 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntroLLM: Entropy Encoded Weight Compression for Efficient Large Language Model Inference on Edge Devices
May 05, 2025



Large Language Models (LLMs) demonstrate exceptional performance across various tasks, but their large storage and computational requirements constrain their deployment on edge devices. To address this, we propose EntroLLM, a novel compression framework that integrates mixed quantization with entropy coding to reduce storage overhead while maintaining model accuracy. Our method applies a layer-wise mixed quantization scheme - choosing between symmetric and asymmetric quantization based on individual layer weight distributions - to optimize compressibility. We then employ Huffman encoding for lossless compression of the quantized weights, significantly reducing memory bandwidth requirements. Furthermore, we introduce parallel Huffman decoding, which enables efficient retrieval of encoded weights during inference, ensuring minimal latency impact. Our experiments on edge-compatible LLMs, including smolLM-1.7B-Instruct, phi3-mini-4k-Instruct, and mistral-7B-Instruct, demonstrate that EntroLLM achieves up to $30%$ storage reduction compared to uint8 models and up to $65%$ storage reduction compared to uint4 models, while preserving perplexity and accuracy, on language benchmark tasks. We further show that our method enables $31.9%$ - $146.6%$ faster inference throughput on memory-bandwidth-limited edge devices, such as NVIDIA Jetson P3450, by reducing the required data movement. The proposed approach requires no additional re-training and is fully compatible with existing post-training quantization methods, making it a practical solution for edge LLMs.
All that is English may be Hindi: Enhancing language identification through automatic ranking of likeliness of word borrowing in social media
Jul 29, 2017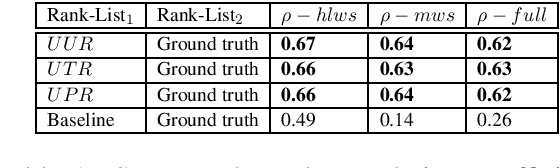
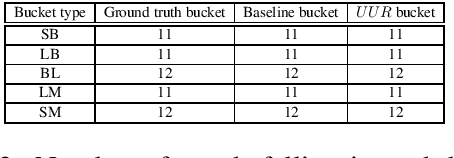
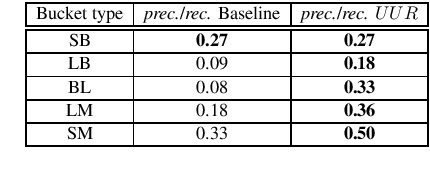
In this paper, we present a set of computational methods to identify the likeliness of a word being borrowed, based on the signals from social media. In terms of Spearman correlation coefficient values, our methods perform more than two times better (nearly 0.62) in predicting the borrowing likeliness compared to the best performing baseline (nearly 0.26) reported in literature. Based on this likeliness estimate we asked annotators to re-annotate the language tags of foreign words in predominantly native contexts. In 88 percent of cases the annotators felt that the foreign language tag should be replaced by native language tag, thus indicating a huge scope for improvement of automatic language identification systems.
Is this word borrowed? An automatic approach to quantify the likeliness of borrowing in social media
Mar 15, 2017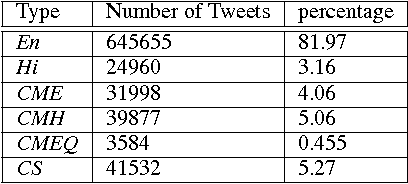
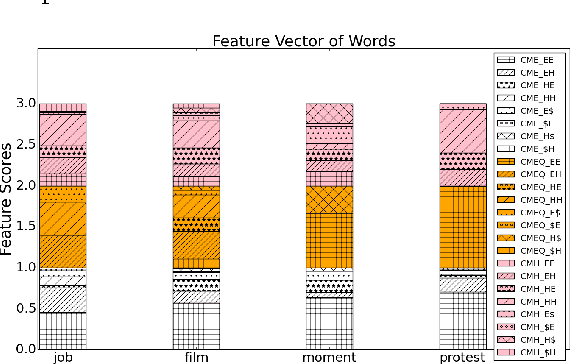
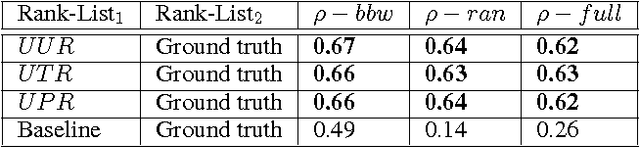

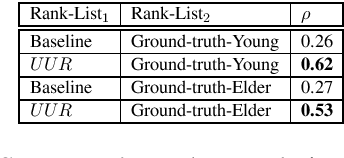
Code-mixing or code-switching are the effortless phenomena of natural switching between two or more languages in a single conversation. Use of a foreign word in a language; however, does not necessarily mean that the speaker is code-switching because often languages borrow lexical items from other languages. If a word is borrowed, it becomes a part of the lexicon of a language; whereas, during code-switching, the speaker is aware that the conversation involves foreign words or phrases. Identifying whether a foreign word used by a bilingual speaker is due to borrowing or code-switching is a fundamental importance to theories of multilingualism, and an essential prerequisite towards the development of language and speech technologies for multilingual communities. In this paper, we present a series of novel computational methods to identify the borrowed likeliness of a word, based on the social media signals. We first propose context based clustering method to sample a set of candidate words from the social media data.Next, we propose three novel and similar metrics based on the usage of these words by the users in different tweets; these metrics were used to score and rank the candidate words indicating their borrowed likeliness. We compare these rankings with a ground truth ranking constructed through a human judgment experiment. The Spearman's rank correlation between the two rankings (nearly 0.62 for all the three metric variants) is more than double the value (0.26) of the most competitive existing baseline reported in the literature. Some other striking observations are, (i) the correlation is higher for the ground truth data elicited from the younger participants (age less than 30) than that from the older participants, and (ii )those participants who use mixed-language for tweeting the least, provide the best signals of borrowing.