 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategy to Increase the Safety of a DNN-based Perception for HAD Systems
Feb 20, 2020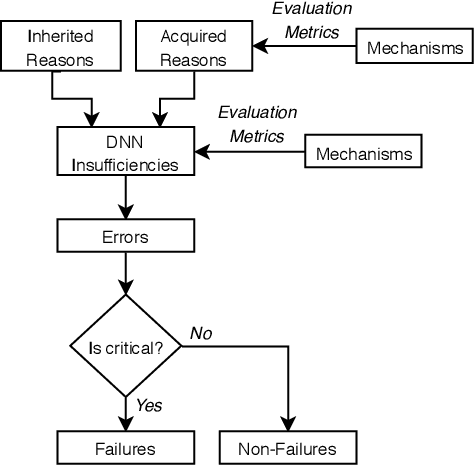
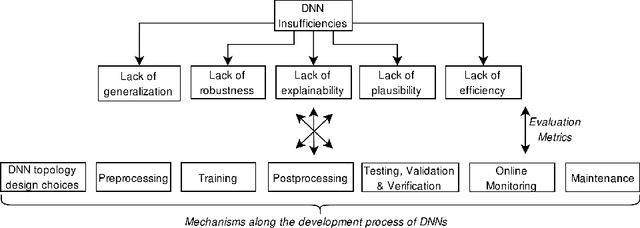
Safety is one of the most important development goals for highly automated driving (HAD) systems. This applies in particular to the perception function driven by Deep Neural Networks (DNNs). For these, large parts of the traditional safety processes and requirements are not fully applicable or sufficient. The aim of this paper is to present a framework for the description and mitigation of DNN insufficiencies and the derivation of relevant safety mechanisms to increase the safety of DNNs. To assess the effectiveness of these safety mechanisms, we present a categorization scheme for evaluation metrics.
MetaFusion: Controlled False-Negative Reduction of Minority Classes in Semantic Segmentation
Dec 16, 2019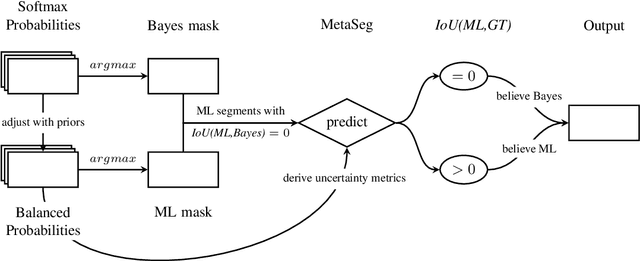
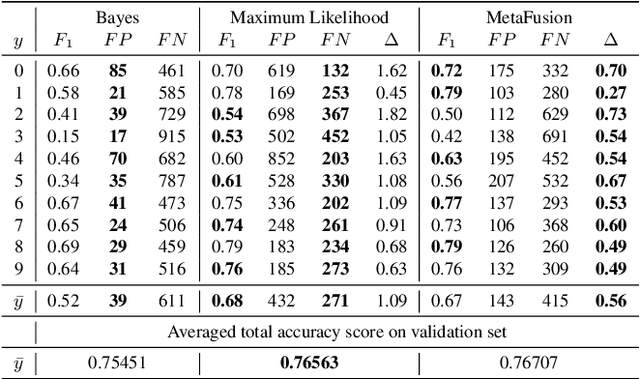

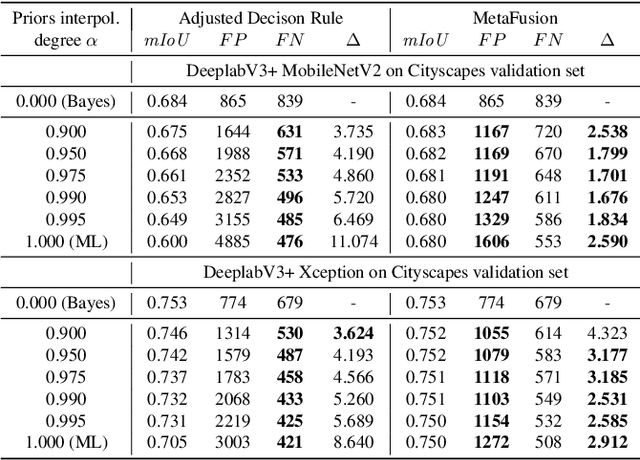
In semantic segmentation datasets, classes of high importance are oftentimes underrepresented, e.g., humans in street scenes. Neural networks are usually trained to reduce the overall number of errors, attaching identical loss to errors of all kinds. However, this is not necessarily aligned with human intuition. For instance, an overlooked pedestrian seems more severe than an incorrectly detected one. One possible remedy is to deploy different decision rules by introducing class priors which assigns larger weight to underrepresented classes. While reducing the false-negatives of the underrepresented class, at the same time this leads to a considerable increase of false-positive indications. In this work, we combine decision rules with methods for false-positive detection. We therefore fuse false-negative detection with uncertainty based false-positive meta classification. We present proof-of-concept results for CIFAR-10, and prove the efficiency of our method for the semantic segmentation of street scenes on the Cityscapes dataset based on predicted instances of the 'human' class. In the latter we employ an advanced false-positive detection method using uncertainty measures aggregated over instances. We thereby achieve improved trade-offs between false-negative and false-positive samples of the underrepresented classes.
Detection of False Positive and False Negative Samples in Semantic Segmentation
Dec 08, 2019
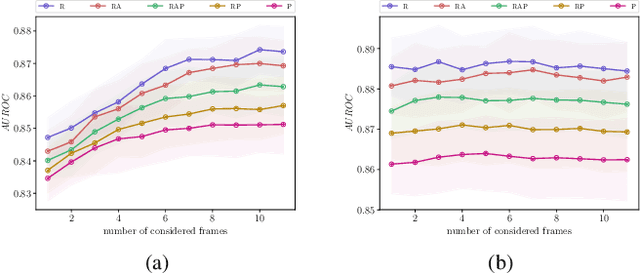

In recent years, deep learning methods have outperformed other methods in image recognition. This has fostered imagination of potential application of deep learning technology including safety relevant applications like the interpretation of medical images or autonomous driving. The passage from assistance of a human decision maker to ever more automated systems however increases the need to properly handle the failure modes of deep learning modules. In this contribution, we review a set of techniques for the self-monitoring of machine-learning algorithms based on uncertainty quantification. In particular, we apply this to the task of semantic segmentation, where the machine learning algorithm decomposes an image according to semantic categories. We discuss false positive and false negative error modes at instance-level and review techniques for the detection of such errors that have been recently proposed by the authors. We also give an outlook on future research directions.
The Ethical Dilemma when Setting up Cost-based Decision Rules in Semantic Segmentation
Jul 02, 2019
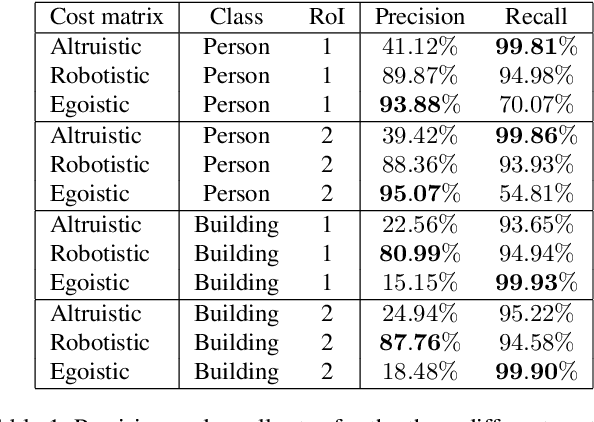


Neural networks for semantic segmentation can be seen as statistical models that provide for each pixel of one image a probability distribution on predefined classes. The predicted class is then usually obtained by the maximum a-posteriori probability (MAP) which is known as Bayes rule in decision theory. From decision theory we also know that the Bayes rule is optimal regarding the simple symmetric cost function. Therefore, it weights each type of confusion between two different classes equally, e.g., given images of urban street scenes there is no distinction in the cost function if the network confuses a person with a street or a building with a tree. Intuitively, there might be confusions of classes that are more important to avoid than others. In this work, we want to raise awareness of the possibility of explicitly defining confusion costs and the associated ethical difficulties if it comes down to providing numbers. We define two cost functions from different extreme perspectives, an egoistic and an altruistic one, and show how safety relevant quantities like precision / recall and (segment-wise) false positive / negative rate change when interpolating between MAP, egoistic and altruistic decision rules.
The Attack Generator: A Systematic Approach Towards Constructing Adversarial Attacks
Jun 17, 2019

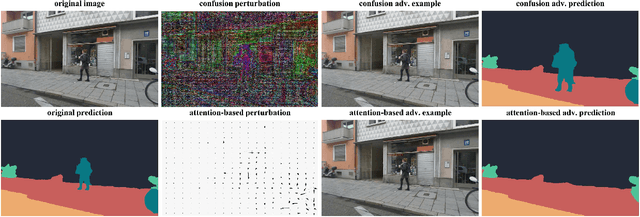
Most state-of-the-art machine learning (ML) classification systems are vulnerable to adversarial perturbations. As a consequence, adversarial robustness poses a significant challenge for the deployment of ML-based systems in safety- and security-critical environments like autonomous driving, disease detection or unmanned aerial vehicles. In the past years we have seen an impressive amount of publications presenting more and more new adversarial attacks. However, the attack research seems to be rather unstructured and new attacks often appear to be random selections from the unlimited set of possible adversarial attacks. With this publication, we present a structured analysis of the adversarial attack creation process. By detecting different building blocks of adversarial attacks, we outline the road to new sets of adversarial attacks. We call this the "attack generator". In the pursuit of this objective, we summarize and extend existing adversarial perturbation taxonomies. The resulting taxonomy is then linked to the application context of computer vision systems for autonomous vehicles, i.e. semantic segmentation and object detection. Finally, in order to prove the usefulness of the attack generator, we investigate existing semantic segmentation attacks with respect to the detected defining components of adversarial attacks.
GAN- vs. JPEG2000 Image Compression for Distributed Automotive Perception: Higher Peak SNR Does Not Mean Better Semantic Segmentation
Feb 12, 2019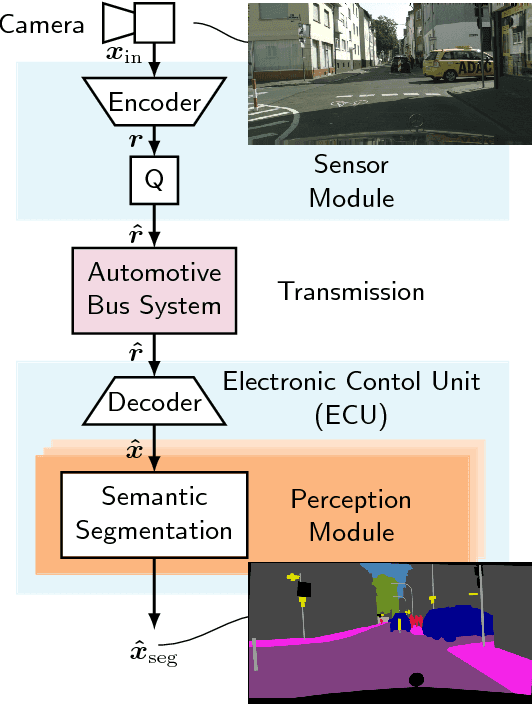
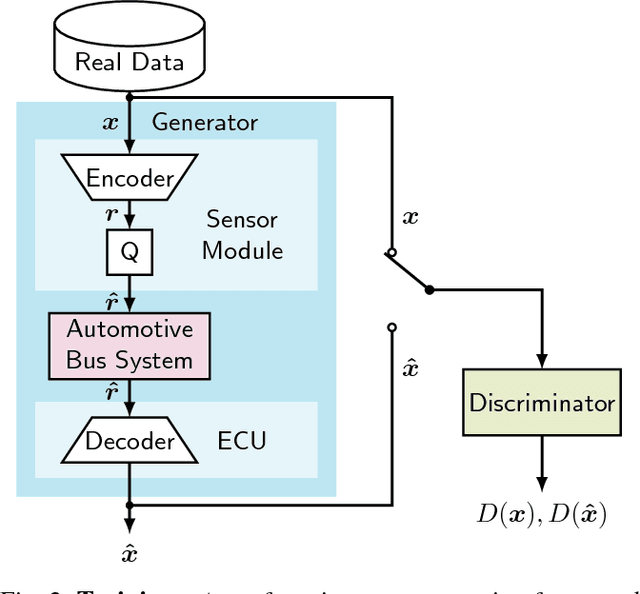
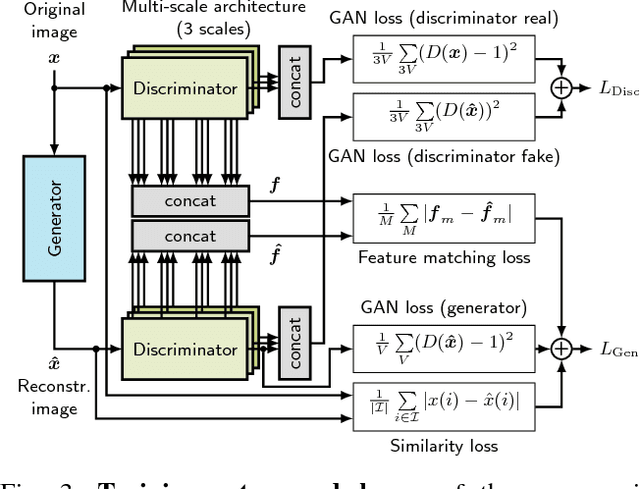

The high amount of sensors required for autonomous driving poses enormous challenges on the capacity of automotive bus systems. There is a need to understand tradeoffs between bitrate and perception performance. In this paper, we compare the image compression standards JPEG, JPEG2000, and WebP to a modern encoder/decoder image compression approach based on generative adversarial networks (GANs). We evaluate both the pure compression performance using typical metrics such as peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and others, but also the performance of a subsequent perception function, namely a semantic segmentation (characterized by the mean intersection over union (mIoU) measure). Not surprisingly, for all investigated compression methods, a higher bitrate means better results in all investigated quality metrics. Interestingly, however, we show that the semantic segmentation mIoU of the GAN autoencoder in the highly relevant low-bitrate regime (at 0.0625 bit/pixel) is better by 3.9% absolute than JPEG2000, although the latter still is considerably better in terms of PSNR (5.91 dB difference). This effect can greatly be enlarged by training the semantic segmentation model with images originating from the decoder, so that the mIoU using the segmentation model trained by GAN reconstructions exceeds the use of the model trained with original images by almost 20% absolute. We conclude that distributed perception in future autonomous driving will most probably not provide a solution to the automotive bus capacity bottleneck by using standard compression schemes such as JPEG2000, but requires modern coding approaches, with the GAN encoder/decoder method being a promising candidate.
Application of Decision Rules for Handling Class Imbalance in Semantic Segmentation
Jan 24, 2019


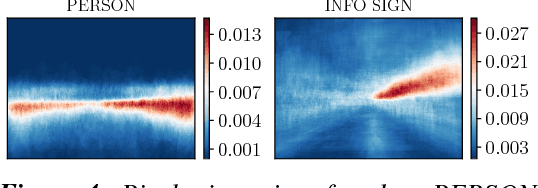
As part of autonomous car driving systems, semantic segmentation is an essential component to obtain a full understanding of the car's environment. One difficulty, that occurs while training neural networks for this purpose, is class imbalance of training data. Consequently, a neural network trained on unbalanced data in combination with maximum a-posteriori classification may easily ignore classes that are rare in terms of their frequency in the dataset. However, these classes are often of highest interest. We approach such potential misclassifications by weighting the posterior class probabilities with the prior class probabilities which in our case are the inverse frequencies of the corresponding classes in the training dataset. More precisely, we adopt a localized method by computing the priors pixel-wise such that the impact can be analyzed at pixel level as well. In our experiments, we train one network from scratch using a proprietary dataset containing 20,000 annotated frames of video sequences recorded from street scenes. The evaluation on our test set shows an increase of average recall with regard to instances of pedestrians and info signs by $25\%$ and $23.4\%$, respectively. In addition, we significantly reduce the non-detection rate for instances of the same classes by $61\%$ and $38\%$.
Prediction Error Meta Classification in Semantic Segmentation: Detection via Aggregated Dispersion Measures of Softmax Probabilities
Nov 01, 2018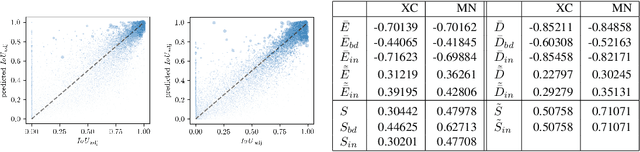
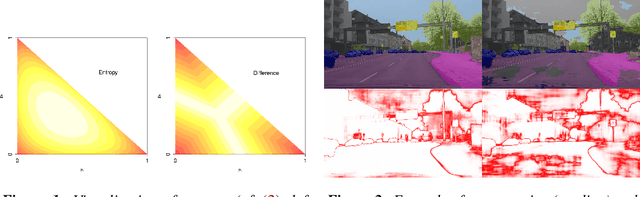
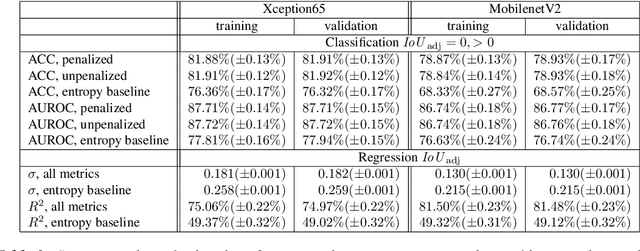
We present a method that "meta" classifies whether segments (objects) predicted by a semantic segmentation neural network intersect with the ground truth. To this end, we employ measures of dispersion for predicted pixel-wise class probability distributions, like classification entropy, that yield heat maps of the input scene's size. We aggregate these dispersion measures segment-wise and derive metrics that are well-correlated with the segment-wise $\mathit{IoU}$ of prediction and ground truth. In our tests, we use two publicly available DeepLabv3+ networks (pre-trained on the Cityscapes data set) and analyze the predictive power of different metrics and different sets of metrics. To this end, we compute logistic LASSO regression fits for the task of classifying $\mathit{IoU}=0$ vs. $\mathit{IoU} > 0$ per segment and obtain classification rates of up to $81.91\%$ and AUROC values of up to $87.71\%$ without the incorporation of advanced techniques like Monte-Carlo dropout. We complement these tests with linear regression fits to predict the segment-wise $\mathit{IoU}$ and obtain prediction standard deviations of down to $0.130$ as well as $R^2$ values of up to $81.48\%$. We show that these results clearly outperform single-metric baseline approaches.
Introducing Noise in Decentralized Training of Neural Networks
Sep 27, 2018
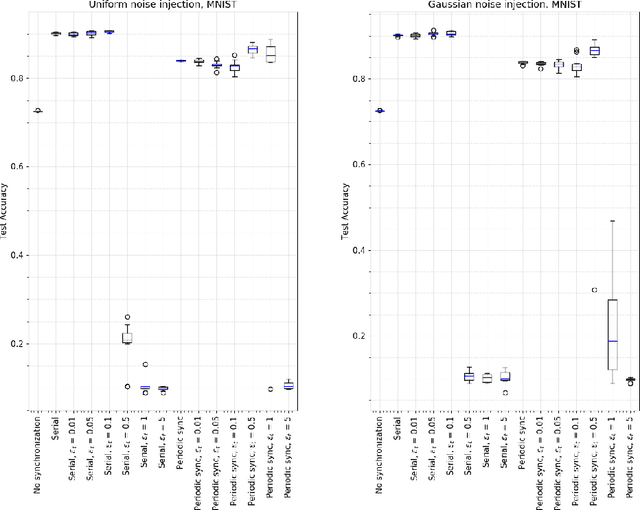
It has been shown that injecting noise into the neural network weights during the training process leads to a better generalization of the resulting model. Noise injection in the distributed setup is a straightforward technique and it represents a promising approach to improve the locally trained models. We investigate the effects of noise injection into the neural networks during a decentralized training process. We show both theoretically and empirically that noise injection has no positive effect in expectation on linear models, though. However for non-linear neural networks we empirically show that noise injection substantially improves model quality helping to reach a generalization ability of a local model close to the serial baseline.
* 13 pages
Efficient Decentralized Deep Learning by Dynamic Model Averaging
Jul 09, 2018
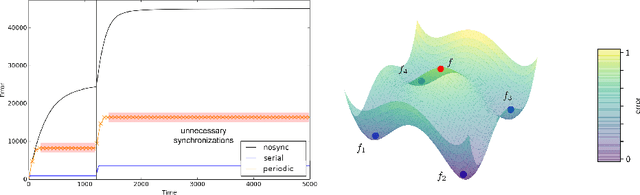
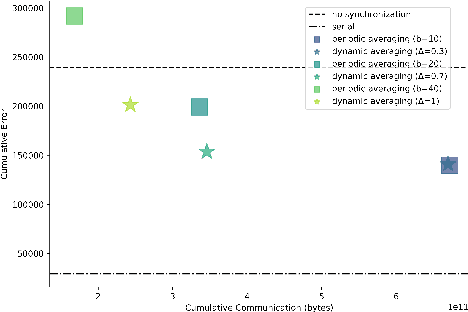
We propose an efficient protocol for decentralized training of deep neural networks from distributed data sources. The proposed protocol allows to handle different phases of model training equally well and to quickly adapt to concept drifts. This leads to a reduction of communication by an order of magnitude compared to periodically communicating state-of-the-art approaches. Moreover, we derive a communication bound that scales well with the hardness of the serialized learning problem. The reduction in communication comes at almost no cost, as the predictive performance remains virtually unchanged. Indeed, the proposed protocol retains loss bounds of periodically averaging schemes. An extensive empirical evaluation validates major improvement of the trade-off between model performance and communication which could be beneficial for numerous decentralized learning applications, such as autonomous driving, or voice recognition and image classification on mobile phones.