 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Patch-Aware Sparse Prompting with Decoupled Training for Continual Learning on the Edge
Apr 08, 2026Continual learning (CL) on edge devices requires not only high accuracy but also training-time efficiency to support on-device adaptation under strict memory and computational constraints. While prompt-based continual learning (PCL) is parameter-efficient and achieves competitive accuracy, prior work has focused mainly on accuracy or inference-time performance, often overlooking the memory and computational costs of on-device training. In this paper, we propose CPS-Prompt, a critical patch-aware sparse prompting framework that explicitly targets training-time memory usage and computational cost by integrating critical patch sampling (CPS) for task-aware token reduction and decoupled prompt and classifier training (DPCT) to reduce backpropagation overhead. Experiments on three public benchmarks and real edge hardware show that CPS-Prompt improves peak memory, training time, and energy efficiency by about 1.6x over the balanced CODA-Prompt baseline, while maintaining accuracy within 2% of the state-of-the-art C-Prompt on average and remaining competitive with CODA-Prompt in accuracy. The code is available at https://github.com/laymond1/cps-prompt.
Continual Multimodal Egocentric Activity Recognition via Modality-Aware Novel Detection
Mar 17, 2026Multimodal egocentric activity recognition integrates visual and inertial cues for robust first-person behavior understanding. However, deploying such systems in open-world environments requires detecting novel activities while continuously learning from non-stationary streams. Existing methods rely on the main logits for novelty scoring, without fully exploiting the complementary evidence available from individual modalities. Because these logits are often dominated by RGB, cues from other modalities, particularly IMU, remain underutilized, and this imbalance worsens over time under catastrophic forgetting. To address this, we propose MAND, a modality-aware framework for multimodal egocentric open-world continual learning. At inference, Modality-aware Adaptive Scoring (MoAS) estimates sample-wise modality reliability from energy scores and adaptively integrates modality logits to better exploit complementary modality cues for novelty detection. During training, Modality-wise Representation Stabilization Training (MoRST) preserves modality-specific discriminability across tasks via auxiliary heads and modality-wise logit distillation. Experiments on a public multimodal egocentric benchmark show that MAND improves novel activity detection AUC by up to 10\% and known-class classification accuracy by up to 2.8\% over state-of-the-art baselines.
On Evaluation of Unsupervised Feature Selection for Pattern Classification
Jan 13, 2026Unsupervised feature selection aims to identify a compact subset of features that captures the intrinsic structure of data without supervised label. Most existing studies evaluate the performance of methods using the single-label dataset that can be instantiated by selecting a label from multi-label data while maintaining the original features. Because the chosen label can vary arbitrarily depending on the experimental setting, the superiority among compared methods can be changed with regard to which label happens to be selected. Thus, evaluating unsupervised feature selection methods based solely on single-label accuracy is unreasonable for assessing their true discriminative ability. This study revisits this evaluation paradigm by adopting a multi-label classification framework. Experiments on 21 multi-label datasets using several representative methods demonstrate that performance rankings differ markedly from those reported under single-label settings, suggesting the possibility of multi-label evaluation settings for fair and reliable comparison of unsupervised feature selection methods.
A new validity measure for fuzzy c-means clustering
Jul 09, 2024A new cluster validity index is proposed for fuzzy clusters obtained from fuzzy c-means algorithm. The proposed validity index exploits inter-cluster proximity between fuzzy clusters. Inter-cluster proximity is used to measure the degree of overlap between clusters. A low proximity value refers to well-partitioned clusters. The best fuzzy c-partition is obtained by minimizing inter-cluster proximity with respect to c. Well-known data sets are tested to show the effectiveness and reliability of the proposed index.
Fuzzy color model and clustering algorithm for color clustering problem
Jul 09, 2024The research interest of this paper is focused on the efficient clustering task for an arbitrary color data. In order to tackle this problem, we have tried to model the inherent uncertainty and vagueness of color data using fuzzy color model. By taking fuzzy approach to color modeling, we could make a soft decision for the vague regions between neighboring colors. The proposed fuzzy color model defined a three dimensional fuzzy color ball and color membership computation method with two inter-color distances. With the fuzzy color model, we developed a new fuzzy clustering algorithm for an efficient partition of color data. Each fuzzy cluster set has a cluster prototype which is represented by fuzzy color centroid.
Supervised detection of anomalous light-curves in massive astronomical catalogs
May 27, 2015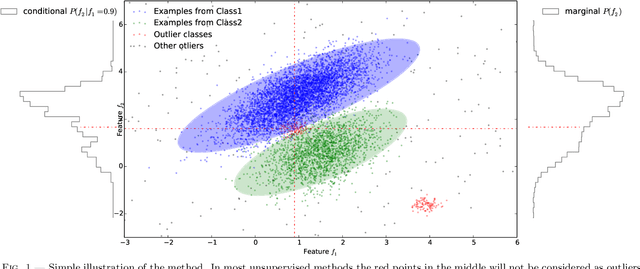
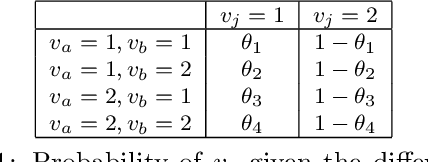
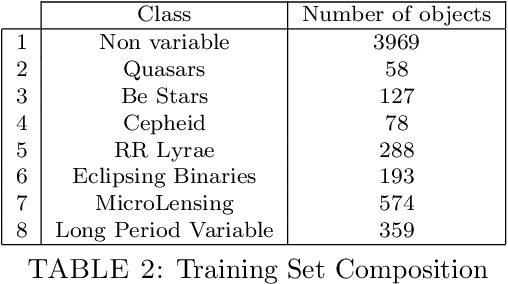
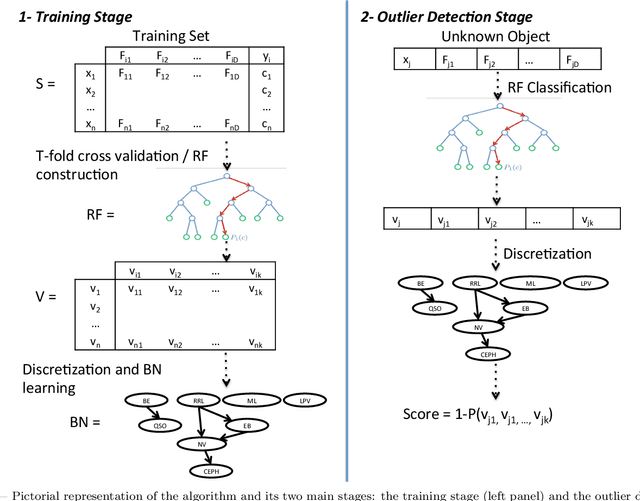
The development of synoptic sky surveys has led to a massive amount of data for which resources needed for analysis are beyond human capabilities. To process this information and to extract all possible knowledge, machine learning techniques become necessary. Here we present a new method to automatically discover unknown variable objects in large astronomical catalogs. With the aim of taking full advantage of all the information we have about known objects, our method is based on a supervised algorithm. In particular, we train a random forest classifier using known variability classes of objects and obtain votes for each of the objects in the training set. We then model this voting distribution with a Bayesian network and obtain the joint voting distribution among the training objects. Consequently, an unknown object is considered as an outlier insofar it has a low joint probability. Our method is suitable for exploring massive datasets given that the training process is performed offline. We tested our algorithm on 20 millions light-curves from the MACHO catalog and generated a list of anomalous candidates. We divided the candidates into two main classes of outliers: artifacts and intrinsic outliers. Artifacts were principally due to air mass variation, seasonal variation, bad calibration or instrumental errors and were consequently removed from our outlier list and added to the training set. After retraining, we selected about 4000 objects, which we passed to a post analysis stage by perfoming a cross-match with all publicly available catalogs. Within these candidates we identified certain known but rare objects such as eclipsing Cepheids, blue variables, cataclysmic variables and X-ray sources. For some outliers there were no additional information. Among them we identified three unknown variability types and few individual outliers that will be followed up for a deeper analysis.
* 16 pages, 18 figures, published in The Astrophysical Journal
An improved quasar detection method in EROS-2 and MACHO LMC datasets
Apr 01, 2013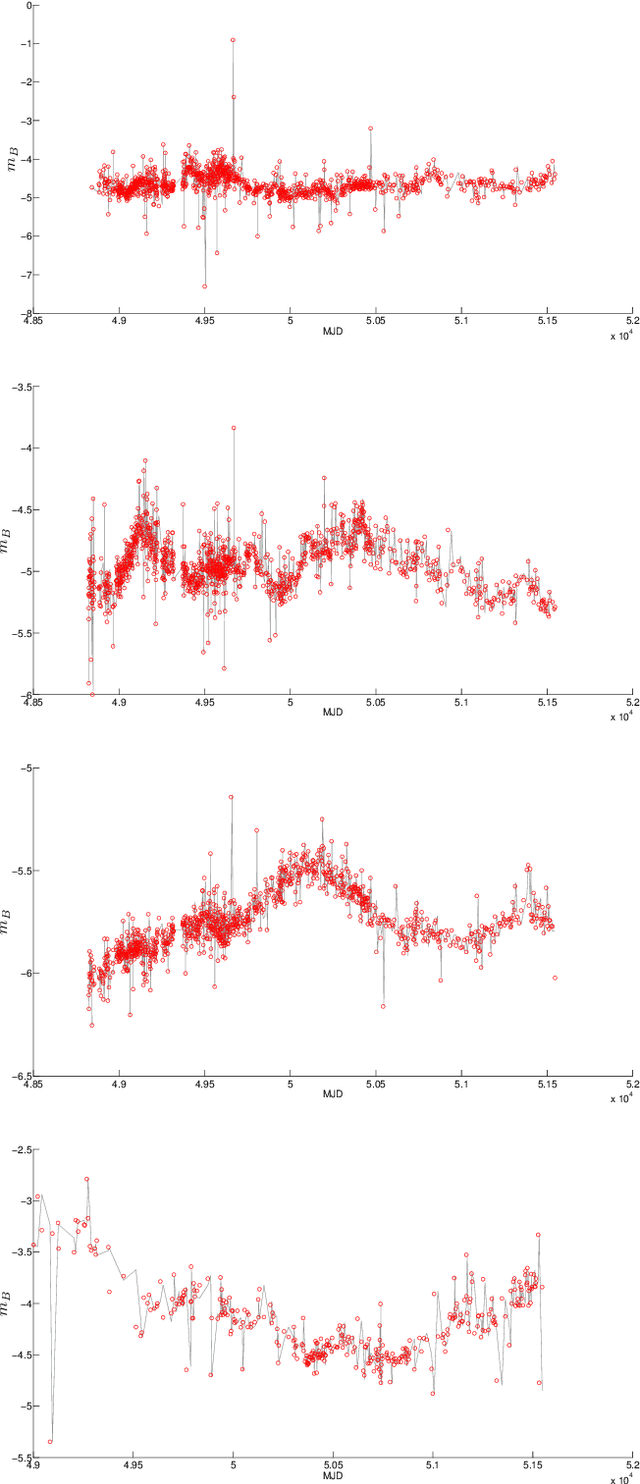

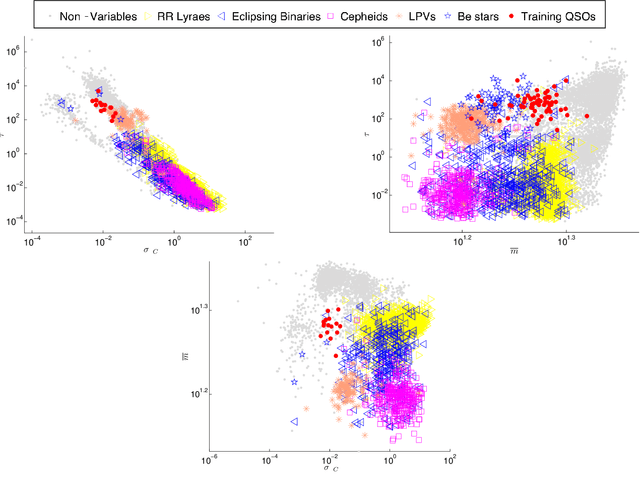

We present a new classification method for quasar identification in the EROS-2 and MACHO datasets based on a boosted version of Random Forest classifier. We use a set of variability features including parameters of a continuous auto regressive model. We prove that continuous auto regressive parameters are very important discriminators in the classification process. We create two training sets (one for EROS-2 and one for MACHO datasets) using known quasars found in the LMC. Our model's accuracy in both EROS-2 and MACHO training sets is about 90% precision and 86% recall, improving the state of the art models accuracy in quasar detection. We apply the model on the complete, including 28 million objects, EROS-2 and MACHO LMC datasets, finding 1160 and 2551 candidates respectively. To further validate our list of candidates, we crossmatched our list with a previous 663 known strong candidates, getting 74% of matches for MACHO and 40% in EROS-2. The main difference on matching level is because EROS-2 is a slightly shallower survey which translates to significantly lower signal-to-noise ratio lightcurves.