 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenZL: Using Graphs to Compress Smaller and Faster
May 11, 2026In the last few decades, research techniques have improved lossless compression ratios by significantly increasing processing time. However, these techniques have not gained popularity in industry because production systems require high throughput and low resource utilization. Instead, real world improvements in compression are increasingly realized by building application-specific compressors which can exploit knowledge about the structure and semantics of the data being compressed. Application-specific compressor systems outperform even the best generic compressors, but these techniques have severe drawbacks -- they are inherently limited in applicability, are hard to develop, and are difficult to maintain and deploy. In this work, we show that these challenges can be overcome with a new compression strategy. We propose the "graph model" of compression, a new theoretical framework for representing compression as a directed acyclic graph of modular codecs. OpenZL implements this framework and compresses data into a self-describing wire format, any configuration of which can be decompressed by a universal decoder. OpenZL's design enables rapid development of application-specific compressors with minimal code. Experimental results demonstrate that OpenZL achieves superior compression ratios and speeds compared to state-of-the-art general-purpose compressors on a variety of real-world datasets. Compared to ratio-focused deep-learning compressors, OpenZL is competitive on ratio while being many orders of magnitude faster. Internal deployments at Meta have also shown consistent improvements in size and/or speed, with development timelines reduced from months to days. OpenZL thus represents a significant advance in practical, scalable, and maintainable data compression for modern data-intensive applications.
Big data comparison of quantum invariants
Mar 20, 2025



We apply big data techniques, including exploratory and topological data analysis, to investigate quantum invariants. More precisely, our study explores the Jones polynomial's structural properties and contrasts its behavior under four principal methods of enhancement: coloring, rank increase, categorification, and leaving the realm of Lie algebras.
Optimizing Multi-GPU Parallelization Strategies for Deep Learning Training
Jul 30, 2019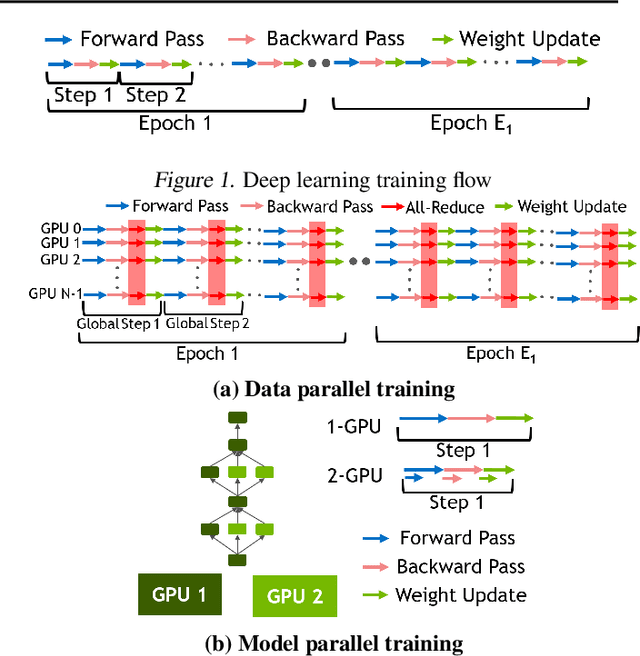

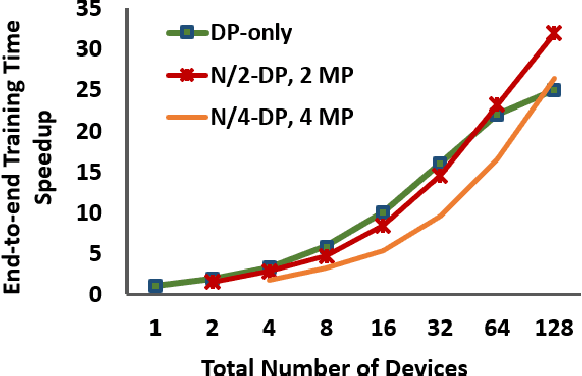
Deploying deep learning (DL) models across multiple compute devices to train large and complex models continues to grow in importance because of the demand for faster and more frequent training. Data parallelism (DP) is the most widely used parallelization strategy, but as the number of devices in data parallel training grows, so does the communication overhead between devices. Additionally, a larger aggregate batch size per step leads to statistical efficiency loss, i.e., a larger number of epochs are required to converge to a desired accuracy. These factors affect overall training time and beyond a certain number of devices, the speedup from leveraging DP begins to scale poorly. In addition to DP, each training step can be accelerated by exploiting model parallelism (MP). This work explores hybrid parallelization, where each data parallel worker is comprised of more than one device, across which the model dataflow graph (DFG) is split using MP. We show that at scale, hybrid training will be more effective at minimizing end-to-end training time than exploiting DP alone. We project that for Inception-V3, GNMT, and BigLSTM, the hybrid strategy provides an end-to-end training speedup of at least 26.5%, 8%, and 22% respectively compared to what DP alone can achieve at scale.