 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining with Pseudo-Code for Instruction Following
May 23, 2025Despite the rapid progress in the capabilities of Large Language Models (LLMs), they continue to have difficulty following relatively simple, unambiguous instructions, especially when compositions are involved. In this paper, we take inspiration from recent work that suggests that models may follow instructions better when they are expressed in pseudo-code. However, writing pseudo-code programs can be tedious and using few-shot demonstrations to craft code representations for use in inference can be unnatural for non-expert users of LLMs. To overcome these limitations, we propose fine-tuning LLMs with instruction-tuning data that additionally includes instructions re-expressed in pseudo-code along with the final response. We evaluate models trained using our method on $11$ publicly available benchmarks comprising of tasks related to instruction-following, mathematics, and common-sense reasoning. We conduct rigorous experiments with $5$ different models and find that not only do models follow instructions better when trained with pseudo-code, they also retain their capabilities on the other tasks related to mathematical and common sense reasoning. Specifically, we observe a relative gain of $3$--$19$% on instruction-following benchmark, and an average gain of upto 14% across all tasks.
ETF: An Entity Tracing Framework for Hallucination Detection in Code Summaries
Oct 22, 2024Recent advancements in large language models (LLMs) have significantly enhanced their ability to understand both natural language and code, driving their use in tasks like natural language-to-code (NL2Code) and code summarization. However, LLMs are prone to hallucination-outputs that stray from intended meanings. Detecting hallucinations in code summarization is especially difficult due to the complex interplay between programming and natural languages. We introduce a first-of-its-kind dataset with $\sim$10K samples, curated specifically for hallucination detection in code summarization. We further propose a novel Entity Tracing Framework (ETF) that a) utilizes static program analysis to identify code entities from the program and b) uses LLMs to map and verify these entities and their intents within generated code summaries. Our experimental analysis demonstrates the effectiveness of the framework, leading to a 0.73 F1 score. This approach provides an interpretable method for detecting hallucinations by grounding entities, allowing us to evaluate summary accuracy.
Evaluating the Instruction-following Abilities of Language Models using Knowledge Tasks
Oct 16, 2024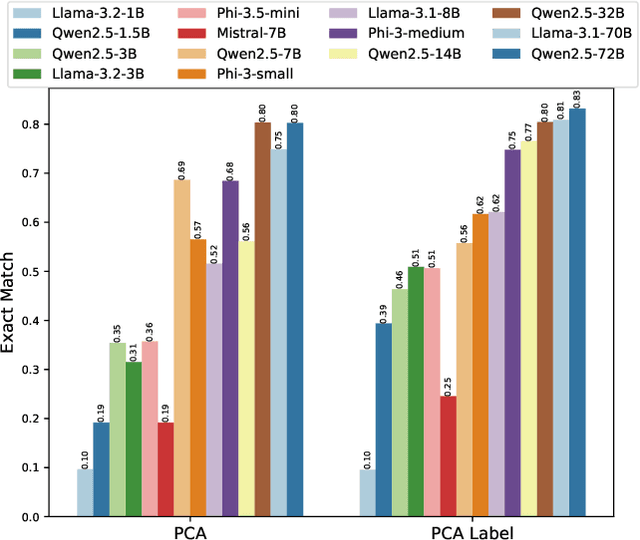
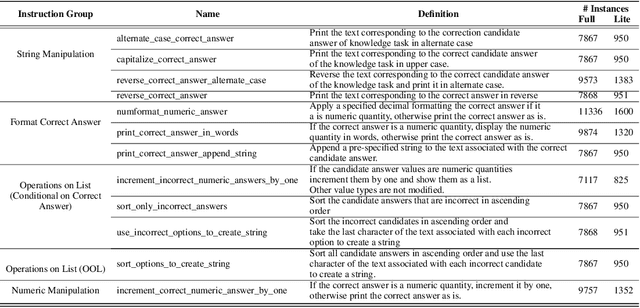
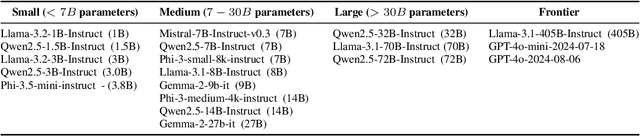
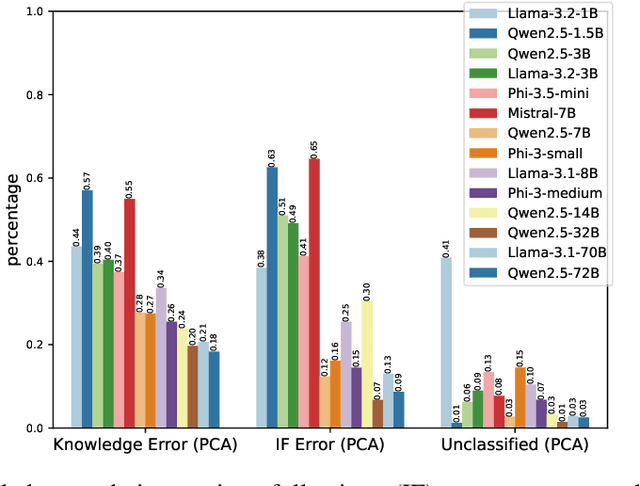
In this work, we focus our attention on developing a benchmark for instruction-following where it is easy to verify both task performance as well as instruction-following capabilities. We adapt existing knowledge benchmarks and augment them with instructions that are a) conditional on correctly answering the knowledge task or b) use the space of candidate options in multiple-choice knowledge-answering tasks. This allows us to study model characteristics, such as their change in performance on the knowledge tasks in the presence of answer-modifying instructions and distractor instructions. In contrast to existing benchmarks for instruction following, we not only measure instruction-following capabilities but also use LLM-free methods to study task performance. We study a series of openly available large language models of varying parameter sizes (1B-405B) and closed source models namely GPT-4o-mini, GPT-4o. We find that even large-scale instruction-tuned LLMs fail to follow simple instructions in zero-shot settings. We release our dataset, the benchmark, code, and results for future work.
ConCodeEval: Evaluating Large Language Models for Code Constraints in Domain-Specific Languages
Jul 03, 2024

Recent work shows Large Language Models (LLMs) struggle to understand natural language constraints for various text generation tasks in zero- and few-shot settings. While, in the code domain, there is wide usage of constraints in code format to maintain the integrity of code written in Domain-Specific Languages (DSLs), yet there has been no work evaluating LLMs with these constraints. We propose two novel tasks to assess the controllability of LLMs using hard and soft constraints represented as code across five representations. Our findings suggest that LLMs struggle to comprehend constraints in all representations irrespective of their portions in the pre-training data. While models are better at comprehending constraints in JSON, YAML, and natural language representations, they struggle with constraints represented in XML and the resource-rich language Python.
DocCGen: Document-based Controlled Code Generation
Jun 17, 2024



Recent developments show that Large Language Models (LLMs) produce state-of-the-art performance on natural language (NL) to code generation for resource-rich general-purpose languages like C++, Java, and Python. However, their practical usage for structured domain-specific languages (DSLs) such as YAML, JSON is limited due to domain-specific schema, grammar, and customizations generally unseen by LLMs during pre-training. Efforts have been made to mitigate this challenge via in-context learning through relevant examples or by fine-tuning. However, it suffers from problems, such as limited DSL samples and prompt sensitivity but enterprises maintain good documentation of the DSLs. Therefore, we propose DocCGen, a framework that can leverage such rich knowledge by breaking the NL-to-Code generation task for structured code languages into a two-step process. First, it detects the correct libraries using the library documentation that best matches the NL query. Then, it utilizes schema rules extracted from the documentation of these libraries to constrain the decoding. We evaluate our framework for two complex structured languages, Ansible YAML and Bash command, consisting of two settings: Out-of-domain (OOD) and In-domain (ID). Our extensive experiments show that DocCGen consistently improves different-sized language models across all six evaluation metrics, reducing syntactic and semantic errors in structured code. We plan to open-source the datasets and code to motivate research in constrained code generation.
Read between the lines -- Functionality Extraction From READMEs
Mar 15, 2024While text summarization is a well-known NLP task, in this paper, we introduce a novel and useful variant of it called functionality extraction from Git README files. Though this task is a text2text generation at an abstract level, it involves its own peculiarities and challenges making existing text2text generation systems not very useful. The motivation behind this task stems from a recent surge in research and development activities around the use of large language models for code-related tasks, such as code refactoring, code summarization, etc. We also release a human-annotated dataset called FuncRead, and develop a battery of models for the task. Our exhaustive experimentation shows that small size fine-tuned models beat any baseline models that can be designed using popular black-box or white-box large language models (LLMs) such as ChatGPT and Bard. Our best fine-tuned 7 Billion CodeLlama model exhibit 70% and 20% gain on the F1 score against ChatGPT and Bard respectively.
Prompting with Pseudo-Code Instructions
May 22, 2023



Prompting with natural language instructions has recently emerged as a popular method of harnessing the capabilities of large language models. Given the inherent ambiguity present in natural language, it is intuitive to consider the possible advantages of prompting with less ambiguous prompt styles, such as the use of pseudo-code. In this paper we explore if prompting via pseudo-code instructions helps improve the performance of pre-trained language models. We manually create a dataset of pseudo-code prompts for 132 different tasks spanning classification, QA and generative language tasks, sourced from the Super-NaturalInstructions dataset. Using these prompts along with their counterparts in natural language, we study their performance on two LLM families - BLOOM and CodeGen. Our experiments show that using pseudo-code instructions leads to better results, with an average increase (absolute) of 7-16 points in F1 scores for classification tasks and an improvement (relative) of 12-38% in aggregate ROUGE-L scores across all tasks. We include detailed ablation studies which indicate that code comments, docstrings, and the structural clues encoded in pseudo-code all contribute towards the improvement in performance. To the best of our knowledge our work is the first to demonstrate how pseudo-code prompts can be helpful in improving the performance of pre-trained LMs.
Divide and Conquer: An Ensemble Approach for Hostile Post Detection in Hindi
Jan 20, 2021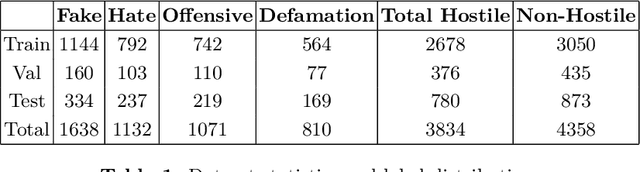
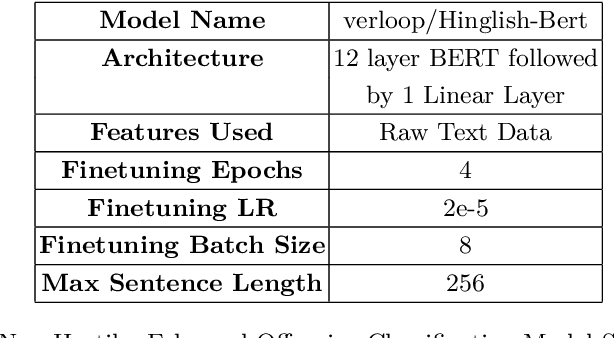


Recently the NLP community has started showing interest towards the challenging task of Hostile Post Detection. This paper present our system for Shared Task at Constraint2021 on "Hostile Post Detection in Hindi". The data for this shared task is provided in Hindi Devanagari script which was collected from Twitter and Facebook. It is a multi-label multi-class classification problem where each data instance is annotated into one or more of the five classes: fake, hate, offensive, defamation, and non-hostile. We propose a two level architecture which is made up of BERT based classifiers and statistical classifiers to solve this problem. Our team 'Albatross', scored 0.9709 Coarse grained hostility F1 score measure on Hostile Post Detection in Hindi subtask and secured 2nd rank out of 45 teams for the task. Our submission is ranked 2nd and 3rd out of a total of 156 submissions with Coarse grained hostility F1 score of 0.9709 and 0.9703 respectively. Our fine grained scores are also very encouraging and can be improved with further finetuning. The code is publicly available.