 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Input Perturbation Methods for Interpreting CNNs and Saliency Map Comparison
Jan 26, 2021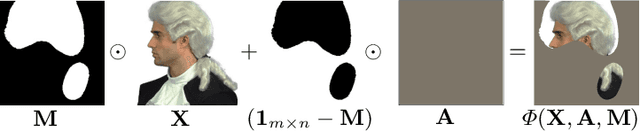
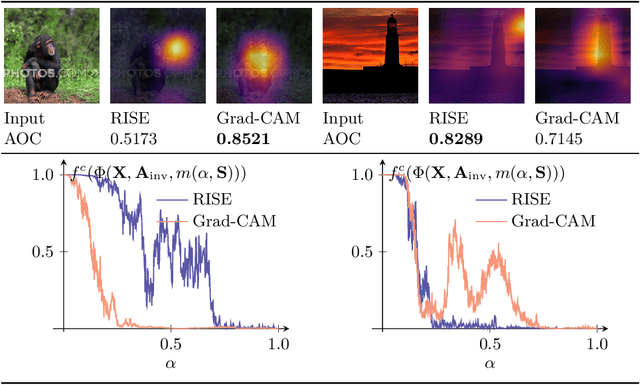
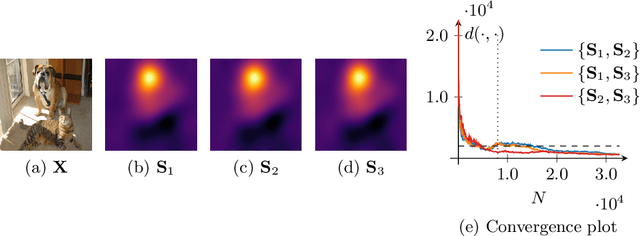
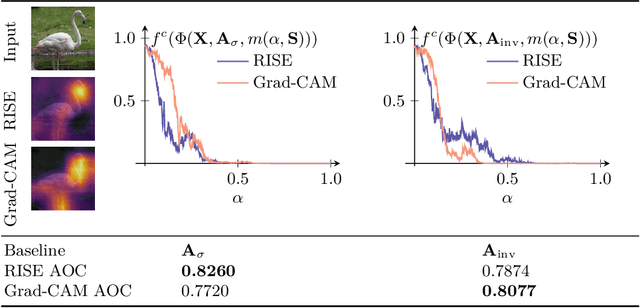
Input perturbation methods occlude parts of an input to a function and measure the change in the function's output. Recently, input perturbation methods have been applied to generate and evaluate saliency maps from convolutional neural networks. In practice, neutral baseline images are used for the occlusion, such that the baseline image's impact on the classification probability is minimal. However, in this paper we show that arguably neutral baseline images still impact the generated saliency maps and their evaluation with input perturbations. We also demonstrate that many choices of hyperparameters lead to the divergence of saliency maps generated by input perturbations. We experimentally reveal inconsistencies among a selection of input perturbation methods and find that they lack robustness for generating saliency maps and for evaluating saliency maps as saliency metrics.
Single Shot Multitask Pedestrian Detection and Behavior Prediction
Jan 06, 2021
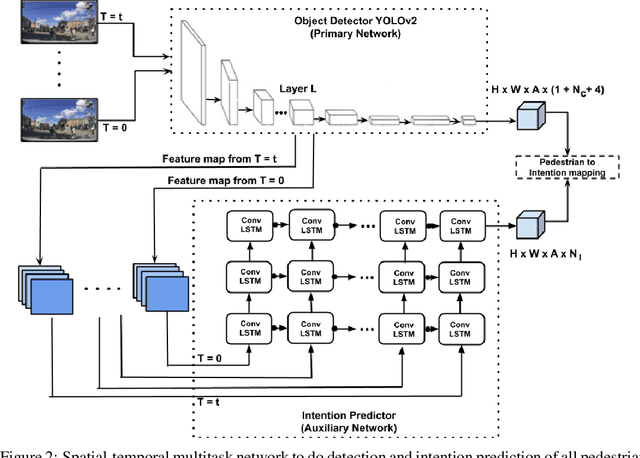
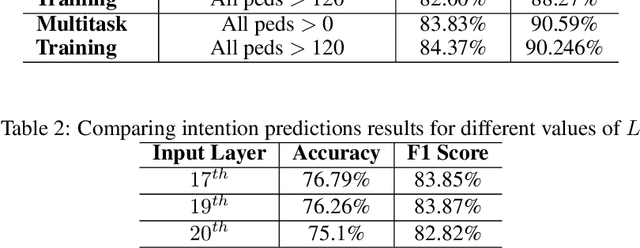

Detecting and predicting the behavior of pedestrians is extremely crucial for self-driving vehicles to plan and interact with them safely. Although there have been several research works in this area, it is important to have fast and memory efficient models such that it can operate in embedded hardware in these autonomous machines. In this work, we propose a novel architecture using spatial-temporal multi-tasking to do camera based pedestrian detection and intention prediction. Our approach significantly reduces the latency by being able to detect and predict all pedestrians' intention in a single shot manner while also being able to attain better accuracy by sharing features with relevant object level information and interactions.