 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Estimation via Auxiliary Models
Dec 11, 2020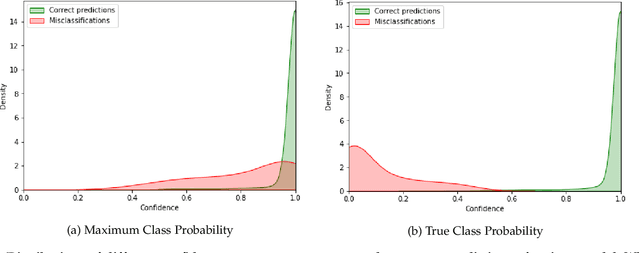
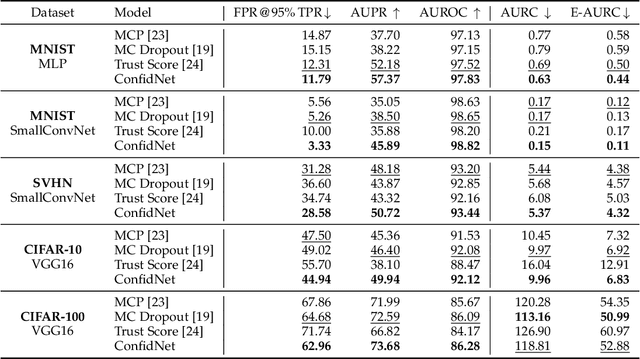
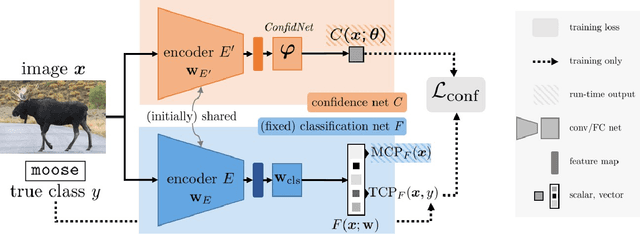

Reliably quantifying the confidence of deep neural classifiers is a challenging yet fundamental requirement for deploying such models in safety-critical applications. In this paper, we introduce a novel target criterion for model confidence, namely the true class probability (TCP). We show that TCP offers better properties for confidence estimation than standard maximum class probability (MCP). Since the true class is by essence unknown at test time, we propose to learn TCP criterion from data with an auxiliary model, introducing a specific learning scheme adapted to this context. We evaluate our approach on the task of failure prediction and of self-training with pseudo-labels for domain adaptation, which both necessitate effective confidence estimates. Extensive experiments are conducted for validating the relevance of the proposed approach in each task. We study various network architectures and experiment with small and large datasets for image classification and semantic segmentation. In every tested benchmark, our approach outperforms strong baselines.
Driving Behavior Explanation with Multi-level Fusion
Dec 09, 2020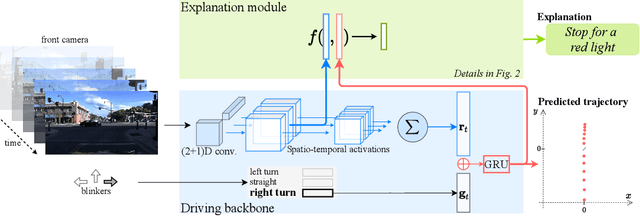
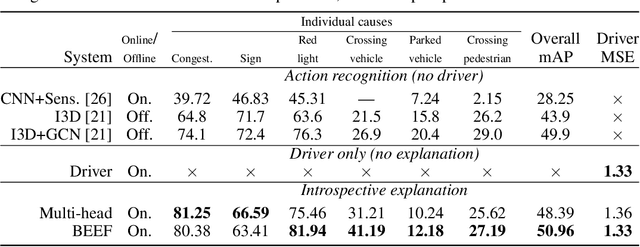
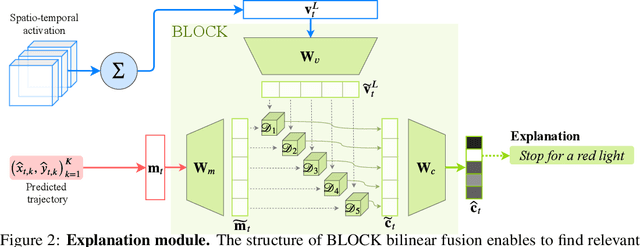
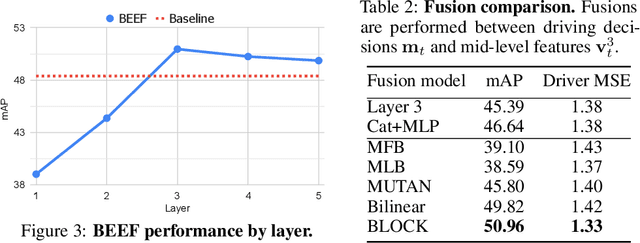
In this era of active development of autonomous vehicles, it becomes crucial to provide driving systems with the capacity to explain their decisions. In this work, we focus on generating high-level driving explanations as the vehicle drives. We present BEEF, for BEhavior Explanation with Fusion, a deep architecture which explains the behavior of a trajectory prediction model. Supervised by annotations of human driving decisions justifications, BEEF learns to fuse features from multiple levels. Leveraging recent advances in the multi-modal fusion literature, BEEF is carefully designed to model the correlations between high-level decisions features and mid-level perceptual features. The flexibility and efficiency of our approach are validated with extensive experiments on the HDD and BDD-X datasets.
Detecting 32 Pedestrian Attributes for Autonomous Vehicles
Dec 04, 2020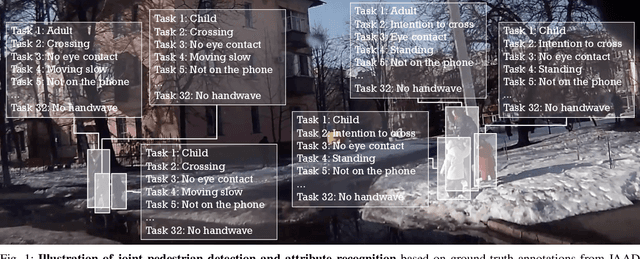
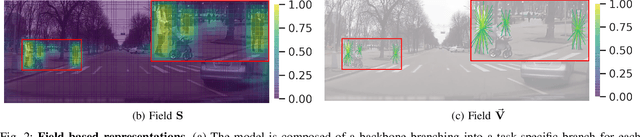
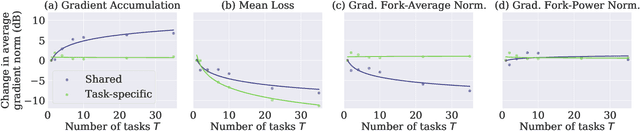

Pedestrians are arguably one of the most safety-critical road users to consider for autonomous vehicles in urban areas. In this paper, we address the problem of jointly detecting pedestrians and recognizing 32 pedestrian attributes. These encompass visual appearance and behavior, and also include the forecasting of road crossing, which is a main safety concern. For this, we introduce a Multi-Task Learning (MTL) model relying on a composite field framework, which achieves both goals in an efficient way. Each field spatially locates pedestrian instances and aggregates attribute predictions over them. This formulation naturally leverages spatial context, making it well suited to low resolution scenarios such as autonomous driving. By increasing the number of attributes jointly learned, we highlight an issue related to the scales of gradients, which arises in MTL with numerous tasks. We solve it by normalizing the gradients coming from different objective functions when they join at the fork in the network architecture during the backward pass, referred to as fork-normalization. Experimental validation is performed on JAAD, a dataset providing numerous attributes for pedestrian analysis from autonomous vehicles, and shows competitive detection and attribute recognition results, as well as a more stable MTL training.
PIE: Portrait Image Embedding for Semantic Control
Sep 20, 2020

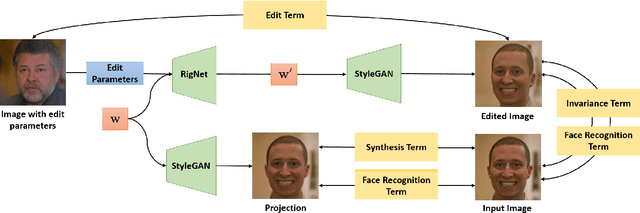

Editing of portrait images is a very popular and important research topic with a large variety of applications. For ease of use, control should be provided via a semantically meaningful parameterization that is akin to computer animation controls. The vast majority of existing techniques do not provide such intuitive and fine-grained control, or only enable coarse editing of a single isolated control parameter. Very recently, high-quality semantically controlled editing has been demonstrated, however only on synthetically created StyleGAN images. We present the first approach for embedding real portrait images in the latent space of StyleGAN, which allows for intuitive editing of the head pose, facial expression, and scene illumination in the image. Semantic editing in parameter space is achieved based on StyleRig, a pretrained neural network that maps the control space of a 3D morphable face model to the latent space of the GAN. We design a novel hierarchical non-linear optimization problem to obtain the embedding. An identity preservation energy term allows spatially coherent edits while maintaining facial integrity. Our approach runs at interactive frame rates and thus allows the user to explore the space of possible edits. We evaluate our approach on a wide set of portrait photos, compare it to the current state of the art, and validate the effectiveness of its components in an ablation study.
VRUNet: Multi-Task Learning Model for Intent Prediction of Vulnerable Road Users
Jul 10, 2020
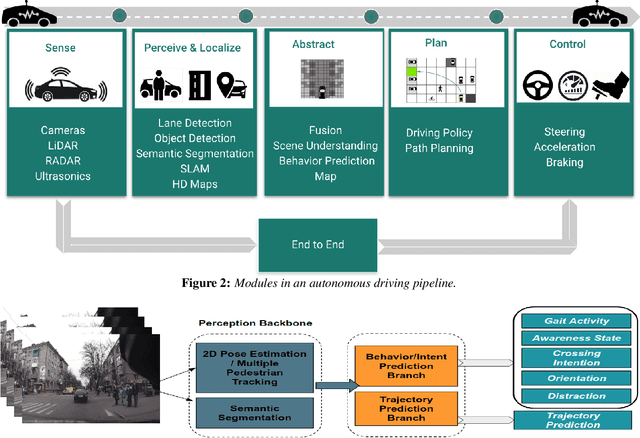
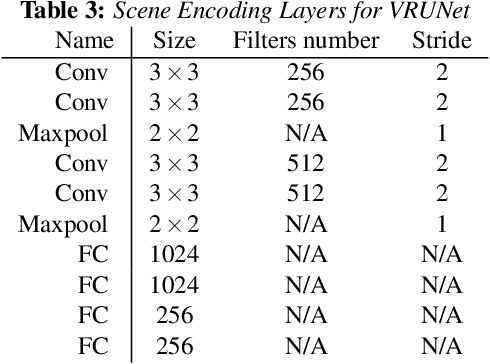
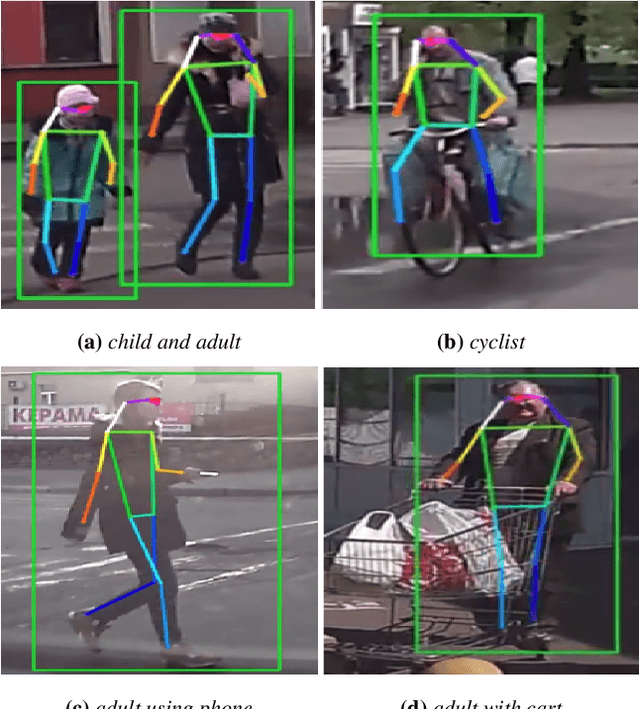
Advanced perception and path planning are at the core for any self-driving vehicle. Autonomous vehicles need to understand the scene and intentions of other road users for safe motion planning. For urban use cases it is very important to perceive and predict the intentions of pedestrians, cyclists, scooters, etc., classified as vulnerable road users (VRU). Intent is a combination of pedestrian activities and long term trajectories defining their future motion. In this paper we propose a multi-task learning model to predict pedestrian actions, crossing intent and forecast their future path from video sequences. We have trained the model on naturalistic driving open-source JAAD dataset, which is rich in behavioral annotations and real world scenarios. Experimental results show state-of-the-art performance on JAAD dataset and how we can benefit from jointly learning and predicting actions and trajectories using 2D human pose features and scene context.
Toward unsupervised, multi-object discovery in large-scale image collections
Jul 06, 2020

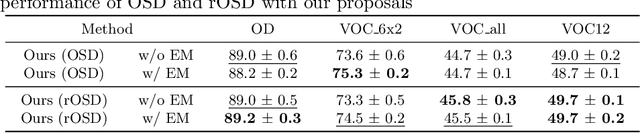
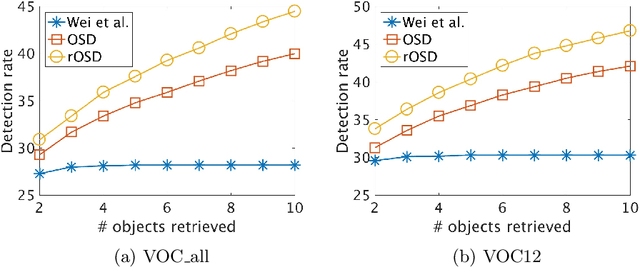
This paper addresses the problem of discovering the objects present in a collection of images without any supervision. We build on the optimization approach of Vo {\em et al.}~\cite{Vo2019UnsupOptim} with several key novelties: (1) We propose a novel saliency-based region proposal algorithm that achieves significantly higher overlap with ground-truth objects than other competitive methods. This procedure leverages off-the-shelf CNN features trained on classification tasks without any bounding box information, but is otherwise unsupervised. (2) We exploit the inherent hierarchical structure of proposals as an effective regularizer for the approach to object discovery of~\cite{Vo2019UnsupOptim}, boosting its performance to significantly improve over the state of the art on several standard benchmarks. (3) We adopt a two-stage strategy to select promising proposals using small random sets of images before using the whole image collection to discover the objects it depicts, allowing us to tackle, for the first time (to the best of our knowledge), the discovery of multiple objects in each one of the pictures making up datasets with up to 20,000 images, an over five-fold increase compared to existing methods, and a first step toward true large-scale unsupervised image interpretation.
Spherical Perspective on Learning with Batch Norm
Jun 23, 2020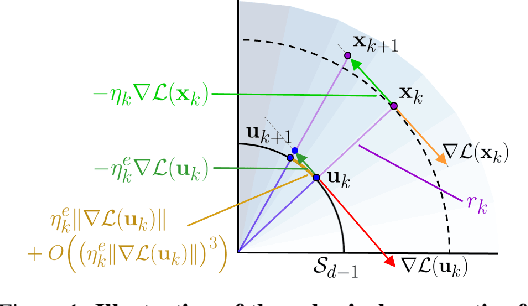
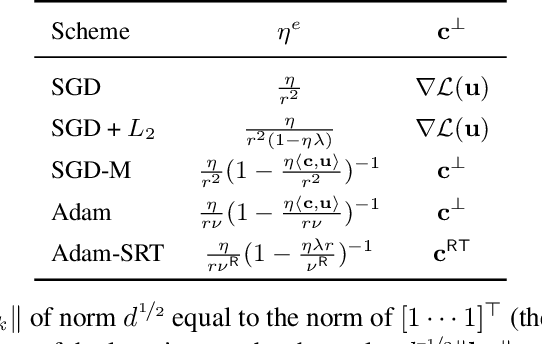
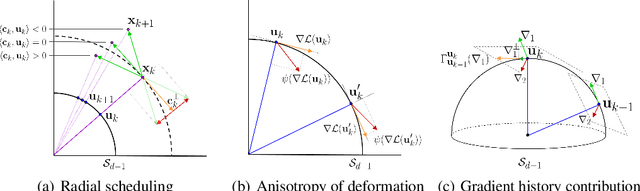
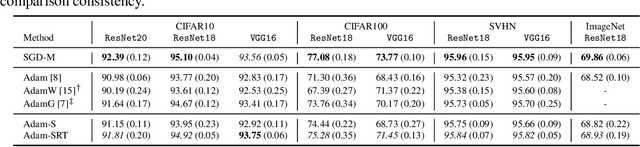
Batch Normalization (BN) is a prominent deep learning technique. In spite of its apparent simplicity, its implications over optimization are yet to be fully understood. In this paper, we study the optimization of neural networks with BN layers from a geometric perspective. We leverage the radial invariance of groups of parameters, such as neurons for multi-layer perceptrons or filters for convolutional neural networks, and translate several popular optimization schemes on the $L_2$ unit hypersphere. This formulation and the associated geometric interpretation sheds new light on the training dynamics and the relation between different optimization schemes. In particular, we use it to derive the effective learning rate of Adam and stochastic gradient descent (SGD) with momentum, and we show that in the presence of BN layers, performing SGD alone is actually equivalent to a variant of Adam constrained to the unit hypersphere. Our analysis also leads us to introduce new variants of Adam. We empirically show, over a variety of datasets and architectures, that they improve accuracy in classification tasks. The complete source code for our experiments is available at: https://github.com/ymontmarin/adamsrt
ESL: Entropy-guided Self-supervised Learning for Domain Adaptation in Semantic Segmentation
Jun 15, 2020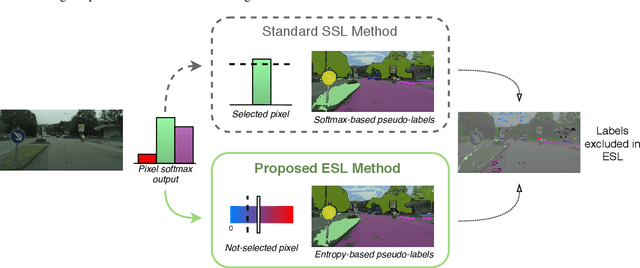
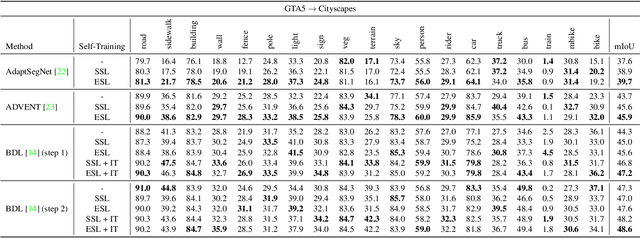
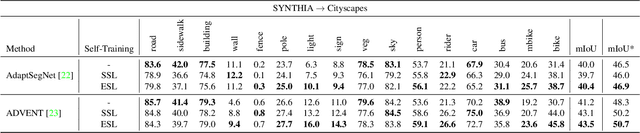

While fully-supervised deep learning yields good models for urban scene semantic segmentation, these models struggle to generalize to new environments with different lighting or weather conditions for instance. In addition, producing the extensive pixel-level annotations that the task requires comes at a great cost. Unsupervised domain adaptation (UDA) is one approach that tries to address these issues in order to make such systems more scalable. In particular, self-supervised learning (SSL) has recently become an effective strategy for UDA in semantic segmentation. At the core of such methods lies `pseudo-labeling', that is, the practice of assigning high-confident class predictions as pseudo-labels, subsequently used as true labels, for target data. To collect pseudo-labels, previous works often rely on the highest softmax score, which we here argue as an unfavorable confidence measurement. In this work, we propose Entropy-guided Self-supervised Learning (ESL), leveraging entropy as the confidence indicator for producing more accurate pseudo-labels. On different UDA benchmarks, ESL consistently outperforms strong SSL baselines and achieves state-of-the-art results.
Photo style transfer with consistency losses
May 09, 2020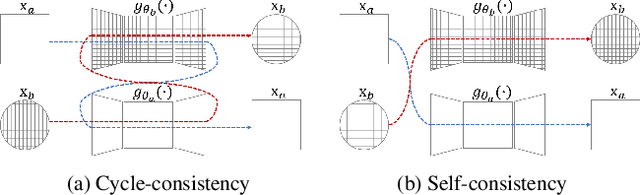


We address the problem of style transfer between two photos and propose a new way to preserve photorealism. Using the single pair of photos available as input, we train a pair of deep convolution networks (convnets), each of which transfers the style of one photo to the other. To enforce photorealism, we introduce a content preserving mechanism by combining a cycle-consistency loss with a self-consistency loss. Experimental results show that this method does not suffer from typical artifacts observed in methods working in the same settings. We then further analyze some properties of these trained convnets. First, we notice that they can be used to stylize other unseen images with same known style. Second, we show that retraining only a small subset of the network parameters can be sufficient to adapt these convnets to new styles.
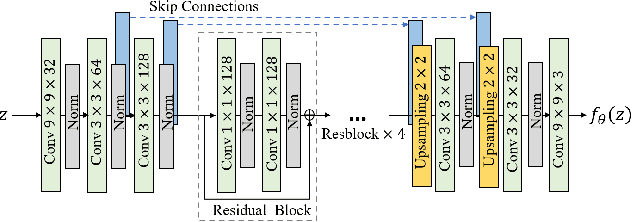
BUDA: Boundless Unsupervised Domain Adaptation in Semantic Segmentation
Apr 02, 2020
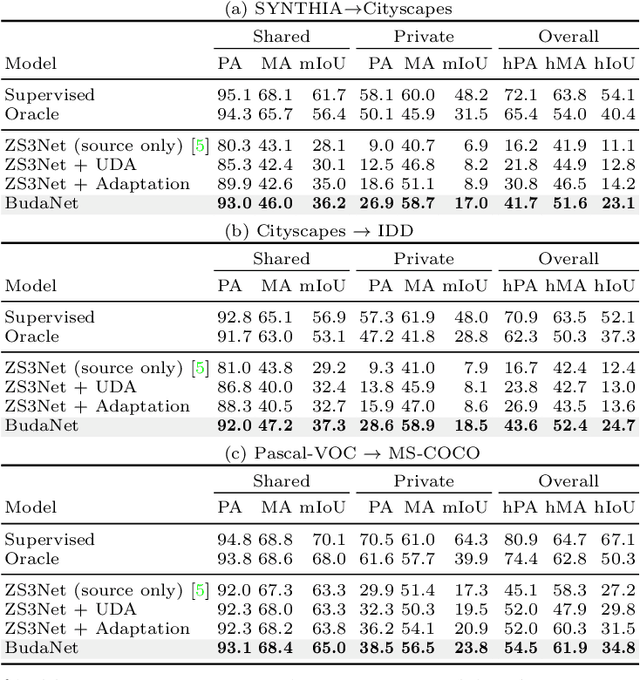
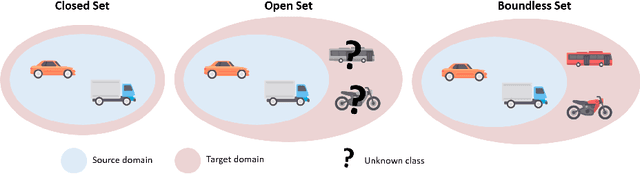
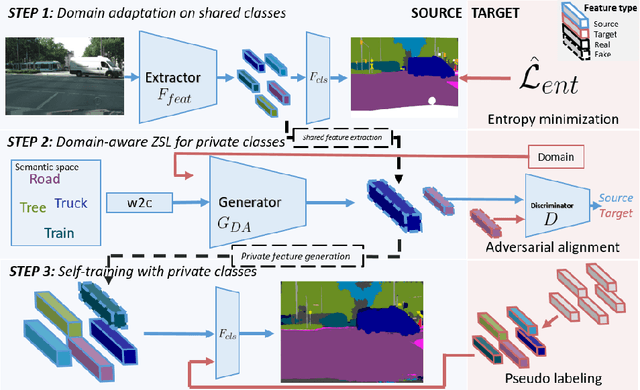
In this work, we define and address "Boundless Unsupervised Domain Adaptation" (BUDA), a novel problem in semantic segmentation. BUDA set-up pictures a realistic scenario where unsupervised target domain not only exhibits a data distribution shift w.r.t. supervised source domain but also includes classes that are absent from the latter. Different to "open-set" and "universal domain adaptation", which both regard never-seen objects as "unknown", BUDA aims at explicit test-time prediction for these never-seen classes. To reach this goal, we propose a novel framework leveraging domain adaptation and zero-shot learning techniques to enable "boundless" adaptation on the target domain. Performance is further improved using self-training on target pseudo-labels. For validation, we consider different domain adaptation set-ups, namely synthetic-2-real, country-2-country and dataset-2-dataset. Our framework outperforms the baselines by significant margins, setting competitive standards on all benchmarks for the new task. Code and models are available at:~\url{https://github.com/valeoai/buda}.