 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Classification of Variable Stars
Dec 04, 2019
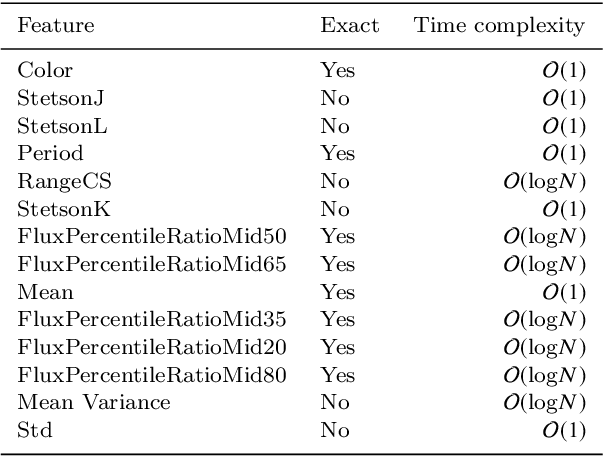
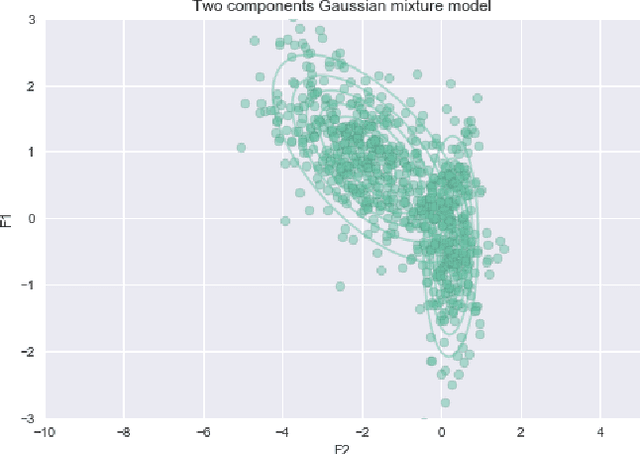
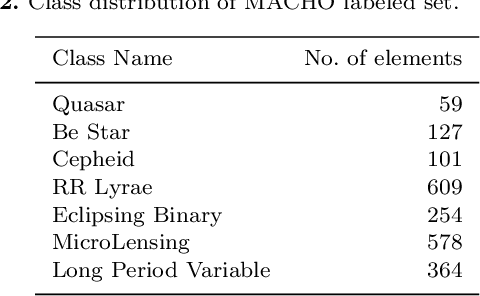
In the last years, automatic classification of variable stars has received substantial attention. Using machine learning techniques for this task has proven to be quite useful. Typically, machine learning classifiers used for this task require to have a fixed training set, and the training process is performed offline. Upcoming surveys such as the Large Synoptic Survey Telescope (LSST) will generate new observations daily, where an automatic classification system able to create alerts online will be mandatory. A system with those characteristics must be able to update itself incrementally. Unfortunately, after training, most machine learning classifiers do not support the inclusion of new observations in light curves, they need to re-train from scratch. Naively re-training from scratch is not an option in streaming settings, mainly because of the expensive pre-processing routines required to obtain a vector representation of light curves (features) each time we include new observations. In this work, we propose a streaming probabilistic classification model; it uses a set of newly designed features that work incrementally. With this model, we can have a machine learning classifier that updates itself in real time with new observations. To test our approach, we simulate a streaming scenario with light curves from CoRot, OGLE and MACHO catalogs. Results show that our model achieves high classification performance, staying an order of magnitude faster than traditional classification approaches.
An Information Theory Approach on Deciding Spectroscopic Follow Ups
Nov 06, 2019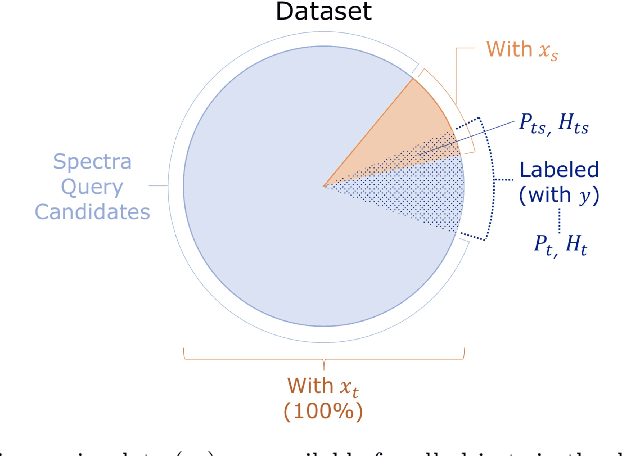
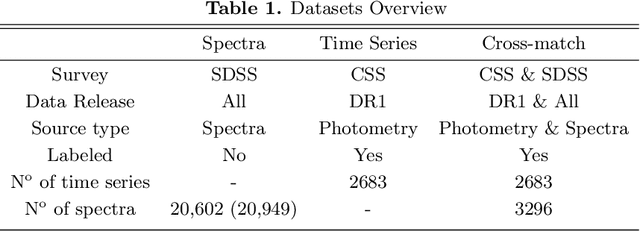
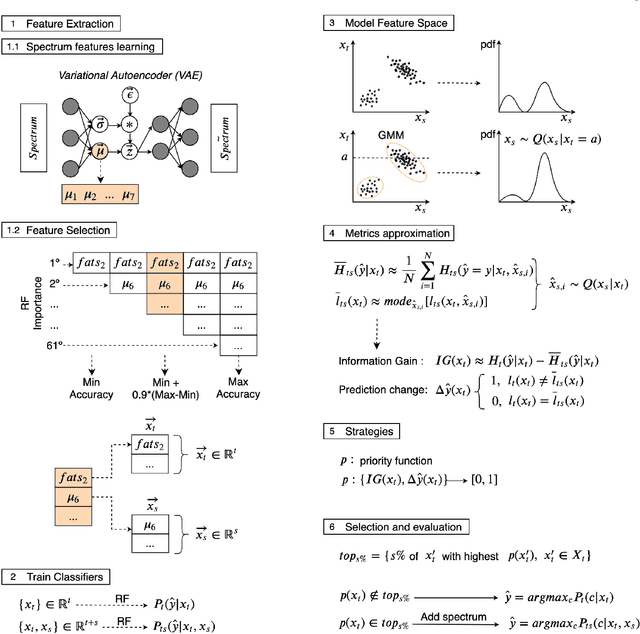
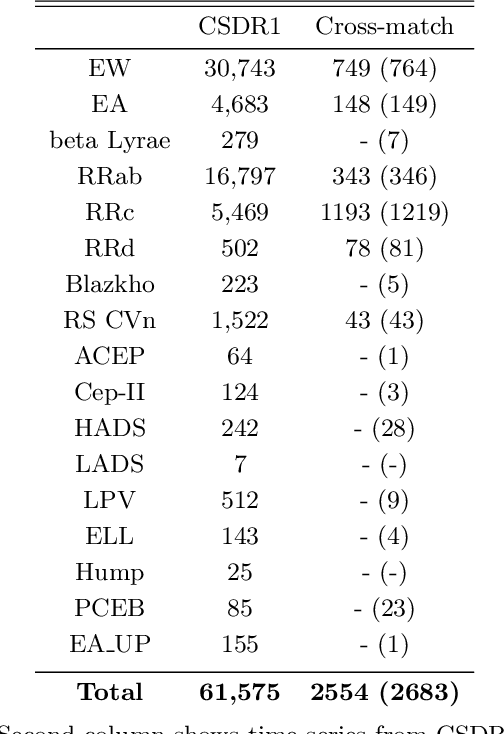
Classification and characterization of variable phenomena and transient phenomena are critical for astrophysics and cosmology. These objects are commonly studied using photometric time series or spectroscopic data. Given that many ongoing and future surveys are in time-domain and given that adding spectra provide further insights but requires more observational resources, it would be valuable to know which objects should we prioritize to have spectrum in addition to time series. We propose a methodology in a probabilistic setting that determines a-priory which objects are worth taking spectrum to obtain better insights, where we focus 'insight' as the type of the object (classification). Objects for which we query its spectrum are reclassified using their full spectrum information. We first train two classifiers, one that uses photometric data and another that uses photometric and spectroscopic data together. Then for each photometric object we estimate the probability of each possible spectrum outcome. We combine these models in various probabilistic frameworks (strategies) which are used to guide the selection of follow up observations. The best strategy depends on the intended use, whether it is getting more confidence or accuracy. For a given number of candidate objects (127, equal to 5% of the dataset) for taking spectra, we improve 37% class prediction accuracy as opposed to 20% of a non-naive (non-random) best base-line strategy. Our approach provides a general framework for follow-up strategies and can be extended beyond classification and to include other forms of follow-ups beyond spectroscopy.
Adversarial Variational Domain Adaptation
Sep 26, 2019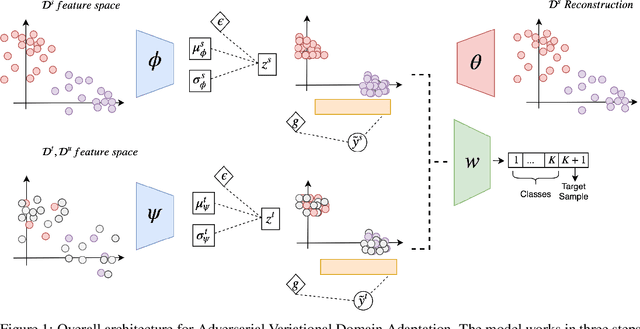
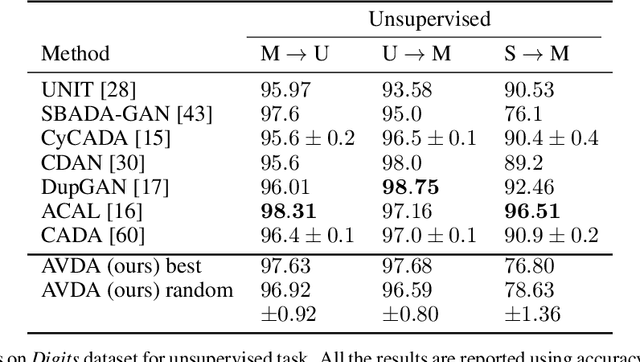
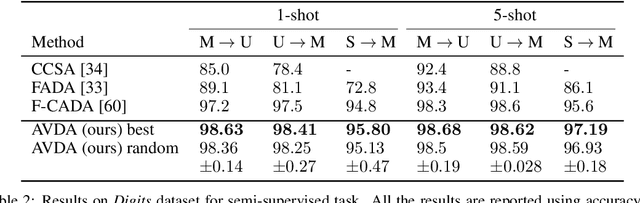
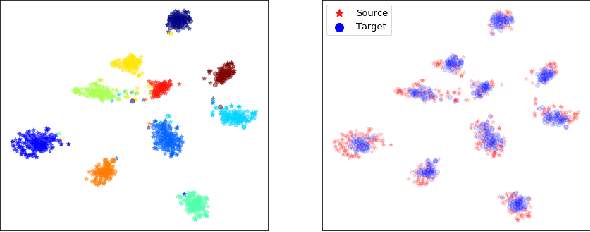
In this work we address the problem of transferring knowledge obtained from a vast annotated source domain to a low labeled or unlabeled target domain. We propose Adversarial Variational Domain Adaptation (AVDA), a semi-supervised domain adaptation method based on deep variational embedded representations. We use approximate inference and adversarial methods to map samples from source and target domains into an aligned semantic embedding. We show that on a semi-supervised few-shot scenario, our approach can be used to obtain a significant speed-up in performance when using an increasing number of labels on the target domain.
Improving Image Classification Robustness through Selective CNN-Filters Fine-Tuning
Apr 08, 2019

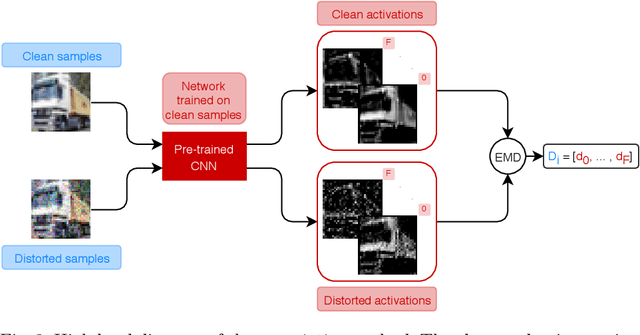
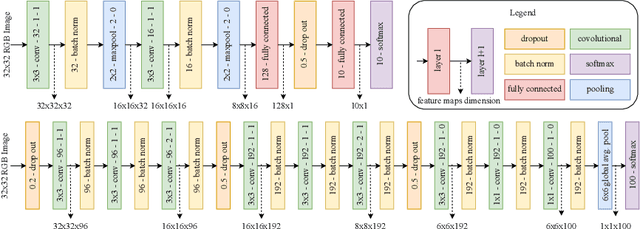
Image quality plays a big role in CNN-based image classification performance. Fine-tuning the network with distorted samples may be too costly for large networks. To solve this issue, we propose a transfer learning approach optimized to keep into account that in each layer of a CNN some filters are more susceptible to image distortion than others. Our method identifies the most susceptible filters and applies retraining only to the filters that show the highest activation maps distance between clean and distorted images. Filters are ranked using the Borda count election method and then only the most affected filters are fine-tuned. This significantly reduces the number of parameters to retrain. We evaluate this approach on the CIFAR-10 and CIFAR-100 datasets, testing it on two different models and two different types of distortion. Results show that the proposed transfer learning technique recovers most of the lost performance due to input data distortion, at a considerably faster pace with respect to existing methods, thanks to the reduced number of parameters to fine-tune. When few noisy samples are provided for training, our filter-level fine tuning performs particularly well, also outperforming state of the art layer-level transfer learning approaches.
Efficient Optimization of Echo State Networks for Time Series Datasets
Mar 12, 2019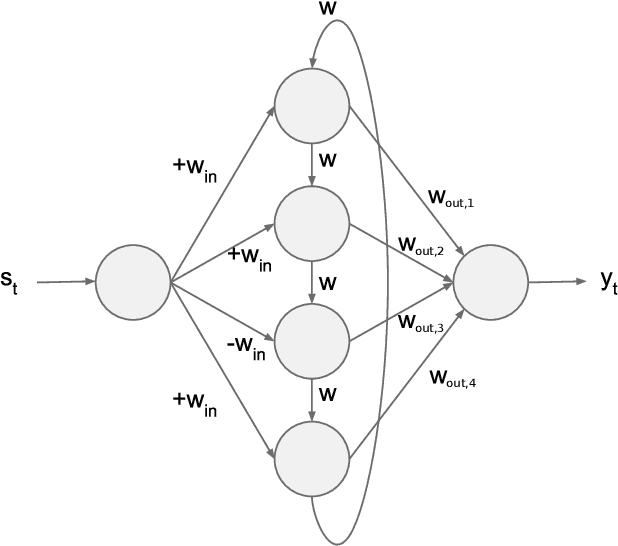
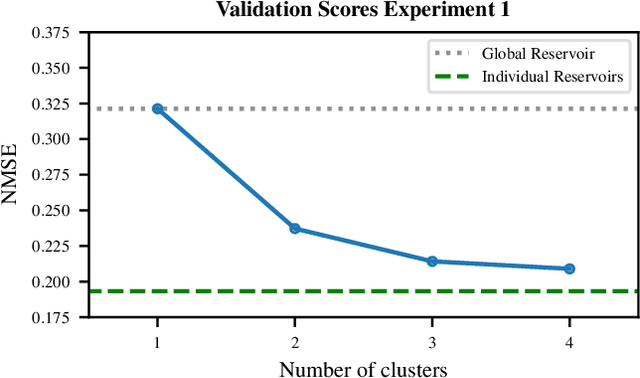
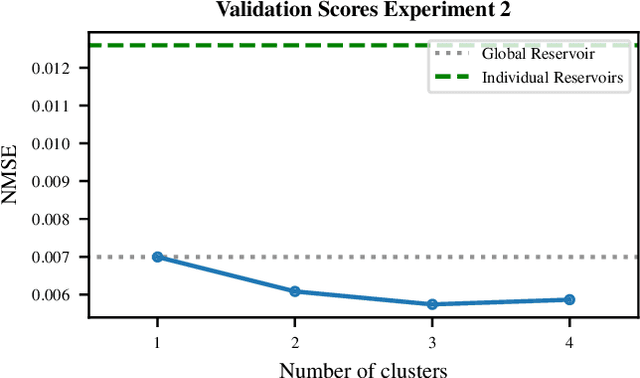
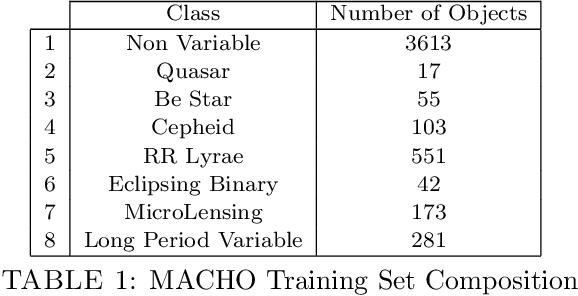
Echo State Networks (ESNs) are recurrent neural networks that only train their output layer, thereby precluding the need to backpropagate gradients through time, which leads to significant computational gains. Nevertheless, a common issue in ESNs is determining its hyperparameters, which are crucial in instantiating a well performing reservoir, but are often set manually or using heuristics. In this work we optimize the ESN hyperparameters using Bayesian optimization which, given a limited budget of function evaluations, outperforms a grid search strategy. In the context of large volumes of time series data, such as light curves in the field of astronomy, we can further reduce the optimization cost of ESNs. In particular, we wish to avoid tuning hyperparameters per individual time series as this is costly; instead, we want to find ESNs with hyperparameters that perform well not just on individual time series but rather on groups of similar time series without sacrificing predictive performance significantly. This naturally leads to a notion of clusters, where each cluster is represented by an ESN tuned to model a group of time series of similar temporal behavior. We demonstrate this approach both on synthetic datasets and real world light curves from the MACHO survey. We show that our approach results in a significant reduction in the number of ESN models required to model a whole dataset, while retaining predictive performance for the series in each cluster.
An Algorithm for the Visualization of Relevant Patterns in Astronomical Light Curves
Mar 08, 2019

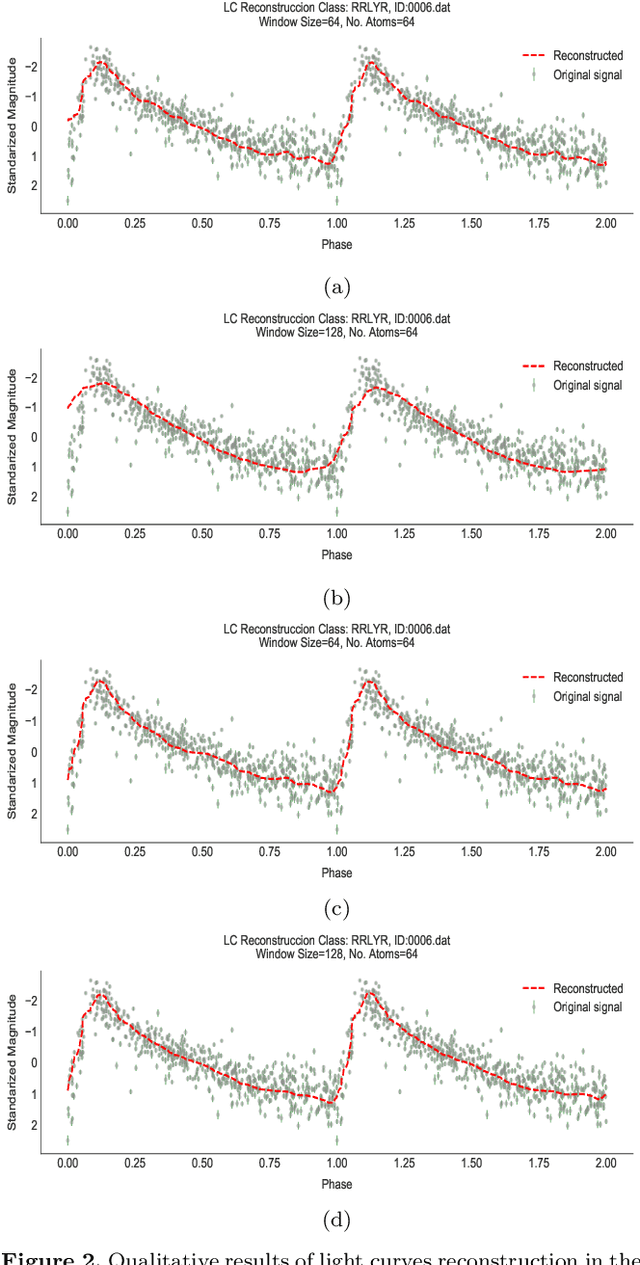
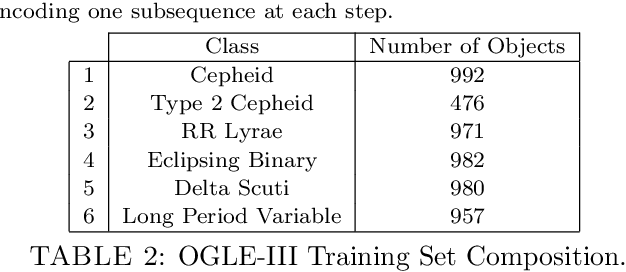
Within the last years, the classification of variable stars with Machine Learning has become a mainstream area of research. Recently, visualization of time series is attracting more attention in data science as a tool to visually help scientists to recognize significant patterns in complex dynamics. Within the Machine Learning literature, dictionary-based methods have been widely used to encode relevant parts of image data. These methods intrinsically assign a degree of importance to patches in pictures, according to their contribution in the image reconstruction. Inspired by dictionary-based techniques, we present an approach that naturally provides the visualization of salient parts in astronomical light curves, making the analogy between image patches and relevant pieces in time series. Our approach encodes the most meaningful patterns such that we can approximately reconstruct light curves by just using the encoded information. We test our method in light curves from the OGLE-III and StarLight databases. Our results show that the proposed model delivers an automatic and intuitive visualization of relevant light curve parts, such as local peaks and drops in magnitude.
* Accepted 2019 January 8. Received 2019 January 8; in original form 2018 January 29. 7 pages, 6 figures
A Full Probabilistic Model for Yes/No Type Crowdsourcing in Multi-Class Classification
Jan 02, 2019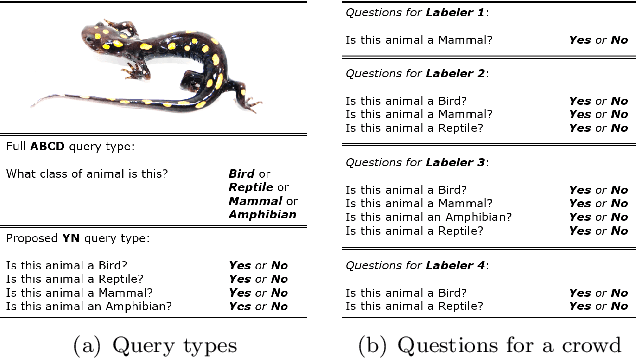
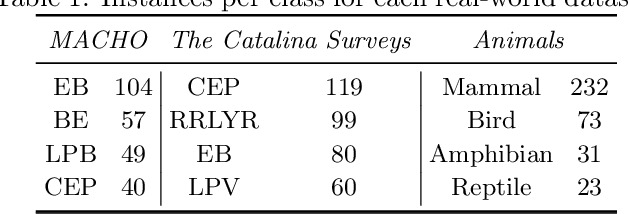
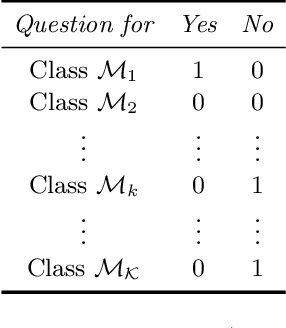

Crowdsourcing has become widely used in supervised scenarios where training sets are scarce and hard to obtain. Most crowdsourcing models in literature assume labelers can provide answers for full questions. In classification contexts, full questions mean that a labeler is asked to discern among all the possible classes. Unfortunately, that discernment is not always easy in realistic scenarios. Labelers may not be experts in differentiating all the classes. In this work, we provide a full probabilistic model for a shorter type of queries. Our shorter queries just required a 'yes' or 'no' response. Our model estimates a joint posterior distribution of matrices related to the labelers confusions and the posterior probability of the class of every object. We develop an approximate inference approach using Monte Carlo Sampling and Black Box Variational Inference, where we provide the derivation of the necessary gradients. We build two realistic crowdsourcing scenarios to test our model. The first scenario queries for irregular astronomical time-series. The second scenario relies on animal's image classification. Results show that we can achieve comparable results with full query crowdsourcing. Furthermore, we show that modeling the labelers failures plays an important role in estimating the true classes. Finally, we provide the community with two real datasets obtained from our crowdsourcing experiments. All our code is publicly available (Available at: revealed as soon as the paper gets published.)
Deep Variational Transfer: Transfer Learning through Semi-supervised Deep Generative Models
Dec 07, 2018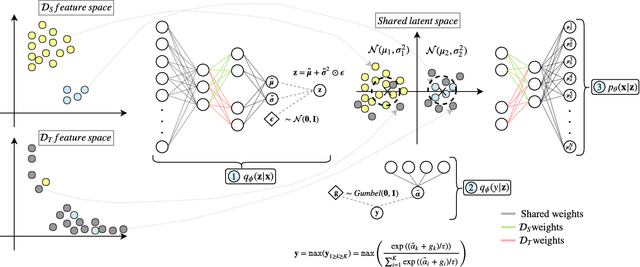
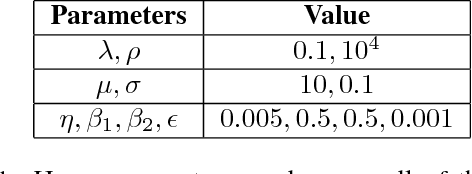
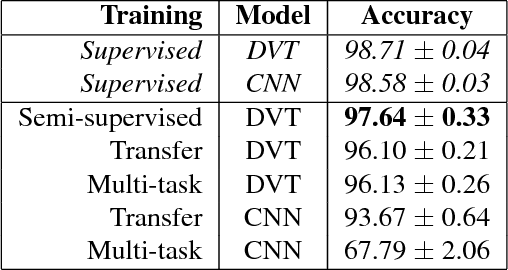
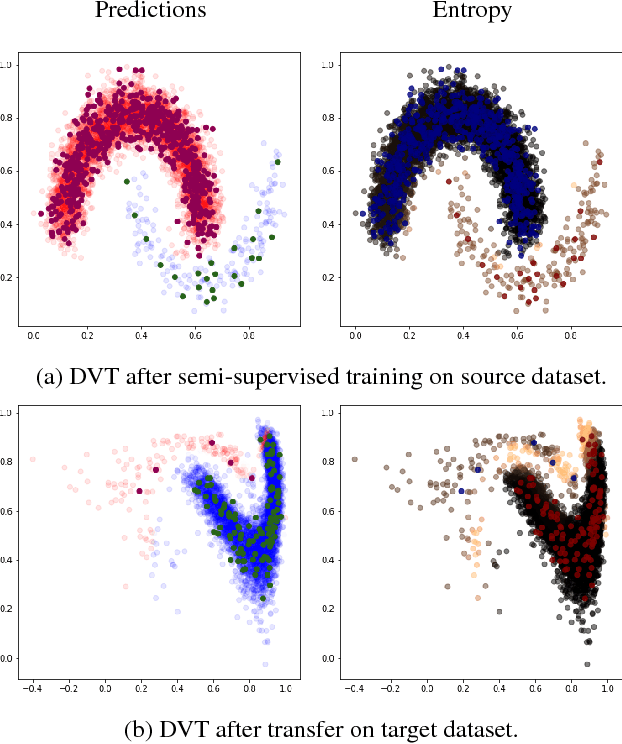
In real-world applications, it is often expensive and time-consuming to obtain labeled examples. In such cases, knowledge transfer from related domains, where labels are abundant, could greatly reduce the need for extensive labeling efforts. In this scenario, transfer learning comes in hand. In this paper, we propose Deep Variational Transfer (DVT), a variational autoencoder that transfers knowledge across domains using a shared latent Gaussian mixture model. Thanks to the combination of a semi-supervised ELBO and parameters sharing across domains, we are able to simultaneously: (i) align all supervised examples of the same class into the same latent Gaussian Mixture component, independently from their domain; (ii) predict the class of unsupervised examples from different domains and use them to better model the occurring shifts. We perform tests on MNIST and USPS digits datasets, showing DVT's ability to perform transfer learning across heterogeneous datasets. Additionally, we present DVT's top classification performances on the MNIST semi-supervised learning challenge. We further validate DVT on a astronomical datasets. DVT achieves states-of-the-art classification performances, transferring knowledge across real stars surveys datasets, EROS, MACHO and HiTS, . In the worst performance, we double the achieved F1-score for rare classes. These experiments show DVT's ability to tackle all major challenges posed by transfer learning: different covariate distributions, different and highly imbalanced class distributions and different feature spaces.
T-CGAN: Conditional Generative Adversarial Network for Data Augmentation in Noisy Time Series with Irregular Sampling
Nov 20, 2018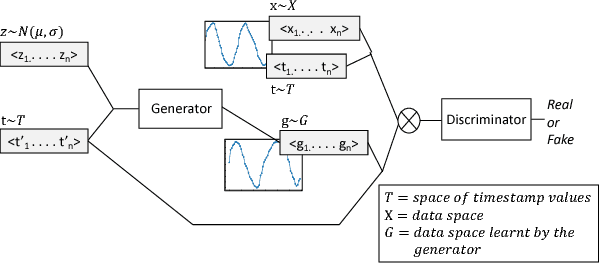
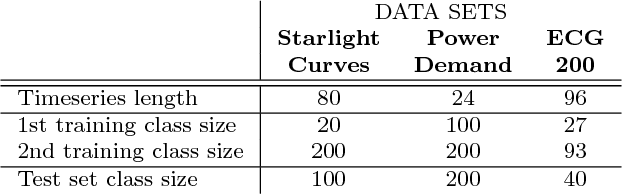
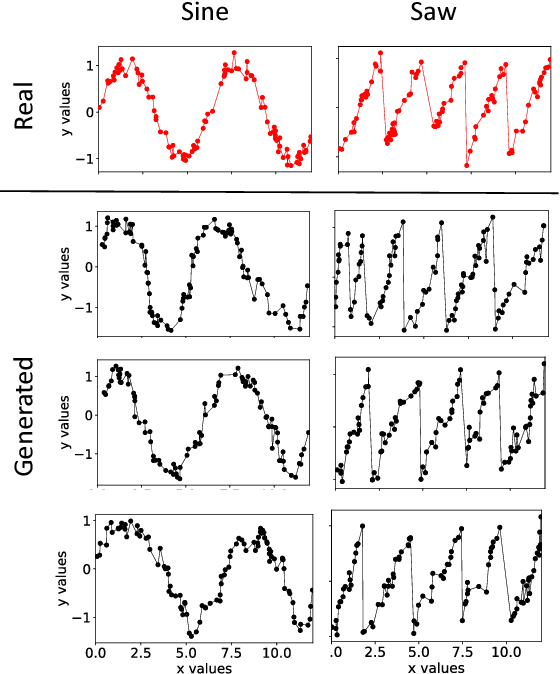
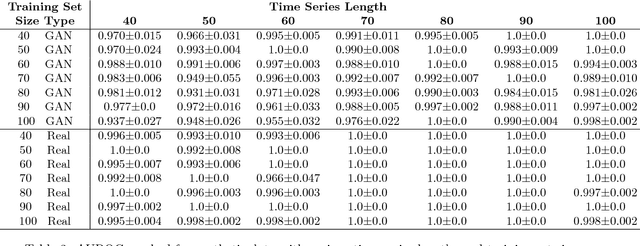
In this paper we propose a data augmentation method for time series with irregular sampling, Time-Conditional Generative Adversarial Network (T-CGAN). Our approach is based on Conditional Generative Adversarial Networks (CGAN), where the generative step is implemented by a deconvolutional NN and the discriminative step by a convolutional NN. Both the generator and the discriminator are conditioned on the sampling timestamps, to learn the hidden relationship between data and timestamps, and consequently to generate new time series. We evaluate our model with synthetic and real-world datasets. For the synthetic data, we compare the performance of a classifier trained with T-CGAN-generated data, against the performance of the same classifier trained on the original data. Results show that classifiers trained on T-CGAN-generated data perform the same as classifiers trained on real data, even with very short time series and small training sets. For the real world datasets, we compare our method with other techniques of data augmentation for time series, such as time slicing and time warping, over a classification problem with unbalanced datasets. Results show that our method always outperforms the other approaches, both in case of regularly sampled and irregularly sampled time series. We achieve particularly good performance in case with a small training set and short, noisy, irregularly-sampled time series.
Clustering Based Feature Learning on Variable Stars
Feb 29, 2016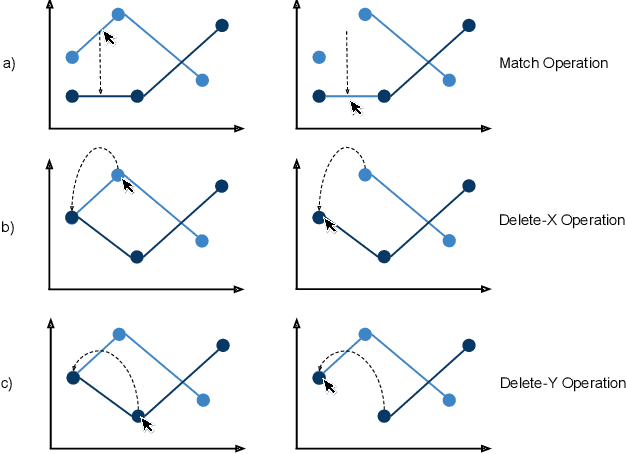
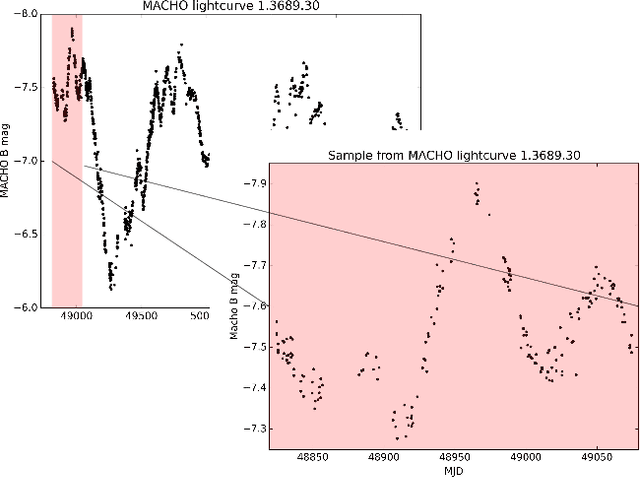
The success of automatic classification of variable stars strongly depends on the lightcurve representation. Usually, lightcurves are represented as a vector of many statistical descriptors designed by astronomers called features. These descriptors commonly demand significant computational power to calculate, require substantial research effort to develop and do not guarantee good performance on the final classification task. Today, lightcurve representation is not entirely automatic; algorithms that extract lightcurve features are designed by humans and must be manually tuned up for every survey. The vast amounts of data that will be generated in future surveys like LSST mean astronomers must develop analysis pipelines that are both scalable and automated. Recently, substantial efforts have been made in the machine learning community to develop methods that prescind from expert-designed and manually tuned features for features that are automatically learned from data. In this work we present what is, to our knowledge, the first unsupervised feature learning algorithm designed for variable stars. Our method first extracts a large number of lightcurve subsequences from a given set of photometric data, which are then clustered to find common local patterns in the time series. Representatives of these patterns, called exemplars, are then used to transform lightcurves of a labeled set into a new representation that can then be used to train an automatic classifier. The proposed algorithm learns the features from both labeled and unlabeled lightcurves, overcoming the bias generated when the learning process is done only with labeled data. We test our method on MACHO and OGLE datasets; the results show that the classification performance we achieve is as good and in some cases better than the performance achieved using traditional features, while the computational cost is significantly lower.