 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePierre Ablin
Momentum Residual Neural Networks
Feb 15, 2021
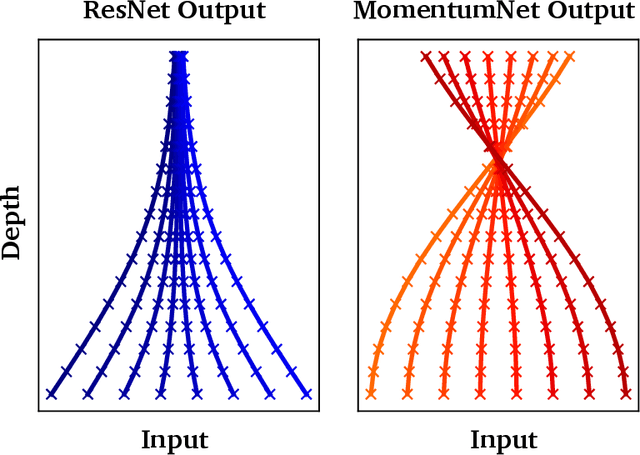

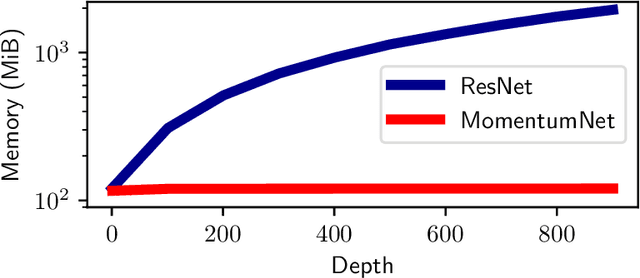

The training of deep residual neural networks (ResNets) with backpropagation has a memory cost that increases linearly with respect to the depth of the network. A simple way to circumvent this issue is to use reversible architectures. In this paper, we propose to change the forward rule of a ResNet by adding a momentum term. The resulting networks, momentum residual neural networks (MomentumNets), are invertible. Unlike previous invertible architectures, they can be used as a drop-in replacement for any existing ResNet block. We show that MomentumNets can be interpreted in the infinitesimal step size regime as second-order ordinary differential equations (ODEs) and exactly characterize how adding momentum progressively increases the representation capabilities of MomentumNets. Our analysis reveals that MomentumNets can learn any linear mapping up to a multiplicative factor, while ResNets cannot. In a learning to optimize setting, where convergence to a fixed point is required, we show theoretically and empirically that our method succeeds while existing invertible architectures fail. We show on CIFAR and ImageNet that MomentumNets have the same accuracy as ResNets, while having a much smaller memory footprint, and show that pre-trained MomentumNets are promising for fine-tuning models.
Fast and accurate optimization on the orthogonal manifold without retraction
Feb 15, 2021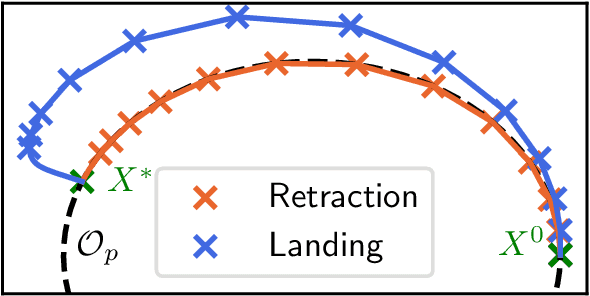
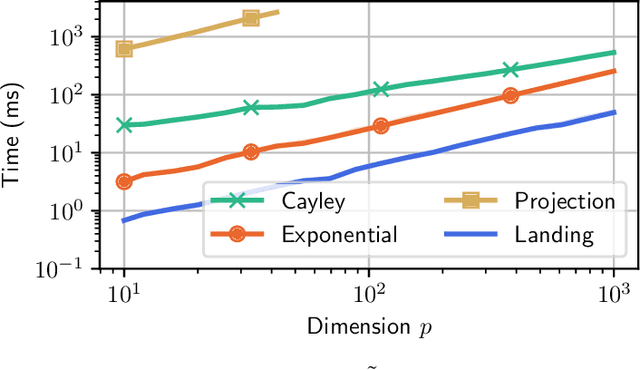
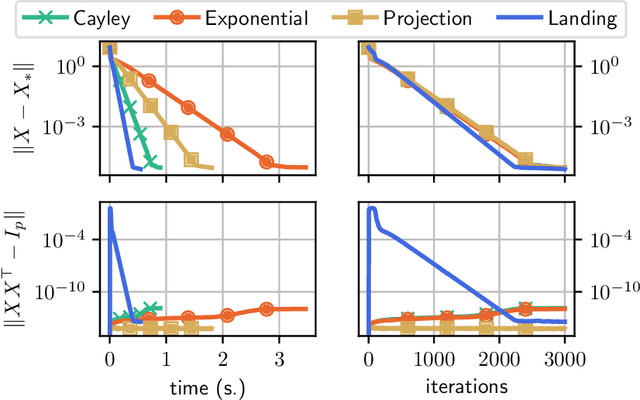
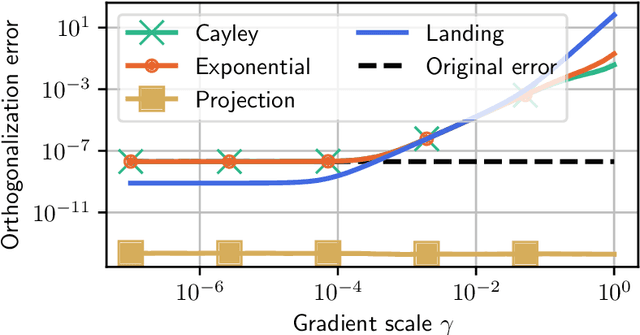
We consider the problem of minimizing a function over the manifold of orthogonal matrices. The majority of algorithms for this problem compute a direction in the tangent space, and then use a retraction to move in that direction while staying on the manifold. Unfortunately, the numerical computation of retractions on the orthogonal manifold always involves some expensive linear algebra operation, such as matrix inversion or matrix square-root. These operations quickly become expensive as the dimension of the matrices grows. To bypass this limitation, we propose the landing algorithm which does not involve retractions. The algorithm is not constrained to stay on the manifold but its evolution is driven by a potential energy which progressively attracts it towards the manifold. One iteration of the landing algorithm only involves matrix multiplications, which makes it cheap compared to its retraction counterparts. We provide an analysis of the convergence of the algorithm, and demonstrate its promises on large-scale problems, where it is faster and less prone to numerical errors than retraction-based methods.
Deep orthogonal linear networks are shallow
Nov 27, 2020We consider the problem of training a deep orthogonal linear network, which consists of a product of orthogonal matrices, with no non-linearity in-between. We show that training the weights with Riemannian gradient descent is equivalent to training the whole factorization by gradient descent. This means that there is no effect of overparametrization and implicit bias at all in this setting: training such a deep, overparametrized, network is perfectly equivalent to training a one-layer shallow network.
Modeling Shared Responses in Neuroimaging Studies through MultiView ICA
Jun 12, 2020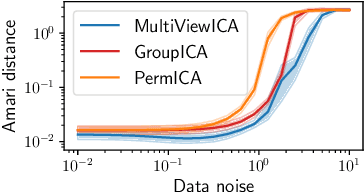
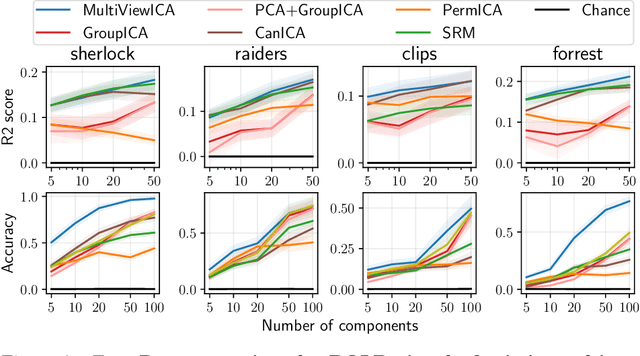
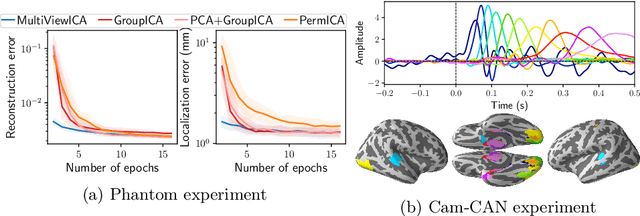
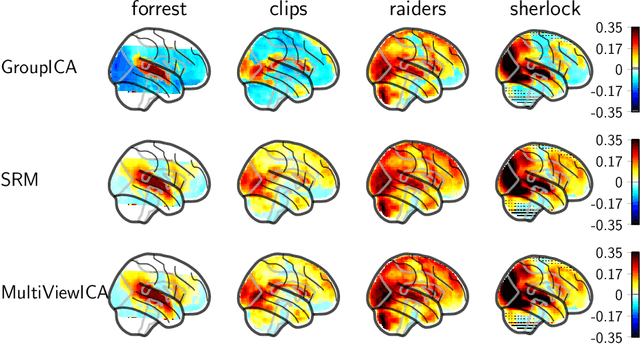
Group studies involving large cohorts of subjects are important to draw general conclusions about brain functional organization. However, the aggregation of data coming from multiple subjects is challenging, since it requires accounting for large variability in anatomy, functional topography and stimulus response across individuals. Data modeling is especially hard for ecologically relevant conditions such as movie watching, where the experimental setup does not imply well-defined cognitive operations. We propose a novel MultiView Independent Component Analysis (ICA) model for group studies, where data from each subject are modeled as a linear combination of shared independent sources plus noise. Contrary to most group-ICA procedures, the likelihood of the model is available in closed form. We develop an alternate quasi-Newton method for maximizing the likelihood, which is robust and converges quickly. We demonstrate the usefulness of our approach first on fMRI data, where our model demonstrates improved sensitivity in identifying common sources among subjects. Moreover, the sources recovered by our model exhibit lower between-session variability than other methods.On magnetoencephalography (MEG) data, our method yields more accurate source localization on phantom data. Applied on 200 subjects from the Cam-CAN dataset it reveals a clear sequence of evoked activity in sensor and source space. The code is freely available at https://github.com/hugorichard/multiviewica.
Super-efficiency of automatic differentiation for functions defined as a minimum
Feb 10, 2020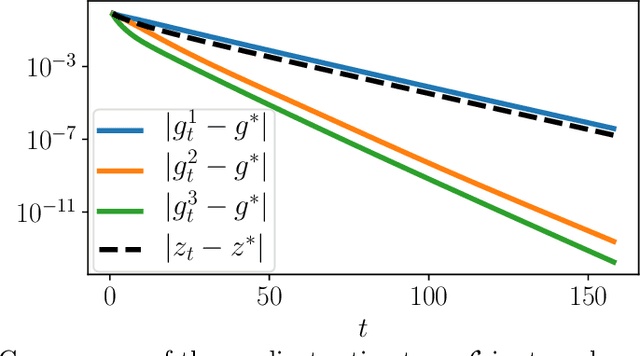


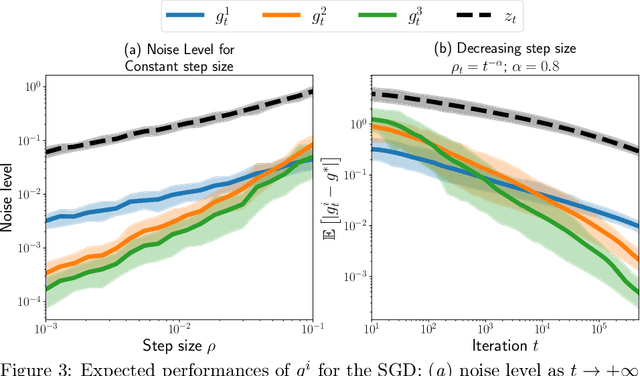
In min-min optimization or max-min optimization, one has to compute the gradient of a function defined as a minimum. In most cases, the minimum has no closed-form, and an approximation is obtained via an iterative algorithm. There are two usual ways of estimating the gradient of the function: using either an analytic formula obtained by assuming exactness of the approximation, or automatic differentiation through the algorithm. In this paper, we study the asymptotic error made by these estimators as a function of the optimization error. We find that the error of the automatic estimator is close to the square of the error of the analytic estimator, reflecting a super-efficiency phenomenon. The convergence of the automatic estimator greatly depends on the convergence of the Jacobian of the algorithm. We analyze it for gradient descent and stochastic gradient descent and derive convergence rates for the estimators in these cases. Our analysis is backed by numerical experiments on toy problems and on Wasserstein barycenter computation. Finally, we discuss the computational complexity of these estimators and give practical guidelines to chose between them.
Manifold-regression to predict from MEG/EEG brain signals without source modeling
Jun 07, 2019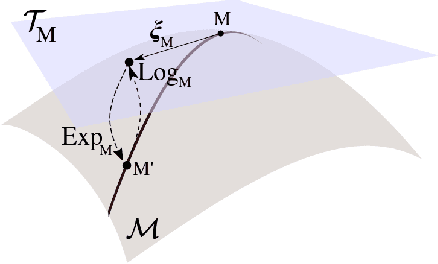
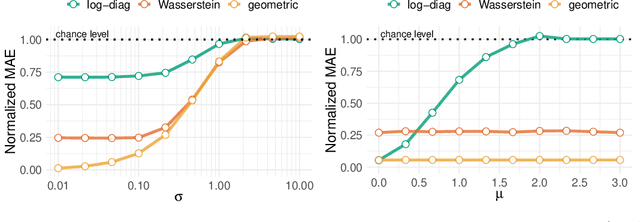
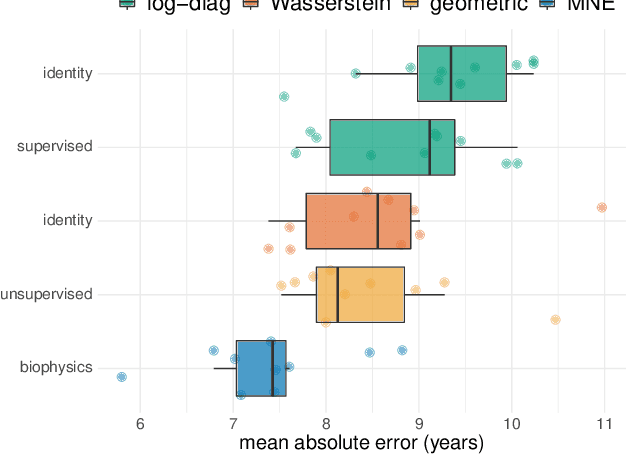
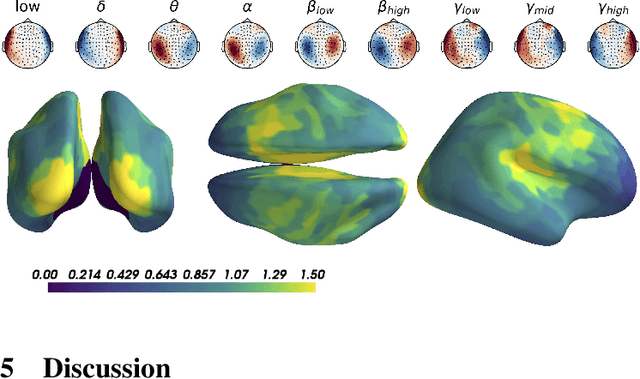
Magnetoencephalography and electroencephalography (M/EEG) can reveal neuronal dynamics non-invasively in real-time and are therefore appreciated methods in medicine and neuroscience. Recent advances in modeling brain-behavior relationships have highlighted the effectiveness of Riemannian geometry for summarizing the spatially correlated time-series from M/EEG in terms of their covariance. However, after artefact-suppression, M/EEG data is often rank deficient which limits the application of Riemannian concepts. In this article, we focus on the task of regression with rank-reduced covariance matrices. We study two Riemannian approaches that vectorize the M/EEG covariance between-sensors through projection into a tangent space. The Wasserstein distance readily applies to rank-reduced data but lacks affine-invariance. This can be overcome by finding a common subspace in which the covariance matrices are full rank, enabling the affine-invariant geometric distance. We investigated the implications of these two approaches in synthetic generative models, which allowed us to control estimation bias of a linear model for prediction. We show that Wasserstein and geometric distances allow perfect out-of-sample prediction on the generative models. We then evaluated the methods on real data with regard to their effectiveness in predicting age from M/EEG covariance matrices. The findings suggest that the data-driven Riemannian methods outperform different sensor-space estimators and that they get close to the performance of biophysics-driven source-localization model that requires MRI acquisitions and tedious data processing. Our study suggests that the proposed Riemannian methods can serve as fundamental building-blocks for automated large-scale analysis of M/EEG.
Learning step sizes for unfolded sparse coding
May 27, 2019
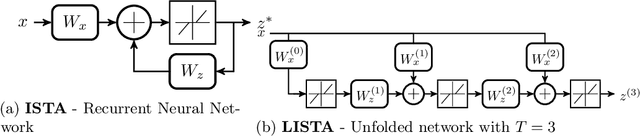
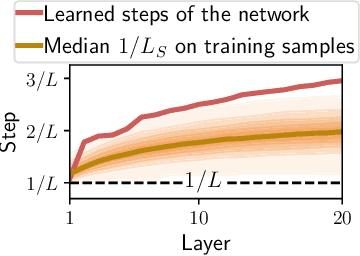
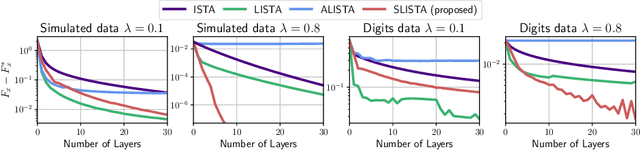
Sparse coding is typically solved by iterative optimization techniques, such as the Iterative Shrinkage-Thresholding Algorithm (ISTA). Unfolding and learning weights of ISTA using neural networks is a practical way to accelerate estimation. In this paper, we study the selection of adapted step sizes for ISTA. We show that a simple step size strategy can improve the convergence rate of ISTA by leveraging the sparsity of the iterates. However, it is impractical in most large-scale applications. Therefore, we propose a network architecture where only the step sizes of ISTA are learned. We demonstrate that for a large class of unfolded algorithms, if the algorithm converges to the solution of the Lasso, its last layers correspond to ISTA with learned step sizes. Experiments show that our method is competitive with state-of-the-art networks when the solutions are sparse enough.
Beyond Pham's algorithm for joint diagonalization
Nov 28, 2018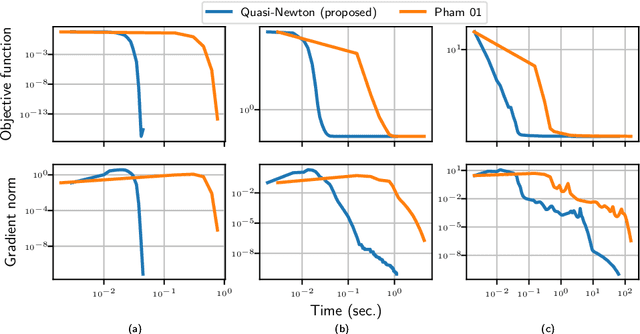
The approximate joint diagonalization of a set of matrices consists in finding a basis in which these matrices are as diagonal as possible. This problem naturally appears in several statistical learning tasks such as blind signal separation. We consider the diagonalization criterion studied in a seminal paper by Pham (2001), and propose a new quasi-Newton method for its optimization. Through numerical experiments on simulated and real datasets, we show that the proposed method outper-forms Pham's algorithm. An open source Python package is released.