 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware Saliency Prediction for Videos with Incomplete Gaze Data
Apr 16, 2021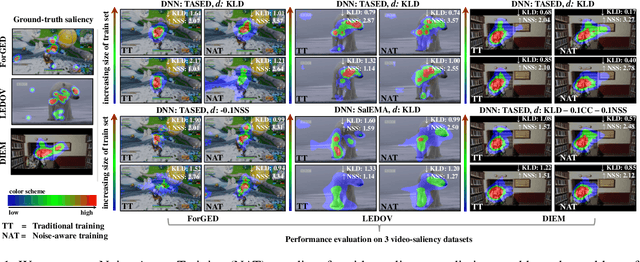
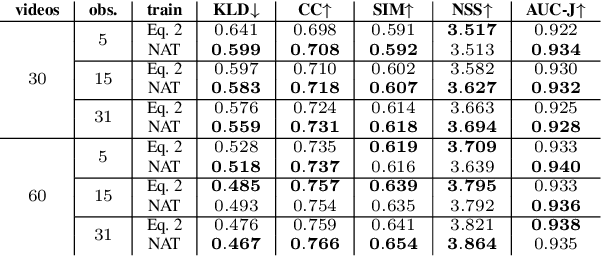

Deep-learning-based algorithms have led to impressive results in visual-saliency prediction, but the impact of noise in training gaze data has been largely overlooked. This issue is especially relevant for videos, where the gaze data tends to be incomplete, and thus noisier, compared to images. Therefore, we propose a noise-aware training (NAT) paradigm for visual-saliency prediction that quantifies the uncertainty arising from gaze data incompleteness and inaccuracy, and accounts for it in training. We demonstrate the advantage of NAT independently of the adopted model architecture, loss function, or training dataset. Given its robustness to the noise in incomplete training datasets, NAT ushers in the possibility of designing gaze datasets with fewer human subjects. We also introduce the first dataset that offers a video-game context for video-saliency research, with rich temporal semantics, and multiple gaze attractors per frame.
Binary TTC: A Temporal Geofence for Autonomous Navigation
Jan 12, 2021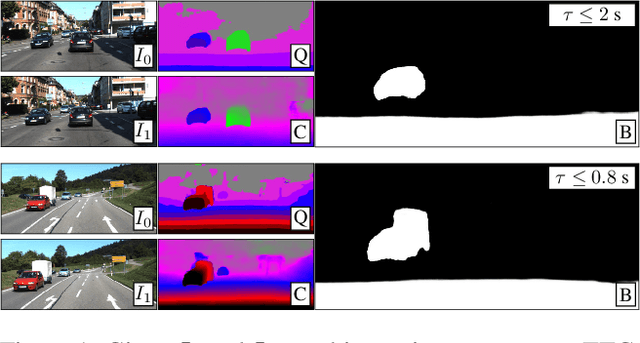
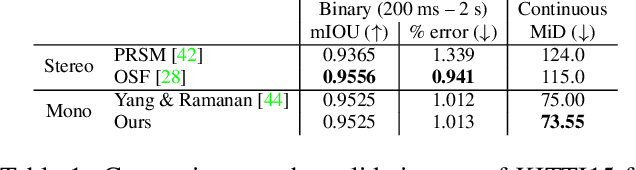

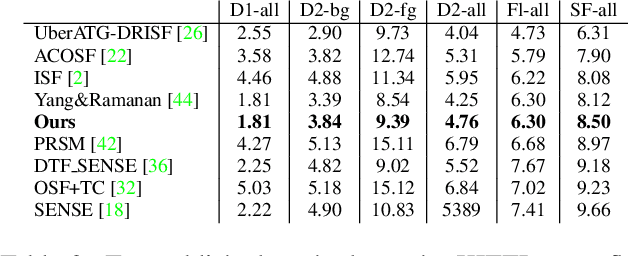
Time-to-contact (TTC), the time for an object to collide with the observer's plane, is a powerful tool for path planning: it is potentially more informative than the depth, velocity, and acceleration of objects in the scene -- even for humans. TTC presents several advantages, including requiring only a monocular, uncalibrated camera. However, regressing TTC for each pixel is not straightforward, and most existing methods make over-simplifying assumptions about the scene. We address this challenge by estimating TTC via a series of simpler, binary classifications. We predict with low latency whether the observer will collide with an obstacle within a certain time, which is often more critical than knowing exact, per-pixel TTC. For such scenarios, our method offers a temporal geofence in 6.4 ms -- over 25x faster than existing methods. Our approach can also estimate per-pixel TTC with arbitrarily fine quantization (including continuous values), when the computational budget allows for it. To the best of our knowledge, our method is the first to offer TTC information (binary or coarsely quantized) at sufficiently high frame-rates for practical use.
Bi3D: Stereo Depth Estimation via Binary Classifications
Jun 01, 2020Stereo-based depth estimation is a cornerstone of computer vision, with state-of-the-art methods delivering accurate results in real time. For several applications such as autonomous navigation, however, it may be useful to trade accuracy for lower latency. We present Bi3D, a method that estimates depth via a series of binary classifications. Rather than testing if objects are at a particular depth $D$, as existing stereo methods do, it classifies them as being closer or farther than $D$. This property offers a powerful mechanism to balance accuracy and latency. Given a strict time budget, Bi3D can detect objects closer than a given distance in as little as a few milliseconds, or estimate depth with arbitrarily coarse quantization, with complexity linear with the number of quantization levels. Bi3D can also use the allotted quantization levels to get continuous depth, but in a specific depth range. For standard stereo (i.e., continuous depth on the whole range), our method is close to or on par with state-of-the-art, finely tuned stereo methods.
Meshlet Priors for 3D Mesh Reconstruction
Jan 06, 2020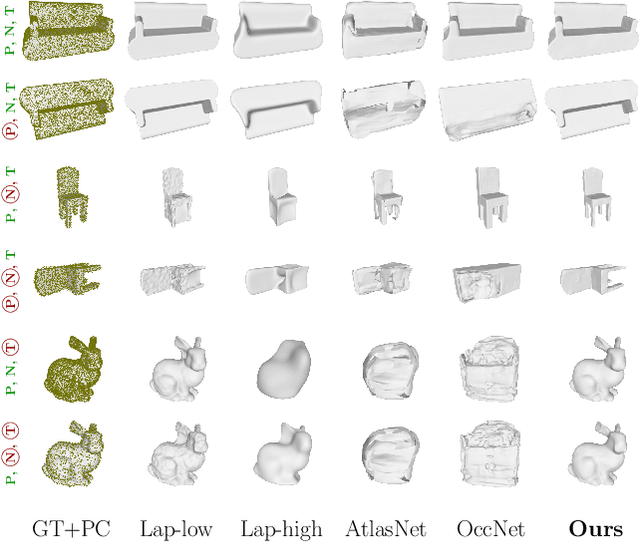
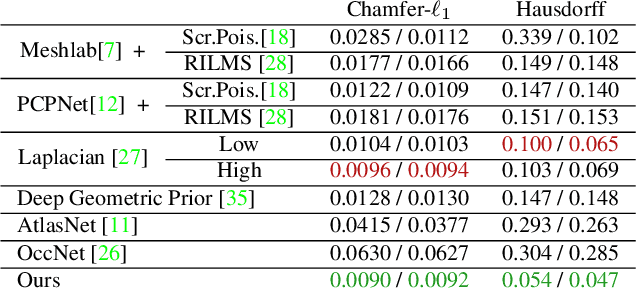

Estimating a mesh from an unordered set of sparse, noisy 3D points is a challenging problem that requires carefully selected priors. Existing hand-crafted priors, such as smoothness regularizers, impose an undesirable trade-off between attenuating noise and preserving local detail. Recent deep-learning approaches produce impressive results by learning priors directly from the data. However, the priors are learned at the object level, which makes these algorithms class-specific, and even sensitive to the pose of the object. We introduce meshlets, small patches of mesh that we use to learn local shape priors. Meshlets act as a dictionary of local features and thus allow to use learned priors to reconstruct object meshes in any pose and from unseen classes, even when the noise is large and the samples sparse.
PieAPP: Perceptual Image-Error Assessment through Pairwise Preference
Jun 06, 2018
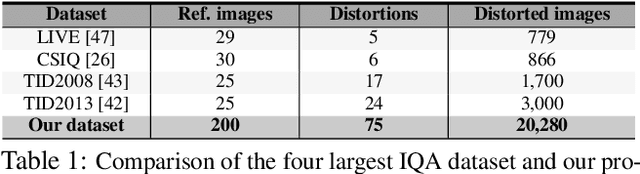
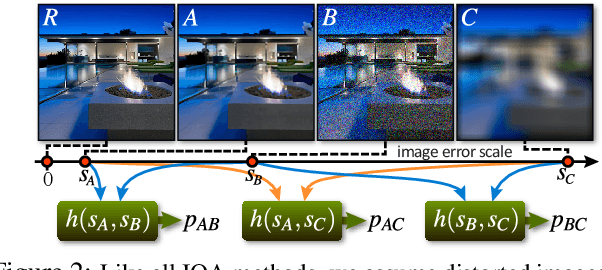
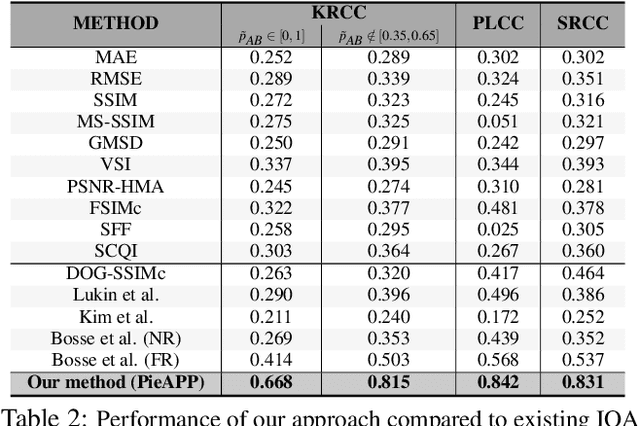
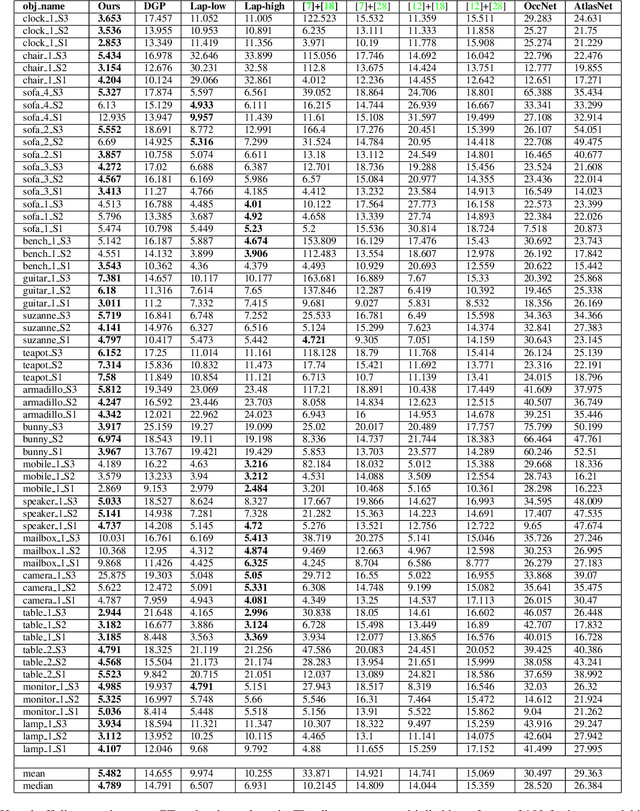
The ability to estimate the perceptual error between images is an important problem in computer vision with many applications. Although it has been studied extensively, however, no method currently exists that can robustly predict visual differences like humans. Some previous approaches used hand-coded models, but they fail to model the complexity of the human visual system. Others used machine learning to train models on human-labeled datasets, but creating large, high-quality datasets is difficult because people are unable to assign consistent error labels to distorted images. In this paper, we present a new learning-based method that is the first to predict perceptual image error like human observers. Since it is much easier for people to compare two given images and identify the one more similar to a reference than to assign quality scores to each, we propose a new, large-scale dataset labeled with the probability that humans will prefer one image over another. We then train a deep-learning model using a novel, pairwise-learning framework to predict the preference of one distorted image over the other. Our key observation is that our trained network can then be used separately with only one distorted image and a reference to predict its perceptual error, without ever being trained on explicit human perceptual-error labels. The perceptual error estimated by our new metric, PieAPP, is well-correlated with human opinion. Furthermore, it significantly outperforms existing algorithms, beating the state-of-the-art by almost 3x on our test set in terms of binary error rate, while also generalizing to new kinds of distortions, unlike previous learning-based methods.
* 8 pages; 5 figures; proceedings of CVPR 2018
Patch-Based Image Hallucination for Super Resolution with Detail Reconstruction from Similar Sample Images
Jun 03, 2018

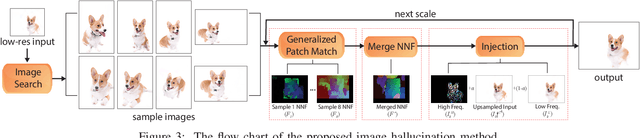

Image hallucination and super-resolution have been studied for decades, and many approaches have been proposed to upsample low-resolution images using information from the images themselves, multiple example images, or large image databases. However, most of this work has focused exclusively on small magnification levels because the algorithms simply sharpen the blurry edges in the upsampled images - no actual new detail is typically reconstructed in the final result. In this paper, we present a patch-based algorithm for image hallucination which, for the first time, properly synthesizes novel high frequency detail. To do this, we pose the synthesis problem as a patch-based optimization which inserts coherent, high-frequency detail from contextually-similar images of the same physical scene/subject provided from either a personal image collection or a large online database. The resulting image is visually plausible and contains coherent high frequency information. We demonstrate the robustness of our algorithm by testing it on a large number of images and show that its performance is considerably superior to all state-of-the-art approaches, a result that is verified to be statistically significant through a randomized user study.
Improving the Resolution of CNN Feature Maps Efficiently with Multisampling
May 28, 2018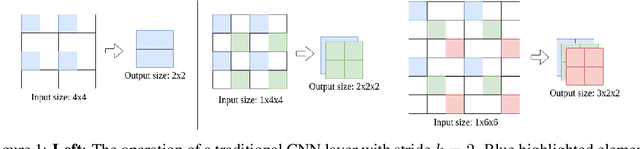
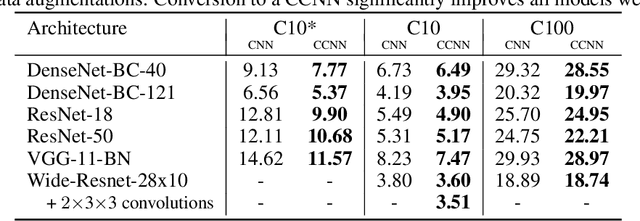

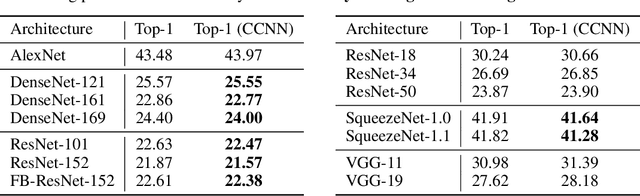
We describe a new class of subsampling techniques for CNNs, termed multisampling, that significantly increases the amount of information kept by feature maps through subsampling layers. One version of our method, which we call checkered subsampling, significantly improves the accuracy of state-of-the-art architectures such as DenseNet and ResNet without any additional parameters and, remarkably, improves the accuracy of certain pretrained ImageNet models without any training or fine-tuning. We glean new insight into the nature of data augmentations and demonstrate, for the first time, that coarse feature maps are significantly bottlenecking the performance of neural networks in image classification.
Localization-Aware Active Learning for Object Detection
Jan 16, 2018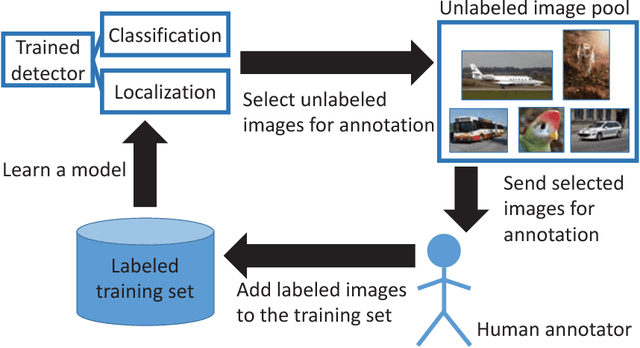
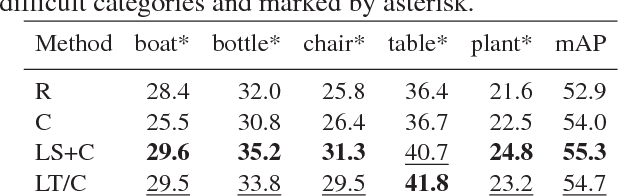

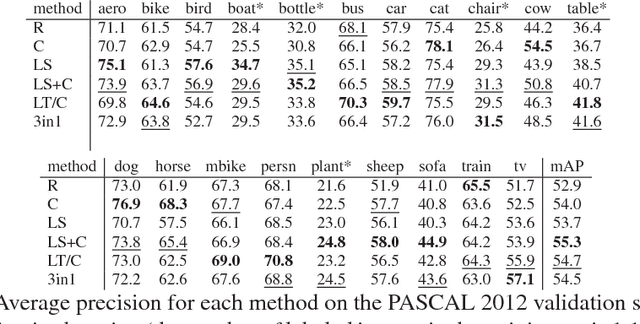
Active learning - a class of algorithms that iteratively searches for the most informative samples to include in a training dataset - has been shown to be effective at annotating data for image classification. However, the use of active learning for object detection is still largely unexplored as determining informativeness of an object-location hypothesis is more difficult. In this paper, we address this issue and present two metrics for measuring the informativeness of an object hypothesis, which allow us to leverage active learning to reduce the amount of annotated data needed to achieve a target object detection performance. Our first metric measures 'localization tightness' of an object hypothesis, which is based on the overlapping ratio between the region proposal and the final prediction. Our second metric measures 'localization stability' of an object hypothesis, which is based on the variation of predicted object locations when input images are corrupted by noise. Our experimental results show that by augmenting a conventional active-learning algorithm designed for classification with the proposed metrics, the amount of labeled training data required can be reduced up to 25%. Moreover, on PASCAL 2007 and 2012 datasets our localization-stability method has an average relative improvement of 96.5% and 81.9% over the baseline method using classification only.
GraphMatch: Efficient Large-Scale Graph Construction for Structure from Motion
Oct 04, 2017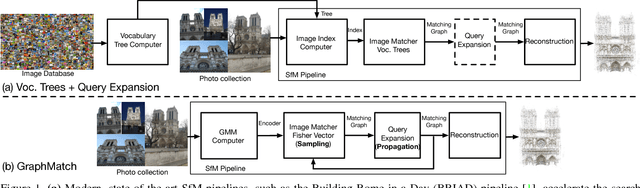
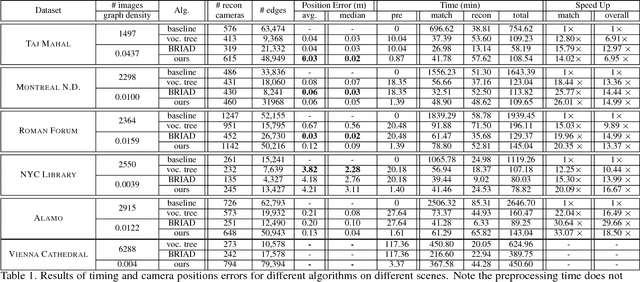
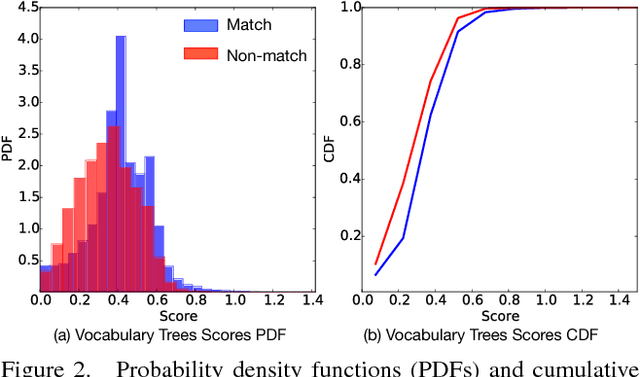
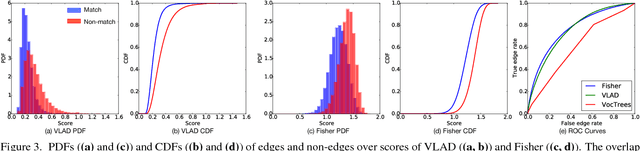
We present GraphMatch, an approximate yet efficient method for building the matching graph for large-scale structure-from-motion (SfM) pipelines. Unlike modern SfM pipelines that use vocabulary (Voc.) trees to quickly build the matching graph and avoid a costly brute-force search of matching image pairs, GraphMatch does not require an expensive offline pre-processing phase to construct a Voc. tree. Instead, GraphMatch leverages two priors that can predict which image pairs are likely to match, thereby making the matching process for SfM much more efficient. The first is a score computed from the distance between the Fisher vectors of any two images. The second prior is based on the graph distance between vertices in the underlying matching graph. GraphMatch combines these two priors into an iterative "sample-and-propagate" scheme similar to the PatchMatch algorithm. Its sampling stage uses Fisher similarity priors to guide the search for matching image pairs, while its propagation stage explores neighbors of matched pairs to find new ones with a high image similarity score. Our experiments show that GraphMatch finds the most image pairs as compared to competing, approximate methods while at the same time being the most efficient.
ANSAC: Adaptive Non-minimal Sample and Consensus
Sep 27, 2017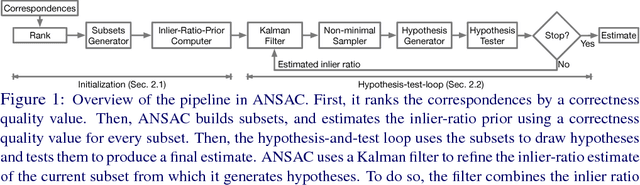
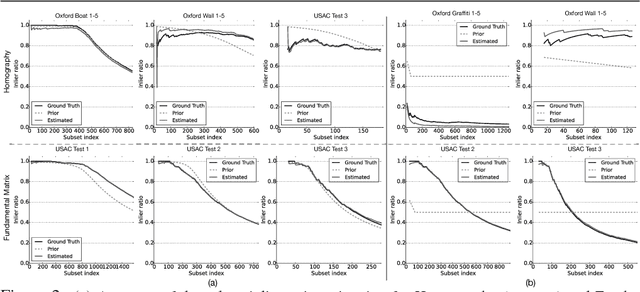
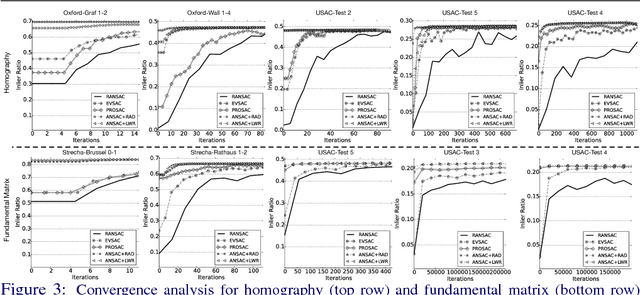
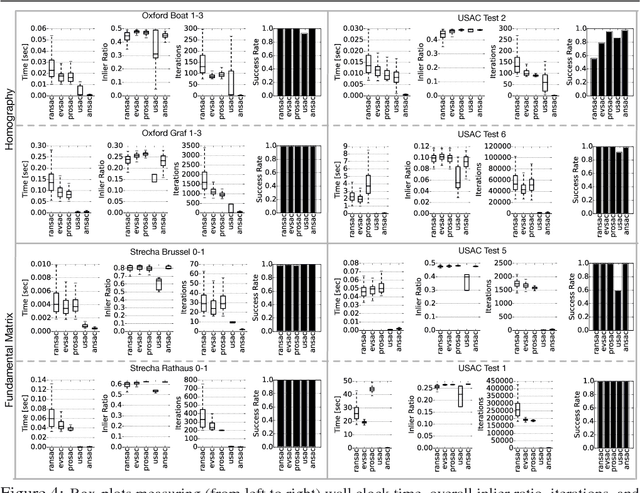
While RANSAC-based methods are robust to incorrect image correspondences (outliers), their hypothesis generators are not robust to correct image correspondences (inliers) with positional error (noise). This slows down their convergence because hypotheses drawn from a minimal set of noisy inliers can deviate significantly from the optimal model. This work addresses this problem by introducing ANSAC, a RANSAC-based estimator that accounts for noise by adaptively using more than the minimal number of correspondences required to generate a hypothesis. ANSAC estimates the inlier ratio (the fraction of correct correspondences) of several ranked subsets of candidate correspondences and generates hypotheses from them. Its hypothesis-generation mechanism prioritizes the use of subsets with high inlier ratio to generate high-quality hypotheses. ANSAC uses an early termination criterion that keeps track of the inlier ratio history and terminates when it has not changed significantly for a period of time. The experiments show that ANSAC finds good homography and fundamental matrix estimates in a few iterations, consistently outperforming state-of-the-art methods.