 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of LLM for Education
Dec 26, 2023


This study proposes a method for distilling the knowledge of fine-tuned Large Language Models (LLMs) into a smaller, more efficient, and accurate neural network, specifically targeting the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model using the prediction probabilities of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To test this approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three other datasets with student-written responses. We also compared performance with original neural network (NN) models to validate the accuracy. Results have shown that the NN and distilled student models have comparable accuracy to the teacher model for the 7T dataset; however, other datasets have shown significantly lower accuracy (28% on average) for NN, though our proposed distilled model is still able to achieve 12\% higher accuracy than NN. Furthermore, the student model size ranges from 0.1M to 0.02M, 100 times smaller in terms of parameters and ten times smaller compared with the original output model size. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
Optimal Sampling Designs for Multi-dimensional Streaming Time Series with Application to Power Grid Sensor Data
Mar 14, 2023



The Internet of Things (IoT) system generates massive high-speed temporally correlated streaming data and is often connected with online inference tasks under computational or energy constraints. Online analysis of these streaming time series data often faces a trade-off between statistical efficiency and computational cost. One important approach to balance this trade-off is sampling, where only a small portion of the sample is selected for the model fitting and update. Motivated by the demands of dynamic relationship analysis of IoT system, we study the data-dependent sample selection and online inference problem for a multi-dimensional streaming time series, aiming to provide low-cost real-time analysis of high-speed power grid electricity consumption data. Inspired by D-optimality criterion in design of experiments, we propose a class of online data reduction methods that achieve an optimal sampling criterion and improve the computational efficiency of the online analysis. We show that the optimal solution amounts to a strategy that is a mixture of Bernoulli sampling and leverage score sampling. The leverage score sampling involves auxiliary estimations that have a computational advantage over recursive least squares updates. Theoretical properties of the auxiliary estimations involved are also discussed. When applied to European power grid consumption data, the proposed leverage score based sampling methods outperform the benchmark sampling method in online estimation and prediction. The general applicability of the sampling-assisted online estimation method is assessed via simulation studies.
An optimal transport approach for selecting a representative subsample with application in efficient kernel density estimation
May 31, 2022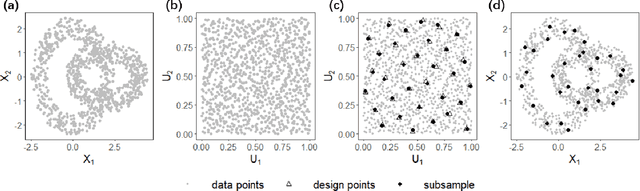
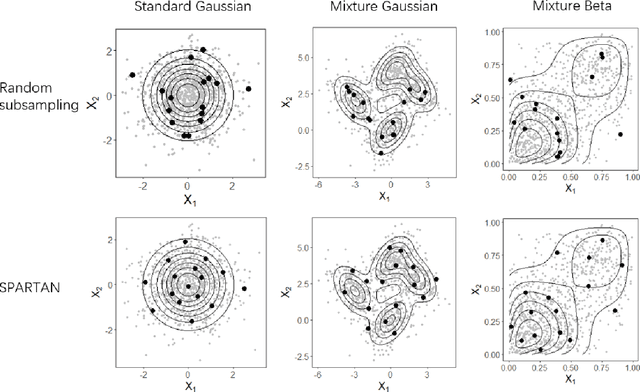
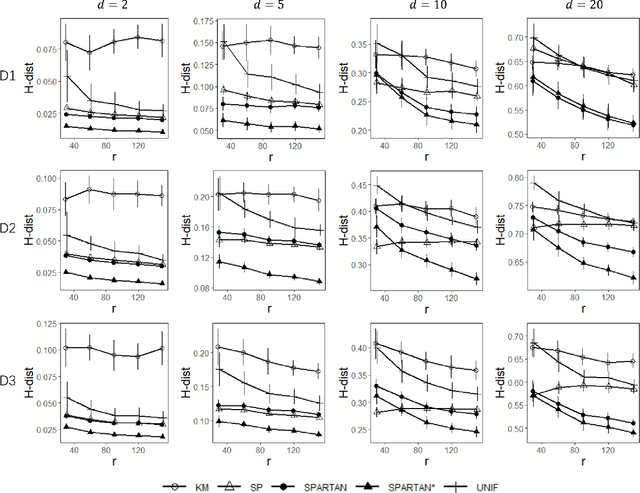
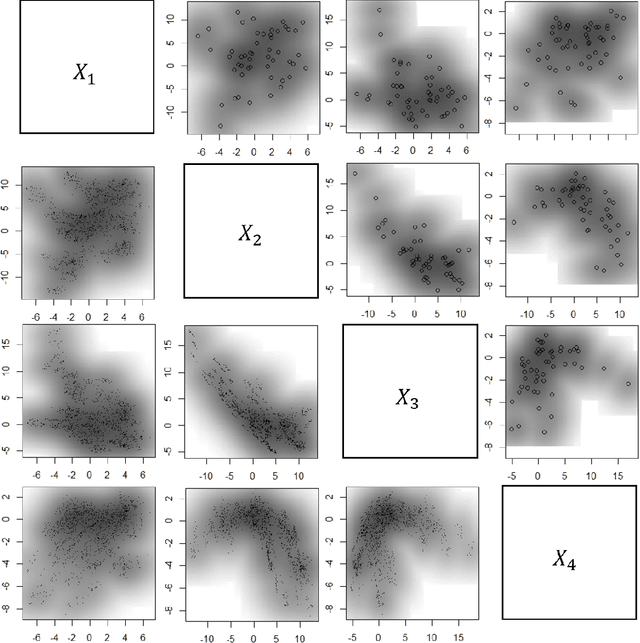
Subsampling methods aim to select a subsample as a surrogate for the observed sample. Such methods have been used pervasively in large-scale data analytics, active learning, and privacy-preserving analysis in recent decades. Instead of model-based methods, in this paper, we study model-free subsampling methods, which aim to identify a subsample that is not confined by model assumptions. Existing model-free subsampling methods are usually built upon clustering techniques or kernel tricks. Most of these methods suffer from either a large computational burden or a theoretical weakness. In particular, the theoretical weakness is that the empirical distribution of the selected subsample may not necessarily converge to the population distribution. Such computational and theoretical limitations hinder the broad applicability of model-free subsampling methods in practice. We propose a novel model-free subsampling method by utilizing optimal transport techniques. Moreover, we develop an efficient subsampling algorithm that is adaptive to the unknown probability density function. Theoretically, we show the selected subsample can be used for efficient density estimation by deriving the convergence rate for the proposed subsample kernel density estimator. We also provide the optimal bandwidth for the proposed estimator. Numerical studies on synthetic and real-world datasets demonstrate the performance of the proposed method is superior.
Managing dataset shift by adversarial validation for credit scoring
Dec 19, 2021
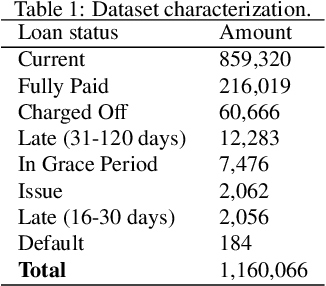
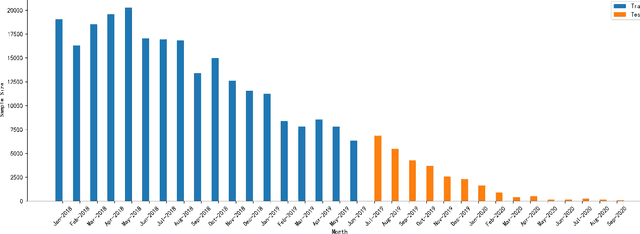

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.
Large-scale optimal transport map estimation using projection pursuit
Jun 09, 2021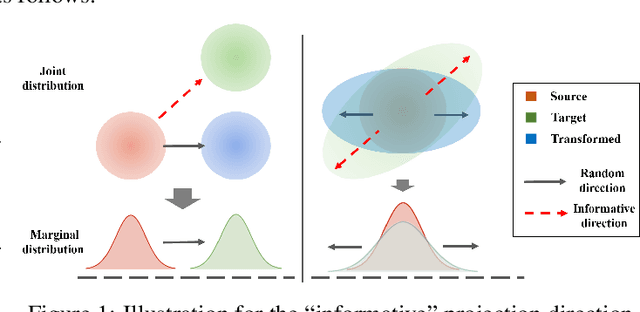

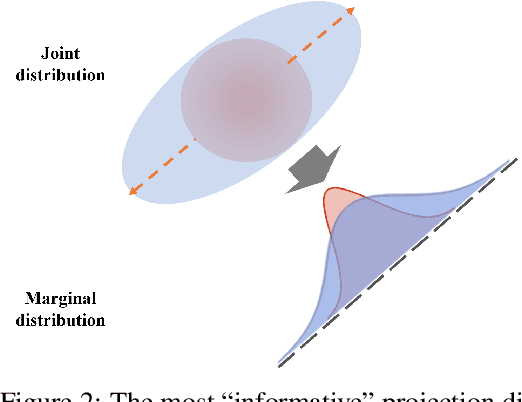

This paper studies the estimation of large-scale optimal transport maps (OTM), which is a well-known challenging problem owing to the curse of dimensionality. Existing literature approximates the large-scale OTM by a series of one-dimensional OTM problems through iterative random projection. Such methods, however, suffer from slow or none convergence in practice due to the nature of randomly selected projection directions. Instead, we propose an estimation method of large-scale OTM by combining the idea of projection pursuit regression and sufficient dimension reduction. The proposed method, named projection pursuit Monge map (PPMM), adaptively selects the most ``informative'' projection direction in each iteration. We theoretically show the proposed dimension reduction method can consistently estimate the most ``informative'' projection direction in each iteration. Furthermore, the PPMM algorithm weakly convergences to the target large-scale OTM in a reasonable number of steps. Empirically, PPMM is computationally easy and converges fast. We assess its finite sample performance through the applications of Wasserstein distance estimation and generative models.
Sufficient dimension reduction for classification using principal optimal transport direction
Oct 21, 2020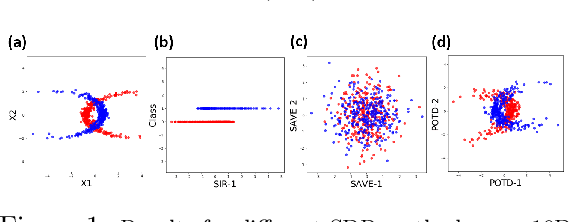
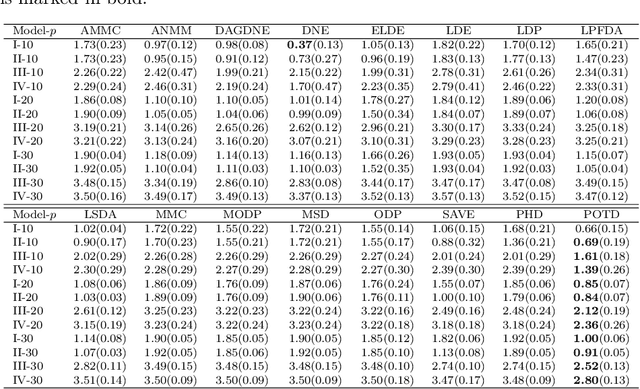
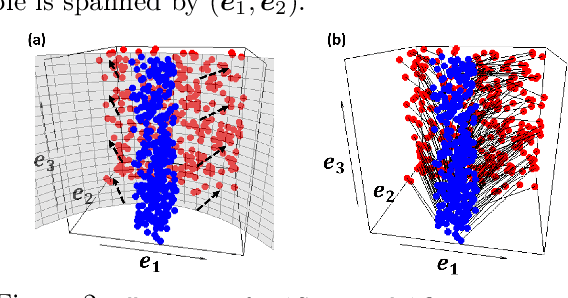
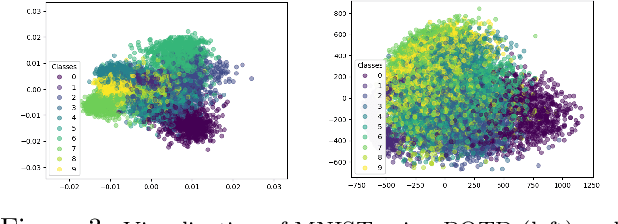
Sufficient dimension reduction is used pervasively as a supervised dimension reduction approach. Most existing sufficient dimension reduction methods are developed for data with a continuous response and may have an unsatisfactory performance for the categorical response, especially for the binary-response. To address this issue, we propose a novel estimation method of sufficient dimension reduction subspace (SDR subspace) using optimal transport. The proposed method, named principal optimal transport direction (POTD), estimates the basis of the SDR subspace using the principal directions of the optimal transport coupling between the data respecting different response categories. The proposed method also reveals the relationship among three seemingly irrelevant topics, i.e., sufficient dimension reduction, support vector machine, and optimal transport. We study the asymptotic properties of POTD and show that in the cases when the class labels contain no error, POTD estimates the SDR subspace exclusively. Empirical studies show POTD outperforms most of the state-of-the-art linear dimension reduction methods.
A Review on Modern Computational Optimal Transport Methods with Applications in Biomedical Research
Sep 10, 2020
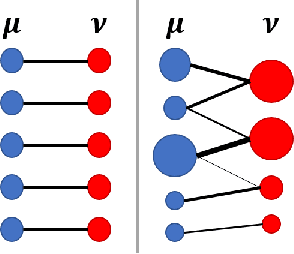
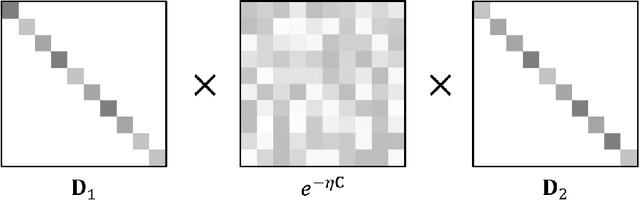
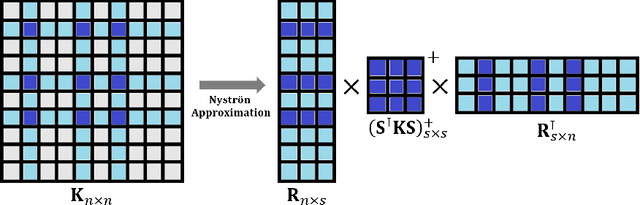
Optimal transport has been one of the most exciting subjects in mathematics, starting from the 18th century. As a powerful tool to transport between two probability measures, optimal transport methods have been reinvigorated nowadays in a remarkable proliferation of modern data science applications. To meet the big data challenges, various computational tools have been developed in the recent decade to accelerate the computation for optimal transport methods. In this review, we present some cutting-edge computational optimal transport methods with a focus on the regularization-based methods and the projection-based methods. We discuss their real-world applications in biomedical research.
Asymptotic Analysis of Sampling Estimators for Randomized Numerical Linear Algebra Algorithms
Feb 24, 2020
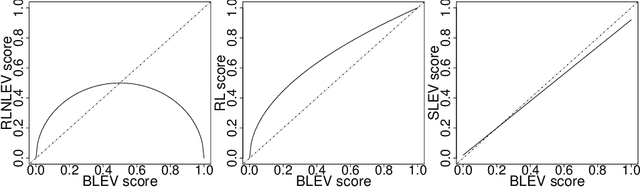
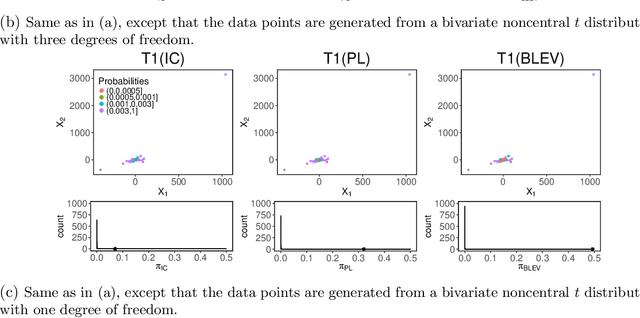
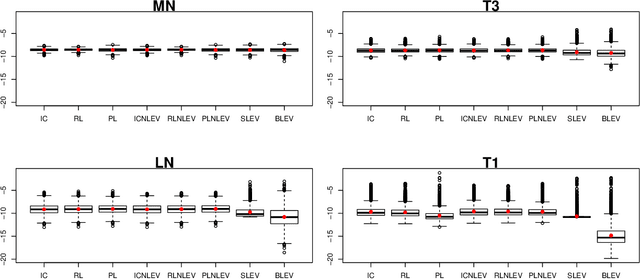
The statistical analysis of Randomized Numerical Linear Algebra (RandNLA) algorithms within the past few years has mostly focused on their performance as point estimators. However, this is insufficient for conducting statistical inference, e.g., constructing confidence intervals and hypothesis testing, since the distribution of the estimator is lacking. In this article, we develop an asymptotic analysis to derive the distribution of RandNLA sampling estimators for the least-squares problem. In particular, we derive the asymptotic distribution of a general sampling estimator with arbitrary sampling probabilities. The analysis is conducted in two complementary settings, i.e., when the objective of interest is to approximate the full sample estimator or is to infer the underlying ground truth model parameters. For each setting, we show that the sampling estimator is asymptotically normally distributed under mild regularity conditions. Moreover, the sampling estimator is asymptotically unbiased in both settings. Based on our asymptotic analysis, we use two criteria, the Asymptotic Mean Squared Error (AMSE) and the Expected Asymptotic Mean Squared Error (EAMSE), to identify optimal sampling probabilities. Several of these optimal sampling probability distributions are new to the literature, e.g., the root leverage sampling estimator and the predictor length sampling estimator. Our theoretical results clarify the role of leverage in the sampling process, and our empirical results demonstrate improvements over existing methods.
Minimax Nonparametric Two-sample Test
Nov 08, 2019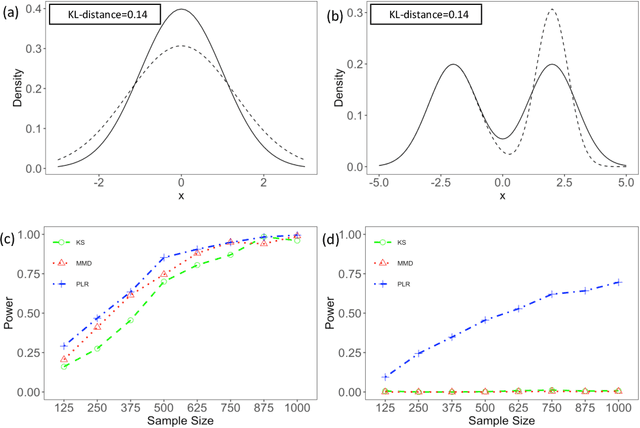
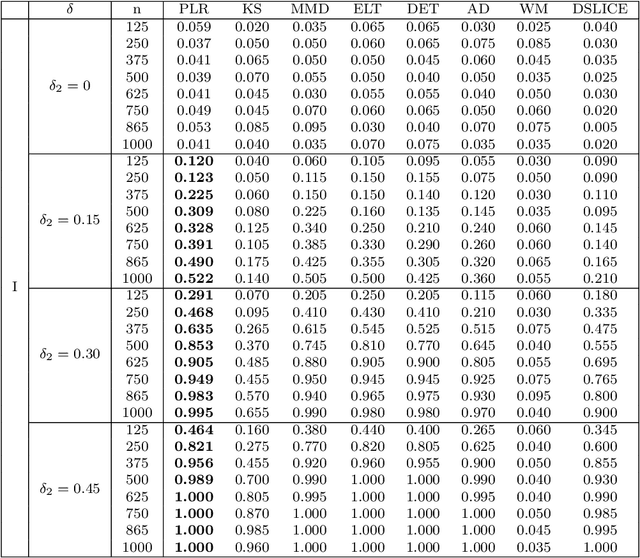
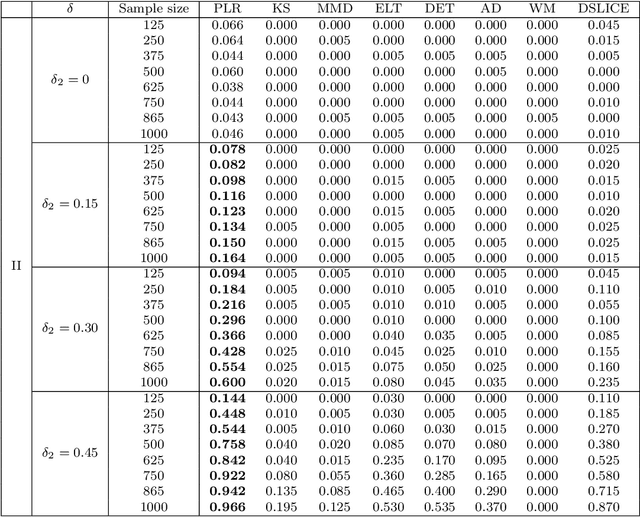
We consider the problem of comparing probability densities between two groups. To model the complex pattern of the underlying densities, we formulate the problem as a nonparametric density hypothesis testing problem. The major difficulty is that conventional tests may fail to distinguish the alternative from the null hypothesis under the controlled type I error. In this paper, we model log-transformed densities in a tensor product reproducing kernel Hilbert space (RKHS) and propose a probabilistic decomposition of this space. Under such a decomposition, we quantify the difference of the densities between two groups by the component norm in the probabilistic decomposition. Based on the Bernstein width, a sharp minimax lower bound of the distinguishable rate is established for the nonparametric two-sample test. We then propose a penalized likelihood ratio (PLR) test possessing the Wilks' phenomenon with an asymptotically Chi-square distributed test statistic and achieving the established minimax testing rate. Simulations and real applications demonstrate that the proposed test outperforms the conventional approaches under various scenarios.
Optimal Subsampling for Large Sample Logistic Regression
Mar 07, 2018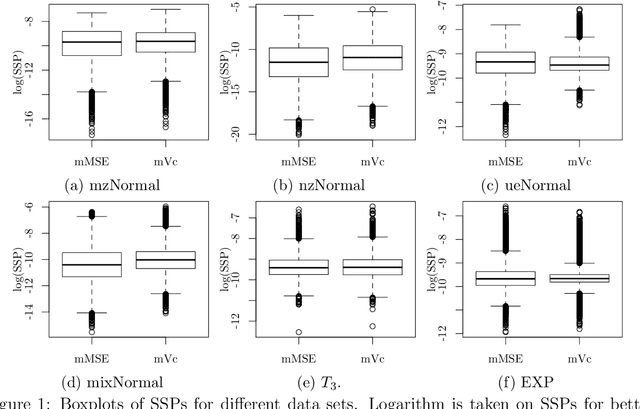
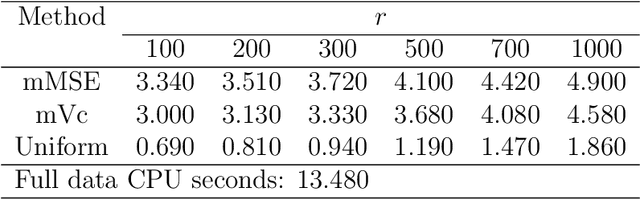
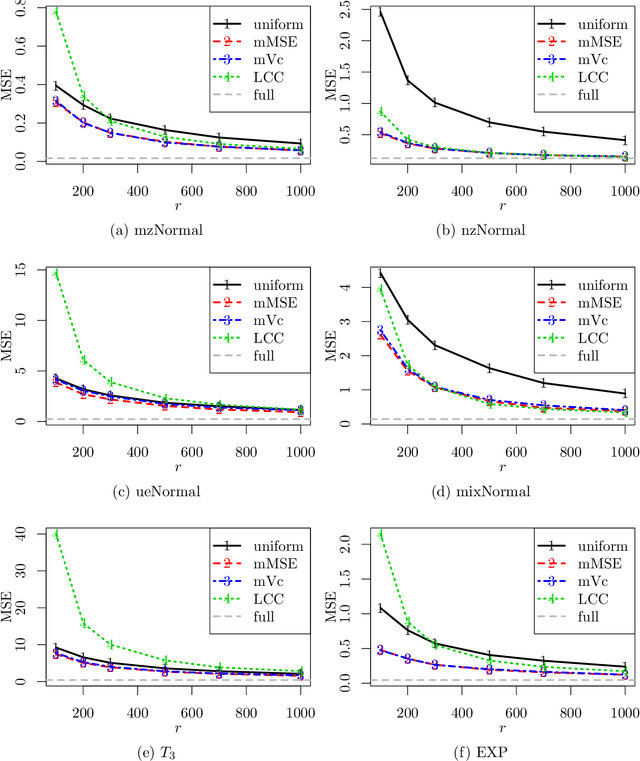
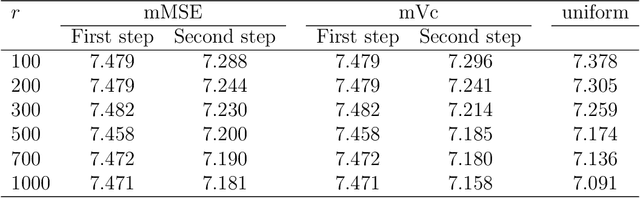
For massive data, the family of subsampling algorithms is popular to downsize the data volume and reduce computational burden. Existing studies focus on approximating the ordinary least squares estimate in linear regression, where statistical leverage scores are often used to define subsampling probabilities. In this paper, we propose fast subsampling algorithms to efficiently approximate the maximum likelihood estimate in logistic regression. We first establish consistency and asymptotic normality of the estimator from a general subsampling algorithm, and then derive optimal subsampling probabilities that minimize the asymptotic mean squared error of the resultant estimator. An alternative minimization criterion is also proposed to further reduce the computational cost. The optimal subsampling probabilities depend on the full data estimate, so we develop a two-step algorithm to approximate the optimal subsampling procedure. This algorithm is computationally efficient and has a significant reduction in computing time compared to the full data approach. Consistency and asymptotic normality of the estimator from a two-step algorithm are also established. Synthetic and real data sets are used to evaluate the practical performance of the proposed method.