 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Diffusion based on Preference Disentanglement for Generative Recommendation
Jun 01, 2026Recently, Generative Recommenders (GRs) have emerged as a transformative recommendation paradigm by replacing traditional item IDs with semantic indices (SIDs). Owing to the exceptional generative capabilities of diffusion models, a few pioneering works explore developing GRs with diffusion architectures as the backbone. However, a fatal limitation of existing diffusion-based GRs is that the diffusion process applies uniformly to all items within the historical interactions. In contrast, the user preference is shaped by multifaceted time-evolving factors and thus exhibits a non-stationary distribution in the temporal aspect. To bridge this gap, this study proposes a novel GR framework, named TDPM, by designing the time-aware diffusion on SID tokens. Specifically, TDPM explicitly integrates the impact of time-evolving user preferences into the diffusion process. In detail, the user preference is disentangled into (i) the period preference, which remains consistent over a long time-span, and (ii) the point preference, which is triggered by recent focal events. Extensive experiments on three public real-world datasets demonstrate the significant superiority of TDPM over the state-of-the-art baselines. TDPM achieves average improvements of up to 29.21% and 25.45% in terms of HR@20 and NDCG@20, respectively. The ablation study further underscores the necessity of time-aware token diffusion in diffusion-based GRs.
Rel-MOSS: Towards Imbalanced Relational Deep Learning on Relational Databases
Mar 09, 2026In recent advances, to enable a fully data-driven learning paradigm on relational databases (RDB), relational deep learning (RDL) is proposed to structure the RDB as a heterogeneous entity graph and adopt the graph neural network (GNN) as the predictive model. However, existing RDL methods neglect the imbalance problem of relational data in RDBs and risk under-representing the minority entities, leading to an unusable model in practice. In this work, we investigate, for the first time, class imbalance problem in RDB entity classification and design the relation-centric minority synthetic over-sampling GNN (Rel-MOSS), in order to fill a critical void in the current literature. Specifically, to mitigate the issue of minority-related information being submerged by majority counterparts, we design the relation-wise gating controller to modulate neighborhood messages from each individual relation type. Based on the relational-gated representations, we further propose the relation-guided minority synthesizer for over-sampling, which integrates the entity relational signatures to maintain relational consistency. Extensive experiments on 12 entity classification datasets provide compelling evidence for the superiority of Rel-MOSS, yielding an average improvement of up to 2.46% and 4.00% in terms of Balanced Accuracy and G-Mean, compared with SOTA RDL methods and classic methods for handling class imbalance.
Exploiting Dynamic and Fine-grained Semantic Scope for Extreme Multi-label Text Classification
May 24, 2022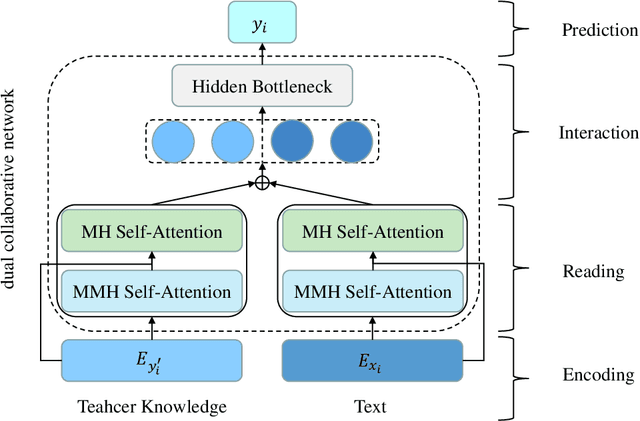

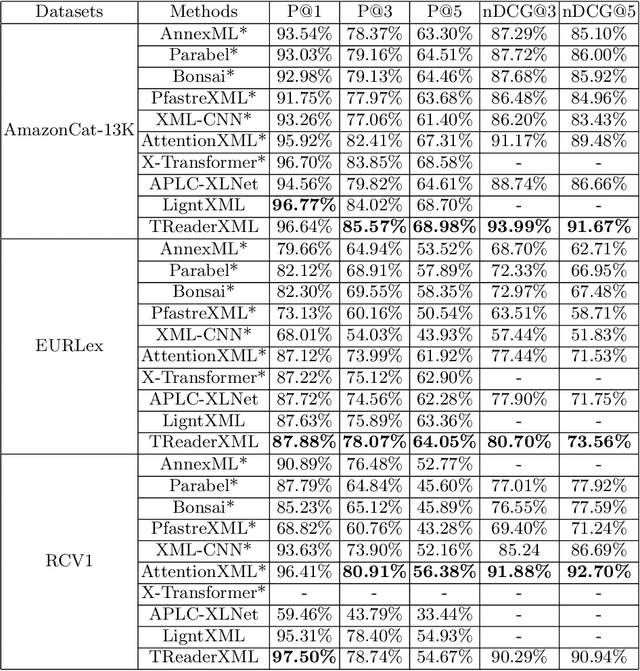
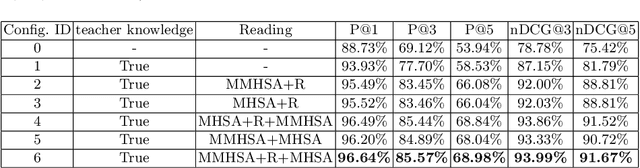
Extreme multi-label text classification (XMTC) refers to the problem of tagging a given text with the most relevant subset of labels from a large label set. A majority of labels only have a few training instances due to large label dimensionality in XMTC. To solve this data sparsity issue, most existing XMTC methods take advantage of fixed label clusters obtained in early stage to balance performance on tail labels and head labels. However, such label clusters provide static and coarse-grained semantic scope for every text, which ignores distinct characteristics of different texts and has difficulties modelling accurate semantics scope for texts with tail labels. In this paper, we propose a novel framework TReaderXML for XMTC, which adopts dynamic and fine-grained semantic scope from teacher knowledge for individual text to optimize text conditional prior category semantic ranges. TReaderXML dynamically obtains teacher knowledge for each text by similar texts and hierarchical label information in training sets to release the ability of distinctly fine-grained label-oriented semantic scope. Then, TReaderXML benefits from a novel dual cooperative network that firstly learns features of a text and its corresponding label-oriented semantic scope by parallel Encoding Module and Reading Module, secondly embeds two parts by Interaction Module to regularize the text's representation by dynamic and fine-grained label-oriented semantic scope, and finally find target labels by Prediction Module. Experimental results on three XMTC benchmark datasets show that our method achieves new state-of-the-art results and especially performs well for severely imbalanced and sparse datasets.