 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast Squares Regression with Markovian Data: Fundamental Limits and Algorithms
Jun 16, 2020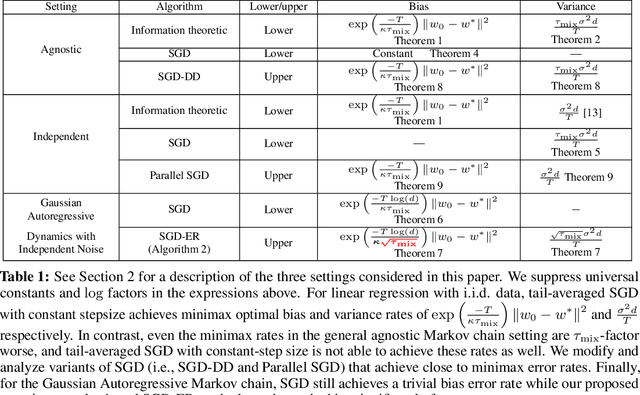
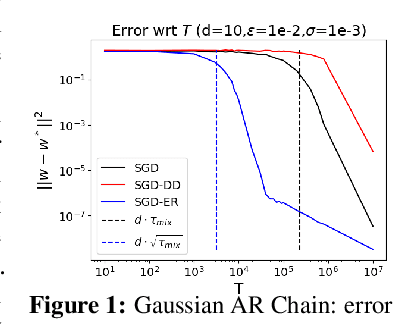
We study the problem of least squares linear regression where the data-points are dependent and are sampled from a Markov chain. We establish sharp information theoretic minimax lower bounds for this problem in terms of $\tau_{\mathsf{mix}}$, the mixing time of the underlying Markov chain, under different noise settings. Our results establish that in general, optimization with Markovian data is strictly harder than optimization with independent data and a trivial algorithm (SGD-DD) that works with only one in every $\tilde{\Theta}(\tau_{\mathsf{mix}})$ samples, which are approximately independent, is minimax optimal. In fact, it is strictly better than the popular Stochastic Gradient Descent (SGD) method with constant step-size which is otherwise minimax optimal in the regression with independent data setting. Beyond a worst case analysis, we investigate whether structured datasets seen in practice such as Gaussian auto-regressive dynamics can admit more efficient optimization schemes. Surprisingly, even in this specific and natural setting, Stochastic Gradient Descent (SGD) with constant step-size is still no better than SGD-DD. Instead, we propose an algorithm based on experience replay--a popular reinforcement learning technique--that achieves a significantly better error rate. Our improved rate serves as one of the first results where an algorithm outperforms SGD-DD on an interesting Markov chain and also provides one of the first theoretical analyses to support the use of experience replay in practice.
The Pitfalls of Simplicity Bias in Neural Networks
Jun 13, 2020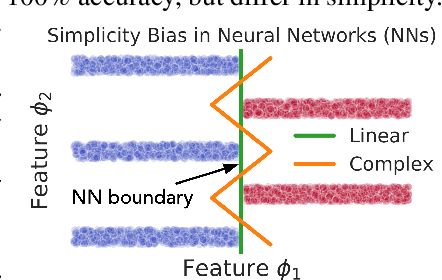

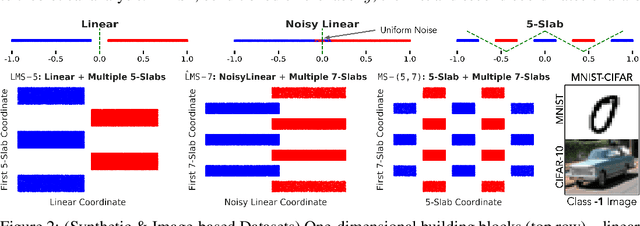
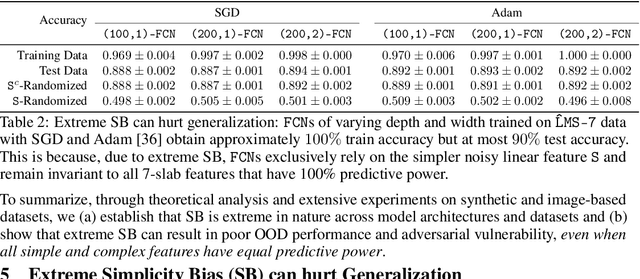
Several works have proposed Simplicity Bias (SB)---the tendency of standard training procedures such as Stochastic Gradient Descent (SGD) to find simple models---to justify why neural networks generalize well [Arpit et al. 2017, Nakkiran et al. 2019, Valle-Perez et al. 2019]. However, the precise notion of simplicity remains vague. Furthermore, previous settings that use SB to justify why neural networks generalize well do not simultaneously capture the brittleness of neural networks---a widely observed phenomenon in practice [Goodfellow et al. 2014, Jo and Bengio 2017]. To this end, we introduce a collection of piecewise-linear and image-based datasets that (a) naturally incorporate a precise notion of simplicity and (b) capture the subtleties of neural networks trained on real datasets. Through theory and experiments on these datasets, we show that SB of SGD and variants is extreme: neural networks rely exclusively on the simplest feature and remain invariant to all predictive complex features. Consequently, the extreme nature of SB explains why seemingly benign distribution shifts and small adversarial perturbations significantly degrade model performance. Moreover, contrary to conventional wisdom, SB can also hurt generalization on the same data distribution, as SB persists even when the simplest feature has less predictive power than the more complex features. We also demonstrate that common approaches for improving generalization and robustness---ensembles and adversarial training---do not mitigate SB and its shortcomings. Given the central role played by SB in generalization and robustness, we hope that the datasets and methods in this paper serve as an effective testbed to evaluate novel algorithmic approaches aimed at avoiding the pitfalls of extreme SB.
COVID-19: Strategies for Allocation of Test Kits
Apr 03, 2020
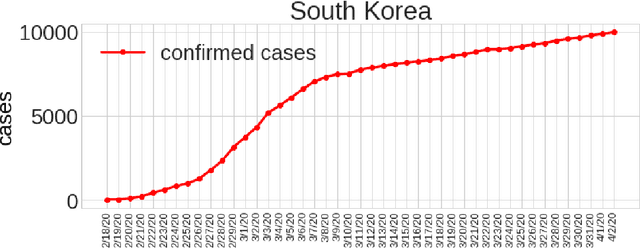
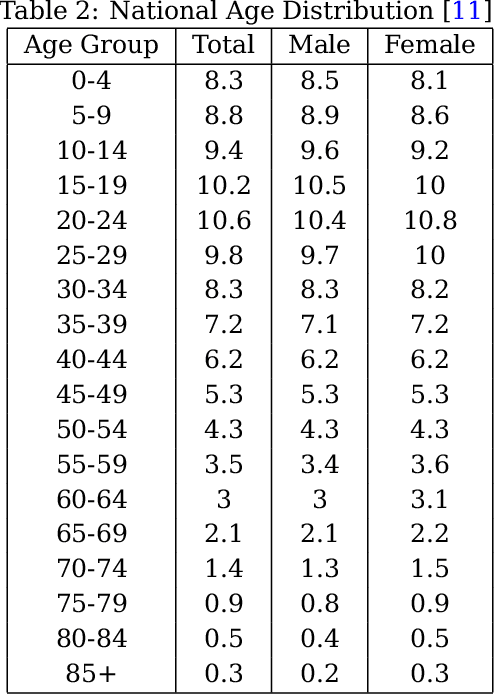
With the increasing spread of COVID-19, it is important to systematically test more and more people. The current strategy for test-kit allocation is mostly rule-based, focusing on individuals having (a) symptoms for COVID-19, (b) travel history or (c) contact history with confirmed COVID-19 patients. Such testing strategy may miss out on detecting asymptomatic individuals who got infected via community spread. Thus, it is important to allocate a separate budget of test-kits per day targeted towards preventing community spread and detecting new cases early on. In this report, we consider the problem of allocating test-kits and discuss some solution approaches. We believe that these approaches will be useful to contain community spread and detect new cases early on. Additionally, these approaches would help in collecting unbiased data which can then be used to improve the accuracy of machine learning models trained to predict COVID-19 infections.
Soft Threshold Weight Reparameterization for Learnable Sparsity
Mar 11, 2020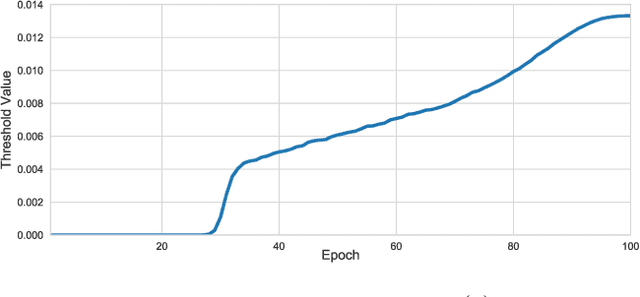
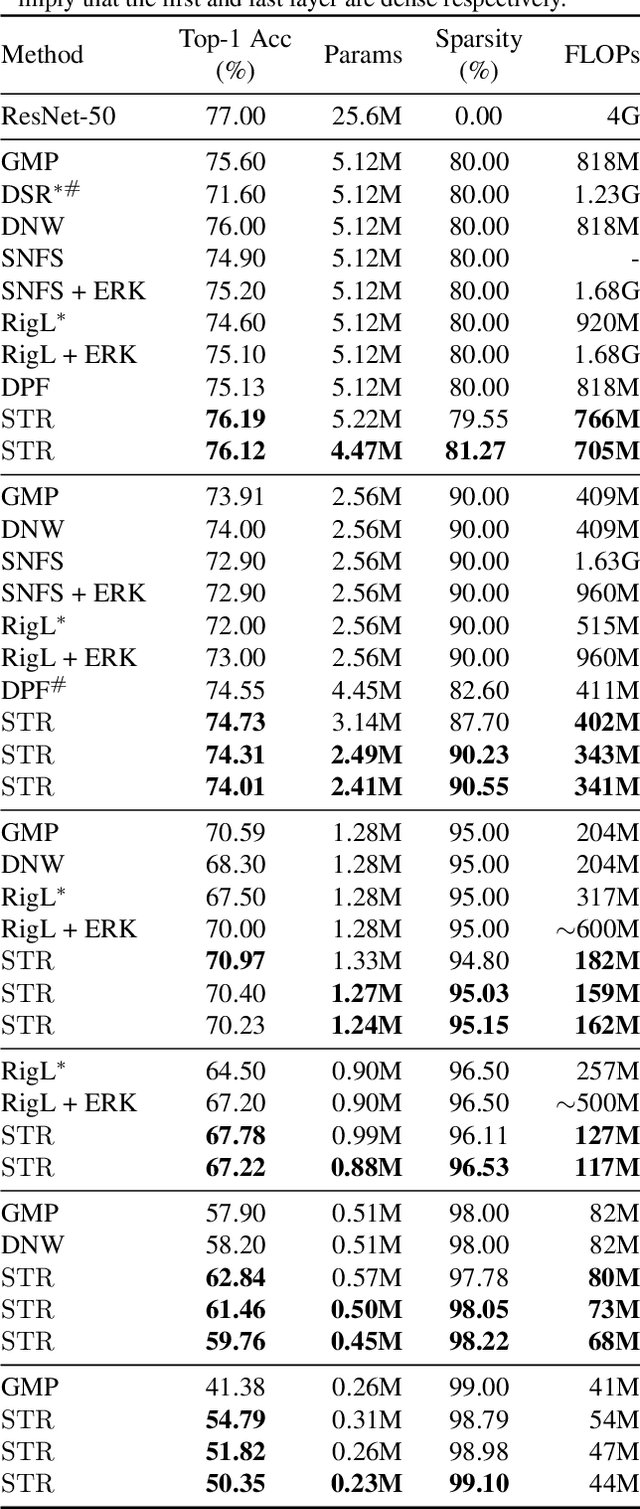
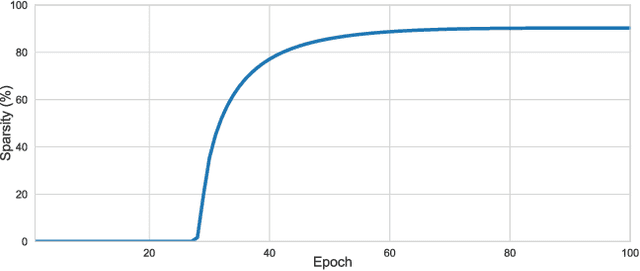
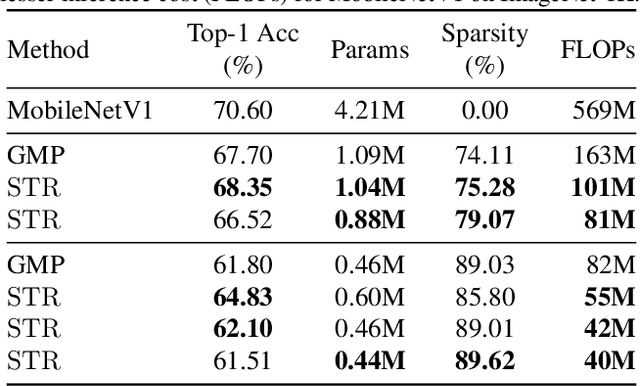
Sparsity in Deep Neural Networks (DNNs) is studied extensively with the focus of maximizing prediction accuracy given an overall parameter budget. Existing methods rely on uniform or heuristic non-uniform sparsity budgets which have sub-optimal layer-wise parameter allocation resulting in a) lower prediction accuracy or b) higher inference cost (FLOPs). This work proposes Soft Threshold Reparameterization (STR), a novel use of the soft-threshold operator on DNN weights. STR smoothly induces sparsity while learning pruning thresholds thereby obtaining a non-uniform sparsity budget. Our method achieves state-of-the-art accuracy for unstructured sparsity in CNNs (ResNet50 and MobileNetV1 on ImageNet-1K), and, additionally, learns non-uniform budgets that empirically reduce the FLOPs by up to 50%. Notably, STR boosts the accuracy over existing results by up to 10% in the ultra sparse (99%) regime and can also be used to induce low-rank (structured sparsity) in RNNs. In short, STR is a simple mechanism which learns effective sparsity budgets that contrast with popular heuristics.
DROCC: Deep Robust One-Class Classification
Feb 28, 2020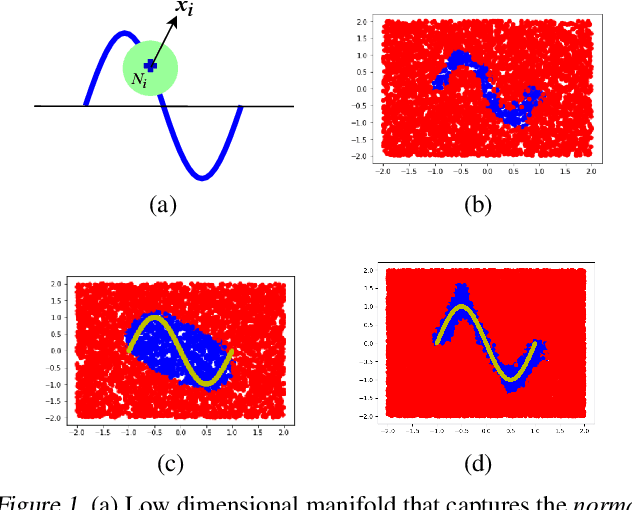
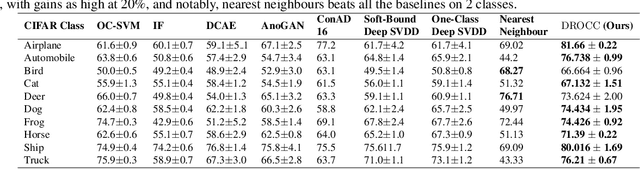
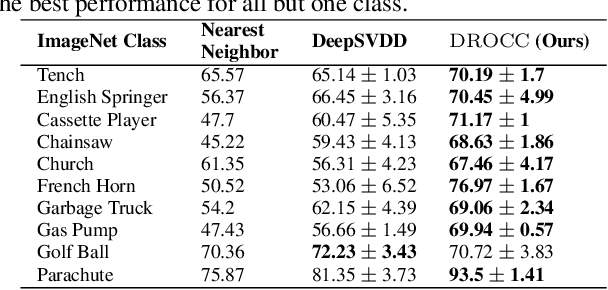
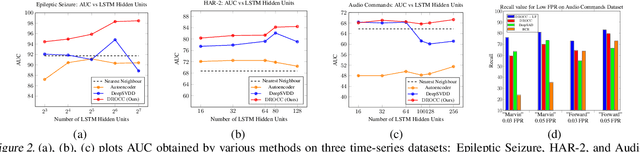
Classical approaches for one-class problems such as one-class SVM (Scholkopf et al., 1999) and isolation forest (Liu et al., 2008) require careful feature engineering when applied to structured domains like images. To alleviate this concern, state-of-the-art methods like DeepSVDD (Ruff et al., 2018) consider the natural alternative of minimizing a classical one-class loss applied to the learned final layer representations. However, such an approach suffers from the fundamental drawback that a representation that simply collapses all the inputs minimizes the one class loss; heuristics to mitigate collapsed representations provide limited benefits. In this work, we propose Deep Robust One Class Classification (DROCC) method that is robust to such a collapse by training the network to distinguish the training points from their perturbations, generated adversarially. DROCC is motivated by the assumption that the interesting class lies on a locally linear low dimensional manifold. Empirical evaluation demonstrates DROCC's effectiveness on two different one-class problem settings and on a range of real-world datasets across different domains - images(CIFAR and ImageNet), audio and timeseries, offering up to 20% increase in accuracy over the state-of-the-art in anomaly detection.
RNNPool: Efficient Non-linear Pooling for RAM Constrained Inference
Feb 27, 2020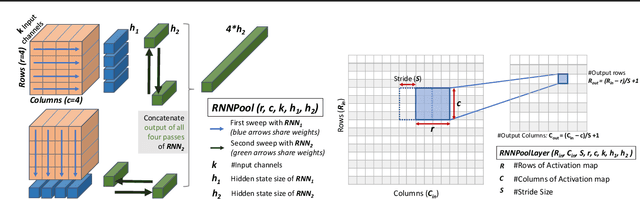
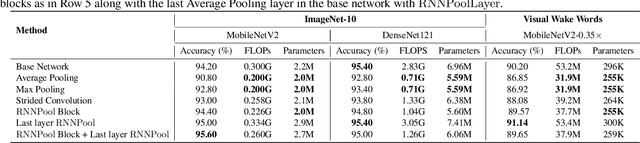
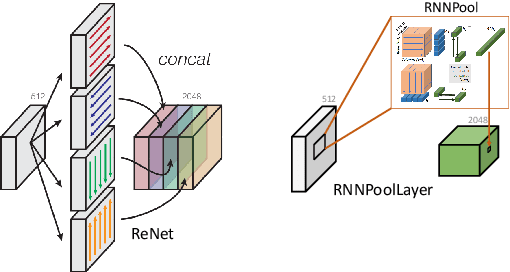

Pooling operators are key components in most Convolutional Neural Networks (CNNs) as they serve to downsample images, aggregate feature information, and increase receptive field. However, standard pooling operators reduce the feature size gradually to avoid significant loss in information via gross aggregation. Consequently, CNN architectures tend to be deep, computationally expensive and challenging to deploy on RAM constrained devices. We introduce RNNPool, a novel pooling operator based on Recurrent Neural Networks (RNNs), that efficiently aggregate features over large patches of an image and rapidly downsamples its size. Our empirical evaluation indicates that an RNNPool layer(s) can effectively replace multiple blocks in a variety of architectures such as MobileNets (Sandler et al., 2018), DenseNet (Huang et al., 2017) and can be used for several vision tasks like image classification and face detection. That is, RNNPool can significantly decrease computational complexity and peak RAM usage for inference, while retaining comparable accuracy. Further, we use RNNPool to construct a novel real-time face detection method that achieves state-of-the-art MAP within computational budget afforded by a tiny Cortex M4 microcontroller with ~256 KB RAM.
Rich-Item Recommendations for Rich-Users via GCNN: Exploiting Dynamic and Static Side Information
Jan 28, 2020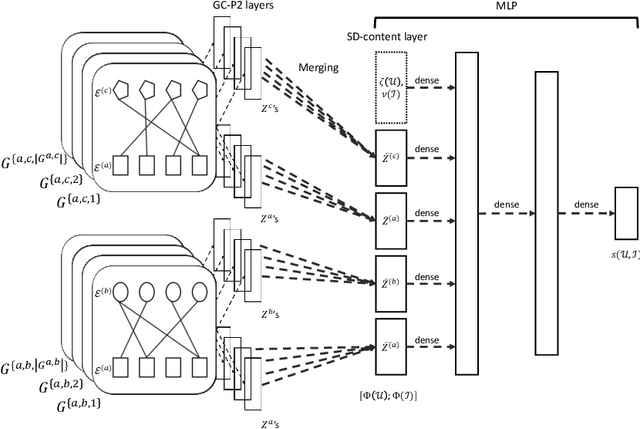
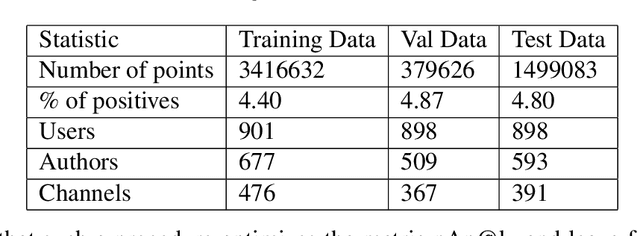
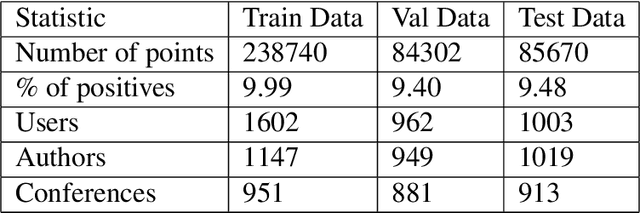
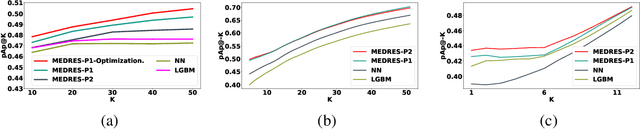
We study the standard problem of recommending relevant items to users; a user is someone who seeks recommendation, and an item is something which should be recommended. In today's modern world, both users and items are 'rich' multi-faceted entities but existing literature, for ease of modeling, views these facets in silos. In this paper, we provide a general formulation of the recommendation problem that captures the complexities of modern systems and encompasses most of the existing recommendation system formulations. In our formulation, each user and item is modeled via a set of static entities and a dynamic component. The relationships between entities are captured by multiple weighted bipartite graphs. To effectively exploit these complex interactions for recommendations, we propose MEDRES -- a multiple graph-CNN based novel deep-learning architecture. In addition, we propose a new metric, pAp@k, that is critical for a variety of classification+ranking scenarios. We also provide an optimization algorithm that directly optimizes the proposed metric and trains MEDRES in an end-to-end framework. We demonstrate the effectiveness of our method on two benchmarks as well as on a message recommendation system deployed in Microsoft Teams where it improves upon the existing production-grade model by 3%.
OASIS: ILP-Guided Synthesis of Loop Invariants
Nov 26, 2019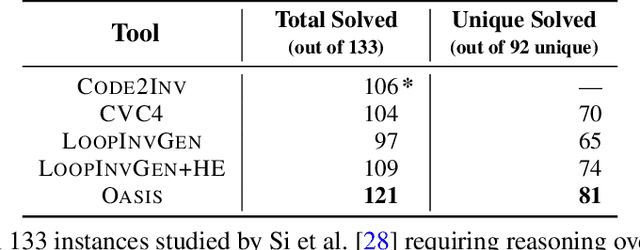
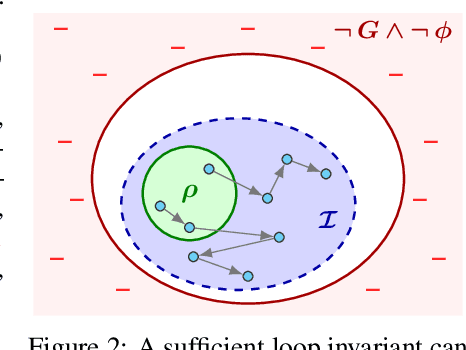

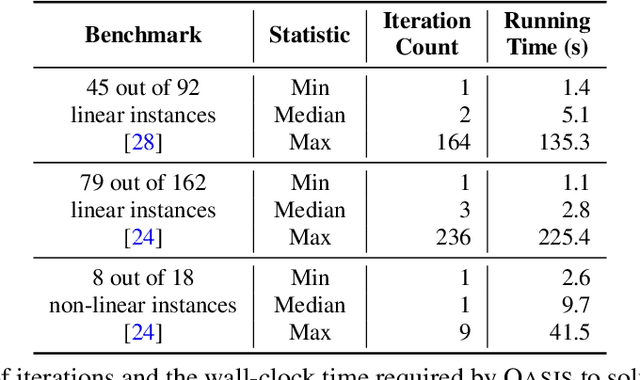
Finding appropriate inductive loop invariants for a program is a key challenge in verifying its functional properties. Although the problem is undecidable in general, several heuristics have been proposed to handle practical programs that tend to have simple control-flow structures. However, these heuristics only work well when the space of invariants is small. On the other hand, machine-learned techniques that use continuous optimization have a high sample complexity, i.e., the number of invariant guesses and the associated counterexamples, since the invariant is required to exactly satisfy a specification. We propose a novel technique that is able to solve complex verification problems involving programs with larger number of variables and non-linear specifications. We formulate an invariant as a piecewise low-degree polynomial, and reduce the problem of synthesizing it to a set of integer linear programming (ILP) problems. This enables the use of state-of-the-art ILP techniques that combine enumerative search with continuous optimization; thus ensuring fast convergence for a large class of verification tasks while still ensuring low sample complexity. We instantiate our technique as the open-source oasis tool using an off-the-shelf ILP solver, and evaluate it on more than 300 benchmark tasks collected from the annual SyGuS competition and recent prior work. Our experiments show that oasis outperforms the state-of-the-art tools, including the winner of last year's SyGuS competition, and is able to solve 9 challenging tasks that existing tools fail on.
Learning Functions over Sets via Permutation Adversarial Networks
Jul 12, 2019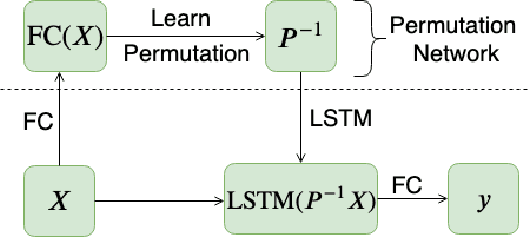

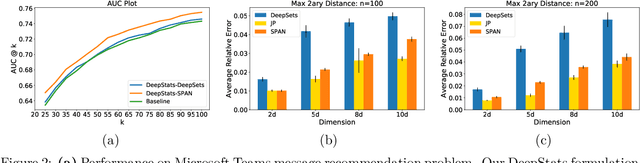

In this paper, we consider the problem of learning functions over sets, i.e., functions that are invariant to permutations of input set items. Recent approaches of pooling individual element embeddings can necessitate extremely large embedding sizes for challenging functions. We address this challenge by allowing standard neural networks like LSTMs to succinctly capture the function over the set. However, to ensure invariance with respect to permutations of set elements, we propose a novel architecture called SPAN that simultaneously learns the function as well as adversarial or worst-case permutations for each input set. The learning problem reduces to a min-max optimization problem that is solved via a simple alternating block coordinate descent technique. We conduct extensive experiments on a variety of set-learning tasks and demonstrate that SPAN learns nearly permutation-invariant functions while still ensuring accuracy on test data. On a variety of tasks sampled from the domains of statistics, graph functions and linear algebra, we show that our method can significantly outperform state-of-the-art methods such as DeepSets and Janossy Pooling. Finally, we present a case study of how learning set-functions can help extract powerful features for recommendation systems, and show that such a method can be as much as 2% more accurate than carefully hand-tuned features on a real-world recommendation system.
Efficient Algorithms for Smooth Minimax Optimization
Jul 02, 2019
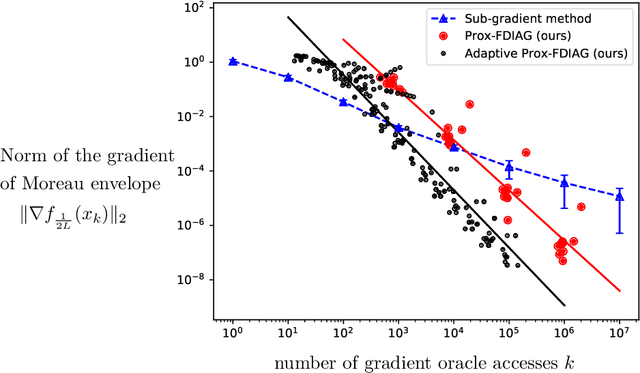
This paper studies first order methods for solving smooth minimax optimization problems $\min_x \max_y g(x,y)$ where $g(\cdot,\cdot)$ is smooth and $g(x,\cdot)$ is concave for each $x$. In terms of $g(\cdot,y)$, we consider two settings -- strongly convex and nonconvex -- and improve upon the best known rates in both. For strongly-convex $g(\cdot, y),\ \forall y$, we propose a new algorithm combining Mirror-Prox and Nesterov's AGD, and show that it can find global optimum in $\tilde{O}(1/k^2)$ iterations, improving over current state-of-the-art rate of $O(1/k)$. We use this result along with an inexact proximal point method to provide $\tilde{O}(1/k^{1/3})$ rate for finding stationary points in the nonconvex setting where $g(\cdot, y)$ can be nonconvex. This improves over current best-known rate of $O(1/k^{1/5})$. Finally, we instantiate our result for finite nonconvex minimax problems, i.e., $\min_x \max_{1\leq i\leq m} f_i(x)$, with nonconvex $f_i(\cdot)$, to obtain convergence rate of $O(m(\log m)^{3/2}/k^{1/3})$ total gradient evaluations for finding a stationary point.