 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Strategic Recommendations
Sep 15, 2020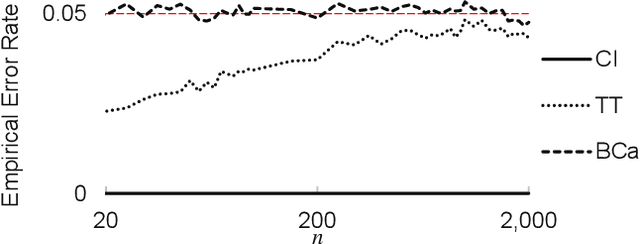

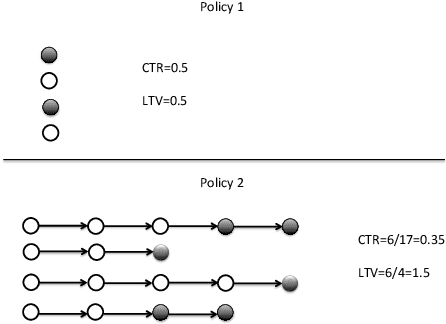
Strategic recommendations (SR) refer to the problem where an intelligent agent observes the sequential behaviors and activities of users and decides when and how to interact with them to optimize some long-term objectives, both for the user and the business. These systems are in their infancy in the industry and in need of practical solutions to some fundamental research challenges. At Adobe research, we have been implementing such systems for various use-cases, including points of interest recommendations, tutorial recommendations, next step guidance in multi-media editing software, and ad recommendation for optimizing lifetime value. There are many research challenges when building these systems, such as modeling the sequential behavior of users, deciding when to intervene and offer recommendations without annoying the user, evaluating policies offline with high confidence, safe deployment, non-stationarity, building systems from passive data that do not contain past recommendations, resource constraint optimization in multi-user systems, scaling to large and dynamic actions spaces, and handling and incorporating human cognitive biases. In this paper we cover various use-cases and research challenges we solved to make these systems practical.
Evaluating the Performance of Reinforcement Learning Algorithms
Jun 30, 2020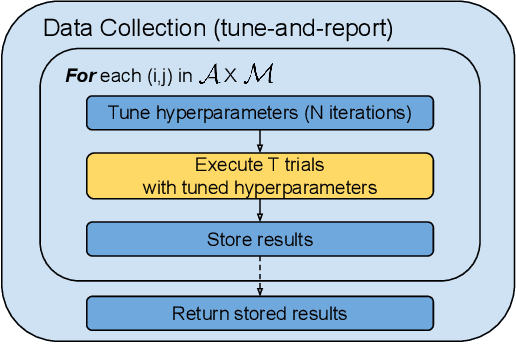
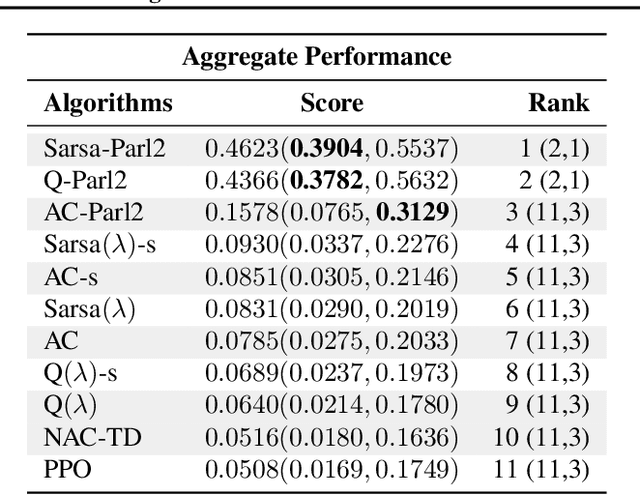
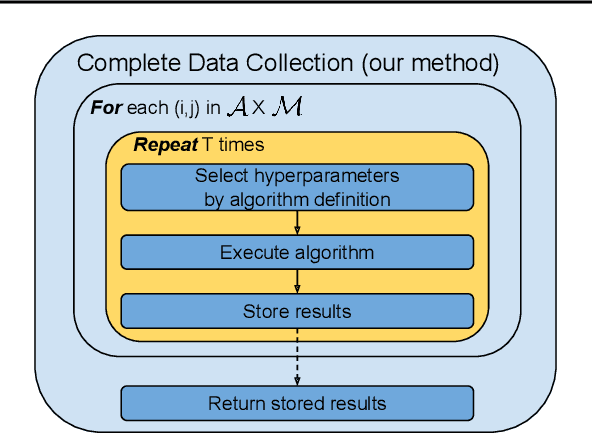
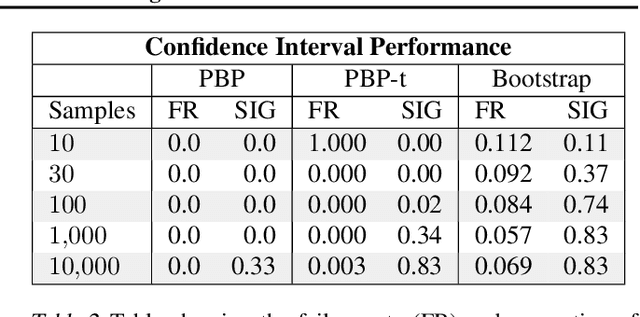
Performance evaluations are critical for quantifying algorithmic advances in reinforcement learning. Recent reproducibility analyses have shown that reported performance results are often inconsistent and difficult to replicate. In this work, we argue that the inconsistency of performance stems from the use of flawed evaluation metrics. Taking a step towards ensuring that reported results are consistent, we propose a new comprehensive evaluation methodology for reinforcement learning algorithms that produces reliable measurements of performance both on a single environment and when aggregated across environments. We demonstrate this method by evaluating a broad class of reinforcement learning algorithms on standard benchmark tasks.
Optimizing for the Future in Non-Stationary MDPs
Jun 02, 2020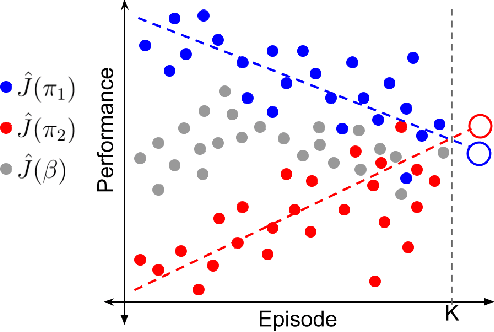
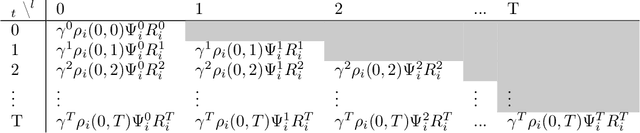
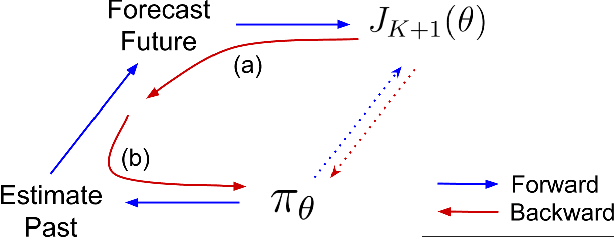
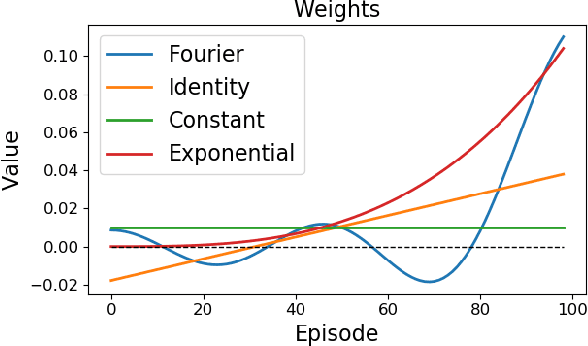
Most reinforcement learning methods are based upon the key assumption that the transition dynamics and reward functions are fixed, that is, the underlying Markov decision process (MDP) is stationary. However, in many practical real-world applications, this assumption is often violated. We discuss how current methods can have inherent limitations for non-stationary MDPs, and therefore searching for a policy that is good for the future, unknown MDP, requires rethinking the optimization paradigm. To address this problem, we develop a method that builds upon ideas from both counter-factual reasoning and curve-fitting to proactively search for a good future policy, without ever modeling the underlying non-stationarity. Interestingly, we observe that minimizing performance over some of the data from past episodes might be beneficial when searching for a policy that maximizes future performance. The effectiveness of the proposed method is demonstrated on problems motivated by real-world applications.
Learning Reusable Options for Multi-Task Reinforcement Learning
Jan 06, 2020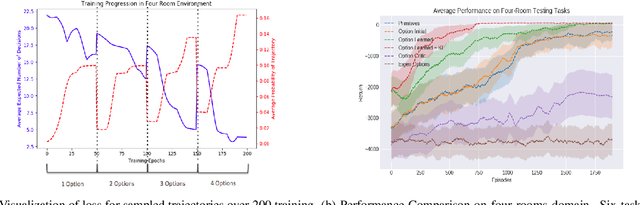
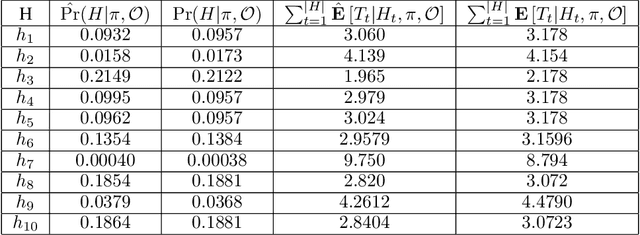
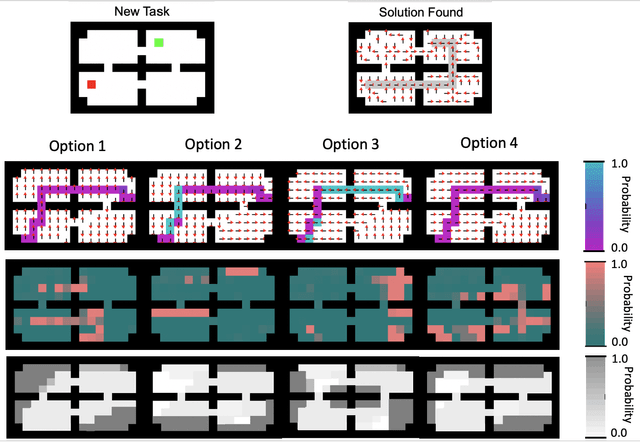
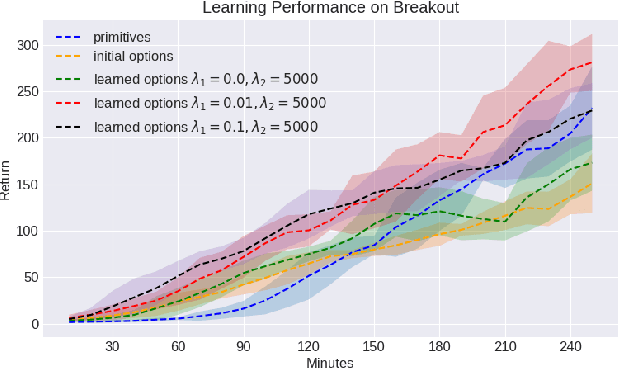
Reinforcement learning (RL) has become an increasingly active area of research in recent years. Although there are many algorithms that allow an agent to solve tasks efficiently, they often ignore the possibility that prior experience related to the task at hand might be available. For many practical applications, it might be unfeasible for an agent to learn how to solve a task from scratch, given that it is generally a computationally expensive process; however, prior experience could be leveraged to make these problems tractable in practice. In this paper, we propose a framework for exploiting existing experience by learning reusable options. We show that after an agent learns policies for solving a small number of problems, we are able to use the trajectories generated from those policies to learn reusable options that allow an agent to quickly learn how to solve novel and related problems.
Reinforcement learning with a network of spiking agents
Nov 10, 2019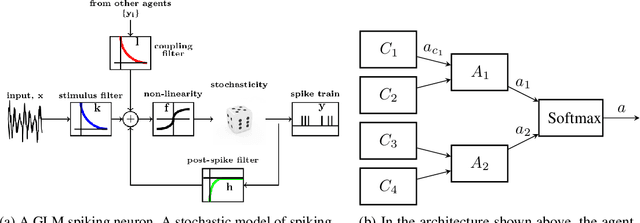
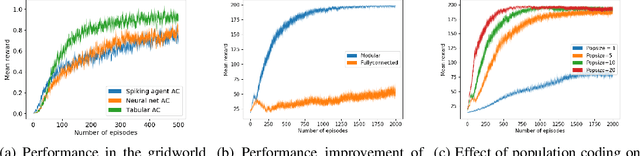
Neuroscientific theory suggests that dopaminergic neurons broadcast global reward prediction errors to large areas of the brain influencing the synaptic plasticity of the neurons in those regions. We build on this theory to propose a multi-agent learning framework with spiking neurons in the generalized linear model (GLM) formulation as agents, to solve reinforcement learning (RL) tasks. We show that a network of GLM spiking agents connected in a hierarchical fashion, where each spiking agent modulates its firing policy based on local information and a global prediction error, can learn complex action representations to solve RL tasks. We further show how leveraging principles of modularity and population coding inspired from the brain can help reduce variance in the learning updates making it a viable optimization technique.
Is the Policy Gradient a Gradient?
Jun 17, 2019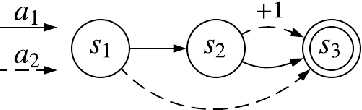
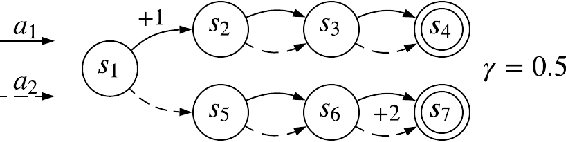

The policy gradient theorem describes the gradient of the expected discounted return with respect to an agent's policy parameters. However, most policy gradient methods do not use the discount factor in the manner originally prescribed, and therefore do not optimize the discounted objective. It has been an open question in RL as to which, if any, objective they optimize instead. We show that the direction followed by these methods is not the gradient of any objective, and reclassify them as semi-gradient methods with respect to the undiscounted objective. Further, we show that they are not guaranteed to converge to a locally optimal policy, and construct an counterexample where they will converge to the globally pessimal policy with respect to both the discounted and undiscounted objectives.
Classical Policy Gradient: Preserving Bellman's Principle of Optimality
Jun 06, 2019We propose a new objective function for finite-horizon episodic Markov decision processes that better captures Bellman's principle of optimality, and provide an expression for the gradient of the objective.
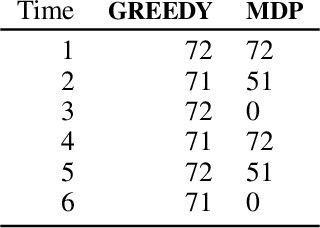
Reinforcement Learning When All Actions are Not Always Available
Jun 05, 2019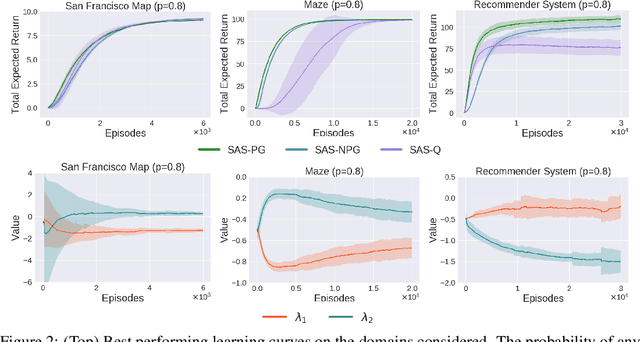
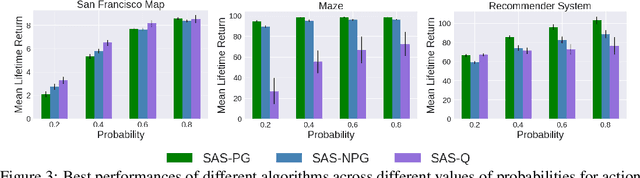
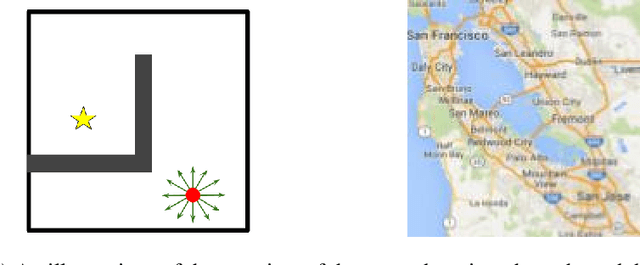
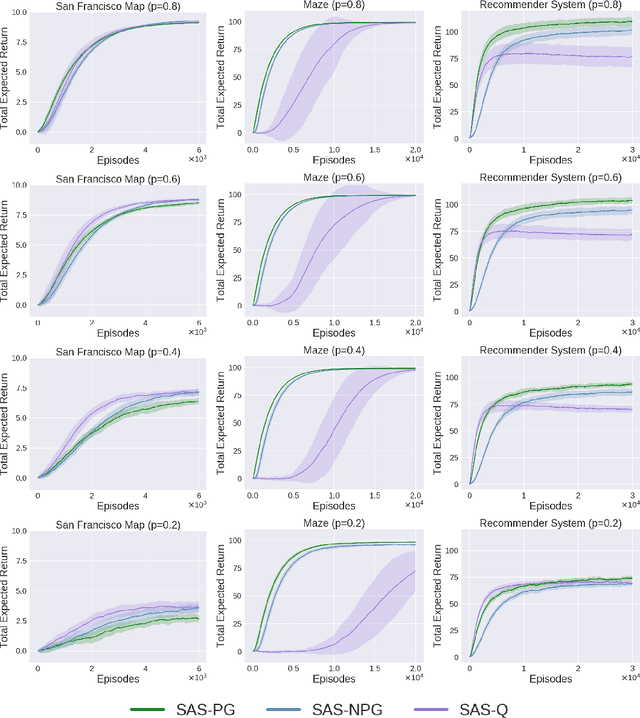
The Markov decision process (MDP) formulation used to model many real-world sequential decision making problems does not capture the setting where the set of available decisions (actions) at each time step is stochastic. Recently, the stochastic action set Markov decision process (SAS-MDP) formulation has been proposed, which captures the concept of a stochastic action set. In this paper we argue that existing RL algorithms for SAS-MDPs suffer from divergence issues, and present new algorithms for SAS-MDPs that incorporate variance reduction techniques unique to this setting, and provide conditions for their convergence. We conclude with experiments that demonstrate the practicality of our approaches using several tasks inspired by real-life use cases wherein the action set is stochastic.
Lifelong Learning with a Changing Action Set
Jun 05, 2019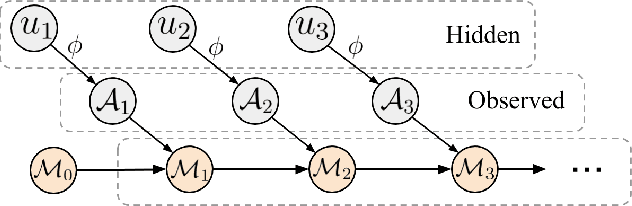
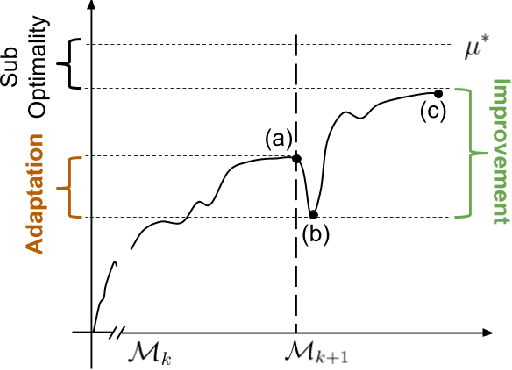
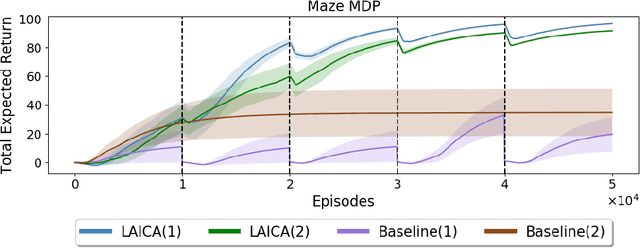
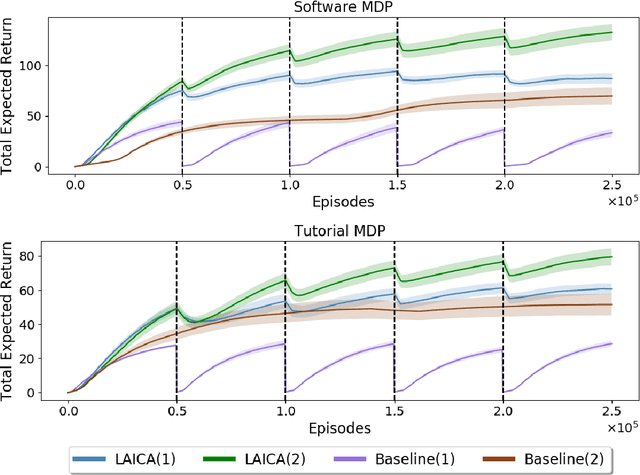
In many real-world sequential decision making problems, the number of available actions (decisions) can vary over time. While problems like catastrophic forgetting, changing transition dynamics, changing rewards functions, etc. have been well-studied in the lifelong learning literature, the setting where the action set changes remains unaddressed. In this paper, we present an algorithm that autonomously adapts to an action set whose size changes over time. To tackle this open problem, we break it into two problems that can be solved iteratively: inferring the underlying, unknown, structure in the space of actions and optimizing a policy that leverages this structure. We demonstrate the efficiency of this approach on large-scale real-world lifelong learning problems.
A New Confidence Interval for the Mean of a Bounded Random Variable
May 15, 2019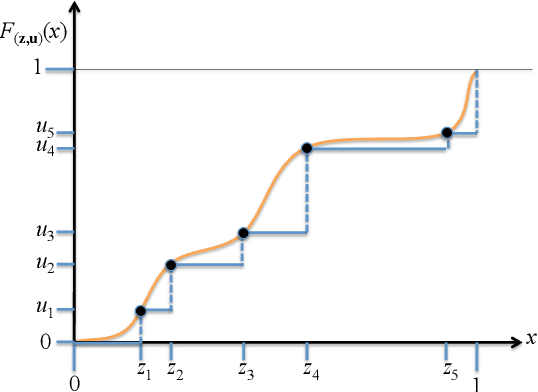
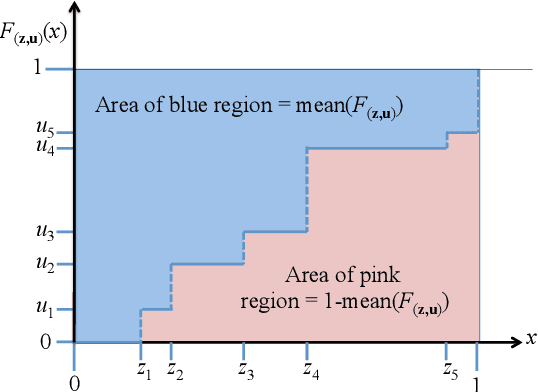
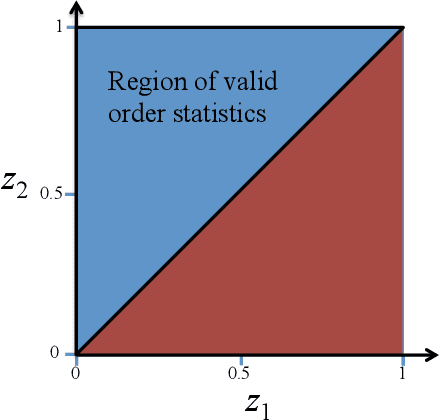
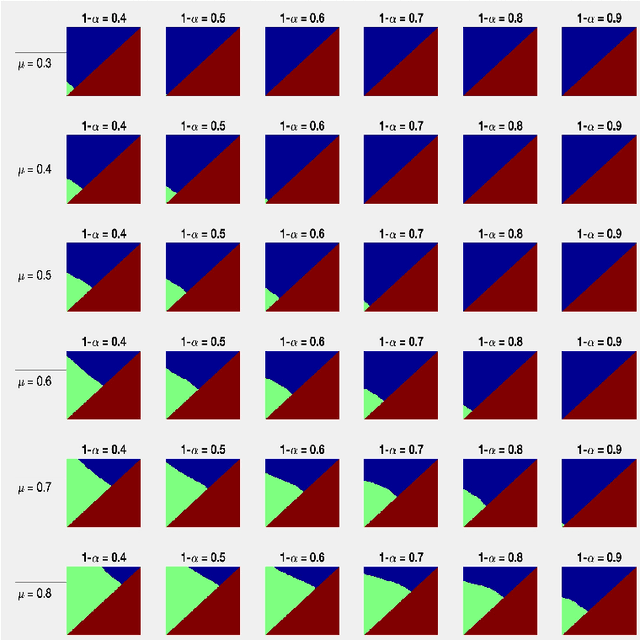
We present a new method for constructing a confidence interval for the mean of a bounded random variable from samples of the random variable. We conjecture that the confidence interval has guaranteed coverage, i.e., that it contains the mean with high probability for all distributions on a bounded interval, for all samples sizes, and for all confidence levels. This new method provides confidence intervals that are competitive with those produced using Student's t-statistic, but does not rely on normality assumptions. In particular, its only requirement is that the distribution be bounded on a known finite interval.