 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Multi-GPU Parallelization Strategies for Deep Learning Training
Jul 30, 2019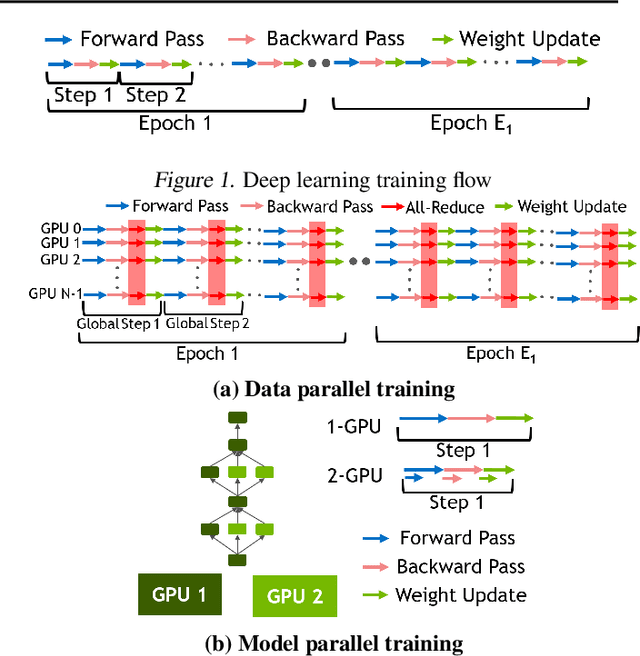

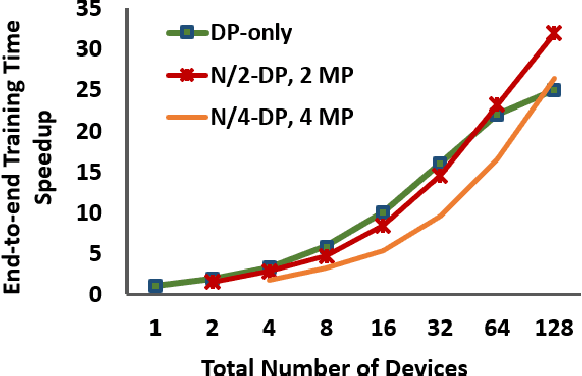
Deploying deep learning (DL) models across multiple compute devices to train large and complex models continues to grow in importance because of the demand for faster and more frequent training. Data parallelism (DP) is the most widely used parallelization strategy, but as the number of devices in data parallel training grows, so does the communication overhead between devices. Additionally, a larger aggregate batch size per step leads to statistical efficiency loss, i.e., a larger number of epochs are required to converge to a desired accuracy. These factors affect overall training time and beyond a certain number of devices, the speedup from leveraging DP begins to scale poorly. In addition to DP, each training step can be accelerated by exploiting model parallelism (MP). This work explores hybrid parallelization, where each data parallel worker is comprised of more than one device, across which the model dataflow graph (DFG) is split using MP. We show that at scale, hybrid training will be more effective at minimizing end-to-end training time than exploiting DP alone. We project that for Inception-V3, GNMT, and BigLSTM, the hybrid strategy provides an end-to-end training speedup of at least 26.5%, 8%, and 22% respectively compared to what DP alone can achieve at scale.
vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design
Jul 28, 2016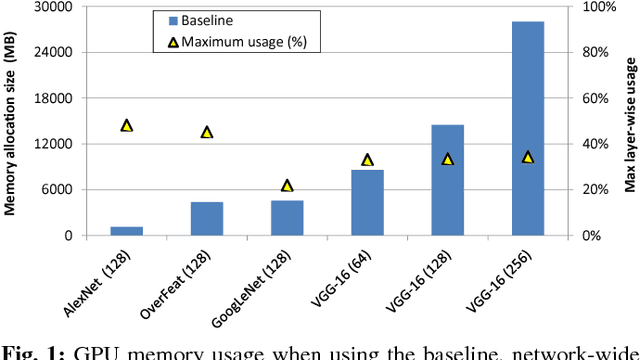
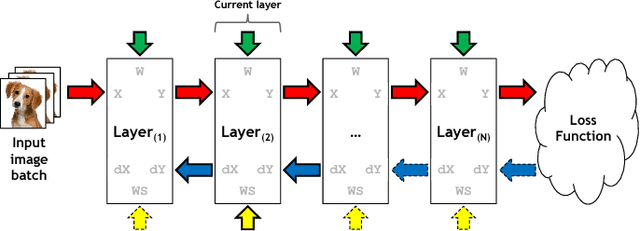
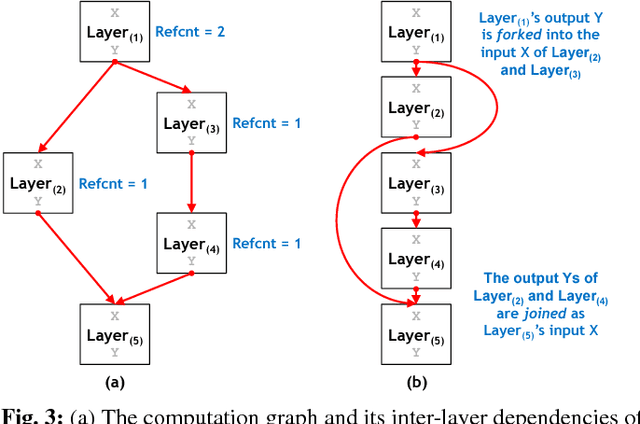
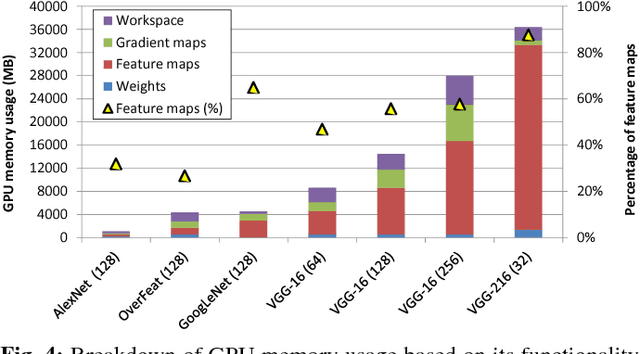
The most widely used machine learning frameworks require users to carefully tune their memory usage so that the deep neural network (DNN) fits into the DRAM capacity of a GPU. This restriction hampers a researcher's flexibility to study different machine learning algorithms, forcing them to either use a less desirable network architecture or parallelize the processing across multiple GPUs. We propose a runtime memory manager that virtualizes the memory usage of DNNs such that both GPU and CPU memory can simultaneously be utilized for training larger DNNs. Our virtualized DNN (vDNN) reduces the average GPU memory usage of AlexNet by up to 89%, OverFeat by 91%, and GoogLeNet by 95%, a significant reduction in memory requirements of DNNs. Similar experiments on VGG-16, one of the deepest and memory hungry DNNs to date, demonstrate the memory-efficiency of our proposal. vDNN enables VGG-16 with batch size 256 (requiring 28 GB of memory) to be trained on a single NVIDIA Titan X GPU card containing 12 GB of memory, with 18% performance loss compared to a hypothetical, oracular GPU with enough memory to hold the entire DNN.