 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Cloud-Grade SLOs for Local Mixture-of-Experts Inference through CPU-GPU Hybrid Design
Jun 09, 2026Local deployment of large Mixture-of-Experts (MoE) models falls short of the service quality achieved in cloud-scale environments, even under low-concurrency workloads. We identify four key gaps in local MoE inference: reliance on capacity-reduced models (quantized, distilled, rerouted), inability to meet 30-second TTFT for long prefills (more than 12K), sub-baseline decode throughput (under 20 tokens/s), and poor concurrency under mixed prefill-decode and batched decode workloads. We present a CPU-GPU hybrid system that achieves cloud-level SLOs on dual-socket commodity CPUs and consumer GPUs by (1) stream-loading prefill (SLP), boosting prefill throughput to 1,200 tokens/s and enabling 32K prompts within 30 seconds; (2) distributed SLP (DSLP) with SmallEP expert parallelism, reaching 1,800 tokens/s and 45K prompts in 30 seconds on two RTX 5090s; (3) intra-node prefill-decode disaggregation with zero-copy shared weights and a dual-batch attention-MoE overlap scheme, sustaining concurrency with under 15 percent latency increase and 50 percent throughput gains; (4) an AVX-512-optimized FP8 GEMV kernel, enabling native CPU FP8 inference while delivering 4-5x lower CPU latency; and (5) fine-grained CPU parallelism that attains 28 tokens/s on INT4 DeepSeek-V3 and 21.5 tokens/s on intact FP8 V3. Evaluations show our system delivers cloud-level QoS for flagship MoE models on consumer CPU-GPU platforms, reshaping local deployment with intact, original-precision inference and enabling high-quality, cost-effective access without datacenter infrastructure.
Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
May 26, 2026Large language models (LLMs) have shown strong empirical gains as self-evolving agents for CUDA kernel generation, driven by feedback-conditioned planning across generations. However, how planning decisions attribute and combine heterogeneous feedback signals remains opaque. Standard end-to-end ablations fail to resolve this question, as iterative planning amplifies early perturbations and conflates feedback effects with trajectory-dependent drift. We introduce \texttt{CUDAnalyst}, a unified analysis layer for controlled, generation-level attribution of planning decisions to feedback components via trajectory freezing and selective feedback injection. \texttt{CUDAnalyst} enables stable generation-level evaluation and principled coalitional-style attribution of feedback effects and interactions. Our results show that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones. These trends hold across reference backbones, representative workloads, and reference induction regimes, indicating that the identified feedback-to-plan structure is robust within the controlled axes studied.
BrainFuse: a unified infrastructure integrating realistic biological modeling and core AI methodology
Jan 29, 2026Neuroscience and artificial intelligence represent distinct yet complementary pathways to general intelligence. However, amid the ongoing boom in AI research and applications, the translational synergy between these two fields has grown increasingly elusive-hampered by a widening infrastructural incompatibility: modern AI frameworks lack native support for biophysical realism, while neural simulation tools are poorly suited for gradient-based optimization and neuromorphic hardware deployment. To bridge this gap, we introduce BrainFuse, a unified infrastructure that provides comprehensive support for biophysical neural simulation and gradient-based learning. By addressing algorithmic, computational, and deployment challenges, BrainFuse exhibits three core capabilities: (1) algorithmic integration of detailed neuronal dynamics into a differentiable learning framework; (2) system-level optimization that accelerates customizable ion-channel dynamics by up to 3,000x on GPUs; and (3) scalable computation with highly compatible pipelines for neuromorphic hardware deployment. We demonstrate this full-stack design through both AI and neuroscience tasks, from foundational neuron simulation and functional cylinder modeling to real-world deployment and application scenarios. For neuroscience, BrainFuse supports multiscale biological modeling, enabling the deployment of approximately 38,000 Hodgkin-Huxley neurons with 100 million synapses on a single neuromorphic chip while consuming as low as 1.98 W. For AI, BrainFuse facilitates the synergistic application of realistic biological neuron models, demonstrating enhanced robustness to input noise and improved temporal processing endowed by complex HH dynamics. BrainFuse therefore serves as a foundational engine to facilitate cross-disciplinary research and accelerate the development of next-generation bio-inspired intelligent systems.
Singular Value Decomposition on Kronecker Adaptation for Large Language Model
Jun 18, 2025Large pre-trained Transformer models achieve state-of-the-art results across diverse language and reasoning tasks, but full fine-tuning incurs substantial storage, memory, and computational overhead. Parameter-efficient fine-tuning (PEFT) methods mitigate these costs by learning only a small subset of task-specific parameters, yet existing approaches either introduce inference-time latency (adapter modules), suffer from suboptimal convergence (randomly initialized low-rank updates), or rely on fixed rank choices that may not match task complexity (Kronecker-based decompositions). We propose SoKA (SVD on Kronecker Adaptation), a novel PEFT strategy that combines Kronecker-product tensor factorization with SVD-driven initialization and spectrum-aware dynamic rank selection. Our Kronecker-Product SVD (KPSVD) procedure extracts principal components of the full weight update into compact Kronecker factors, while an adaptive rank selection algorithm uses energy-threshold and elbow-point criteria to prune negligible components. Empirical evaluation on LLaMA2-7B across arithmetic reasoning (GSM8K), formal mathematics (MATH), and code generation (MBPP) demonstrates that SoKA requires only 0.99M trainable parameters, 25% fewer than LoRA/PiSSA, while matching or exceeding baseline performance. Moreover, SoKA exhibits faster convergence and more stable gradients, highlighting its robustness and efficiency for large-scale model adaptation.
Pipelining Kruskal's: A Neuromorphic Approach for Minimum Spanning Tree
May 19, 2025Neuromorphic computing, characterized by its event-driven computation and massive parallelism, is particularly effective for handling data-intensive tasks in low-power environments, such as computing the minimum spanning tree (MST) for large-scale graphs. The introduction of dynamic synaptic modifications provides new design opportunities for neuromorphic algorithms. Building on this foundation, we propose an SNN-based union-sort routine and a pipelined version of Kruskal's algorithm for MST computation. The event-driven nature of our method allows for the concurrent execution of two completely decoupled stages: neuromorphic sorting and union-find. Our approach demonstrates superior performance compared to state-of-the-art Prim 's-based methods on large-scale graphs from the DIMACS10 dataset, achieving speedups by 269.67x to 1283.80x, with a median speedup of 540.76x. We further evaluate the pipelined implementation against two serial variants of Kruskal's algorithm, which rely on neuromorphic sorting and neuromorphic radix sort, showing significant performance advantages in most scenarios.
Hierarchical Macro Strategy Model for MOBA Game AI
Dec 19, 2018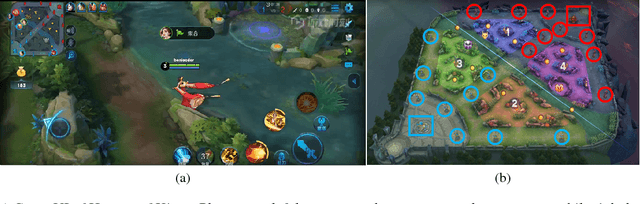

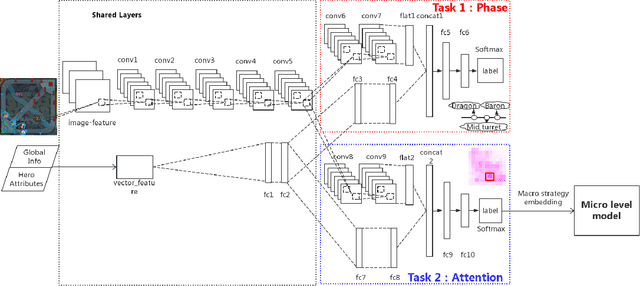
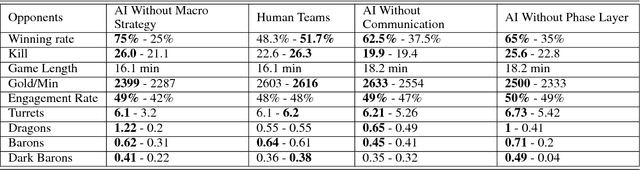
The next challenge of game AI lies in Real Time Strategy (RTS) games. RTS games provide partially observable gaming environments, where agents interact with one another in an action space much larger than that of GO. Mastering RTS games requires both strong macro strategies and delicate micro level execution. Recently, great progress has been made in micro level execution, while complete solutions for macro strategies are still lacking. In this paper, we propose a novel learning-based Hierarchical Macro Strategy model for mastering MOBA games, a sub-genre of RTS games. Trained by the Hierarchical Macro Strategy model, agents explicitly make macro strategy decisions and further guide their micro level execution. Moreover, each of the agents makes independent strategy decisions, while simultaneously communicating with the allies through leveraging a novel imitated cross-agent communication mechanism. We perform comprehensive evaluations on a popular 5v5 Multiplayer Online Battle Arena (MOBA) game. Our 5-AI team achieves a 48% winning rate against human player teams which are ranked top 1% in the player ranking system.