 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Developers: Towards Reliable Patch Validation at Scale for Linux
Mar 25, 2026Patch reviewing is critical for software development, especially in distributed open-source development, which highly depends on voluntary work, such as Linux. This paper studies the past 10 years of patch reviews of the Linux memory management subsystem to characterize the challenges involved in patch reviewing at scale. Our study reveals that the review process is still primarily reliant on human effort despite a wide-range of automatic checking tools. Although kernel developers strive to review all patch proposals, they struggle to keep up with the increasing volume of submissions and depend significantly on a few developers for these reviews. To help scale the patch review process, we introduce FLINT, a patch validation system framework that synthesizes insights from past discussions among developers and automatically analyzes patch proposals for compliance. FLINT employs a rule-based analysis informed by past discussions among developers and an LLM that does not require training or fine-tuning on new data, and can continuously improve with minimum human effort. FLINT uses a multi-stage approach to efficiently distill the essential information from past discussions. Later, when a patch proposal needs review, FLINT retrieves the relevant validation rules for validation and generates a reference-backed report that developers can easily interpret and validate. FLINT targets bugs that traditional tools find hard to detect, ranging from maintainability issues, e.g., design choices and naming conventions, to complex concurrency issues, e.g., deadlocks and data races. FLINT detected 2 new issues in Linux v6.18 development cycle and 7 issues in previous versions. FLINT achieves 21% and 14% of higher ground-truth coverage on concurrency bugs than the baseline with LLM only. Moreover, FLINT achieves a 35% false positive rate, which is lower than the baseline.
Symbol Rate Maximization in Rolling-Shutter OCC: Design and Implementation Considerations
Feb 09, 2026Optical Camera Communication (OCC) systems can take advantage of the row-by-row scanning process of rolling-shutter cameras to capture the fast variations of light intensity coming from Visible Light Communication (VLC) LED-based transmitters. In order to study the maximum data rate that is feasible in such kind of OCC systems, this paper presents its equivalent digital communication system model in which the rolling-shutter camera is modeled as a rectangular matched-filter whose time width is equal to the exposure time of the camera, followed by a sampling process at the pixel row sweep rate of the camera. Based on the proposed rolling-shutter camera model, the maximum symbol rate that such OCC systems can support is experimentally demonstrated, and the impact of imperfect time synchronization between the VLC transmitter and the rolling-shutter OCC receiver is characterized in the form of Inter-Symbol Interference (ISI). The equivalent three-tap channel model that results from this process is experimentally validated and the generated ISI is compensated with the use of linear equalization in reception. Simulation and experimental results show a strong correlation between them, demonstrating that the proposed approach can be used to make the OCC system work at the Nyquist sampling rate, which is equivalent to the pixel row sweep rate of the rolling-shutter camera used in reception.
ADARES: Adaptive Resource Management for Virtual Machines
Dec 06, 2018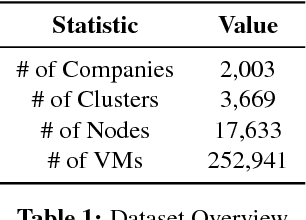
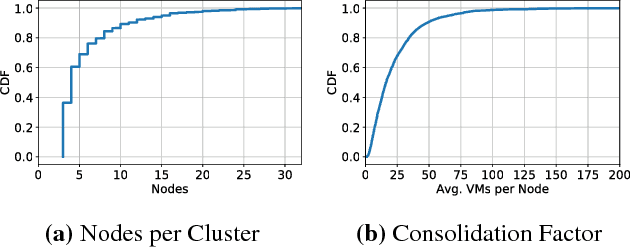
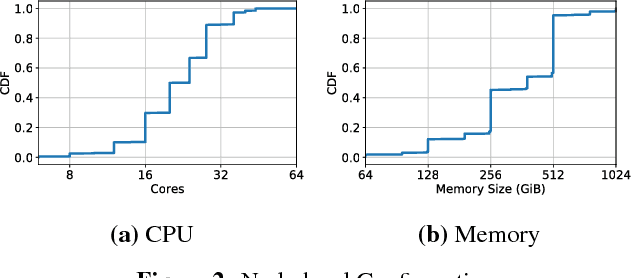
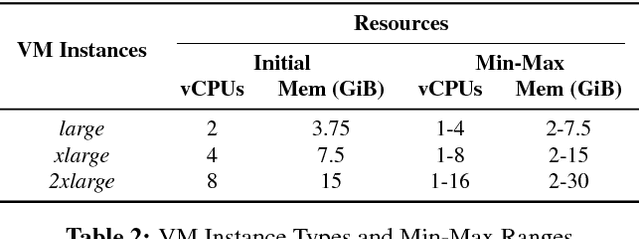
Virtual execution environments allow for consolidation of multiple applications onto the same physical server, thereby enabling more efficient use of server resources. However, users often statically configure the resources of virtual machines through guesswork, resulting in either insufficient resource allocations that hinder VM performance, or excessive allocations that waste precious data center resources. In this paper, we first characterize real-world resource allocation and utilization of VMs through the analysis of an extensive dataset, consisting of more than 250k VMs from over 3.6k private enterprise clusters. Our large-scale analysis confirms that VMs are often misconfigured, either overprovisioned or underprovisioned, and that this problem is pervasive across a wide range of private clusters. We then propose ADARES, an adaptive system that dynamically adjusts VM resources using machine learning techniques. In particular, ADARES leverages the contextual bandits framework to effectively manage the adaptations. Our system exploits easily collectible data, at the cluster, node, and VM levels, to make more sensible allocation decisions, and uses transfer learning to safely explore the configurations space and speed up training. Our empirical evaluation shows that ADARES can significantly improve system utilization without sacrificing performance. For instance, when compared to threshold and prediction-based baselines, it achieves more predictable VM-level performance and also reduces the amount of virtual CPUs and memory provisioned by up to 35% and 60% respectively for synthetic workloads on real clusters.