 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiT: Point-Conditioned Diffusion Transformer for Satellite Image Synthesis
Mar 02, 2026We introduce GeoDiT, a diffusion transformer designed for text-to-satellite image generation with point-based control. Existing controlled satellite image generative models often require pixel-level maps that are time-consuming to acquire, yet semantically limited. To address this limitation, we introduce a novel point-based conditioning framework that controls the generation process through the spatial location of the points and the textual description associated with each point, providing semantically rich control signals. This approach enables flexible, annotation-friendly, and computationally simple inference for satellite image generation. To this end, we introduce an adaptive local attention mechanism that effectively regularizes the attention scores based on the input point queries. We systematically evaluate various domain-specific design choices for training GeoDiT, including the selection of satellite image representation for alignment and geolocation representation for conditioning. Our experiments demonstrate that GeoDiT achieves impressive generation performance, surpassing the state-of-the-art remote sensing generative models.
From Prediction to Explanation: Multimodal, Explainable, and Interactive Deepfake Detection Framework for Non-Expert Users
Aug 11, 2025The proliferation of deepfake technologies poses urgent challenges and serious risks to digital integrity, particularly within critical sectors such as forensics, journalism, and the legal system. While existing detection systems have made significant progress in classification accuracy, they typically function as black-box models, offering limited transparency and minimal support for human reasoning. This lack of interpretability hinders their usability in real-world decision-making contexts, especially for non-expert users. In this paper, we present DF-P2E (Deepfake: Prediction to Explanation), a novel multimodal framework that integrates visual, semantic, and narrative layers of explanation to make deepfake detection interpretable and accessible. The framework consists of three modular components: (1) a deepfake classifier with Grad-CAM-based saliency visualisation, (2) a visual captioning module that generates natural language summaries of manipulated regions, and (3) a narrative refinement module that uses a fine-tuned Large Language Model (LLM) to produce context-aware, user-sensitive explanations. We instantiate and evaluate the framework on the DF40 benchmark, the most diverse deepfake dataset to date. Experiments demonstrate that our system achieves competitive detection performance while providing high-quality explanations aligned with Grad-CAM activations. By unifying prediction and explanation in a coherent, human-aligned pipeline, this work offers a scalable approach to interpretable deepfake detection, advancing the broader vision of trustworthy and transparent AI systems in adversarial media environments.
Analog Signal Processing Approach for Coarse and Fine Depth Estimation
Jan 06, 2015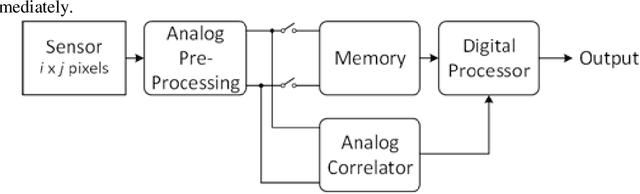

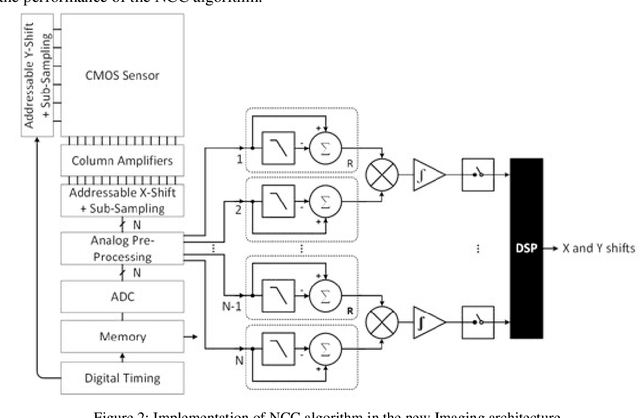
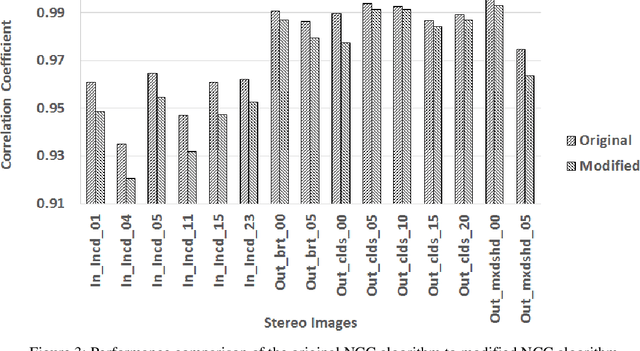
Imaging and Image sensors is a field that is continuously evolving. There are new products coming into the market every day. Some of these have very severe Size, Weight and Power constraints whereas other devices have to handle very high computational loads. Some require both these conditions to be met simultaneously. Current imaging architectures and digital image processing solutions will not be able to meet these ever increasing demands. There is a need to develop novel imaging architectures and image processing solutions to address these requirements. In this work we propose analog signal processing as a solution to this problem. The analog processor is not suggested as a replacement to a digital processor but it will be used as an augmentation device which works in parallel with the digital processor, making the system faster and more efficient. In order to show the merits of analog processing two stereo correspondence algorithms are implemented. We propose novel modifications to the algorithms and new imaging architectures which, significantly reduces the computation time.