 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo eyes, Two views, and finally, One summary! Towards Multi-modal Multi-tasking Knowledge-Infused Medical Dialogue Summarization
Jul 21, 2024

We often summarize a multi-party conversation in two stages: chunking with homogeneous units and summarizing the chunks. Thus, we hypothesize that there exists a correlation between homogeneous speaker chunking and overall summarization tasks. In this work, we investigate the effectiveness of a multi-faceted approach that simultaneously produces summaries of medical concerns, doctor impressions, and an overall view. We introduce a multi-modal, multi-tasking, knowledge-infused medical dialogue summary generation (MMK-Summation) model, which is incorporated with adapter-based fine-tuning through a gated mechanism for multi-modal information integration. The model, MMK-Summation, takes dialogues as input, extracts pertinent external knowledge based on the context, integrates the knowledge and visual cues from the dialogues into the textual content, and ultimately generates concise summaries encompassing medical concerns, doctor impressions, and a comprehensive overview. The introduced model surpasses multiple baselines and traditional summarization models across all evaluation metrics (including human evaluation), which firmly demonstrates the efficacy of the knowledge-guided multi-tasking, multimodal medical conversation summarization. The code is available at https://github.com/NLP-RL/MMK-Summation.
Towards Knowledge-Infused Automated Disease Diagnosis Assistant
May 18, 2024With the advancement of internet communication and telemedicine, people are increasingly turning to the web for various healthcare activities. With an ever-increasing number of diseases and symptoms, diagnosing patients becomes challenging. In this work, we build a diagnosis assistant to assist doctors, which identifies diseases based on patient-doctor interaction. During diagnosis, doctors utilize both symptomatology knowledge and diagnostic experience to identify diseases accurately and efficiently. Inspired by this, we investigate the role of medical knowledge in disease diagnosis through doctor-patient interaction. We propose a two-channel, knowledge-infused, discourse-aware disease diagnosis model (KI-DDI), where the first channel encodes patient-doctor communication using a transformer-based encoder, while the other creates an embedding of symptom-disease using a graph attention network (GAT). In the next stage, the conversation and knowledge graph embeddings are infused together and fed to a deep neural network for disease identification. Furthermore, we first develop an empathetic conversational medical corpus comprising conversations between patients and doctors, annotated with intent and symptoms information. The proposed model demonstrates a significant improvement over the existing state-of-the-art models, establishing the crucial roles of (a) a doctor's effort for additional symptom extraction (in addition to patient self-report) and (b) infusing medical knowledge in identifying diseases effectively. Many times, patients also show their medical conditions, which acts as crucial evidence in diagnosis. Therefore, integrating visual sensory information would represent an effective avenue for enhancing the capabilities of diagnostic assistants.
An EcoSage Assistant: Towards Building A Multimodal Plant Care Dialogue Assistant
Jan 10, 2024In recent times, there has been an increasing awareness about imminent environmental challenges, resulting in people showing a stronger dedication to taking care of the environment and nurturing green life. The current $19.6 billion indoor gardening industry, reflective of this growing sentiment, not only signifies a monetary value but also speaks of a profound human desire to reconnect with the natural world. However, several recent surveys cast a revealing light on the fate of plants within our care, with more than half succumbing primarily due to the silent menace of improper care. Thus, the need for accessible expertise capable of assisting and guiding individuals through the intricacies of plant care has become paramount more than ever. In this work, we make the very first attempt at building a plant care assistant, which aims to assist people with plant(-ing) concerns through conversations. We propose a plant care conversational dataset named Plantational, which contains around 1K dialogues between users and plant care experts. Our end-to-end proposed approach is two-fold : (i) We first benchmark the dataset with the help of various large language models (LLMs) and visual language model (VLM) by studying the impact of instruction tuning (zero-shot and few-shot prompting) and fine-tuning techniques on this task; (ii) finally, we build EcoSage, a multi-modal plant care assisting dialogue generation framework, incorporating an adapter-based modality infusion using a gated mechanism. We performed an extensive examination (both automated and manual evaluation) of the performance exhibited by various LLMs and VLM in the generation of the domain-specific dialogue responses to underscore the respective strengths and weaknesses of these diverse models.
Yes, this is what I was looking for! Towards Multi-modal Medical Consultation Concern Summary Generation
Jan 10, 2024Over the past few years, the use of the Internet for healthcare-related tasks has grown by leaps and bounds, posing a challenge in effectively managing and processing information to ensure its efficient utilization. During moments of emotional turmoil and psychological challenges, we frequently turn to the internet as our initial source of support, choosing this over discussing our feelings with others due to the associated social stigma. In this paper, we propose a new task of multi-modal medical concern summary (MMCS) generation, which provides a short and precise summary of patients' major concerns brought up during the consultation. Nonverbal cues, such as patients' gestures and facial expressions, aid in accurately identifying patients' concerns. Doctors also consider patients' personal information, such as age and gender, in order to describe the medical condition appropriately. Motivated by the potential efficacy of patients' personal context and visual gestures, we propose a transformer-based multi-task, multi-modal intent-recognition, and medical concern summary generation (IR-MMCSG) system. Furthermore, we propose a multitasking framework for intent recognition and medical concern summary generation for doctor-patient consultations. We construct the first multi-modal medical concern summary generation (MM-MediConSummation) corpus, which includes patient-doctor consultations annotated with medical concern summaries, intents, patient personal information, doctor's recommendations, and keywords. Our experiments and analysis demonstrate (a) the significant role of patients' expressions/gestures and their personal information in intent identification and medical concern summary generation, and (b) the strong correlation between intent recognition and patients' medical concern summary generation The dataset and source code are available at https://github.com/NLP-RL/MMCSG.
Experience and Evidence are the eyes of an excellent summarizer! Towards Knowledge Infused Multi-modal Clinical Conversation Summarization
Sep 27, 2023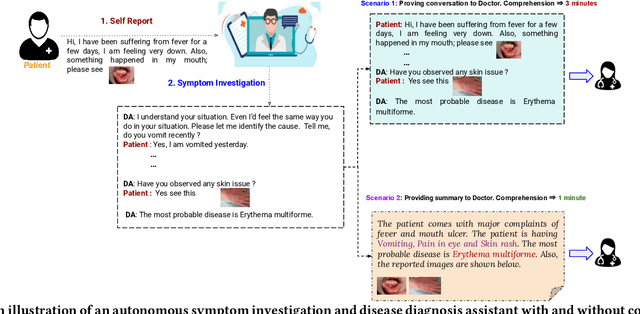

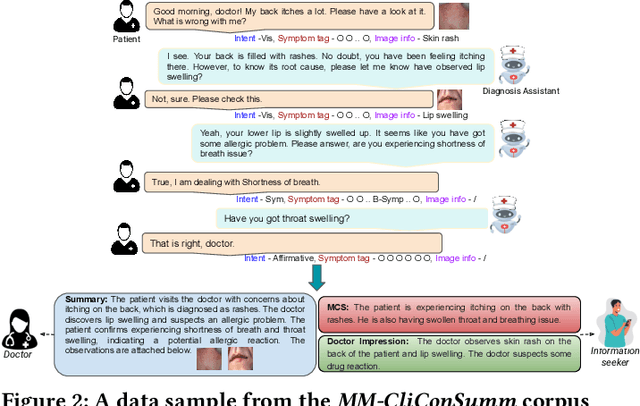
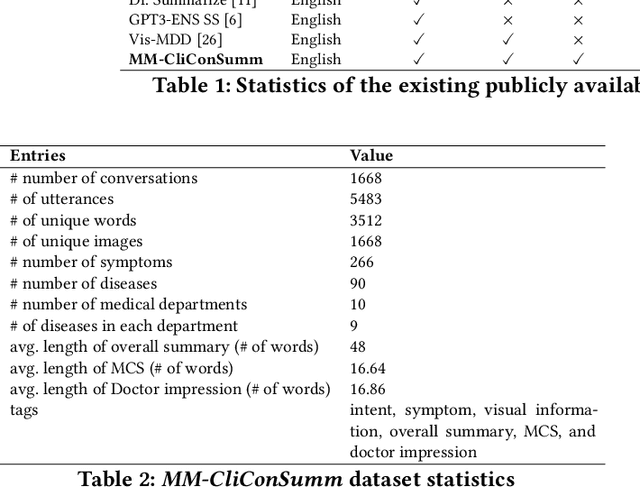
With the advancement of telemedicine, both researchers and medical practitioners are working hand-in-hand to develop various techniques to automate various medical operations, such as diagnosis report generation. In this paper, we first present a multi-modal clinical conversation summary generation task that takes a clinician-patient interaction (both textual and visual information) and generates a succinct synopsis of the conversation. We propose a knowledge-infused, multi-modal, multi-tasking medical domain identification and clinical conversation summary generation (MM-CliConSummation) framework. It leverages an adapter to infuse knowledge and visual features and unify the fused feature vector using a gated mechanism. Furthermore, we developed a multi-modal, multi-intent clinical conversation summarization corpus annotated with intent, symptom, and summary. The extensive set of experiments, both quantitatively and qualitatively, led to the following findings: (a) critical significance of visuals, (b) more precise and medical entity preserving summary with additional knowledge infusion, and (c) a correlation between medical department identification and clinical synopsis generation. Furthermore, the dataset and source code are available at https://github.com/NLP-RL/MM-CliConSummation.
Hi Model, generating 'nice' instead of 'good' is not as bad as generating 'rice'! Towards Context and Semantic Infused Dialogue Generation Loss Function and Evaluation Metric
Sep 11, 2023Over the past two decades, dialogue modeling has made significant strides, moving from simple rule-based responses to personalized and persuasive response generation. However, despite these advancements, the objective functions and evaluation metrics for dialogue generation have remained stagnant, i.e., cross-entropy and BLEU, respectively. These lexical-based metrics have the following key limitations: (a) word-to-word matching without semantic consideration: It assigns the same credit for failure to generate 'nice' and 'rice' for 'good'. (b) missing context attribute for evaluating the generated response: Even if a generated response is relevant to the ongoing dialogue context, it may still be penalized for not matching the gold utterance provided in the corpus. In this paper, we first investigate these limitations comprehensively and propose a new loss function called Semantic Infused Contextualized diaLogue (SemTextualLogue) loss function. Furthermore, we formulate a new evaluation metric called Dialuation, which incorporates both context relevance and semantic appropriateness while evaluating a generated response. We conducted experiments on two benchmark dialogue corpora, encompassing both task-oriented and open-domain scenarios. We found that the dialogue generation model trained with SemTextualLogue loss attained superior performance (in both quantitative and qualitative evaluation) compared to the traditional cross-entropy loss function across the datasets and evaluation metrics.