 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Roots: Leveraging Temporal Dynamics in Diffusion Trajectories for Origin Attribution
Nov 12, 2024



Diffusion models have revolutionized image synthesis, garnering significant research interest in recent years. Diffusion is an iterative algorithm in which samples are generated step-by-step, starting from pure noise. This process introduces the notion of diffusion trajectories, i.e., paths from the standard Gaussian distribution to the target image distribution. In this context, we study discriminative algorithms operating on these trajectories. Specifically, given a pre-trained diffusion model, we consider the problem of classifying images as part of the training dataset, generated by the model or originating from an external source. Our approach demonstrates the presence of patterns across steps that can be leveraged for classification. We also conduct ablation studies, which reveal that using higher-order gradient features to characterize the trajectories leads to significant performance gains and more robust algorithms.
Adversarial Deep-Unfolding Network for MA-XRF Super-Resolution on Old Master Paintings Using Minimal Training Data
Sep 14, 2024High-quality element distribution maps enable precise analysis of the material composition and condition of Old Master paintings. These maps are typically produced from data acquired through Macro X-ray fluorescence (MA-XRF) scanning, a non-invasive technique that collects spectral information. However, MA-XRF is often limited by a trade-off between acquisition time and resolution. Achieving higher resolution requires longer scanning times, which can be impractical for detailed analysis of large artworks. Super-resolution MA-XRF provides an alternative solution by enhancing the quality of MA-XRF scans while reducing the need for extended scanning sessions. This paper introduces a tailored super-resolution approach to improve MA-XRF analysis of Old Master paintings. Our method proposes a novel adversarial neural network architecture for MA-XRF, inspired by the Learned Iterative Shrinkage-Thresholding Algorithm. It is specifically designed to work in an unsupervised manner, making efficient use of the limited available data. This design avoids the need for extensive datasets or pre-trained networks, allowing it to be trained using just a single high-resolution RGB image alongside low-resolution MA-XRF data. Numerical results demonstrate that our method outperforms existing state-of-the-art super-resolution techniques for MA-XRF scans of Old Master paintings.
Reconstructing classes of 3D FRI signals from sampled tomographic projections at unknown angles
Apr 15, 2024



Traditional sampling schemes often assume that the sampling locations are known. Motivated by the recent bioimaging technique known as cryogenic electron microscopy (cryoEM), we consider the problem of reconstructing an unknown 3D structure from samples of its 2D tomographic projections at unknown angles. We focus on 3D convex bilevel polyhedra and 3D point sources and show that the exact estimation of these 3D structures and of the projection angles can be achieved up to an orthogonal transformation. Moreover, we are able to show that the minimum number of projections needed to achieve perfect reconstruction is independent of the complexity of the signal model. By using the divergence theorem, we are able to retrieve the projected vertices of the polyhedron from the sampled tomographic projections, and then we show how to retrieve the 3D object and the projection angles from this information. The proof of our theorem is constructive and leads to a robust reconstruction algorithm, which we validate under various conditions. Finally, we apply aspects of the proposed framework to calibration of X-ray computed tomography (CT) data.
Enhanced Event-Based Video Reconstruction with Motion Compensation
Mar 18, 2024
Deep neural networks for event-based video reconstruction often suffer from a lack of interpretability and have high memory demands. A lightweight network called CISTA-LSTC has recently been introduced showing that high-quality reconstruction can be achieved through the systematic design of its architecture. However, its modelling assumption that input signals and output reconstructed frame share the same sparse representation neglects the displacement caused by motion. To address this, we propose warping the input intensity frames and sparse codes to enhance reconstruction quality. A CISTA-Flow network is constructed by integrating a flow network with CISTA-LSTC for motion compensation. The system relies solely on events, in which predicted flow aids in reconstruction and then reconstructed frames are used to facilitate flow estimation. We also introduce an iterative training framework for this combined system. Results demonstrate that our approach achieves state-of-the-art reconstruction accuracy and simultaneously provides reliable dense flow estimation. Furthermore, our model exhibits flexibility in that it can integrate different flow networks, suggesting its potential for further performance enhancement.
CommIN: Semantic Image Communications as an Inverse Problem with INN-Guided Diffusion Models
Oct 02, 2023Joint source-channel coding schemes based on deep neural networks (DeepJSCC) have recently achieved remarkable performance for wireless image transmission. However, these methods usually focus only on the distortion of the reconstructed signal at the receiver side with respect to the source at the transmitter side, rather than the perceptual quality of the reconstruction which carries more semantic information. As a result, severe perceptual distortion can be introduced under extreme conditions such as low bandwidth and low signal-to-noise ratio. In this work, we propose CommIN, which views the recovery of high-quality source images from degraded reconstructions as an inverse problem. To address this, CommIN combines Invertible Neural Networks (INN) with diffusion models, aiming for superior perceptual quality. Through experiments, we show that our CommIN significantly improves the perceptual quality compared to DeepJSCC under extreme conditions and outperforms other inverse problem approaches used in DeepJSCC.
INDigo: An INN-Guided Probabilistic Diffusion Algorithm for Inverse Problems
Jun 05, 2023Recently it has been shown that using diffusion models for inverse problems can lead to remarkable results. However, these approaches require a closed-form expression of the degradation model and can not support complex degradations. To overcome this limitation, we propose a method (INDigo) that combines invertible neural networks (INN) and diffusion models for general inverse problems. Specifically, we train the forward process of INN to simulate an arbitrary degradation process and use the inverse as a reconstruction process. During the diffusion sampling process, we impose an additional data-consistency step that minimizes the distance between the intermediate result and the INN-optimized result at every iteration, where the INN-optimized image is composed of the coarse information given by the observed degraded image and the details generated by the diffusion process. With the help of INN, our algorithm effectively estimates the details lost in the degradation process and is no longer limited by the requirement of knowing the closed-form expression of the degradation model. Experiments demonstrate that our algorithm obtains competitive results compared with recently leading methods both quantitatively and visually. Moreover, our algorithm performs well on more complex degradation models and real-world low-quality images.
Learning-based Reconstruction of FRI Signals
Dec 16, 2022Finite Rate of Innovation (FRI) sampling theory enables reconstruction of classes of continuous non-bandlimited signals that have a small number of free parameters from their low-rate discrete samples. This task is often translated into a spectral estimation problem that is solved using methods involving estimating signal subspaces, which tend to break down at a certain peak signal-to-noise ratio (PSNR). To avoid this breakdown, we consider alternative approaches that make use of information from labelled data. We propose two model-based learning methods, including deep unfolding the denoising process in spectral estimation, and constructing an encoder-decoder deep neural network that models the acquisition process. Simulation results of both learning algorithms indicate significant improvements of the breakdown PSNR over classical subspace-based methods. While the deep unfolded network achieves similar performance as the classical FRI techniques and outperforms the encoder-decoder network in the low noise regimes, the latter allows to reconstruct the FRI signal even when the sampling kernel is unknown. We also achieve competitive results in detecting pulses from in vivo calcium imaging data in terms of true positive and false positive rate while providing more precise estimations.
Generative Joint Source-Channel Coding for Semantic Image Transmission
Nov 24, 2022



Recent works have shown that joint source-channel coding (JSCC) schemes using deep neural networks (DNNs), called DeepJSCC, provide promising results in wireless image transmission. However, these methods mostly focus on the distortion of the reconstructed signals with respect to the input image, rather than their perception by humans. However, focusing on traditional distortion metrics alone does not necessarily result in high perceptual quality, especially in extreme physical conditions, such as very low bandwidth compression ratio (BCR) and low signal-to-noise ratio (SNR) regimes. In this work, we propose two novel JSCC schemes that leverage the perceptual quality of deep generative models (DGMs) for wireless image transmission, namely InverseJSCC and GenerativeJSCC. While the former is an inverse problem approach to DeepJSCC, the latter is an end-to-end optimized JSCC scheme. In both, we optimize a weighted sum of mean squared error (MSE) and learned perceptual image patch similarity (LPIPS) losses, which capture more semantic similarities than other distortion metrics. InverseJSCC performs denoising on the distorted reconstructions of a DeepJSCC model by solving an inverse optimization problem using style-based generative adversarial network (StyleGAN). Our simulation results show that InverseJSCC significantly improves the state-of-the-art (SotA) DeepJSCC in terms of perceptual quality in edge cases. In GenerativeJSCC, we carry out end-to-end training of an encoder and a StyleGAN-based decoder, and show that GenerativeJSCC significantly outperforms DeepJSCC both in terms of distortion and perceptual quality.
A Fast Automatic Method for Deconvoluting Macro X-ray Fluorescence Data Collected from Easel Paintings
Oct 31, 2022Macro X-ray Fluorescence (MA-XRF) scanning is increasingly widely used by researchers in heritage science to analyse easel paintings as one of a suite of non-invasive imaging techniques. The task of processing the resulting MA-XRF datacube generated in order to produce individual chemical element maps is called MA-XRF deconvolution. While there are several existing methods that have been proposed for MA-XRF deconvolution, they require a degree of manual intervention from the user that can affect the final results. The state-of-the-art AFRID approach can automatically deconvolute the datacube without user input, but it has a long processing time and does not exploit spatial dependency. In this paper, we propose two versions of a fast automatic deconvolution (FAD) method for MA-XRF datacubes collected from easel paintings with ADMM (alternating direction method of multipliers) and FISTA (fast iterative shrinkage-thresholding algorithm). The proposed FAD method not only automatically analyses the datacube and produces element distribution maps of high-quality with spatial dependency considered, but also significantly reduces the running time. The results generated on the MA-XRF datacubes collected from two easel paintings from the National Gallery, London, verify the performance of the proposed FAD method.
DURRNet: Deep Unfolded Single Image Reflection Removal Network
Mar 12, 2022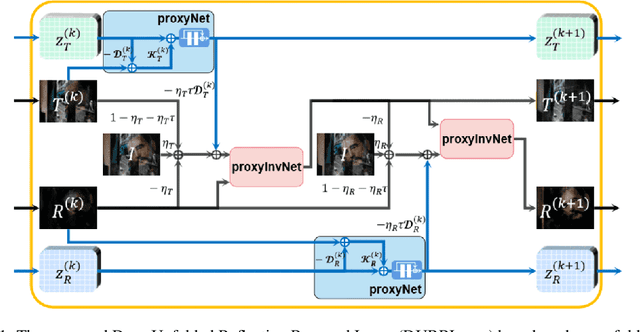

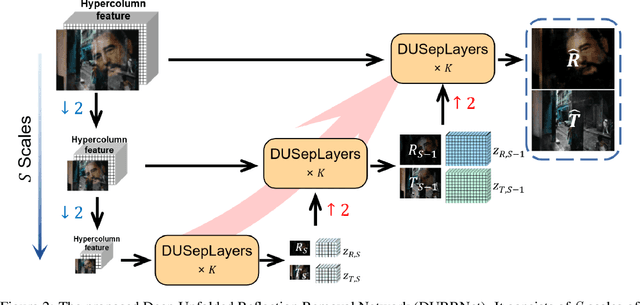

Single image reflection removal problem aims to divide a reflection-contaminated image into a transmission image and a reflection image. It is a canonical blind source separation problem and is highly ill-posed. In this paper, we present a novel deep architecture called deep unfolded single image reflection removal network (DURRNet) which makes an attempt to combine the best features from model-based and learning-based paradigms and therefore leads to a more interpretable deep architecture. Specifically, we first propose a model-based optimization with transform-based exclusion prior and then design an iterative algorithm with simple closed-form solutions for solving each sub-problems. With the deep unrolling technique, we build the DURRNet with ProxNets to model natural image priors and ProxInvNets which are constructed with invertible networks to impose the exclusion prior. Comprehensive experimental results on commonly used datasets demonstrate that the proposed DURRNet achieves state-of-the-art results both visually and quantitatively.