 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings
Mar 12, 2019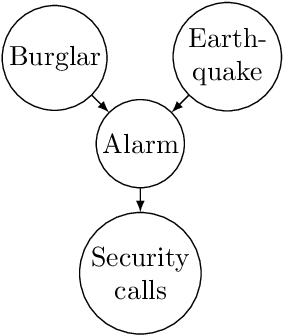

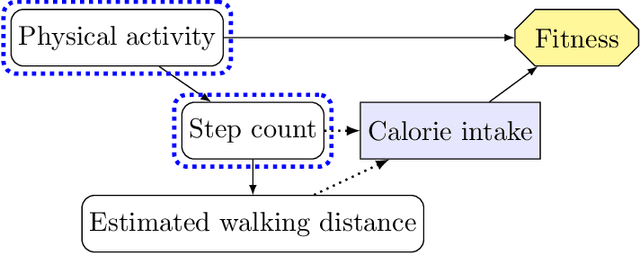
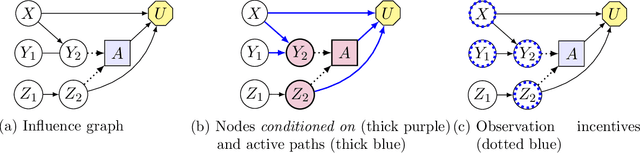
Agents are systems that optimize an objective function in an environment. Together, the goal and the environment induce secondary objectives, incentives. Modeling the agent-environment interaction in graphical models called influence diagrams, we can answer two fundamental questions about an agent's incentives directly from the graph: (1) which nodes is the agent incentivized to observe, and (2) which nodes is the agent incentivized to influence? The answers tell us which information and influence points need extra protection. For example, we may want a classifier for job applications to not use the ethnicity of the candidate, and a reinforcement learning agent not to take direct control of its reward mechanism. Different algorithms and training paradigms can lead to different influence diagrams, so our method can be used to identify algorithms with problematic incentives and help in designing algorithms with better incentives.
Intrinsic Social Motivation via Causal Influence in Multi-Agent RL
Oct 19, 2018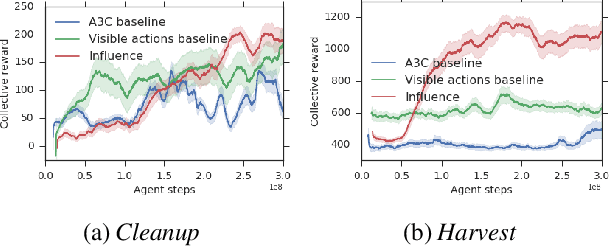
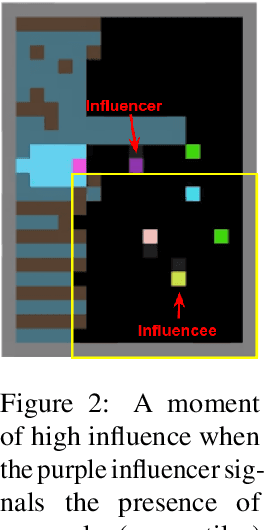
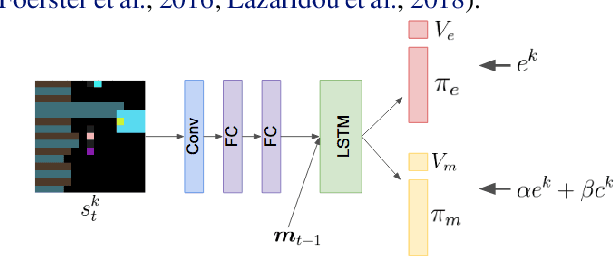
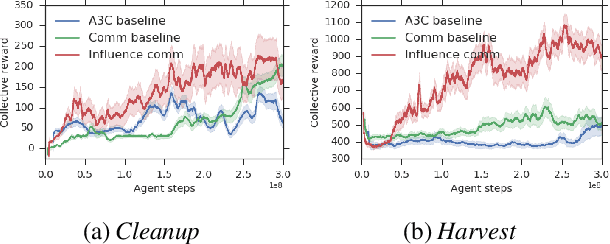
We derive a new intrinsic social motivation for multi-agent reinforcement learning (MARL), in which agents are rewarded for having causal influence over another agent's actions. Causal influence is assessed using counterfactual reasoning. The reward does not depend on observing another agent's reward function, and is thus a more realistic approach to MARL than taken in previous work. We show that the causal influence reward is related to maximizing the mutual information between agents' actions. We test the approach in challenging social dilemma environments, where it consistently leads to enhanced cooperation between agents and higher collective reward. Moreover, we find that rewarding influence can lead agents to develop emergent communication protocols. We therefore employ influence to train agents to use an explicit communication channel, and find that it leads to more effective communication and higher collective reward. Finally, we show that influence can be computed by equipping each agent with an internal model that predicts the actions of other agents. This allows the social influence reward to be computed without the use of a centralised controller, and as such represents a significantly more general and scalable inductive bias for MARL with independent agents.
Modeling Friends and Foes
Jun 30, 2018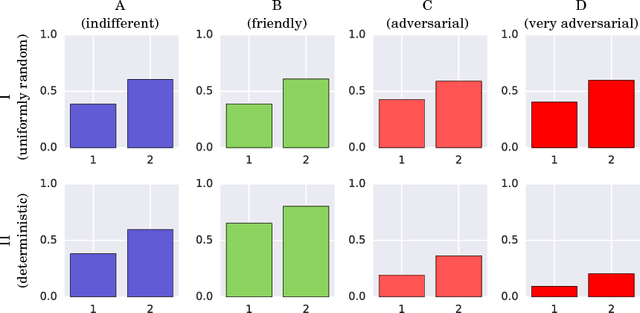
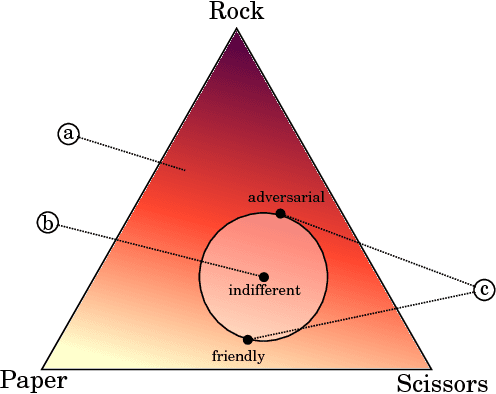
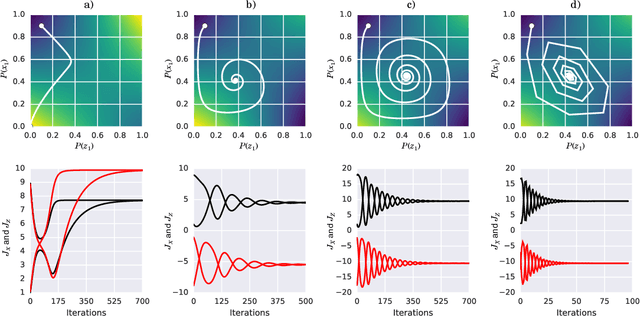
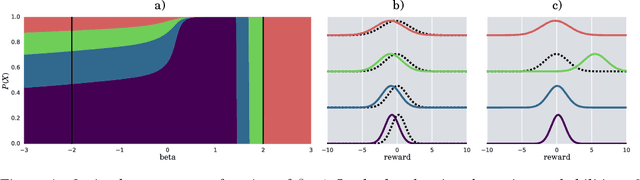
How can one detect friendly and adversarial behavior from raw data? Detecting whether an environment is a friend, a foe, or anything in between, remains a poorly understood yet desirable ability for safe and robust agents. This paper proposes a definition of these environmental "attitudes" based on an characterization of the environment's ability to react to the agent's private strategy. We define an objective function for a one-shot game that allows deriving the environment's probability distribution under friendly and adversarial assumptions alongside the agent's optimal strategy. Furthermore, we present an algorithm to compute these equilibrium strategies, and show experimentally that both friendly and adversarial environments possess non-trivial optimal strategies.
AI Safety Gridworlds
Nov 28, 2017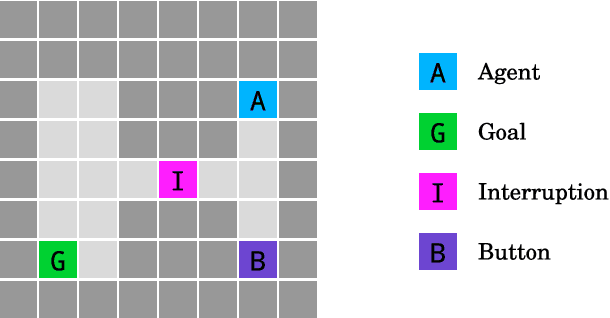
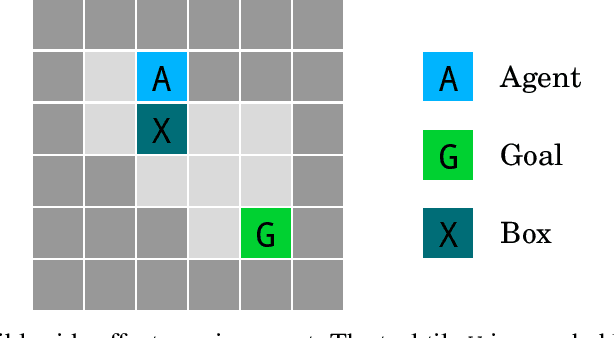
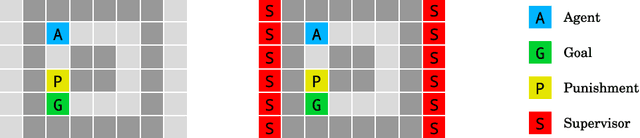
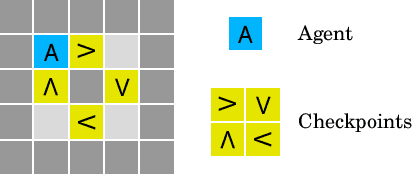
We present a suite of reinforcement learning environments illustrating various safety properties of intelligent agents. These problems include safe interruptibility, avoiding side effects, absent supervisor, reward gaming, safe exploration, as well as robustness to self-modification, distributional shift, and adversaries. To measure compliance with the intended safe behavior, we equip each environment with a performance function that is hidden from the agent. This allows us to categorize AI safety problems into robustness and specification problems, depending on whether the performance function corresponds to the observed reward function. We evaluate A2C and Rainbow, two recent deep reinforcement learning agents, on our environments and show that they are not able to solve them satisfactorily.
Human Decision-Making under Limited Time
Oct 06, 2016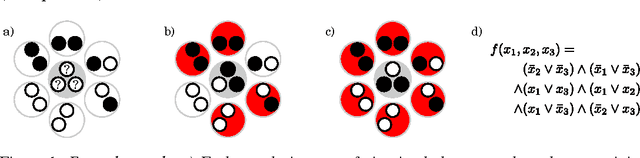
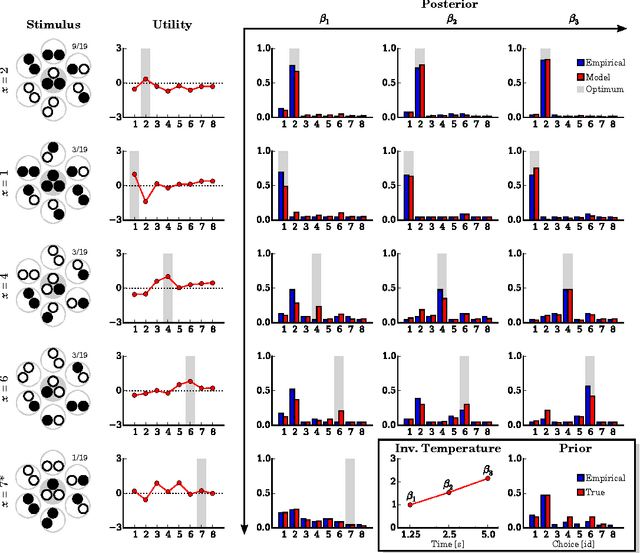
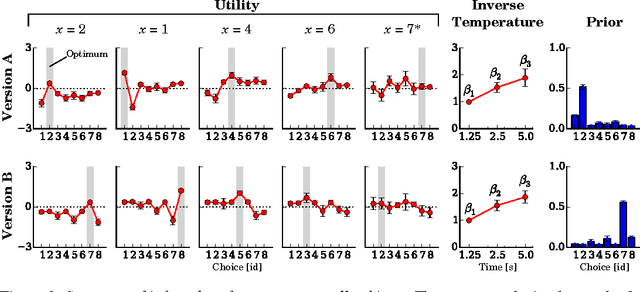
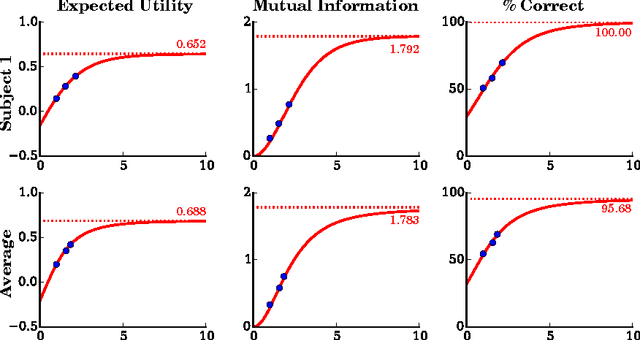
Subjective expected utility theory assumes that decision-makers possess unlimited computational resources to reason about their choices; however, virtually all decisions in everyday life are made under resource constraints - i.e. decision-makers are bounded in their rationality. Here we experimentally tested the predictions made by a formalization of bounded rationality based on ideas from statistical mechanics and information-theory. We systematically tested human subjects in their ability to solve combinatorial puzzles under different time limitations. We found that our bounded-rational model accounts well for the data. The decomposition of the fitted model parameter into the subjects' expected utility function and resource parameter provide interesting insight into the subjects' information capacity limits. Our results confirm that humans gradually fall back on their learned prior choice patterns when confronted with increasing resource limitations.
Memory shapes time perception and intertemporal choices
May 29, 2016

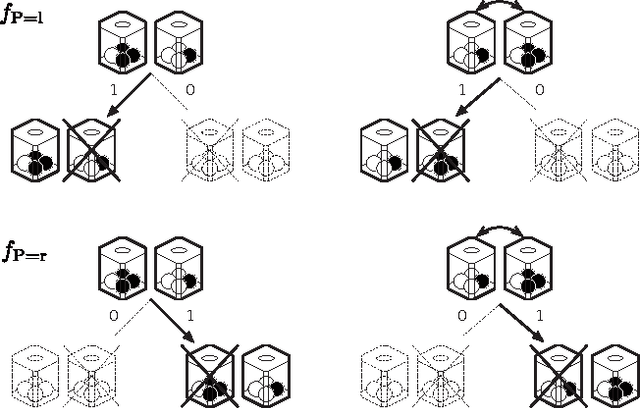
There is a consensus that human and non-human subjects experience temporal distortions in many stages of their perceptual and decision-making systems. Similarly, intertemporal choice research has shown that decision-makers undervalue future outcomes relative to immediate ones. Here we combine techniques from information theory and artificial intelligence to show how both temporal distortions and intertemporal choice preferences can be explained as a consequence of the coding efficiency of sensorimotor representation. In particular, the model implies that interactions that constrain future behavior are perceived as being both longer in duration and more valuable. Furthermore, using simulations of artificial agents, we investigate how memory constraints enforce a renormalization of the perceived timescales. Our results show that qualitatively different discount functions, such as exponential and hyperbolic discounting, arise as a consequence of an agent's probabilistic model of the world.
Information-Theoretic Bounded Rationality
Dec 21, 2015Bounded rationality, that is, decision-making and planning under resource limitations, is widely regarded as an important open problem in artificial intelligence, reinforcement learning, computational neuroscience and economics. This paper offers a consolidated presentation of a theory of bounded rationality based on information-theoretic ideas. We provide a conceptual justification for using the free energy functional as the objective function for characterizing bounded-rational decisions. This functional possesses three crucial properties: it controls the size of the solution space; it has Monte Carlo planners that are exact, yet bypass the need for exhaustive search; and it captures model uncertainty arising from lack of evidence or from interacting with other agents having unknown intentions. We discuss the single-step decision-making case, and show how to extend it to sequential decisions using equivalence transformations. This extension yields a very general class of decision problems that encompass classical decision rules (e.g. EXPECTIMAX and MINIMAX) as limit cases, as well as trust- and risk-sensitive planning.
Belief Flows of Robust Online Learning
May 26, 2015



This paper introduces a new probabilistic model for online learning which dynamically incorporates information from stochastic gradients of an arbitrary loss function. Similar to probabilistic filtering, the model maintains a Gaussian belief over the optimal weight parameters. Unlike traditional Bayesian updates, the model incorporates a small number of gradient evaluations at locations chosen using Thompson sampling, making it computationally tractable. The belief is then transformed via a linear flow field which optimally updates the belief distribution using rules derived from information theoretic principles. Several versions of the algorithm are shown using different constraints on the flow field and compared with conventional online learning algorithms. Results are given for several classification tasks including logistic regression and multilayer neural networks.
Subjectivity, Bayesianism, and Causality
Apr 24, 2015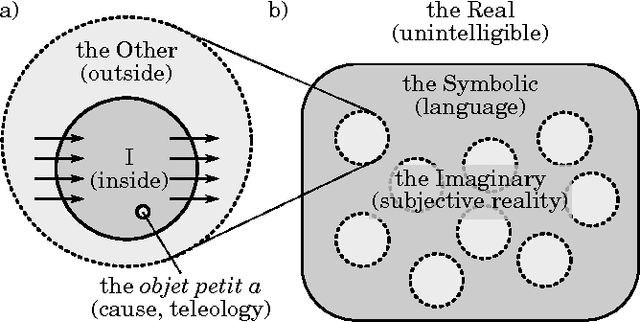
Bayesian probability theory is one of the most successful frameworks to model reasoning under uncertainty. Its defining property is the interpretation of probabilities as degrees of belief in propositions about the state of the world relative to an inquiring subject. This essay examines the notion of subjectivity by drawing parallels between Lacanian theory and Bayesian probability theory, and concludes that the latter must be enriched with causal interventions to model agency. The central contribution of this work is an abstract model of the subject that accommodates causal interventions in a measure-theoretic formalisation. This formalisation is obtained through a game-theoretic Ansatz based on modelling the inside and outside of the subject as an extensive-form game with imperfect information between two players. Finally, I illustrate the expressiveness of this model with an example of causal induction.
An Adversarial Interpretation of Information-Theoretic Bounded Rationality
Apr 22, 2014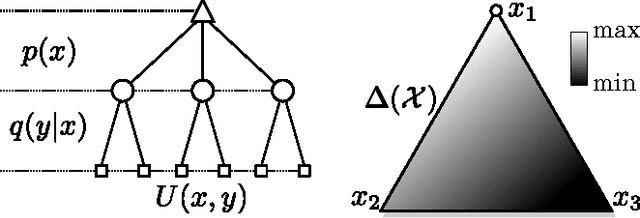
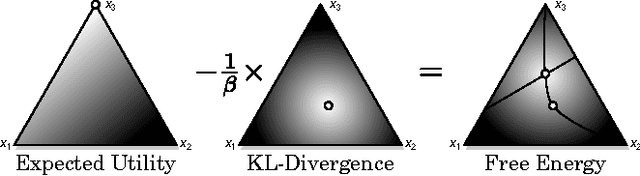
Recently, there has been a growing interest in modeling planning with information constraints. Accordingly, an agent maximizes a regularized expected utility known as the free energy, where the regularizer is given by the information divergence from a prior to a posterior policy. While this approach can be justified in various ways, including from statistical mechanics and information theory, it is still unclear how it relates to decision-making against adversarial environments. This connection has previously been suggested in work relating the free energy to risk-sensitive control and to extensive form games. Here, we show that a single-agent free energy optimization is equivalent to a game between the agent and an imaginary adversary. The adversary can, by paying an exponential penalty, generate costs that diminish the decision maker's payoffs. It turns out that the optimal strategy of the adversary consists in choosing costs so as to render the decision maker indifferent among its choices, which is a definining property of a Nash equilibrium, thus tightening the connection between free energy optimization and game theory.