-art knowledge infusion method, SKILL, achieving over 1.5 times improvement in exact match scores on the MetaQA. KITLM showed a similar performance boost in the aviation domain with AeroQA. The drastic performance improvement of KITLM over the existing methods can be attributed to the infusion of relevant knowledge while mitigating noise. In addition, we release two curated datasets to accelerate knowledge infusion research in specialized fields: a) AeroQA, a new benchmark dataset designed for multi-hop question-answering within the aviation domain, and b) Aviation Corpus, a dataset constructed from unstructured text extracted from the National Transportation Safety Board reports. Our research contributes to advancing the field of domain-specific language understanding and showcases the potential of knowledge infusion techniques in improving the performance of language models on question-answering.
Decision Knowledge Graphs: Construction of and Usage in Question Answering for Clinical Practice Guidelines
Aug 06, 2023In the medical domain, several disease treatment procedures have been documented properly as a set of instructions known as Clinical Practice Guidelines (CPGs). CPGs have been developed over the years on the basis of past treatments, and are updated frequently. A doctor treating a particular patient can use these CPGs to know how past patients with similar conditions were treated successfully and can find the recommended treatment procedure. In this paper, we present a Decision Knowledge Graph (DKG) representation to store CPGs and to perform question-answering on CPGs. CPGs are very complex and no existing representation is suitable to perform question-answering and searching tasks on CPGs. As a result, doctors and practitioners have to manually wade through the guidelines, which is inefficient. Representation of CPGs is challenging mainly due to frequent updates on CPGs and decision-based structure. Our proposed DKG has a decision dimension added to a Knowledge Graph (KG) structure, purported to take care of decision based behavior of CPGs. Using this DKG has shown 40\% increase in accuracy compared to fine-tuned BioBert model in performing question-answering on CPGs. To the best of our knowledge, ours is the first attempt at creating DKGs and using them for representing CPGs.
"Kurosawa": A Script Writer's Assistant
Aug 06, 2023Storytelling is the lifeline of the entertainment industry -- movies, TV shows, and stand-up comedies, all need stories. A good and gripping script is the lifeline of storytelling and demands creativity and resource investment. Good scriptwriters are rare to find and often work under severe time pressure. Consequently, entertainment media are actively looking for automation. In this paper, we present an AI-based script-writing workbench called KUROSAWA which addresses the tasks of plot generation and script generation. Plot generation aims to generate a coherent and creative plot (600-800 words) given a prompt (15-40 words). Script generation, on the other hand, generates a scene (200-500 words) in a screenplay format from a brief description (15-40 words). Kurosawa needs data to train. We use a 4-act structure of storytelling to annotate the plot dataset manually. We create a dataset of 1000 manually annotated plots and their corresponding prompts/storylines and a gold-standard dataset of 1000 scenes with four main elements -- scene headings, action lines, dialogues, and character names -- tagged individually. We fine-tune GPT-3 with the above datasets to generate plots and scenes. These plots and scenes are first evaluated and then used by the scriptwriters of a large and famous media platform ErosNow. We release the annotated datasets and the models trained on these datasets as a working benchmark for automatic movie plot and script generation.
"We care": Improving Code Mixed Speech Emotion Recognition in Customer-Care Conversations
Aug 06, 2023Speech Emotion Recognition (SER) is the task of identifying the emotion expressed in a spoken utterance. Emotion recognition is essential in building robust conversational agents in domains such as law, healthcare, education, and customer support. Most of the studies published on SER use datasets created by employing professional actors in a noise-free environment. In natural settings such as a customer care conversation, the audio is often noisy with speakers regularly switching between different languages as they see fit. We have worked in collaboration with a leading unicorn in the Conversational AI sector to develop Natural Speech Emotion Dataset (NSED). NSED is a natural code-mixed speech emotion dataset where each utterance in a conversation is annotated with emotion, sentiment, valence, arousal, and dominance (VAD) values. In this paper, we show that by incorporating word-level VAD value we improve on the task of SER by 2%, for negative emotions, over the baseline value for NSED. High accuracy for negative emotion recognition is essential because customers expressing negative opinions/views need to be pacified with urgency, lest complaints and dissatisfaction snowball and get out of hand. Escalation of negative opinions speedily is crucial for business interests. Our study then can be utilized to develop conversational agents which are more polite and empathetic in such situations.
Adversarial Training For Low-Resource Disfluency Correction
Jun 10, 2023Disfluencies commonly occur in conversational speech. Speech with disfluencies can result in noisy Automatic Speech Recognition (ASR) transcripts, which affects downstream tasks like machine translation. In this paper, we propose an adversarially-trained sequence-tagging model for Disfluency Correction (DC) that utilizes a small amount of labeled real disfluent data in conjunction with a large amount of unlabeled data. We show the benefit of our proposed technique, which crucially depends on synthetically generated disfluent data, by evaluating it for DC in three Indian languages- Bengali, Hindi, and Marathi (all from the Indo-Aryan family). Our technique also performs well in removing stuttering disfluencies in ASR transcripts introduced by speech impairments. We achieve an average 6.15 points improvement in F1-score over competitive baselines across all three languages mentioned. To the best of our knowledge, we are the first to utilize adversarial training for DC and use it to correct stuttering disfluencies in English, establishing a new benchmark for this task.