 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Batch Normalisation for Approximate Bayesian Inference
Dec 24, 2020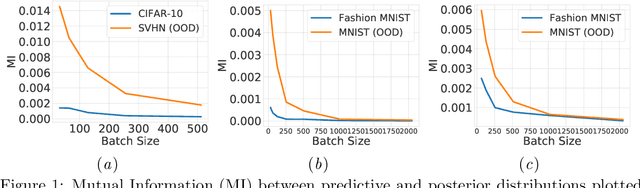
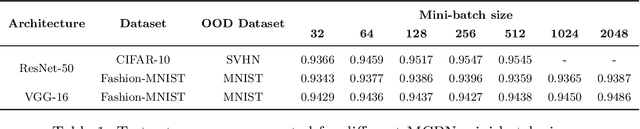
We study batch normalisation in the context of variational inference methods in Bayesian neural networks, such as mean-field or MC Dropout. We show that batch-normalisation does not affect the optimum of the evidence lower bound (ELBO). Furthermore, we study the Monte Carlo Batch Normalisation (MCBN) algorithm, proposed as an approximate inference technique parallel to MC Dropout, and show that for larger batch sizes, MCBN fails to capture epistemic uncertainty. Finally, we provide insights into what is required to fix this failure, namely having to view the mini-batch size as a variational parameter in MCBN. We comment on the asymptotics of the ELBO with respect to this variational parameter, showing that as dataset size increases towards infinity, the batch-size must increase towards infinity as well for MCBN to be a valid approximate inference technique.
Continual Learning in Low-rank Orthogonal Subspaces
Oct 22, 2020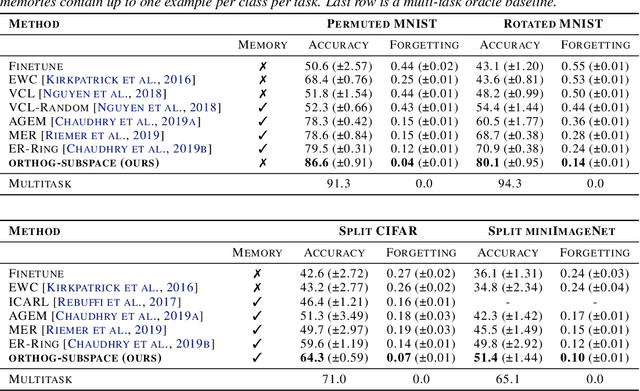

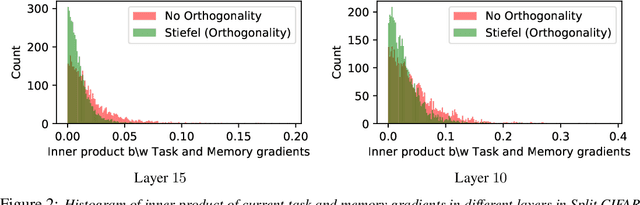
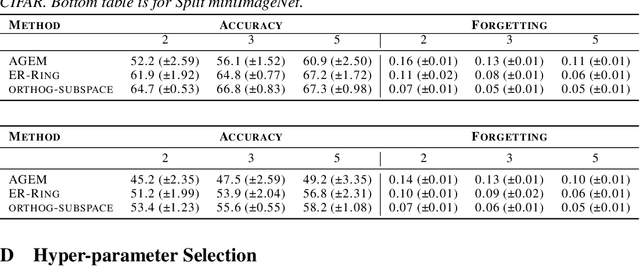
In continual learning (CL), a learner is faced with a sequence of tasks, arriving one after the other, and the goal is to remember all the tasks once the continual learning experience is finished. The prior art in CL uses episodic memory, parameter regularization or extensible network structures to reduce interference among tasks, but in the end, all the approaches learn different tasks in a joint vector space. We believe this invariably leads to interference among different tasks. We propose to learn tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Further, to keep the gradients of different tasks coming from these subspaces orthogonal to each other, we learn isometric mappings by posing network training as an optimization problem over the Stiefel manifold. To the best of our understanding, we report, for the first time, strong results over experience-replay baseline with and without memory on standard classification benchmarks in continual learning. The code is made publicly available.
* The paper is accepted at NeurIPS'20
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020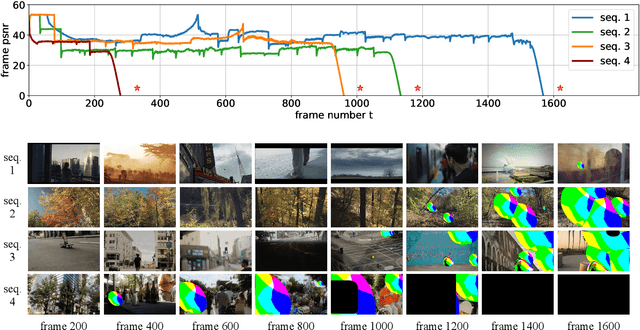
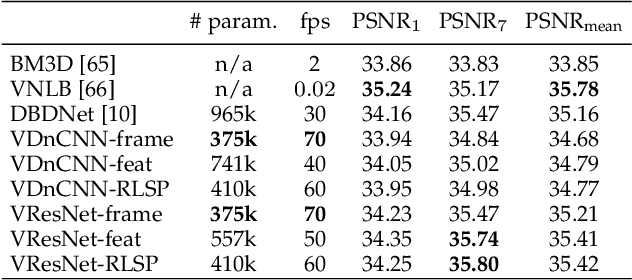
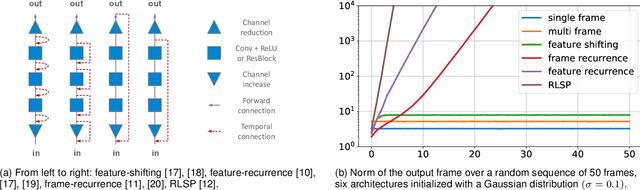
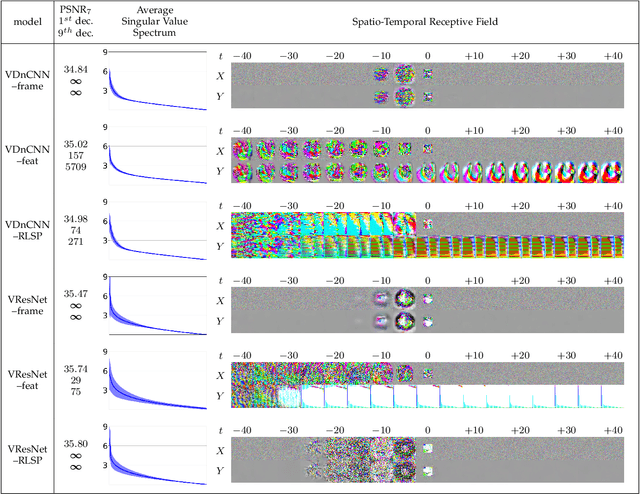
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.
Progressive Skeletonization: Trimming more fat from a network at initialization
Jul 14, 2020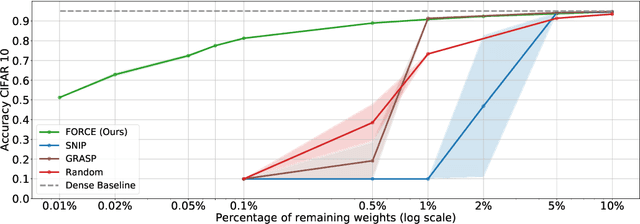
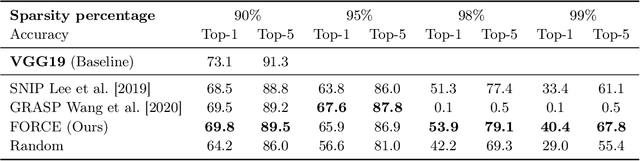
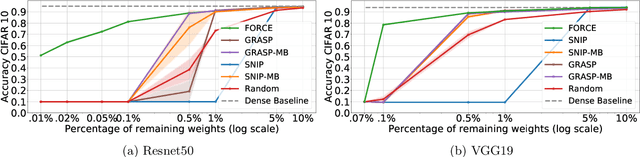
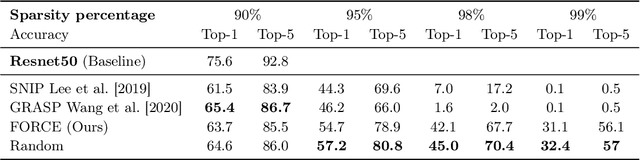
Recent studies have shown that skeletonization (pruning parameters) of networks at initialization provides all the practical benefits of sparsity both at inference and training time, while only marginally degrading their performance. However, we observe that beyond a certain level of sparsity (approx 95%), these approaches fail to preserve the network performance, and to our surprise, in many cases perform even worse than trivial random pruning. To this end, we propose to find a skeletonized network with maximum foresight connection sensitivity (FORCE). Intuitively, out of all possible sub-networks, we propose to find the one whose connections would have a maximum impact on the loss when perturbed. Our approximate solution to maximize the FORCE, progressively prunes connections of a given network at initialization. This allows parameters that were unimportant at earlier stages of skeletonization to become important at later stages. In many cases, our approach enables us to remove up to 99.9% parameters, while keeping networks trainable and providing significantly better performance than recent approaches. We demonstrate the effectiveness of our approach at various levels of sparsity (from medium to extreme) through extensive experiments and analysis. Code can be found in https://github.com/naver/force.
A Revised Generative Evaluation of Visual Dialogue
Apr 24, 2020
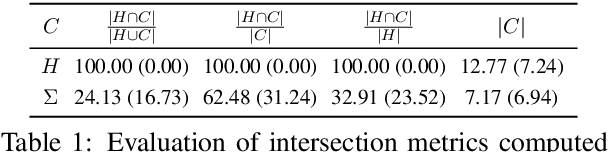
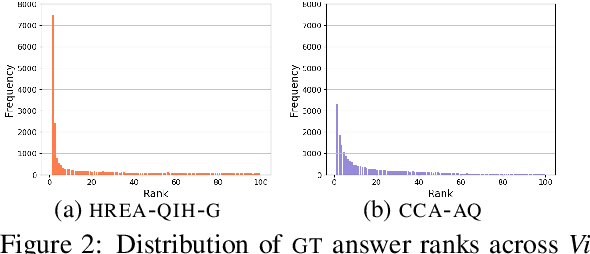
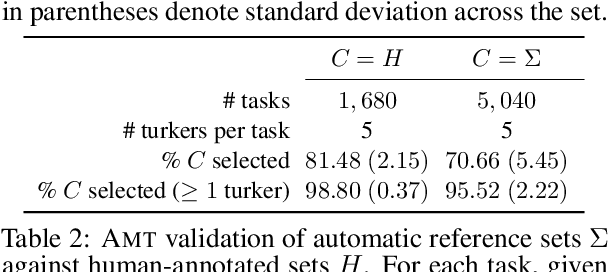
Evaluating Visual Dialogue, the task of answering a sequence of questions relating to a visual input, remains an open research challenge. The current evaluation scheme of the VisDial dataset computes the ranks of ground-truth answers in predefined candidate sets, which Massiceti et al. (2018) show can be susceptible to the exploitation of dataset biases. This scheme also does little to account for the different ways of expressing the same answer--an aspect of language that has been well studied in NLP. We propose a revised evaluation scheme for the VisDial dataset leveraging metrics from the NLP literature to measure consensus between answers generated by the model and a set of relevant answers. We construct these relevant answer sets using a simple and effective semi-supervised method based on correlation, which allows us to automatically extend and scale sparse relevance annotations from humans to the entire dataset. We release these sets and code for the revised evaluation scheme as DenseVisDial, and intend them to be an improvement to the dataset in the face of its existing constraints and design choices.
Calibrating Deep Neural Networks using Focal Loss
Feb 21, 2020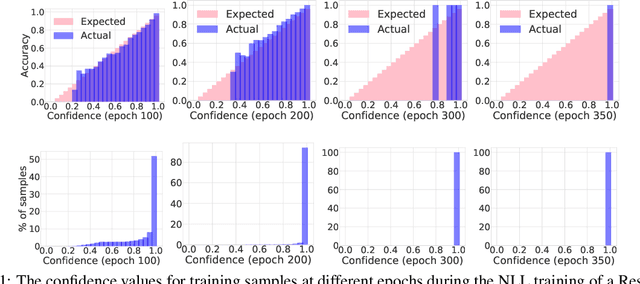
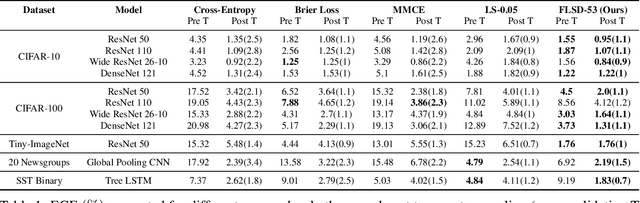
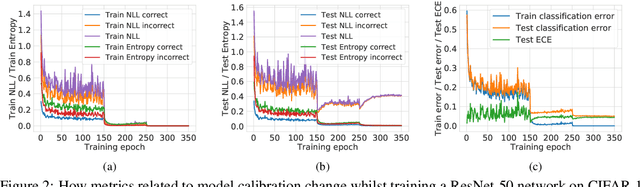
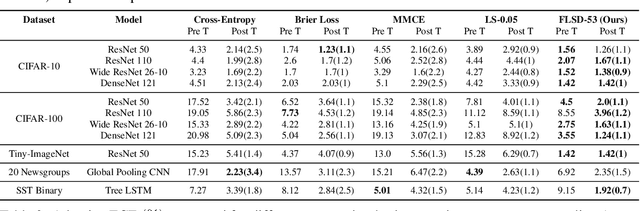
Miscalibration -- a mismatch between a model's confidence and its correctness -- of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss (Lin et al., 2017) allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art accuracy and calibration in almost all cases.
Using Hindsight to Anchor Past Knowledge in Continual Learning
Feb 19, 2020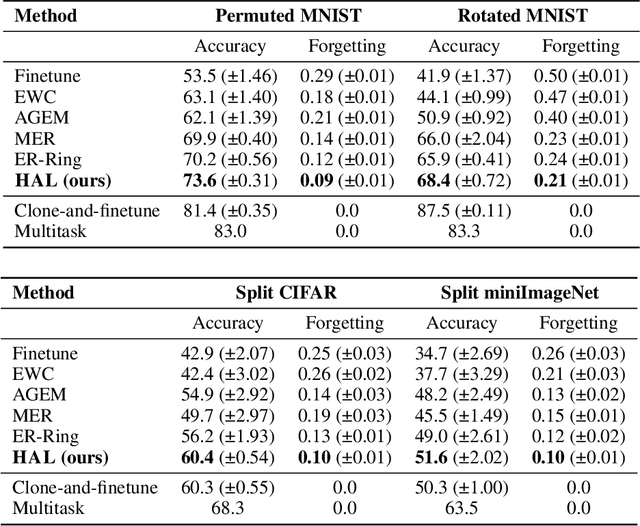
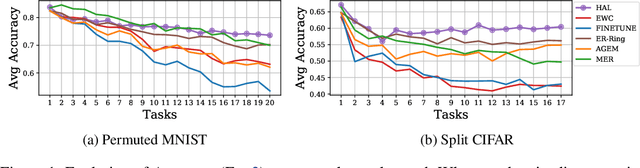
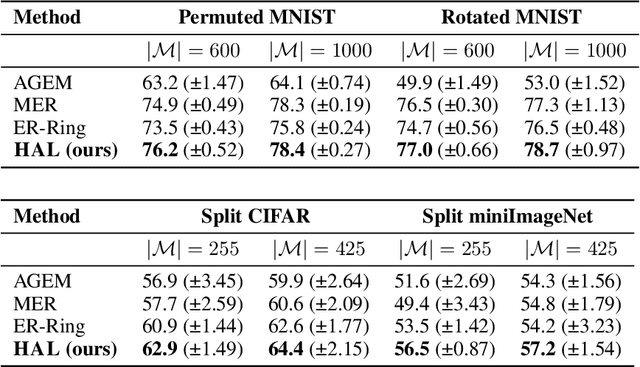
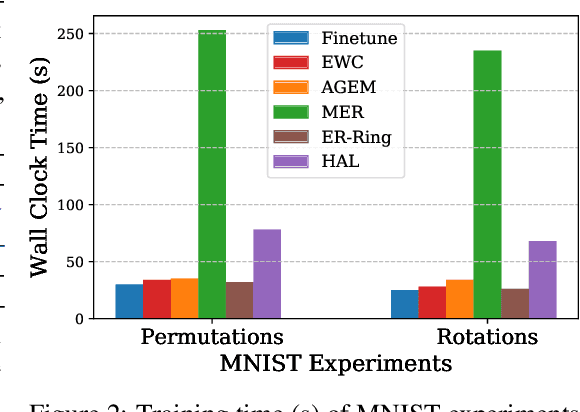
In continual learning, the learner faces a stream of data whose distribution changes over time. Modern neural networks are known to suffer under this setting, as they quickly forget previously acquired knowledge. To address such catastrophic forgetting, many continual learning methods implement different types of experience replay, re-learning on past data stored in a small buffer known as episodic memory. In this work, we complement experience replay with a new objective that we call anchoring, where the learner uses bilevel optimization to update its knowledge on the current task, while keeping intact the predictions on some anchor points of past tasks. These anchor points are learned using gradient-based optimization to maximize forgetting, which is approximated by fine-tuning the currently trained model on the episodic memory of past tasks. Experiments on several supervised learning benchmarks for continual learning demonstrate that our approach improves the standard experience replay in terms of both accuracy and forgetting metrics and for various sizes of episodic memories.
Mirror Descent View for Neural Network Quantization
Oct 18, 2019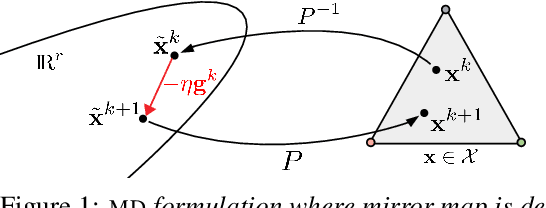
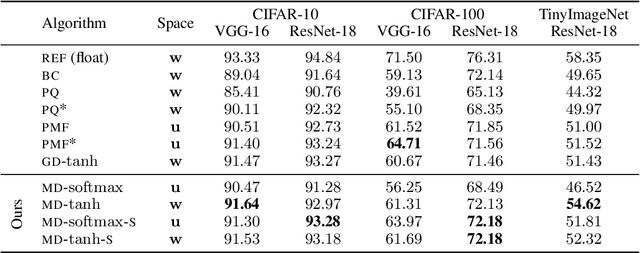
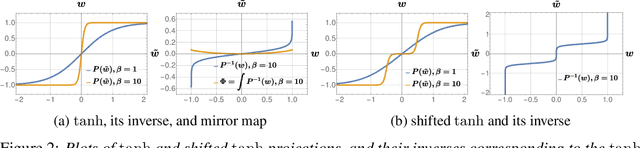
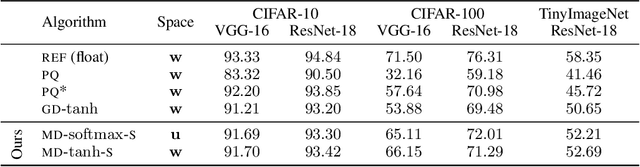
Quantizing large Neural Networks (NN) while maintaining the performance is highly desirable for resource-limited devices due to reduced memory and time complexity. NN quantization is usually formulated as a constrained optimization problem and optimized via a modified version of gradient descent. In this work, by interpreting the continuous parameters (unconstrained) as the dual of the quantized ones, we introduce a Mirror Descent (MD) framework (Bubeck (2015)) for NN quantization. Specifically, we provide conditions on the projections (i.e., mapping from continuous to quantized ones) which would enable us to derive valid mirror maps and in turn the respective MD updates. Furthermore, we discuss a numerically stable implementation of MD by storing an additional set of auxiliary dual variables (continuous). This update is strikingly analogous to the popular Straight Through Estimator (STE) based method which is typically viewed as a "trick" to avoid vanishing gradients issue but here we show that it is an implementation method for MD for certain projections. Our experiments on standard classification datasets (CIFAR-10/100, TinyImageNet) with convolutional and residual architectures show that our MD variants obtain fully-quantized networks with accuracies very close to the floating-point networks.
Interactive Sketch & Fill: Multiclass Sketch-to-Image Translation
Sep 25, 2019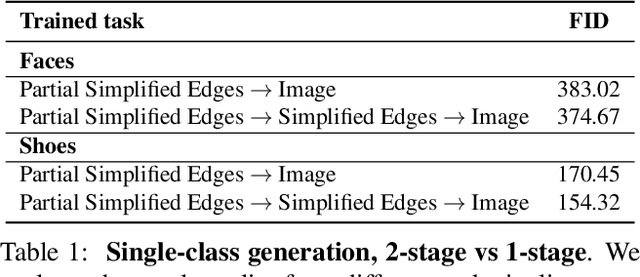


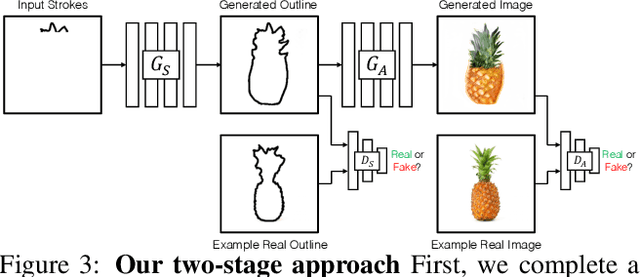
We propose an interactive GAN-based sketch-to-image translation method that helps novice users create images of simple objects. As the user starts to draw a sketch of a desired object type, the network interactively recommends plausible completions, and shows a corresponding synthesized image to the user. This enables a feedback loop, where the user can edit their sketch based on the network's recommendations, visualizing both the completed shape and final rendered image while they draw. In order to use a single trained model across a wide array of object classes, we introduce a gating-based approach for class conditioning, which allows us to generate distinct classes without feature mixing, from a single generator network. Video available at our website: https://arnabgho.github.io/iSketchNFill/.
Stable Rank Normalization for Improved Generalization in Neural Networks and GANs
Jun 12, 2019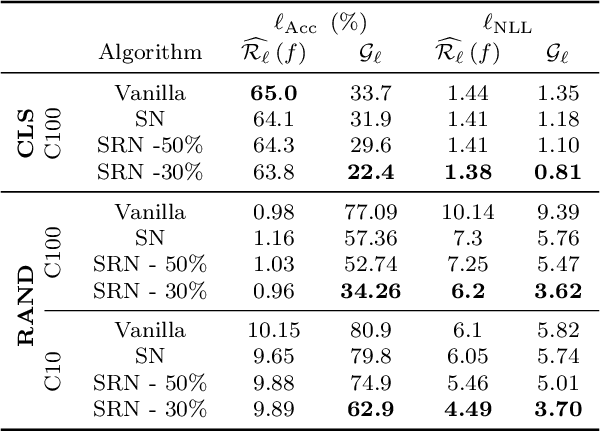
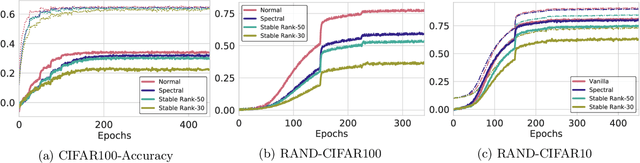
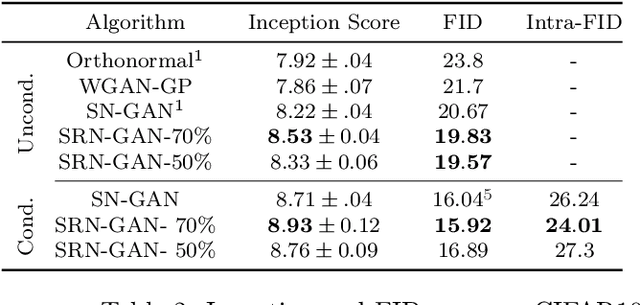
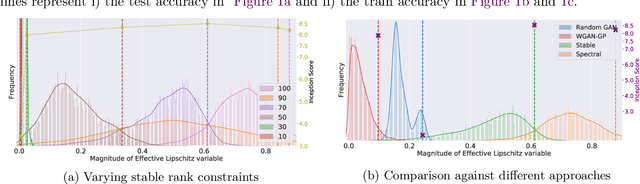
Exciting new work on the generalization bounds for neural networks (NN) given by Neyshabur et al. , Bartlett et al. closely depend on two parameter-depenedent quantities: the Lipschitz constant upper-bound and the stable rank (a softer version of the rank operator). This leads to an interesting question of whether controlling these quantities might improve the generalization behaviour of NNs. To this end, we propose stable rank normalization (SRN), a novel, optimal, and computationally efficient weight-normalization scheme which minimizes the stable rank of a linear operator. Surprisingly we find that SRN, inspite of being non-convex problem, can be shown to have a unique optimal solution. Moreover, we show that SRN allows control of the data-dependent empirical Lipschitz constant, which in contrast to the Lipschitz upper-bound, reflects the true behaviour of a model on a given dataset. We provide thorough analyses to show that SRN, when applied to the linear layers of a NN for classification, provides striking improvements-11.3% on the generalization gap compared to the standard NN along with significant reduction in memorization. When applied to the discriminator of GANs (called SRN-GAN) it improves Inception, FID, and Neural divergence scores on the CIFAR 10/100 and CelebA datasets, while learning mappings with low empirical Lipschitz constants.