 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow LLMs Detect and Correct Their Own Errors: The Role of Internal Confidence Signals
Apr 24, 2026Large language models can detect their own errors and sometimes correct them without external feedback, but the underlying mechanisms remain unknown. We investigate this through the lens of second-order models of confidence from decision neuroscience. In a first-order system, confidence derives from the generation signal itself and is therefore maximal for the chosen response, precluding error detection. Second-order models posit a partially independent evaluative signal that can disagree with the committed response, providing the basis for error detection. Kumaran et al. (2026) showed that LLMs cache a confidence representation at a token immediately following the answer (i.e. post-answer newline: PANL) -- that causally drives verbal confidence and dissociates from log-probabilities. Here we test whether this PANL signal extends beyond confidence to support error detection and self-correction. Here we test whether this signal supports error detection and self-correction, deriving predictions from the second-order framework. Using a verify-then-correct paradigm, we show that: (i) verbal confidence predicts error detection far beyond token log-probabilities, ruling out a first-order account; (ii) PANL activations predict error detection beyond verbal confidence itself; and (iii) PANL predicts which errors the model can correct -- where all behavioural signals fail. Causal interventions confirm that PANL signals rescue error detection behavior when answer information is corrupted. All findings replicate across models (Gemma 3 27B and Qwen 2.5 7B) and tasks (TriviaQA and MNLI). These results reveal that LLMs naturally implement a second-order confidence architecture whose internal evaluative signal encodes not only whether an answer is likely wrong but whether the model has the knowledge to fix it.
Causal Evidence that Language Models use Confidence to Drive Behavior
Mar 23, 2026Metacognition -- the ability to assess one's own cognitive performance -- is documented across species, with internal confidence estimates serving as a key signal for adaptive behavior. While confidence can be extracted from Large Language Model (LLM) outputs, whether models actively use these signals to regulate behavior remains a fundamental question. We investigate this through a four-phase abstention paradigm.Phase 1 established internal confidence estimates in the absence of an abstention option. Phase 2 revealed that LLMs apply implicit thresholds to these estimates when deciding to answer or abstain. Confidence emerged as the dominant predictor of behavior, with effect sizes an order of magnitude larger than knowledge retrieval accessibility (RAG scores) or surface-level semantic features. Phase 3 provided causal evidence through activation steering: manipulating internal confidence signals correspondingly shifted abstention rates. Finally, Phase 4 demonstrated that models can systematically vary abstention policies based on instructed thresholds.Our findings indicate that abstention arises from the joint operation of internal confidence representations and threshold-based policies, mirroring the two-stage metacognitive control found in biological systems. This capacity is essential as LLMs transition into autonomous agents that must recognize their own uncertainty to decide when to act or seek help.
How do LLMs Compute Verbal Confidence
Mar 18, 2026Verbal confidence -- prompting LLMs to state their confidence as a number or category -- is widely used to extract uncertainty estimates from black-box models. However, how LLMs internally generate such scores remains unknown. We address two questions: first, when confidence is computed - just-in-time when requested, or automatically during answer generation and cached for later retrieval; and second, what verbal confidence represents - token log-probabilities, or a richer evaluation of answer quality? Focusing on Gemma 3 27B and Qwen 2.5 7B, we provide convergent evidence for cached retrieval. Activation steering, patching, noising, and swap experiments reveal that confidence representations emerge at answer-adjacent positions before appearing at the verbalization site. Attention blocking pinpoints the information flow: confidence is gathered from answer tokens, cached at the first post-answer position, then retrieved for output. Critically, linear probing and variance partitioning reveal that these cached representations explain substantial variance in verbal confidence beyond token log-probabilities, suggesting a richer answer-quality evaluation rather than a simple fluency readout. These findings demonstrate that verbal confidence reflects automatic, sophisticated self-evaluation -- not post-hoc reconstruction -- with implications for understanding metacognition in LLMs and improving calibration.
Optimizers Qualitatively Alter Solutions And We Should Leverage This
Jul 16, 2025Due to the nonlinear nature of Deep Neural Networks (DNNs), one can not guarantee convergence to a unique global minimum of the loss when using optimizers relying only on local information, such as SGD. Indeed, this was a primary source of skepticism regarding the feasibility of DNNs in the early days of the field. The past decades of progress in deep learning have revealed this skepticism to be misplaced, and a large body of empirical evidence shows that sufficiently large DNNs following standard training protocols exhibit well-behaved optimization dynamics that converge to performant solutions. This success has biased the community to use convex optimization as a mental model for learning, leading to a focus on training efficiency, either in terms of required iteration, FLOPs or wall-clock time, when improving optimizers. We argue that, while this perspective has proven extremely fruitful, another perspective specific to DNNs has received considerably less attention: the optimizer not only influences the rate of convergence, but also the qualitative properties of the learned solutions. Restated, the optimizer can and will encode inductive biases and change the effective expressivity of a given class of models. Furthermore, we believe the optimizer can be an effective way of encoding desiderata in the learning process. We contend that the community should aim at understanding the biases of already existing methods, as well as aim to build new optimizers with the explicit intent of inducing certain properties of the solution, rather than solely judging them based on their convergence rates. We hope our arguments will inspire research to improve our understanding of how the learning process can impact the type of solution we converge to, and lead to a greater recognition of optimizers design as a critical lever that complements the roles of architecture and data in shaping model outcomes.
How to transfer algorithmic reasoning knowledge to learn new algorithms?
Oct 26, 2021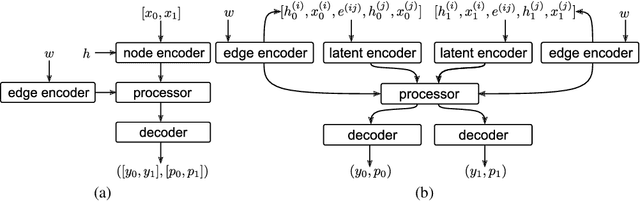

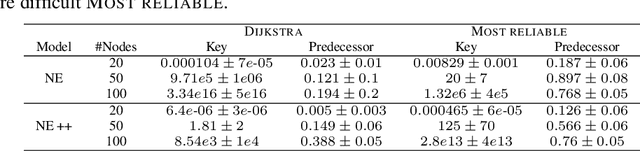
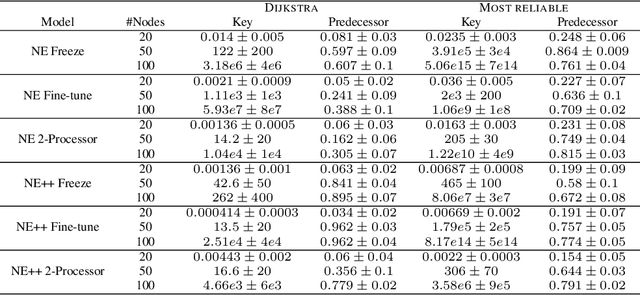
Learning to execute algorithms is a fundamental problem that has been widely studied. Prior work~\cite{veli19neural} has shown that to enable systematic generalisation on graph algorithms it is critical to have access to the intermediate steps of the program/algorithm. In many reasoning tasks, where algorithmic-style reasoning is important, we only have access to the input and output examples. Thus, inspired by the success of pre-training on similar tasks or data in Natural Language Processing (NLP) and Computer Vision, we set out to study how we can transfer algorithmic reasoning knowledge. Specifically, we investigate how we can use algorithms for which we have access to the execution trace to learn to solve similar tasks for which we do not. We investigate two major classes of graph algorithms, parallel algorithms such as breadth-first search and Bellman-Ford and sequential greedy algorithms such as Prim and Dijkstra. Due to the fundamental differences between algorithmic reasoning knowledge and feature extractors such as used in Computer Vision or NLP, we hypothesise that standard transfer techniques will not be sufficient to achieve systematic generalisation. To investigate this empirically we create a dataset including 9 algorithms and 3 different graph types. We validate this empirically and show how instead multi-task learning can be used to achieve the transfer of algorithmic reasoning knowledge.