 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Artificial Intelligence Through a Christian Understanding of Human Flourishing
Apr 03, 2026Artificial intelligence (AI) alignment is fundamentally a formation problem, not only a safety problem. As Large Language Models (LLMs) increasingly mediate moral deliberation and spiritual inquiry, they do more than provide information; they function as instruments of digital catechesis, actively shaping and ordering human understanding, decision-making, and moral reflection. To make this formative influence visible and measurable, we introduce the Flourishing AI Benchmark: Christian Single-Turn (FAI-C-ST), a framework designed to evaluate Frontier Model responses against a Christian understanding of human flourishing across seven dimensions. By comparing 20 Frontier Models against both pluralistic and Christian-specific criteria, we show that current AI systems are not worldview-neutral. Instead, they default to a Procedural Secularism that lacks the grounding necessary to sustain theological coherence, resulting in a systematic performance decline of approximately 17 points across all dimensions of flourishing. Most critically, there is a 31-point decline in the Faith and Spirituality dimension. These findings suggest that the performance gap in values alignment is not a technical limitation, but arises from training objectives that prioritize broad acceptability and safety over deep, internally coherent moral or theological reasoning.
Model-assisted cohort selection with bias analysis for generating large-scale cohorts from the EHR for oncology research
Jan 13, 2020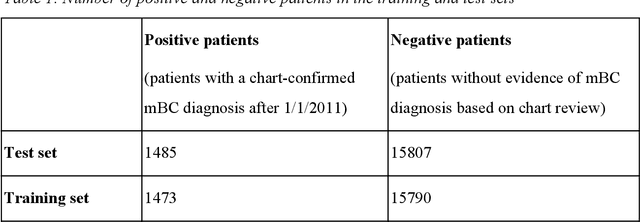
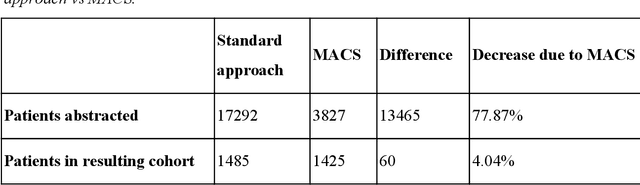
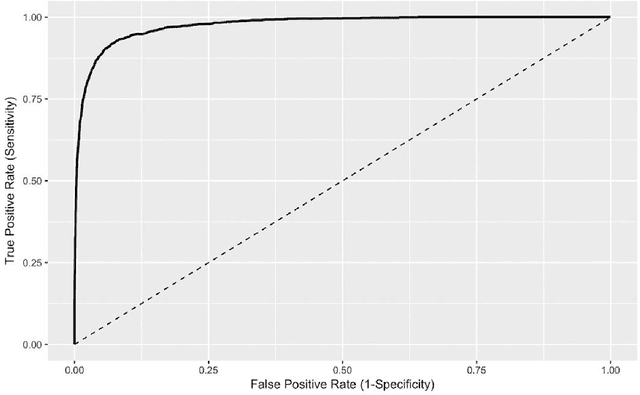
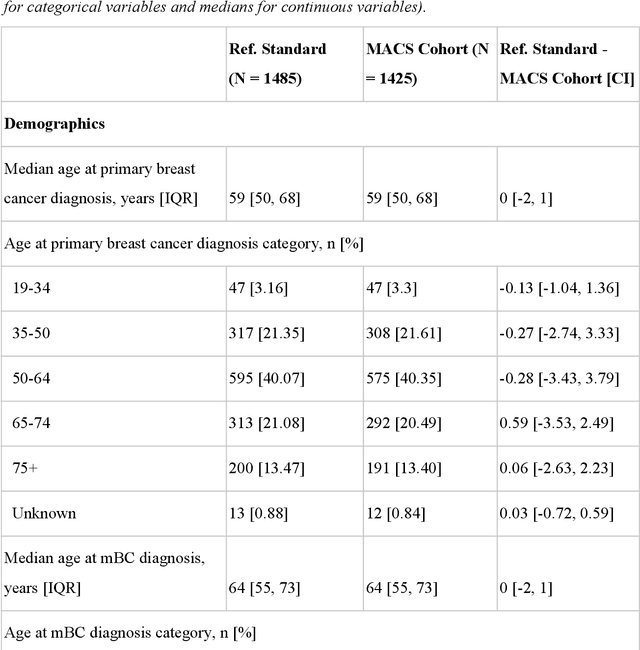
Objective Electronic health records (EHRs) are a promising source of data for health outcomes research in oncology. A challenge in using EHR data is that selecting cohorts of patients often requires information in unstructured parts of the record. Machine learning has been used to address this, but even high-performing algorithms may select patients in a non-random manner and bias the resulting cohort. To improve the efficiency of cohort selection while measuring potential bias, we introduce a technique called Model-Assisted Cohort Selection (MACS) with Bias Analysis and apply it to the selection of metastatic breast cancer (mBC) patients. Materials and Methods We trained a model on 17,263 patients using term-frequency inverse-document-frequency (TF-IDF) and logistic regression. We used a test set of 17,292 patients to measure algorithm performance and perform Bias Analysis. We compared the cohort generated by MACS to the cohort that would have been generated without MACS as reference standard, first by comparing distributions of an extensive set of clinical and demographic variables and then by comparing the results of two analyses addressing existing example research questions. Results Our algorithm had an area under the curve (AUC) of 0.976, a sensitivity of 96.0%, and an abstraction efficiency gain of 77.9%. During Bias Analysis, we found no large differences in baseline characteristics and no differences in the example analyses. Conclusion MACS with bias analysis can significantly improve the efficiency of cohort selection on EHR data while instilling confidence that outcomes research performed on the resulting cohort will not be biased.