 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaising the Bar on the Evaluation of Out-of-Distribution Detection
Sep 24, 2022
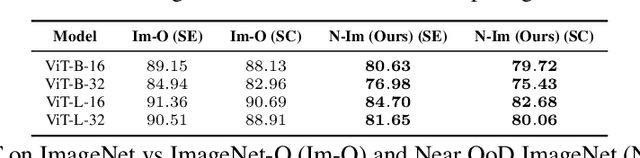
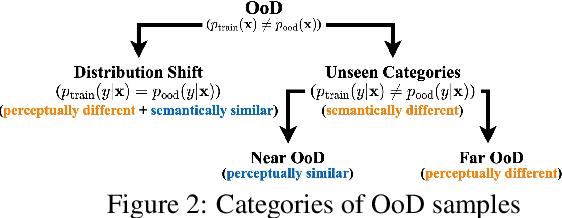
In image classification, a lot of development has happened in detecting out-of-distribution (OoD) data. However, most OoD detection methods are evaluated on a standard set of datasets, arbitrarily different from training data. There is no clear definition of what forms a ``good" OoD dataset. Furthermore, the state-of-the-art OoD detection methods already achieve near perfect results on these standard benchmarks. In this paper, we define 2 categories of OoD data using the subtly different concepts of perceptual/visual and semantic similarity to in-distribution (iD) data. We define Near OoD samples as perceptually similar but semantically different from iD samples, and Shifted samples as points which are visually different but semantically akin to iD data. We then propose a GAN based framework for generating OoD samples from each of these 2 categories, given an iD dataset. Through extensive experiments on MNIST, CIFAR-10/100 and ImageNet, we show that a) state-of-the-art OoD detection methods which perform exceedingly well on conventional benchmarks are significantly less robust to our proposed benchmark. Moreover, b) models performing well on our setup also perform well on conventional real-world OoD detection benchmarks and vice versa, thereby indicating that one might not even need a separate OoD set, to reliably evaluate performance in OoD detection.
Dynamic Graph Message Passing Networks for Visual Recognition
Sep 20, 2022

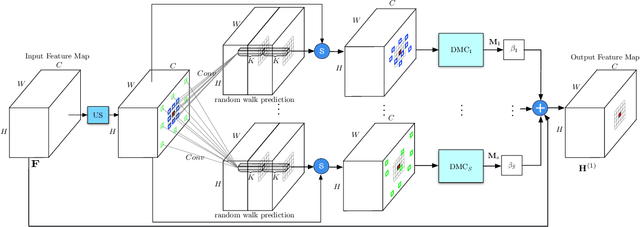
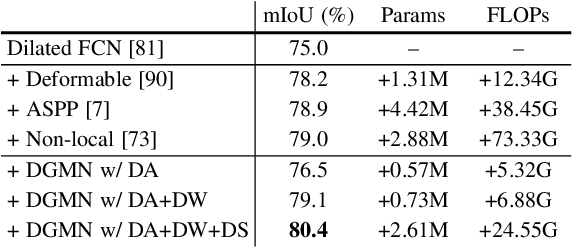
Modelling long-range dependencies is critical for scene understanding tasks in computer vision. Although convolution neural networks (CNNs) have excelled in many vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph, such as the self-attention operation in Transformers, is beneficial for such modelling, however, its computational overhead is prohibitive. In this paper, we propose a dynamic graph message passing network, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. This formulation allows us to design a self-attention module, and more importantly a new Transformer-based backbone network, that we use for both image classification pretraining, and for addressing various downstream tasks (object detection, instance and semantic segmentation). Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on four different tasks. Our approach also outperforms fully-connected graphs while using substantially fewer floating-point operations and parameters. Code and models will be made publicly available at https://github.com/fudan-zvg/DGMN2
Memory-Driven Text-to-Image Generation
Aug 15, 2022
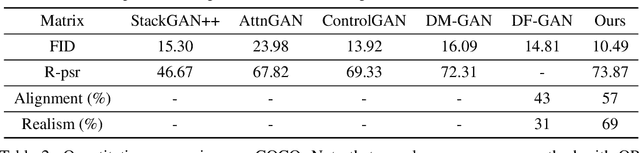

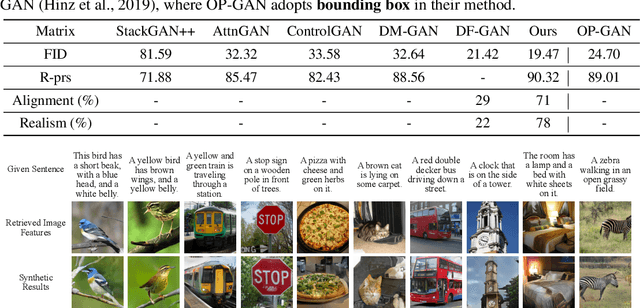
We introduce a memory-driven semi-parametric approach to text-to-image generation, which is based on both parametric and non-parametric techniques. The non-parametric component is a memory bank of image features constructed from a training set of images. The parametric component is a generative adversarial network. Given a new text description at inference time, the memory bank is used to selectively retrieve image features that are provided as basic information of target images, which enables the generator to produce realistic synthetic results. We also incorporate the content information into the discriminator, together with semantic features, allowing the discriminator to make a more reliable prediction. Experimental results demonstrate that the proposed memory-driven semi-parametric approach produces more realistic images than purely parametric approaches, in terms of both visual fidelity and text-image semantic consistency.
An Impartial Take to the CNN vs Transformer Robustness Contest
Jul 22, 2022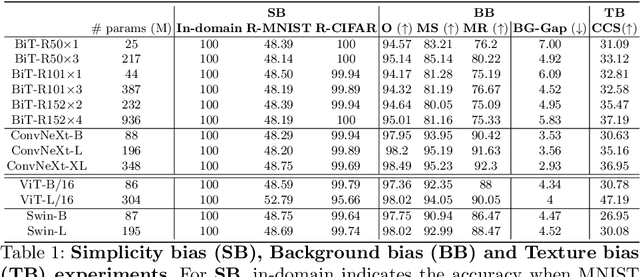

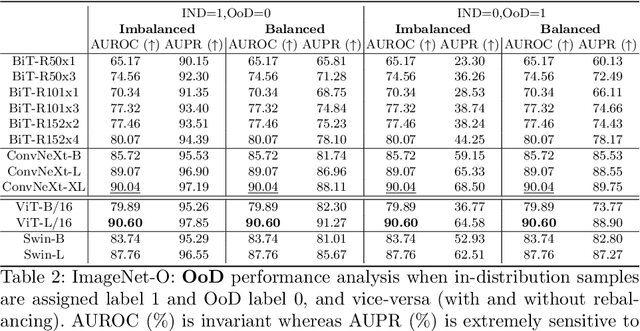
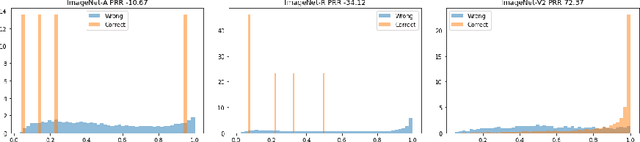
Following the surge of popularity of Transformers in Computer Vision, several studies have attempted to determine whether they could be more robust to distribution shifts and provide better uncertainty estimates than Convolutional Neural Networks (CNNs). The almost unanimous conclusion is that they are, and it is often conjectured more or less explicitly that the reason of this supposed superiority is to be attributed to the self-attention mechanism. In this paper we perform extensive empirical analyses showing that recent state-of-the-art CNNs (particularly, ConvNeXt) can be as robust and reliable or even sometimes more than the current state-of-the-art Transformers. However, there is no clear winner. Therefore, although it is tempting to state the definitive superiority of one family of architectures over another, they seem to enjoy similar extraordinary performances on a variety of tasks while also suffering from similar vulnerabilities such as texture, background, and simplicity biases.
Sample-dependent Adaptive Temperature Scaling for Improved Calibration
Jul 22, 2022
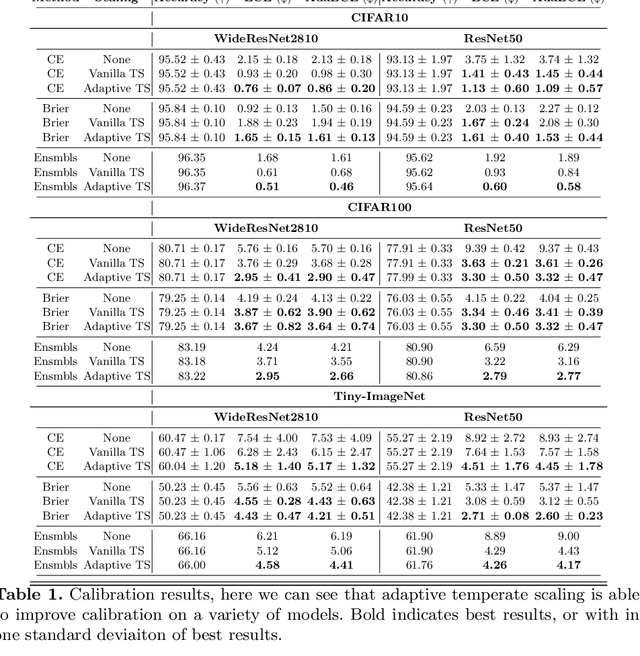
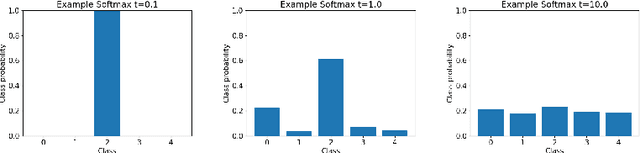
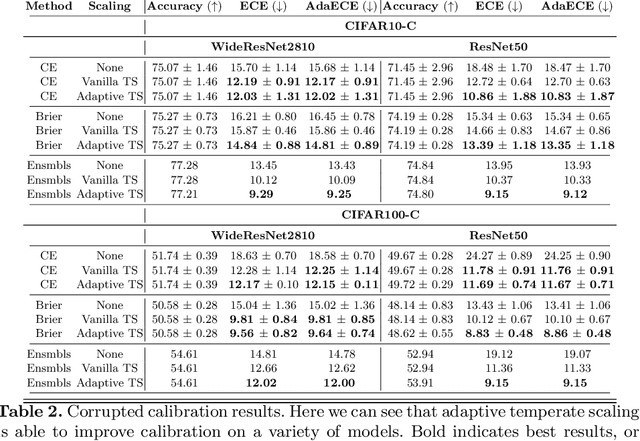
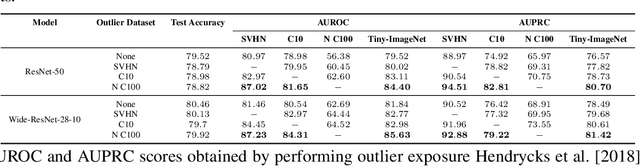
It is now well known that neural networks can be wrong with high confidence in their predictions, leading to poor calibration. The most common post-hoc approach to compensate for this is to perform temperature scaling, which adjusts the confidences of the predictions on any input by scaling the logits by a fixed value. Whilst this approach typically improves the average calibration across the whole test dataset, this improvement typically reduces the individual confidences of the predictions irrespective of whether the classification of a given input is correct or incorrect. With this insight, we base our method on the observation that different samples contribute to the calibration error by varying amounts, with some needing to increase their confidence and others needing to decrease it. Therefore, for each input, we propose to predict a different temperature value, allowing us to adjust the mismatch between confidence and accuracy at a finer granularity. Furthermore, we observe improved results on OOD detection and can also extract a notion of hardness for the data-points. Our method is applied post-hoc, consequently using very little computation time and with a negligible memory footprint and is applied to off-the-shelf pre-trained classifiers. We test our method on the ResNet50 and WideResNet28-10 architectures using the CIFAR10/100 and Tiny-ImageNet datasets, showing that producing per-data-point temperatures is beneficial also for the expected calibration error across the whole test set. Code is available at: https://github.com/thwjoy/adats.
Illusionary Attacks on Sequential Decision Makers and Countermeasures
Jul 20, 2022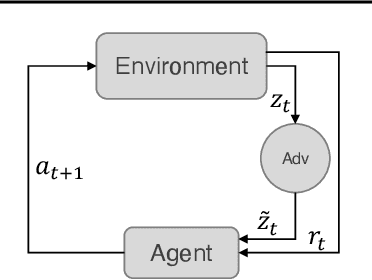
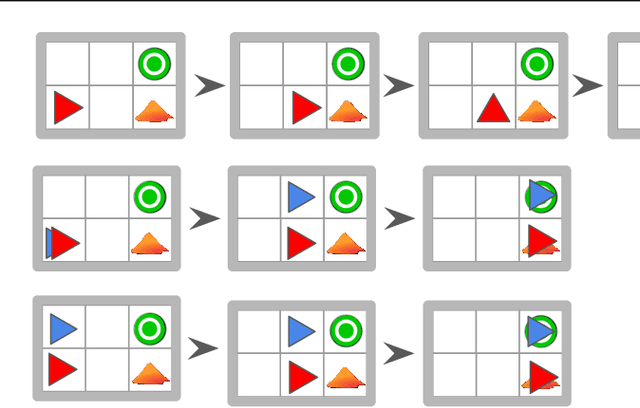
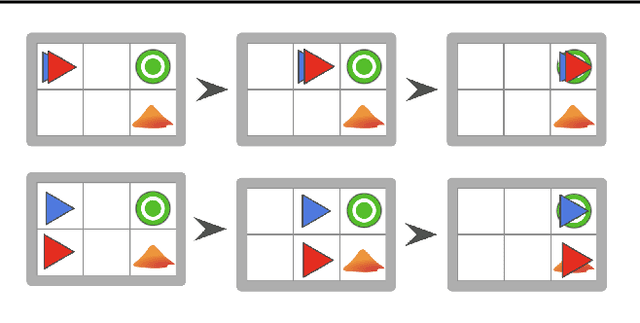
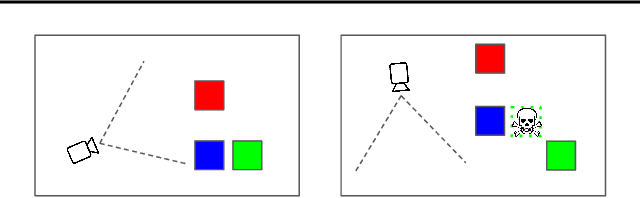
Autonomous intelligent agents deployed to the real-world need to be robust against adversarial attacks on sensory inputs. Existing work in reinforcement learning focuses on minimum-norm perturbation attacks, which were originally introduced to mimic a notion of perceptual invariance in computer vision. In this paper, we note that such minimum-norm perturbation attacks can be trivially detected by victim agents, as these result in observation sequences that are not consistent with the victim agent's actions. Furthermore, many real-world agents, such as physical robots, commonly operate under human supervisors, which are not susceptible to such perturbation attacks. As a result, we propose to instead focus on illusionary attacks, a novel form of attack that is consistent with the world model of the victim agent. We provide a formal definition of this novel attack framework, explore its characteristics under a variety of conditions, and conclude that agents must seek realism feedback to be robust to illusionary attacks.
SiamMask: A Framework for Fast Online Object Tracking and Segmentation
Jul 05, 2022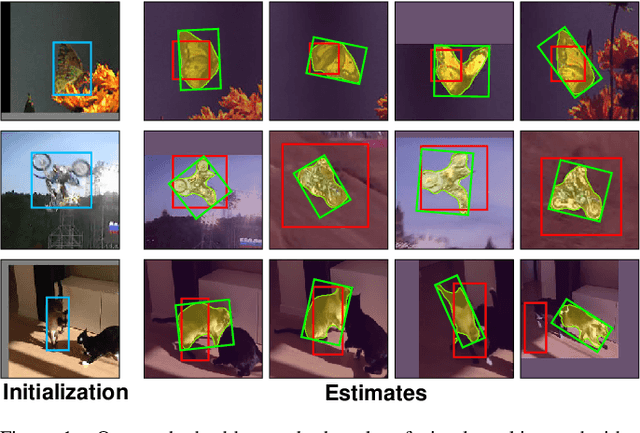
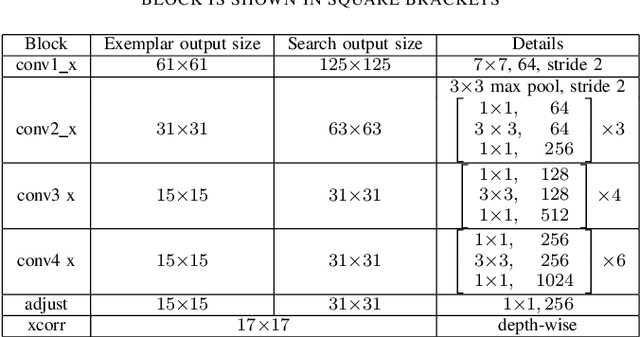
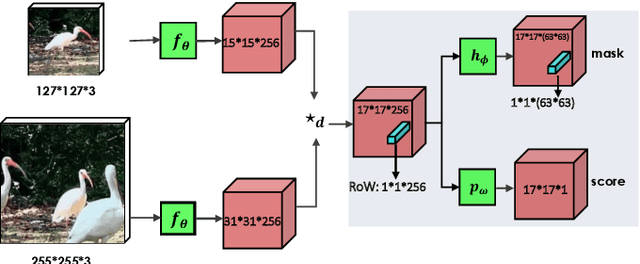
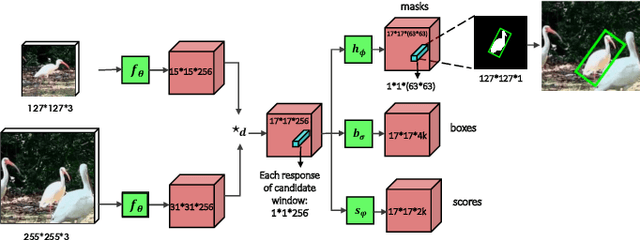
In this paper we introduce SiamMask, a framework to perform both visual object tracking and video object segmentation, in real-time, with the same simple method. We improve the offline training procedure of popular fully-convolutional Siamese approaches by augmenting their losses with a binary segmentation task. Once the offline training is completed, SiamMask only requires a single bounding box for initialization and can simultaneously carry out visual object tracking and segmentation at high frame-rates. Moreover, we show that it is possible to extend the framework to handle multiple object tracking and segmentation by simply re-using the multi-task model in a cascaded fashion. Experimental results show that our approach has high processing efficiency, at around 55 frames per second. It yields real-time state-of-the-art results on visual-object tracking benchmarks, while at the same time demonstrating competitive performance at a high speed for video object segmentation benchmarks.
* 17 pages, Accepted by TPAMI 2022. arXiv admin note: substantial text overlap with arXiv:1812.05050
RegMixup: Mixup as a Regularizer Can Surprisingly Improve Accuracy and Out Distribution Robustness
Jun 29, 2022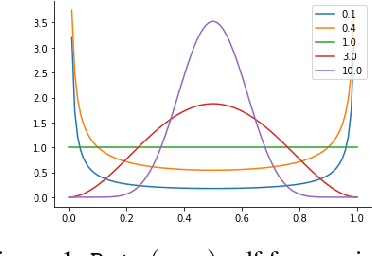

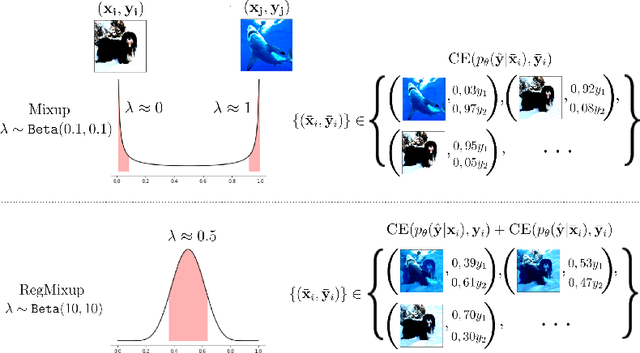
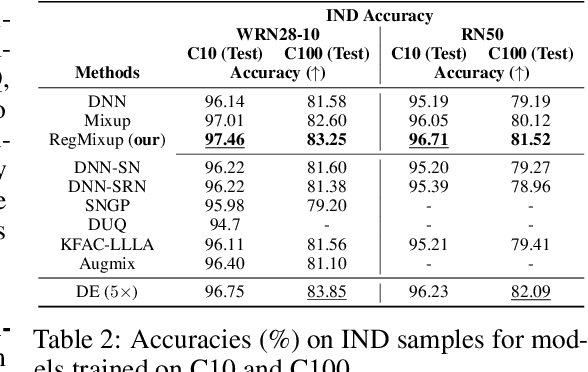
We show that the effectiveness of the well celebrated Mixup [Zhang et al., 2018] can be further improved if instead of using it as the sole learning objective, it is utilized as an additional regularizer to the standard cross-entropy loss. This simple change not only provides much improved accuracy but also significantly improves the quality of the predictive uncertainty estimation of Mixup in most cases under various forms of covariate shifts and out-of-distribution detection experiments. In fact, we observe that Mixup yields much degraded performance on detecting out-of-distribution samples possibly, as we show empirically, because of its tendency to learn models that exhibit high-entropy throughout; making it difficult to differentiate in-distribution samples from out-distribution ones. To show the efficacy of our approach (RegMixup), we provide thorough analyses and experiments on vision datasets (ImageNet & CIFAR-10/100) and compare it with a suite of recent approaches for reliable uncertainty estimation.
How robust are pre-trained models to distribution shift?
Jun 17, 2022
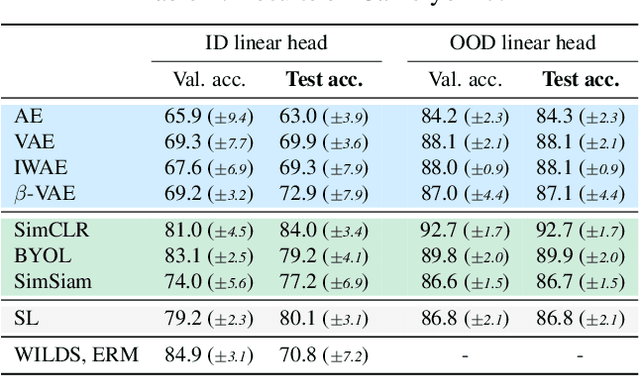
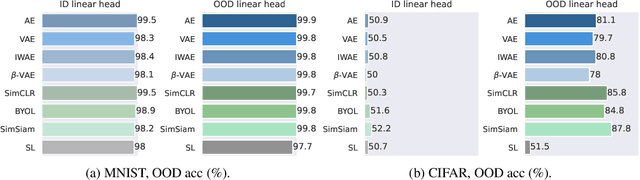

The vulnerability of machine learning models to spurious correlations has mostly been discussed in the context of supervised learning (SL). However, there is a lack of insight on how spurious correlations affect the performance of popular self-supervised learning (SSL) and auto-encoder based models (AE). In this work, we shed light on this by evaluating the performance of these models on both real world and synthetic distribution shift datasets. Following observations that the linear head itself can be susceptible to spurious correlations, we develop a novel evaluation scheme with the linear head trained on out-of-distribution (OOD) data, to isolate the performance of the pre-trained models from a potential bias of the linear head used for evaluation. With this new methodology, we show that SSL models are consistently more robust to distribution shifts and thus better at OOD generalisation than AE and SL models.
Catastrophic overfitting is a bug but also a feature
Jun 16, 2022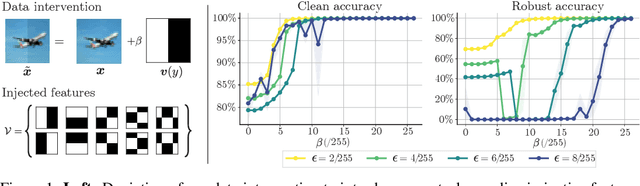
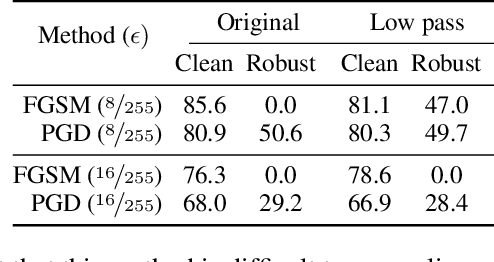

Despite clear computational advantages in building robust neural networks, adversarial training (AT) using single-step methods is unstable as it suffers from catastrophic overfitting (CO): Networks gain non-trivial robustness during the first stages of adversarial training, but suddenly reach a breaking point where they quickly lose all robustness in just a few iterations. Although some works have succeeded at preventing CO, the different mechanisms that lead to this remarkable failure mode are still poorly understood. In this work, however, we find that the interplay between the structure of the data and the dynamics of AT plays a fundamental role in CO. Specifically, through active interventions on typical datasets of natural images, we establish a causal link between the structure of the data and the onset of CO in single-step AT methods. This new perspective provides important insights into the mechanisms that lead to CO and paves the way towards a better understanding of the general dynamics of robust model construction. The code to reproduce the experiments of this paper can be found at https://github.com/gortizji/co_features .