 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection
Feb 12, 2026Evolutionary agentic systems intensify the trade-off between computational efficiency and reasoning capability by repeatedly invoking large language models (LLMs) during inference. This setting raises a central question: how can an agent dynamically select an LLM that is sufficiently capable for the current generation step while remaining computationally efficient? While model cascades offer a practical mechanism for balancing this trade-off, existing routing strategies typically rely on static heuristics or external controllers and do not explicitly account for model uncertainty. We introduce AdaptEvolve: Adaptive LLM Selection for Multi-LLM Evolutionary Refinement within an evolutionary sequential refinement framework that leverages intrinsic generation confidence to estimate real-time solvability. Empirical results show that confidence-driven selection yields a favourable Pareto frontier, reducing total inference cost by an average of 37.9% across benchmarks while retaining 97.5% of the upper-bound accuracy of static large-model baselines. Our code is available at https://github.com/raypretam/adaptive_llm_selection.
Instella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
Jul 28, 2025The demand for Large Language Models (LLMs) capable of sophisticated mathematical reasoning is growing across industries. However, the development of performant mathematical LLMs is critically bottlenecked by the scarcity of difficult, novel training data. We introduce \textbf{SAND-Math} (Synthetic Augmented Novel and Difficult Mathematics problems and solutions), a pipeline that addresses this by first generating high-quality problems from scratch and then systematically elevating their complexity via a new \textbf{Difficulty Hiking} step. We demonstrate the effectiveness of our approach through two key findings. First, augmenting a strong baseline with SAND-Math data significantly boosts performance, outperforming the next-best synthetic dataset by \textbf{$\uparrow$ 17.85 absolute points} on the AIME25 benchmark. Second, in a dedicated ablation study, we show our Difficulty Hiking process is highly effective: by increasing average problem difficulty from 5.02 to 5.98, this step lifts AIME25 performance from 46.38\% to 49.23\%. The full generation pipeline, final dataset, and a fine-tuned model form a practical and scalable toolkit for building more capable and efficient mathematical reasoning LLMs. SAND-Math dataset is released here: \href{https://huggingface.co/datasets/amd/SAND-MATH}{https://huggingface.co/datasets/amd/SAND-MATH}
TaDA: Training-free recipe for Decoding with Adaptive KV Cache Compression and Mean-centering
Jun 05, 2025The key-value (KV) cache in transformer models is a critical component for efficient decoding or inference, yet its memory demands scale poorly with sequence length, posing a major challenge for scalable deployment of large language models. Among several approaches to KV cache compression, quantization of key and value activations has been widely explored. Most KV cache quantization methods still need to manage sparse and noncontiguous outliers separately. To address this, we introduce TaDA, a training-free recipe for KV cache compression with quantization precision that adapts to error sensitivity across layers and a mean centering to eliminate separate outlier handling. Our approach yields substantial accuracy improvements for multiple models supporting various context lengths. Moreover, our approach does not need to separately manage outlier elements -- a persistent hurdle in most traditional quantization methods. Experiments on standard benchmarks demonstrate that our technique reduces KV cache memory footprint to 27% of the original 16-bit baseline while achieving comparable accuracy. Our method paves the way for scalable and high-performance reasoning in language models by potentially enabling inference for longer context length models, reasoning models, and longer chain of thoughts.
Single Shot Multitask Pedestrian Detection and Behavior Prediction
Jan 06, 2021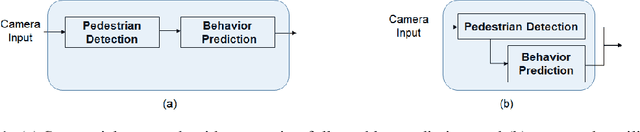
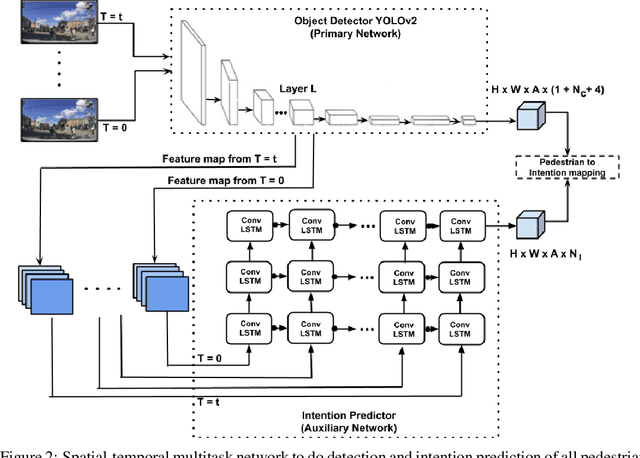
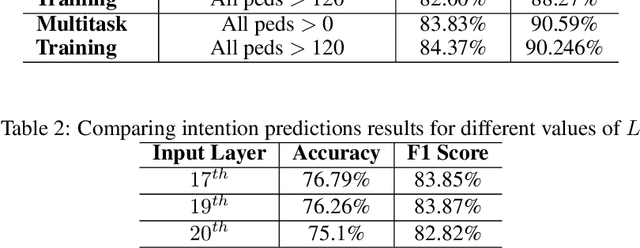

Detecting and predicting the behavior of pedestrians is extremely crucial for self-driving vehicles to plan and interact with them safely. Although there have been several research works in this area, it is important to have fast and memory efficient models such that it can operate in embedded hardware in these autonomous machines. In this work, we propose a novel architecture using spatial-temporal multi-tasking to do camera based pedestrian detection and intention prediction. Our approach significantly reduces the latency by being able to detect and predict all pedestrians' intention in a single shot manner while also being able to attain better accuracy by sharing features with relevant object level information and interactions.
Analyzing the Variety Loss in the Context of Probabilistic Trajectory Prediction
Jul 23, 2019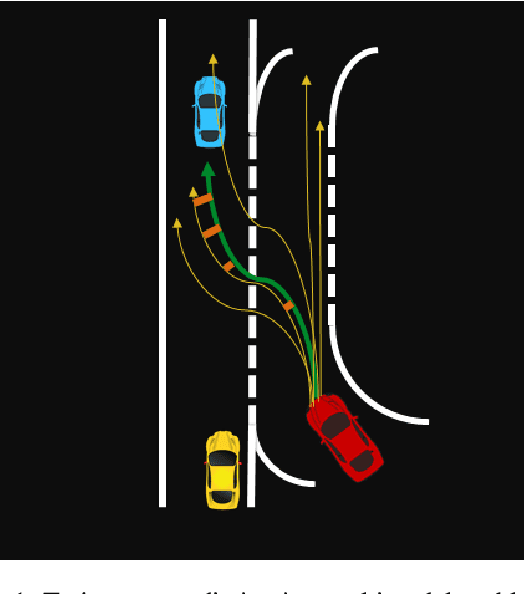

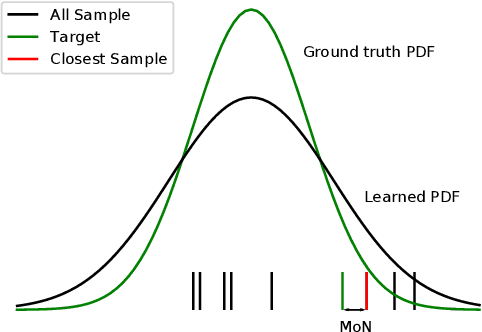
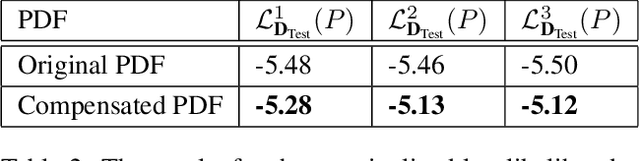
Trajectory or behavior prediction of traffic agents is an important component of autonomous driving and robot planning in general. It can be framed as a probabilistic future sequence generation problem and recent literature has studied the applicability of generative models in this context. The variety or Minimum over N (MoN) loss, which tries to minimize the error between the ground truth and the closest of N output predictions, has been used in these recent learning models to improve the diversity of predictions. In this work, we present a proof to show that the MoN loss does not lead to the ground truth probability density function, but approximately to its square root instead. We validate this finding with extensive experiments on both simulated toy as well as real world datasets. We also propose multiple solutions to compensate for the dilation to show improvement of log likelihood of the ground truth samples in the corrected probability density function.
Structured Memory based Deep Model to Detect as well as Characterize Novel Inputs
Jan 30, 2018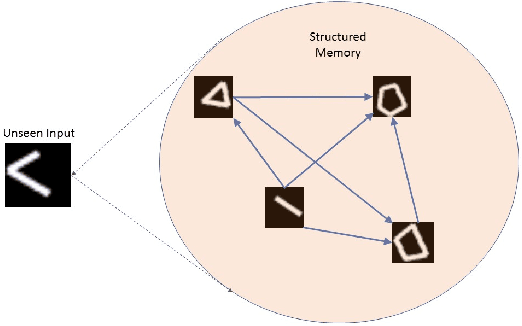
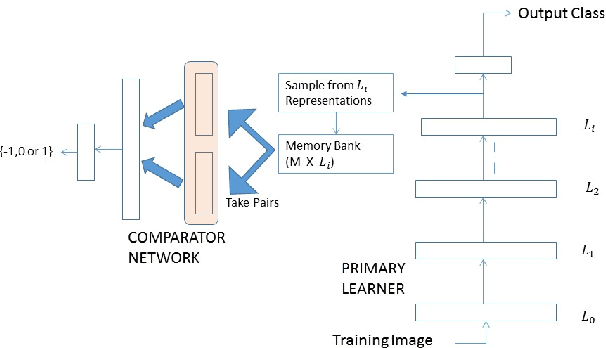
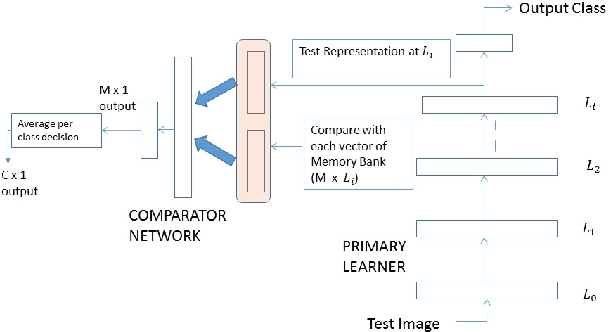
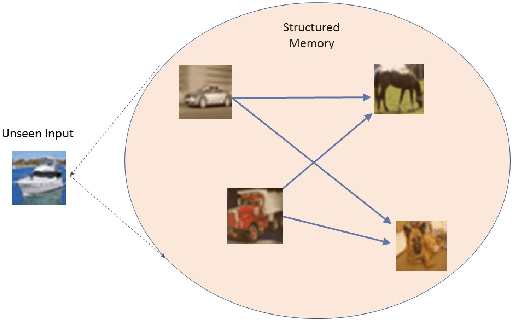
While deep learning has pushed the boundaries in various machine learning tasks, the current models are still far away from replicating many functions that a normal human brain can do. Explicit memorization based deep architecture have been recently proposed with the objective to understand and predict better. In this work, we design a system that involves a primary learner and an adjacent representational memory bank which is organized using a comparative learner. This spatially forked deep architecture with a structured memory can simultaneously predict and reason about the nature of an input, which may even belong to a category never seen in the training data, by relating it with the memorized past representations at the higher layers. Characterizing images of unseen object classes in both synthetic and real world datasets is used as an example to showcase the operational success of the proposed framework.