 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning suppresses simulation bias in predictive models built from sparse, multi-modal data
Apr 19, 2021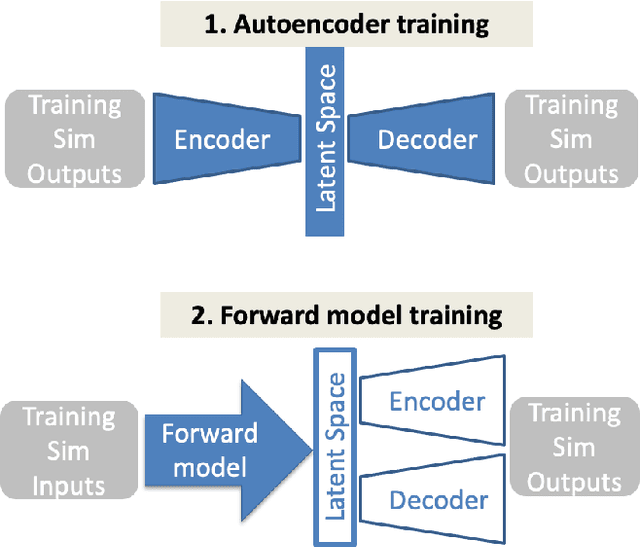
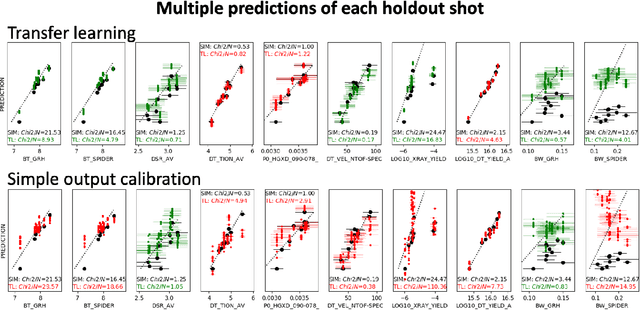
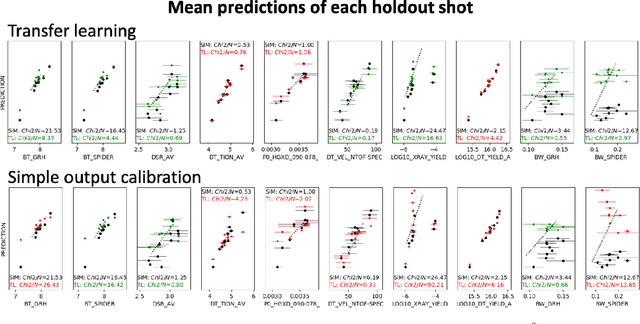
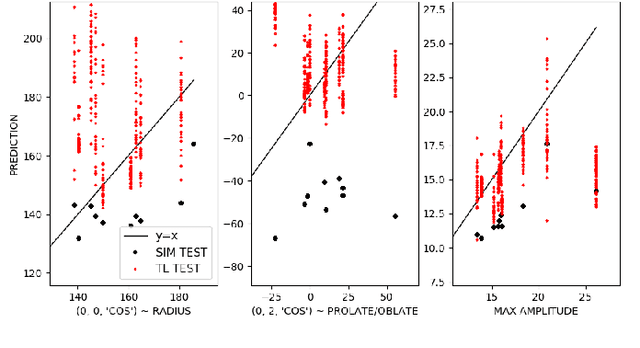
Many problems in science, engineering, and business require making predictions based on very few observations. To build a robust predictive model, these sparse data may need to be augmented with simulated data, especially when the design space is multidimensional. Simulations, however, often suffer from an inherent bias. Estimation of this bias may be poorly constrained not only because of data sparsity, but also because traditional predictive models fit only one type of observations, such as scalars or images, instead of all available data modalities, which might have been acquired and simulated at great cost. We combine recent developments in deep learning to build more robust predictive models from multimodal data with a recent, novel technique to suppress the bias, and extend it to take into account multiple data modalities. First, an initial, simulation-trained, neural network surrogate model learns important correlations between different data modalities and between simulation inputs and outputs. Then, the model is partially retrained, or transfer learned, to fit the observations. Using fewer than 10 inertial confinement fusion experiments for retraining, we demonstrate that this technique systematically improves simulation predictions while a simple output calibration makes predictions worse. We also offer extensive cross-validation with real and synthetic data to support our findings. The transfer learning method can be applied to other problems that require transferring knowledge from simulations to the domain of real observations. This paper opens up the path to model calibration using multiple data types, which have traditionally been ignored in predictive models.
Meaningful uncertainties from deep neural network surrogates of large-scale numerical simulations
Oct 26, 2020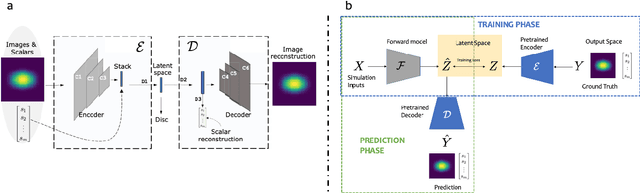
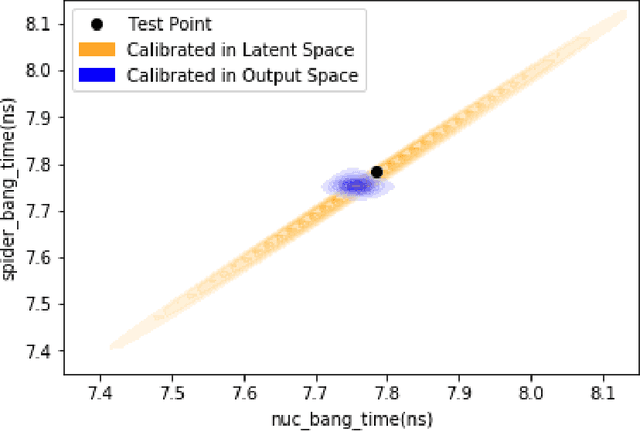
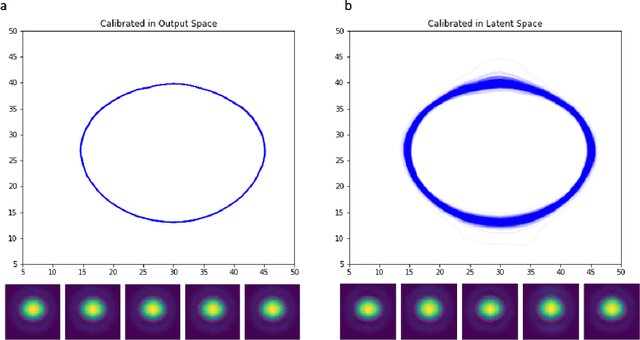
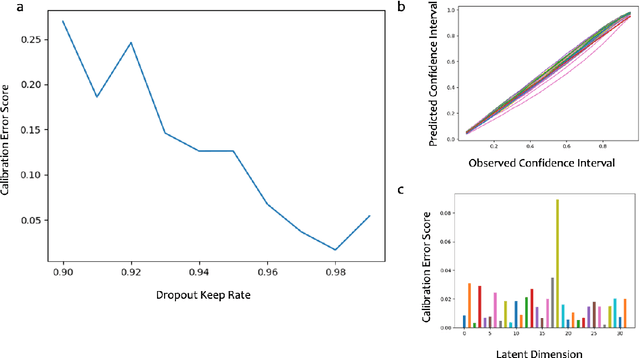
Large-scale numerical simulations are used across many scientific disciplines to facilitate experimental development and provide insights into underlying physical processes, but they come with a significant computational cost. Deep neural networks (DNNs) can serve as highly-accurate surrogate models, with the capacity to handle diverse datatypes, offering tremendous speed-ups for prediction and many other downstream tasks. An important use-case for these surrogates is the comparison between simulations and experiments; prediction uncertainty estimates are crucial for making such comparisons meaningful, yet standard DNNs do not provide them. In this work we define the fundamental requirements for a DNN to be useful for scientific applications, and demonstrate a general variational inference approach to equip predictions of scalar and image data from a DNN surrogate model trained on inertial confinement fusion simulations with calibrated Bayesian uncertainties. Critically, these uncertainties are interpretable, meaningful and preserve physics-correlations in the predicted quantities.
Machine Learning-Powered Mitigation Policy Optimization in Epidemiological Models
Oct 16, 2020
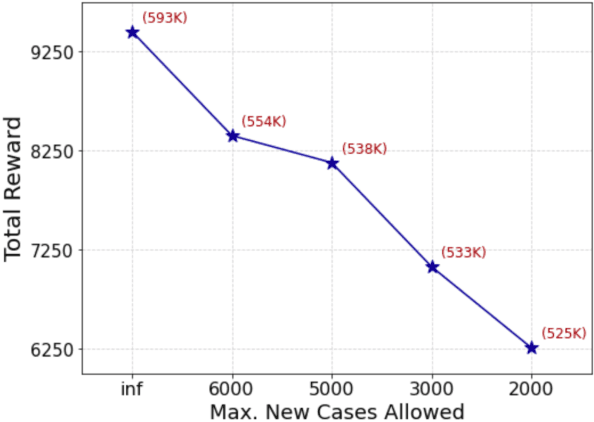

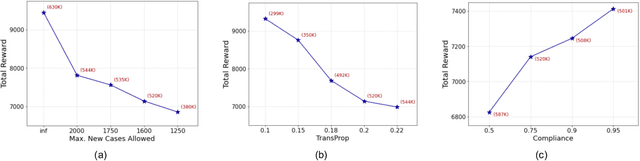
A crucial aspect of managing a public health crisis is to effectively balance prevention and mitigation strategies, while taking their socio-economic impact into account. In particular, determining the influence of different non-pharmaceutical interventions (NPIs) on the effective use of public resources is an important problem, given the uncertainties on when a vaccine will be made available. In this paper, we propose a new approach for obtaining optimal policy recommendations based on epidemiological models, which can characterize the disease progression under different interventions, and a look-ahead reward optimization strategy to choose the suitable NPI at different stages of an epidemic. Given the time delay inherent in any epidemiological model and the exponential nature especially of an unmanaged epidemic, we find that such a look-ahead strategy infers non-trivial policies that adhere well to the constraints specified. Using two different epidemiological models, namely SEIR and EpiCast, we evaluate the proposed algorithm to determine the optimal NPI policy, under a constraint on the number of daily new cases and the primary reward being the absence of restrictions.
Accurate Calibration of Agent-based Epidemiological Models with Neural Network Surrogates
Oct 13, 2020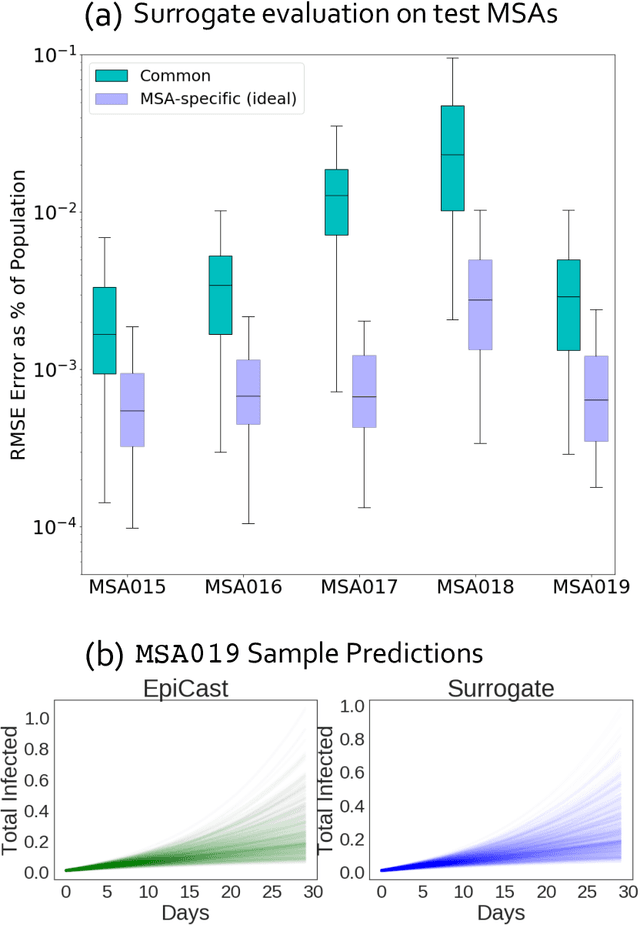

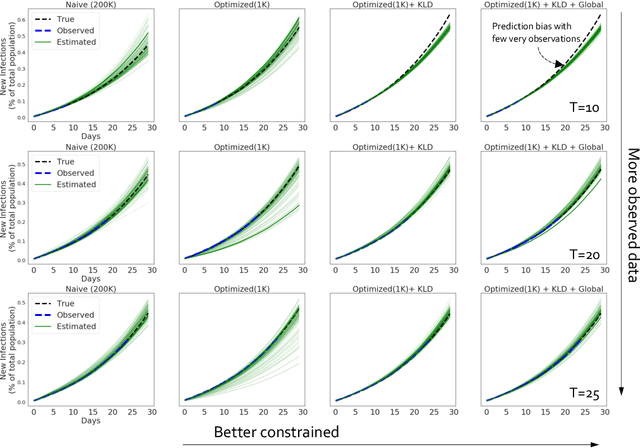

Calibrating complex epidemiological models to observed data is a crucial step to provide both insights into the current disease dynamics, i.e.\ by estimating a reproductive number, as well as to provide reliable forecasts and scenario explorations. Here we present a new approach to calibrate an agent-based model -- EpiCast -- using a large set of simulation ensembles for different major metropolitan areas of the United States. In particular, we propose: a new neural network based surrogate model able to simultaneously emulate all different locations; and a novel posterior estimation that provides not only more accurate posterior estimates of all parameters but enables the joint fitting of global parameters across regions.
Accurate and Robust Feature Importance Estimation under Distribution Shifts
Sep 30, 2020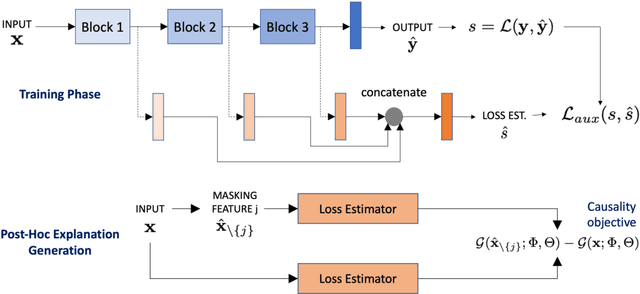
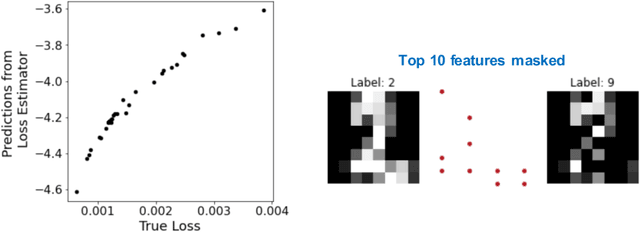
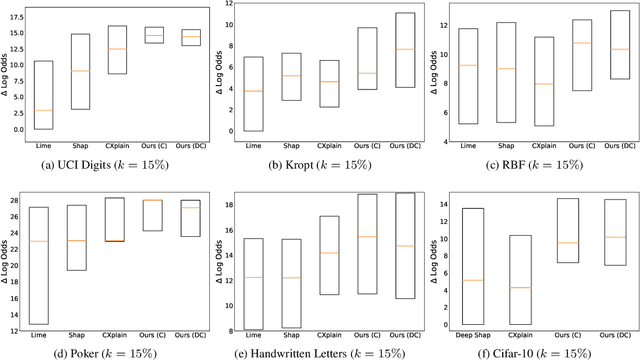
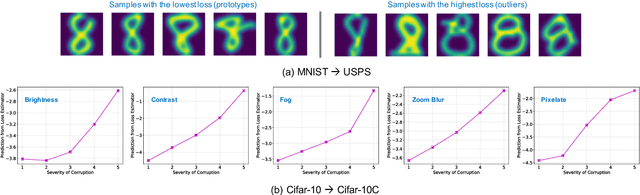
With increasing reliance on the outcomes of black-box models in critical applications, post-hoc explainability tools that do not require access to the model internals are often used to enable humans understand and trust these models. In particular, we focus on the class of methods that can reveal the influence of input features on the predicted outputs. Despite their wide-spread adoption, existing methods are known to suffer from one or more of the following challenges: computational complexities, large uncertainties and most importantly, inability to handle real-world domain shifts. In this paper, we propose PRoFILE, a novel feature importance estimation method that addresses all these challenges. Through the use of a loss estimator jointly trained with the predictive model and a causal objective, PRoFILE can accurately estimate the feature importance scores even under complex distribution shifts, without any additional re-training. To this end, we also develop learning strategies for training the loss estimator, namely contrastive and dropout calibration, and find that it can effectively detect distribution shifts. Using empirical studies on several benchmark image and non-image data, we show significant improvements over state-of-the-art approaches, both in terms of fidelity and robustness.
Designing Accurate Emulators for Scientific Processes using Calibration-Driven Deep Models
May 05, 2020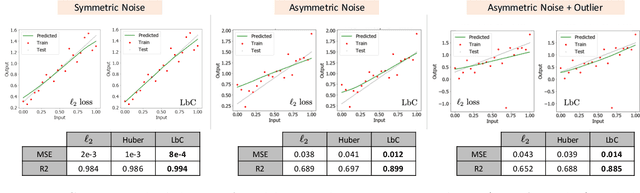
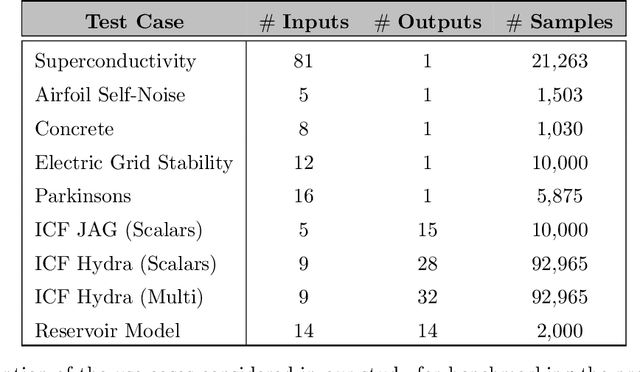
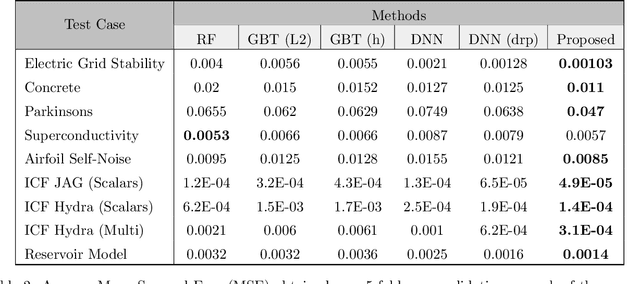
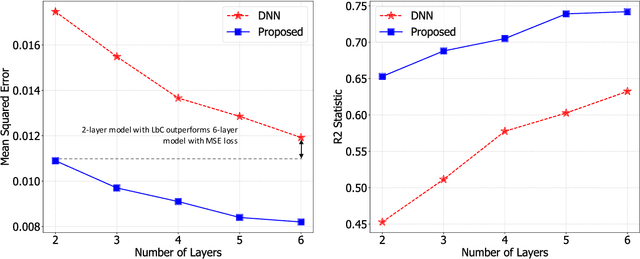
Predictive models that accurately emulate complex scientific processes can achieve exponential speed-ups over numerical simulators or experiments, and at the same time provide surrogates for improving the subsequent analysis. Consequently, there is a recent surge in utilizing modern machine learning (ML) methods, such as deep neural networks, to build data-driven emulators. While the majority of existing efforts has focused on tailoring off-the-shelf ML solutions to better suit the scientific problem at hand, we study an often overlooked, yet important, problem of choosing loss functions to measure the discrepancy between observed data and the predictions from a model. Due to lack of better priors on the expected residual structure, in practice, simple choices such as the mean squared error and the mean absolute error are made. However, the inherent symmetric noise assumption made by these loss functions makes them inappropriate in cases where the data is heterogeneous or when the noise distribution is asymmetric. We propose Learn-by-Calibrating (LbC), a novel deep learning approach based on interval calibration for designing emulators in scientific applications, that are effective even with heterogeneous data and are robust to outliers. Using a large suite of use-cases, we show that LbC provides significant improvements in generalization error over widely-adopted loss function choices, achieves high-quality emulators even in small data regimes and more importantly, recovers the inherent noise structure without any explicit priors.
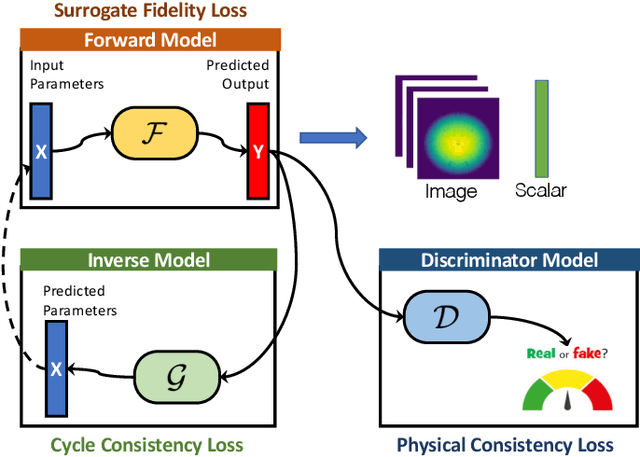
Improved Surrogates in Inertial Confinement Fusion with Manifold and Cycle Consistencies
Dec 17, 2019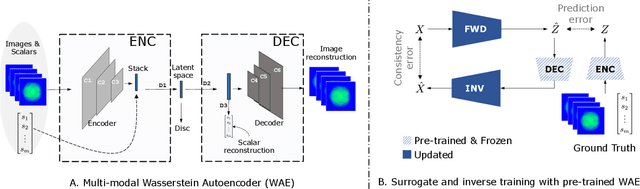

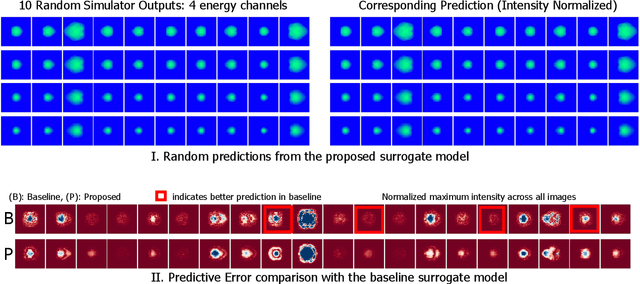
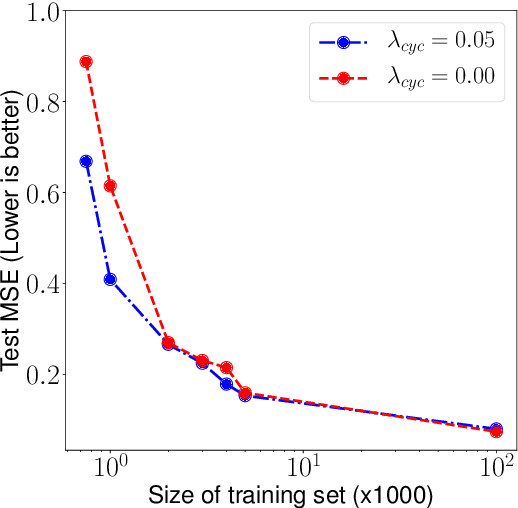
Neural networks have become very popular in surrogate modeling because of their ability to characterize arbitrary, high dimensional functions in a data driven fashion. This paper advocates for the training of surrogates that are consistent with the physical manifold -- i.e., predictions are always physically meaningful, and are cyclically consistent -- i.e., when the predictions of the surrogate, when passed through an independently trained inverse model give back the original input parameters. We find that these two consistencies lead to surrogates that are superior in terms of predictive performance, more resilient to sampling artifacts, and tend to be more data efficient. Using Inertial Confinement Fusion (ICF) as a test bed problem, we model a 1D semi-analytic numerical simulator and demonstrate the effectiveness of our approach. Code and data are available at https://github.com/rushilanirudh/macc/
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019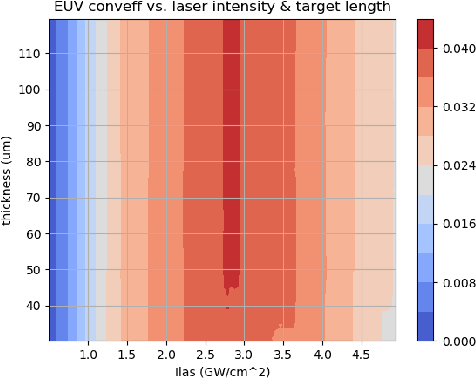
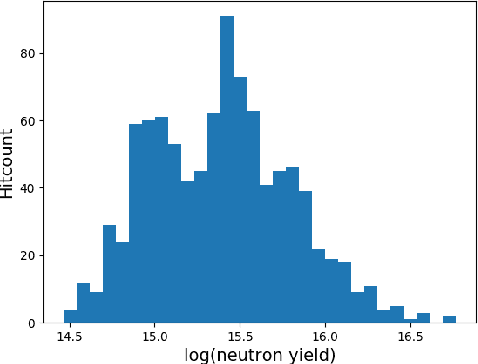
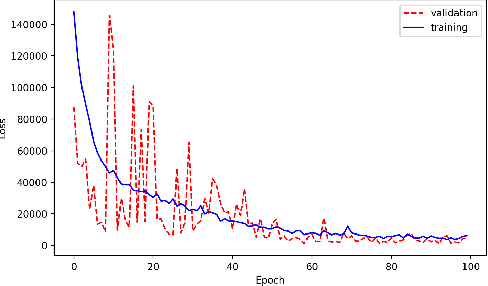
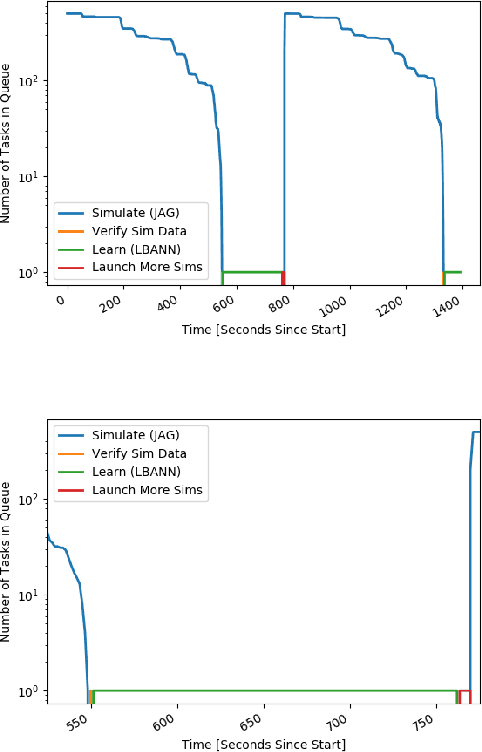
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.
Parallelizing Training of Deep Generative Models on Massive Scientific Datasets
Oct 05, 2019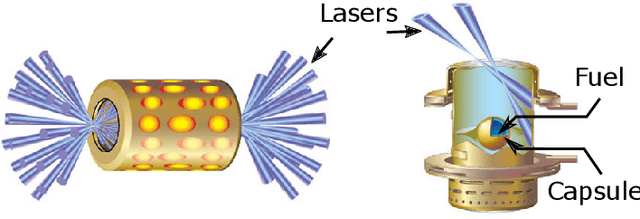
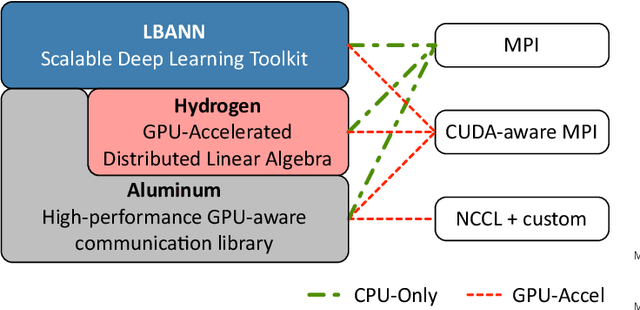
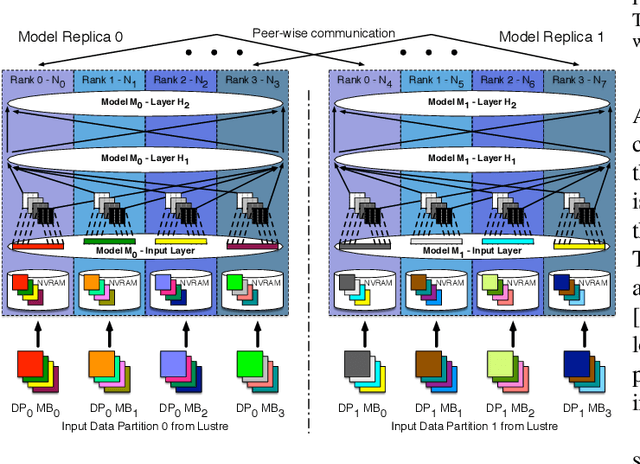
Training deep neural networks on large scientific data is a challenging task that requires enormous compute power, especially if no pre-trained models exist to initialize the process. We present a novel tournament method to train traditional as well as generative adversarial networks built on LBANN, a scalable deep learning framework optimized for HPC systems. LBANN combines multiple levels of parallelism and exploits some of the worlds largest supercomputers. We demonstrate our framework by creating a complex predictive model based on multi-variate data from high-energy-density physics containing hundreds of millions of images and hundreds of millions of scalar values derived from tens of millions of simulations of inertial confinement fusion. Our approach combines an HPC workflow and extends LBANN with optimized data ingestion and the new tournament-style training algorithm to produce a scalable neural network architecture using a CORAL-class supercomputer. Experimental results show that 64 trainers (1024 GPUs) achieve a speedup of 70.2 over a single trainer (16 GPUs) baseline, and an effective 109% parallel efficiency.
Exploring Generative Physics Models with Scientific Priors in Inertial Confinement Fusion
Oct 03, 2019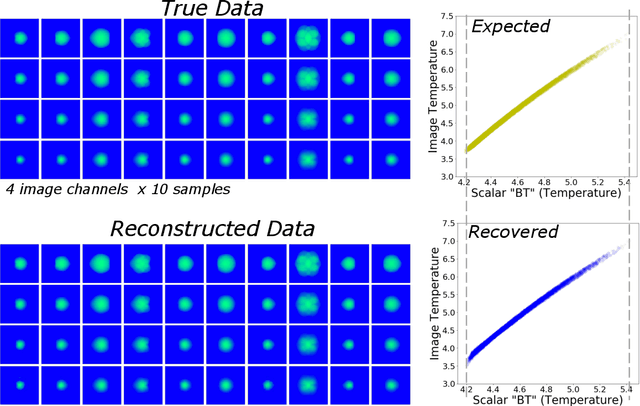
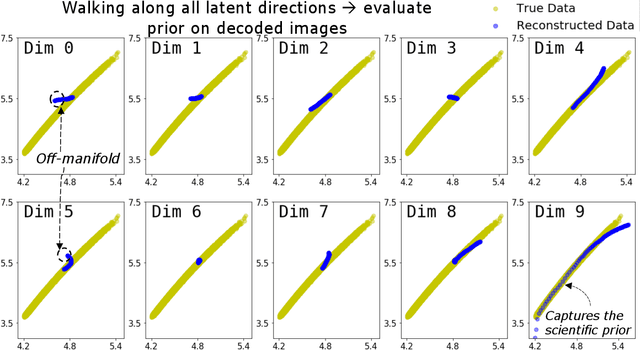
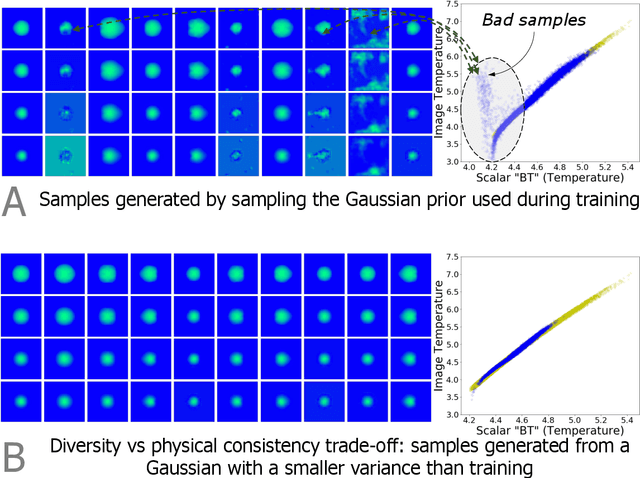
There is significant interest in using modern neural networks for scientific applications due to their effectiveness in modeling highly complex, non-linear problems in a data-driven fashion. However, a common challenge is to verify the scientific plausibility or validity of outputs predicted by a neural network. This work advocates the use of known scientific constraints as a lens into evaluating, exploring, and understanding such predictions for the problem of inertial confinement fusion.