 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntroLLM: Entropy Encoded Weight Compression for Efficient Large Language Model Inference on Edge Devices
May 05, 2025



Large Language Models (LLMs) demonstrate exceptional performance across various tasks, but their large storage and computational requirements constrain their deployment on edge devices. To address this, we propose EntroLLM, a novel compression framework that integrates mixed quantization with entropy coding to reduce storage overhead while maintaining model accuracy. Our method applies a layer-wise mixed quantization scheme - choosing between symmetric and asymmetric quantization based on individual layer weight distributions - to optimize compressibility. We then employ Huffman encoding for lossless compression of the quantized weights, significantly reducing memory bandwidth requirements. Furthermore, we introduce parallel Huffman decoding, which enables efficient retrieval of encoded weights during inference, ensuring minimal latency impact. Our experiments on edge-compatible LLMs, including smolLM-1.7B-Instruct, phi3-mini-4k-Instruct, and mistral-7B-Instruct, demonstrate that EntroLLM achieves up to $30%$ storage reduction compared to uint8 models and up to $65%$ storage reduction compared to uint4 models, while preserving perplexity and accuracy, on language benchmark tasks. We further show that our method enables $31.9%$ - $146.6%$ faster inference throughput on memory-bandwidth-limited edge devices, such as NVIDIA Jetson P3450, by reducing the required data movement. The proposed approach requires no additional re-training and is fully compatible with existing post-training quantization methods, making it a practical solution for edge LLMs.
OASIS: Optimized Lightweight Autoencoder System for Distributed In-Sensor computing
May 04, 2025



In-sensor computing, which integrates computation directly within the sensor, has emerged as a promising paradigm for machine vision applications such as AR/VR and smart home systems. By processing data on-chip before transmission, it alleviates the bandwidth bottleneck caused by high-resolution, high-frame-rate image transmission, particularly in video applications. We envision a system architecture that integrates a CMOS image sensor (CIS) with a logic chip via advanced packaging, where the logic chip processes early-stage deep neural network (DNN) layers. However, its limited compute and memory make deploying advanced DNNs challenging. A simple solution is to split the model, executing the first part on the logic chip and the rest off-chip. However, modern DNNs require multiple layers before dimensionality reduction, limiting their ability to achieve the primary goal of in-sensor computing: minimizing data bandwidth. To address this, we propose a dual-branch autoencoder-based vision architecture that deploys a lightweight encoder on the logic chip while the task-specific network runs off-chip. The encoder is trained using a triple loss function: (1) task-specific loss to optimize accuracy, (2) entropy loss to enforce compact and compressible representations, and (3) reconstruction loss (mean-square error) to preserve essential visual information. This design enables a four-order-of-magnitude reduction in output activation dimensionality compared to input images, resulting in a $2{-}4.5\times$ decrease in energy consumption, as validated by our hardware-backed semi-analytical energy models. We evaluate our approach on CNN and ViT-based models across applications in smart home and augmented reality domains, achieving state-of-the-art accuracy with energy efficiency of up to 22.7 TOPS/W.
Neural Network Training with Approximate Logarithmic Computations
Oct 22, 2019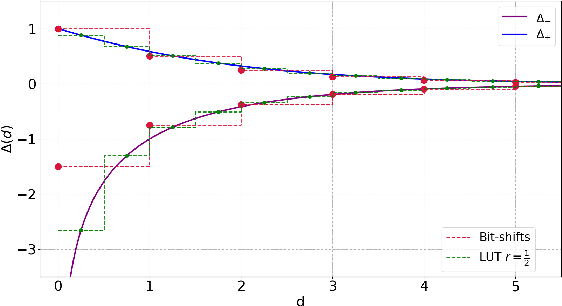
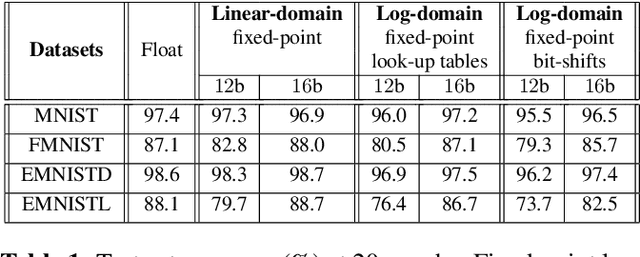
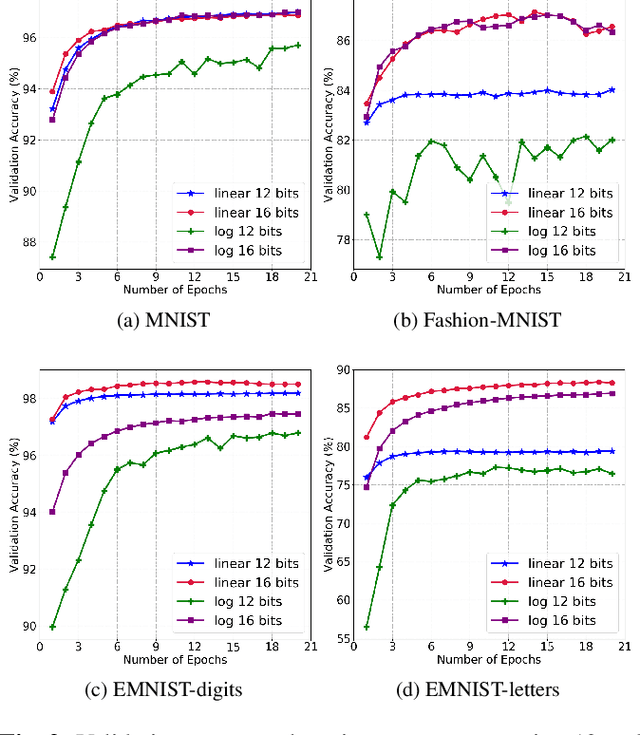
The high computational complexity associated with training deep neural networks limits online and real-time training on edge devices. This paper proposed an end-to-end training and inference scheme that eliminates multiplications by approximate operations in the log-domain which has the potential to significantly reduce implementation complexity. We implement the entire training procedure in the log-domain, with fixed-point data representations. This training procedure is inspired by hardware-friendly approximations of log-domain addition which are based on look-up tables and bit-shifts. We show that our 16-bit log-based training can achieve classification accuracy within approximately 1% of the equivalent floating-point baselines for a number of commonly used datasets.