 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory for Equivariant Quantum Neural Networks
Oct 16, 2022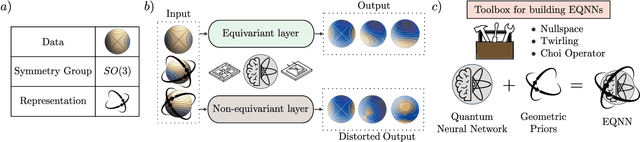
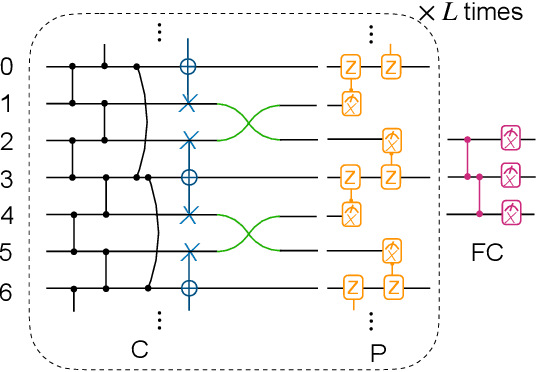
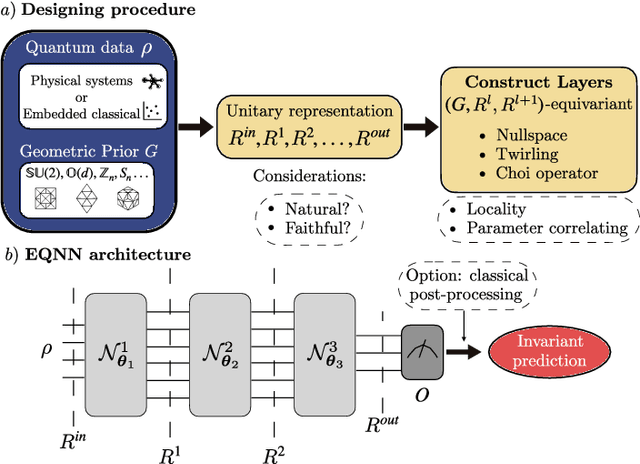
Most currently used quantum neural network architectures have little-to-no inductive biases, leading to trainability and generalization issues. Inspired by a similar problem, recent breakthroughs in classical machine learning address this crux by creating models encoding the symmetries of the learning task. This is materialized through the usage of equivariant neural networks whose action commutes with that of the symmetry. In this work, we import these ideas to the quantum realm by presenting a general theoretical framework to understand, classify, design and implement equivariant quantum neural networks. As a special implementation, we show how standard quantum convolutional neural networks (QCNN) can be generalized to group-equivariant QCNNs where both the convolutional and pooling layers are equivariant under the relevant symmetry group. Our framework can be readily applied to virtually all areas of quantum machine learning, and provides hope to alleviate central challenges such as barren plateaus, poor local minima, and sample complexity.
Representation Theory for Geometric Quantum Machine Learning
Oct 14, 2022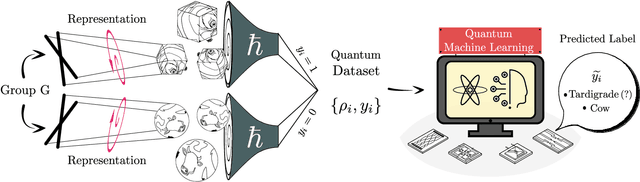
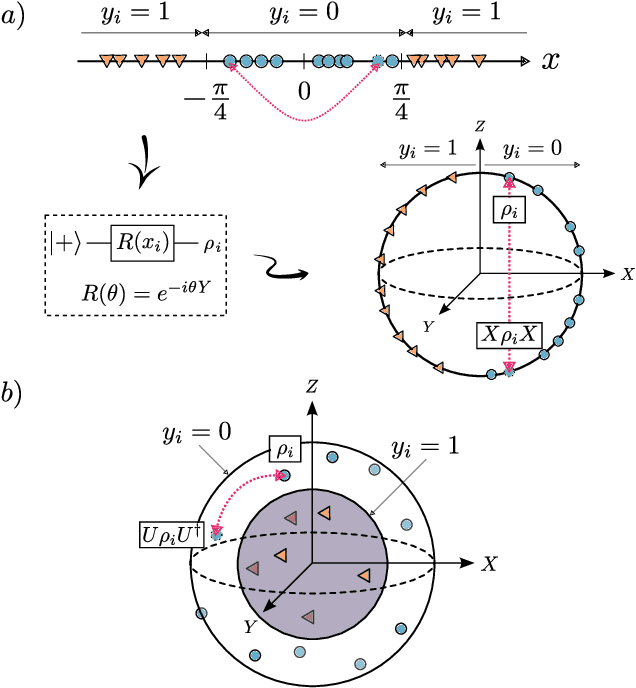
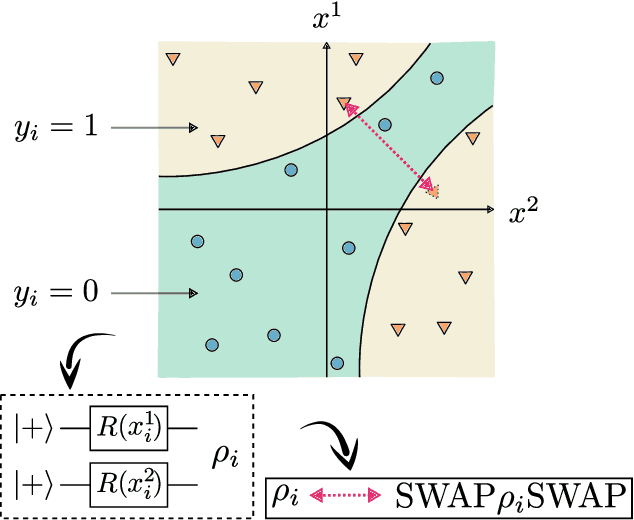
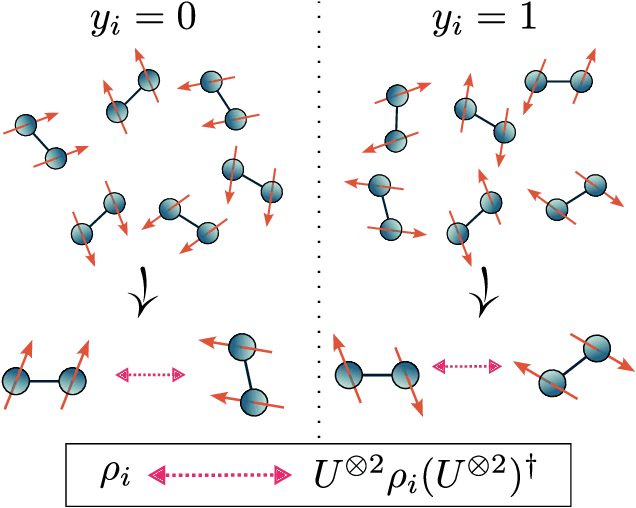
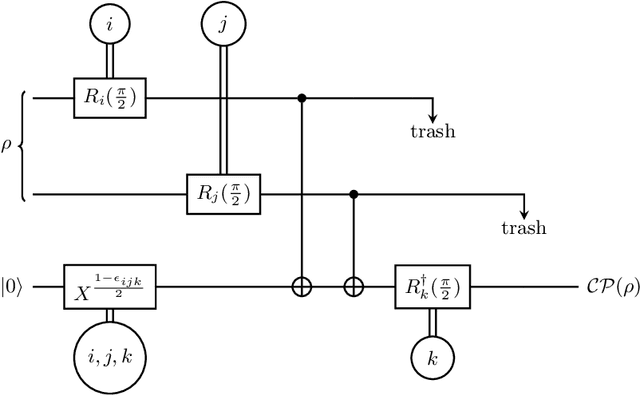
Recent advances in classical machine learning have shown that creating models with inductive biases encoding the symmetries of a problem can greatly improve performance. Importation of these ideas, combined with an existing rich body of work at the nexus of quantum theory and symmetry, has given rise to the field of Geometric Quantum Machine Learning (GQML). Following the success of its classical counterpart, it is reasonable to expect that GQML will play a crucial role in developing problem-specific and quantum-aware models capable of achieving a computational advantage. Despite the simplicity of the main idea of GQML -- create architectures respecting the symmetries of the data -- its practical implementation requires a significant amount of knowledge of group representation theory. We present an introduction to representation theory tools from the optics of quantum learning, driven by key examples involving discrete and continuous groups. These examples are sewn together by an exposition outlining the formal capture of GQML symmetries via "label invariance under the action of a group representation", a brief (but rigorous) tour through finite and compact Lie group representation theory, a reexamination of ubiquitous tools like Haar integration and twirling, and an overview of some successful strategies for detecting symmetries.
Practical Black Box Hamiltonian Learning
Jun 30, 2022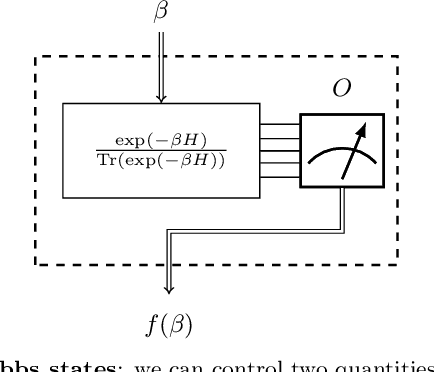

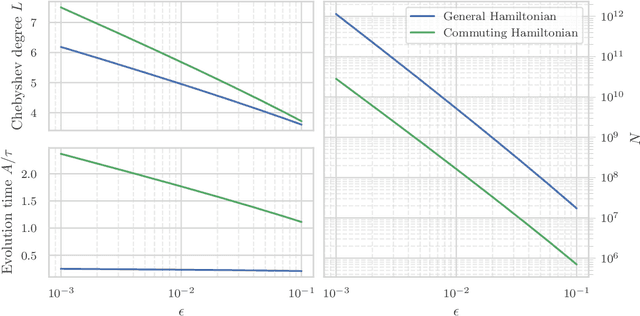
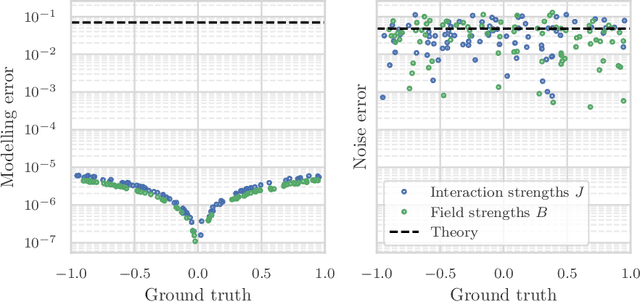
We study the problem of learning the parameters for the Hamiltonian of a quantum many-body system, given limited access to the system. In this work, we build upon recent approaches to Hamiltonian learning via derivative estimation. We propose a protocol that improves the scaling dependence of prior works, particularly with respect to parameters relating to the structure of the Hamiltonian (e.g., its locality $k$). Furthermore, by deriving exact bounds on the performance of our protocol, we are able to provide a precise numerical prescription for theoretically optimal settings of hyperparameters in our learning protocol, such as the maximum evolution time (when learning with unitary dynamics) or minimum temperature (when learning with Gibbs states). Thanks to these improvements, our protocol is practical for large problems: we demonstrate this with a numerical simulation of our protocol on an 80-qubit system.
Inference-Based Quantum Sensing
Jun 20, 2022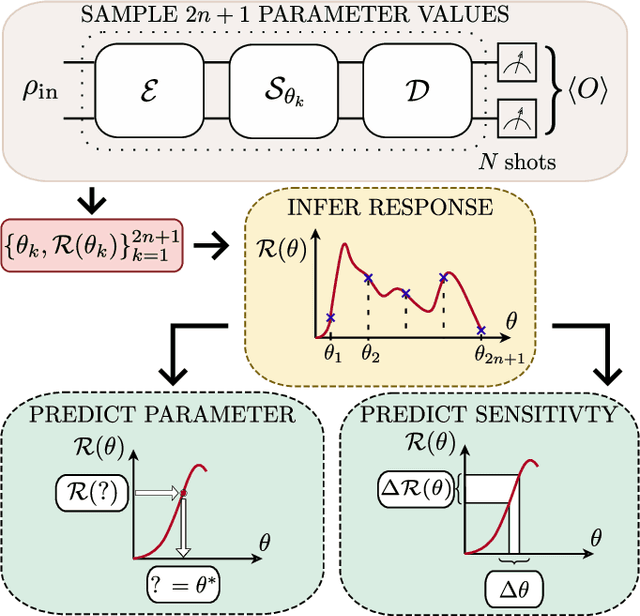
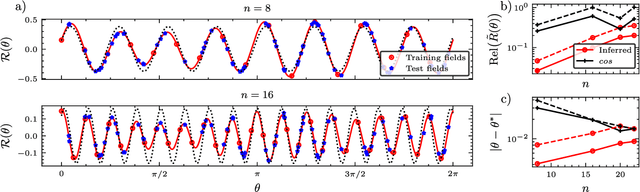
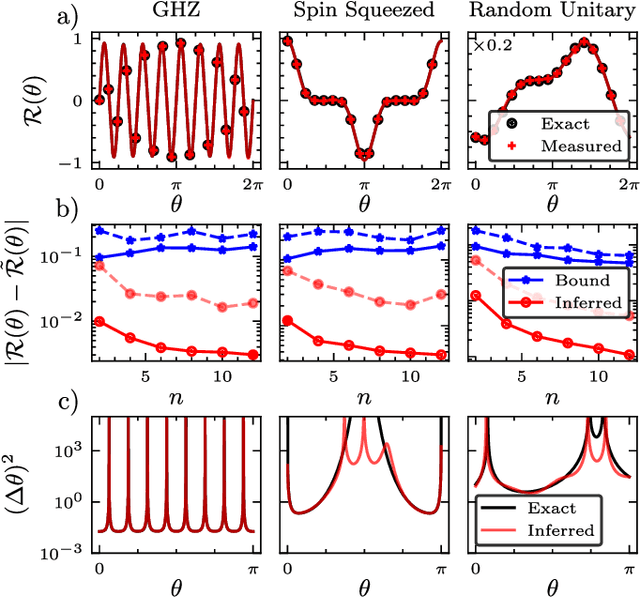
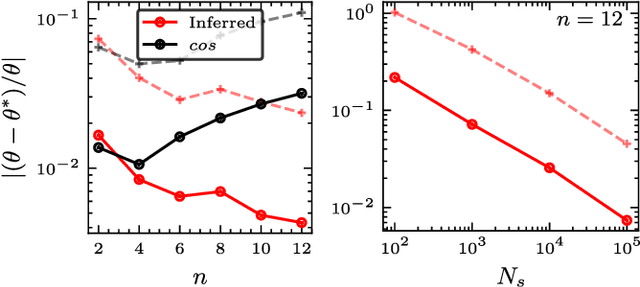
In a standard Quantum Sensing (QS) task one aims at estimating an unknown parameter $\theta$, encoded into an $n$-qubit probe state, via measurements of the system. The success of this task hinges on the ability to correlate changes in the parameter to changes in the system response $\mathcal{R}(\theta)$ (i.e., changes in the measurement outcomes). For simple cases the form of $\mathcal{R}(\theta)$ is known, but the same cannot be said for realistic scenarios, as no general closed-form expression exists. In this work we present an inference-based scheme for QS. We show that, for a general class of unitary families of encoding, $\mathcal{R}(\theta)$ can be fully characterized by only measuring the system response at $2n+1$ parameters. In turn, this allows us to infer the value of an unknown parameter given the measured response, as well as to determine the sensitivity of the sensing scheme, which characterizes its overall performance. We show that inference error is, with high probability, smaller than $\delta$, if one measures the system response with a number of shots that scales only as $\Omega(\log^3(n)/\delta^2)$. Furthermore, the framework presented can be broadly applied as it remains valid for arbitrary probe states and measurement schemes, and, even holds in the presence of quantum noise. We also discuss how to extend our results beyond unitary families. Finally, to showcase our method we implement it for a QS task on real quantum hardware, and in numerical simulations.
Group-Invariant Quantum Machine Learning
May 04, 2022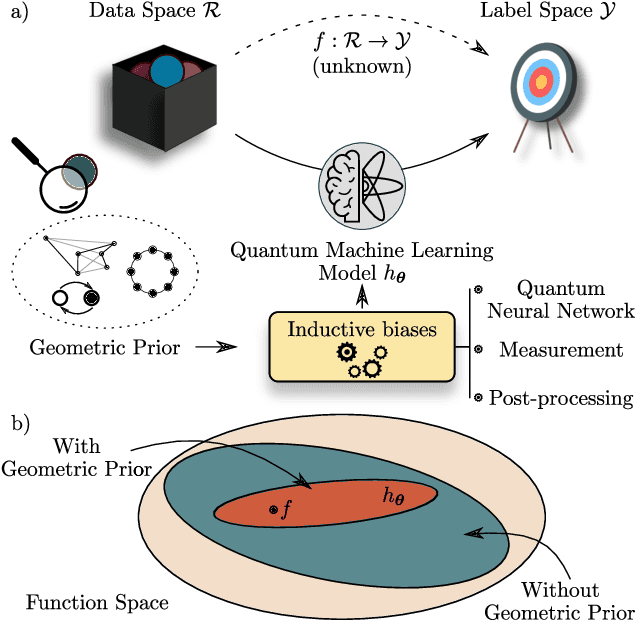

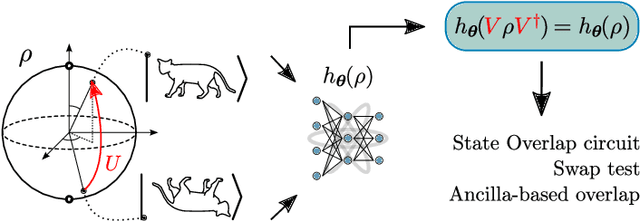
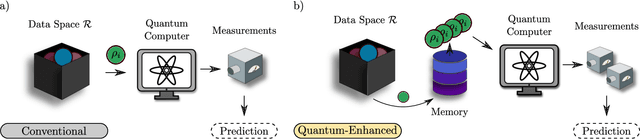
Quantum Machine Learning (QML) models are aimed at learning from data encoded in quantum states. Recently, it has been shown that models with little to no inductive biases (i.e., with no assumptions about the problem embedded in the model) are likely to have trainability and generalization issues, especially for large problem sizes. As such, it is fundamental to develop schemes that encode as much information as available about the problem at hand. In this work we present a simple, yet powerful, framework where the underlying invariances in the data are used to build QML models that, by construction, respect those symmetries. These so-called group-invariant models produce outputs that remain invariant under the action of any element of the symmetry group $\mathfrak{G}$ associated to the dataset. We present theoretical results underpinning the design of $\mathfrak{G}$-invariant models, and exemplify their application through several paradigmatic QML classification tasks including cases when $\mathfrak{G}$ is a continuous Lie group and also when it is a discrete symmetry group. Notably, our framework allows us to recover, in an elegant way, several well known algorithms for the literature, as well as to discover new ones. Taken together, we expect that our results will help pave the way towards a more geometric and group-theoretic approach to QML model design.
Dynamical simulation via quantum machine learning with provable generalization
Apr 21, 2022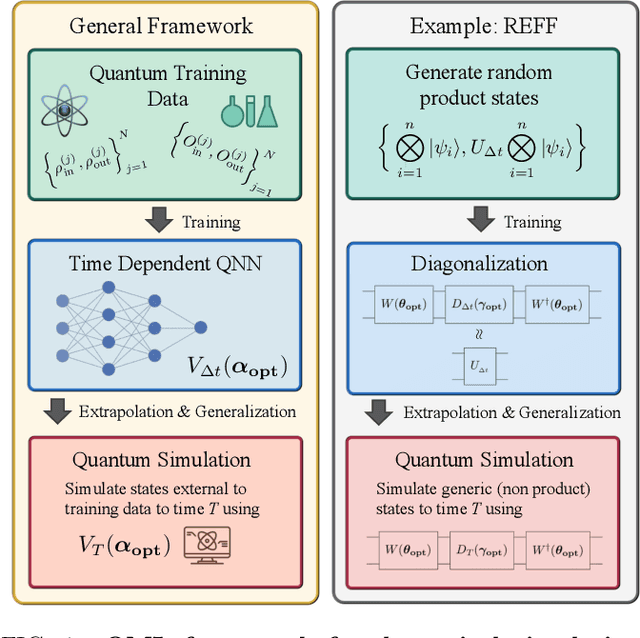
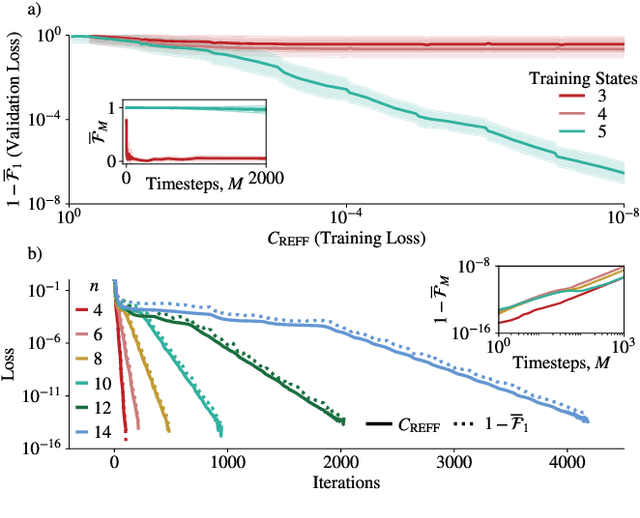
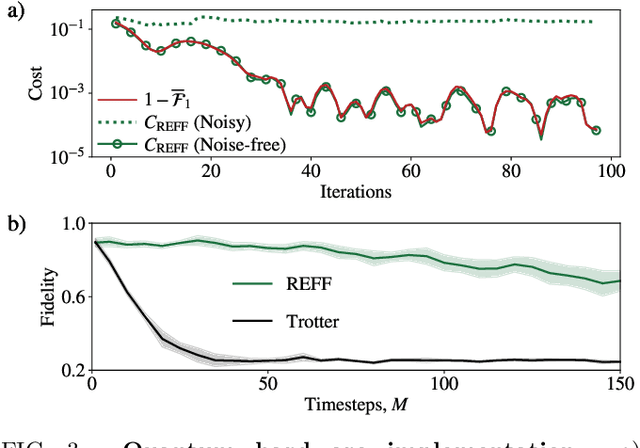
Much attention has been paid to dynamical simulation and quantum machine learning (QML) independently as applications for quantum advantage, while the possibility of using QML to enhance dynamical simulations has not been thoroughly investigated. Here we develop a framework for using QML methods to simulate quantum dynamics on near-term quantum hardware. We use generalization bounds, which bound the error a machine learning model makes on unseen data, to rigorously analyze the training data requirements of an algorithm within this framework. This provides a guarantee that our algorithm is resource-efficient, both in terms of qubit and data requirements. Our numerics exhibit efficient scaling with problem size, and we simulate 20 times longer than Trotterization on IBMQ-Bogota.
Out-of-distribution generalization for learning quantum dynamics
Apr 21, 2022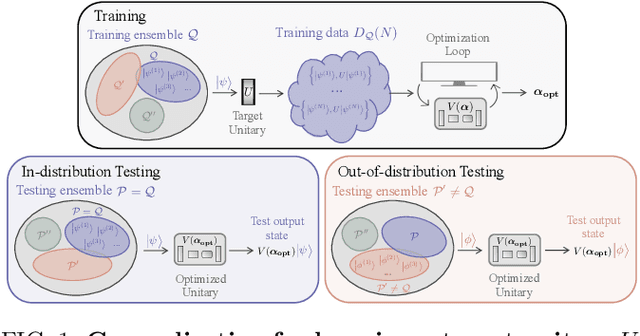
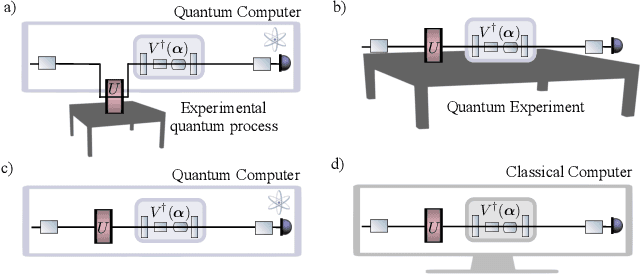
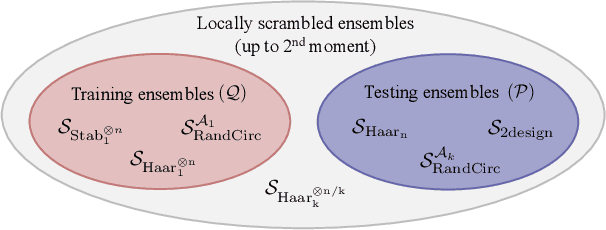
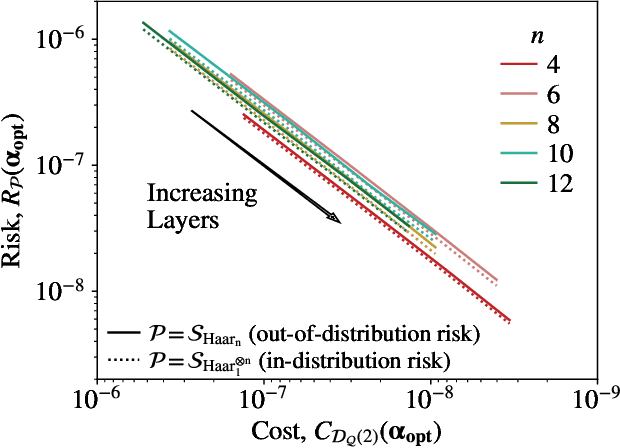
Generalization bounds are a critical tool to assess the training data requirements of Quantum Machine Learning (QML). Recent work has established guarantees for in-distribution generalization of quantum neural networks (QNNs), where training and testing data are assumed to be drawn from the same data distribution. However, there are currently no results on out-of-distribution generalization in QML, where we require a trained model to perform well even on data drawn from a distribution different from the training distribution. In this work, we prove out-of-distribution generalization for the task of learning an unknown unitary using a QNN and for a broad class of training and testing distributions. In particular, we show that one can learn the action of a unitary on entangled states using only product state training data. We numerically illustrate this by showing that the evolution of a Heisenberg spin chain can be learned using only product training states. Since product states can be prepared using only single-qubit gates, this advances the prospects of learning quantum dynamics using near term quantum computers and quantum experiments, and further opens up new methods for both the classical and quantum compilation of quantum circuits.
Covariance matrix preparation for quantum principal component analysis
Apr 07, 2022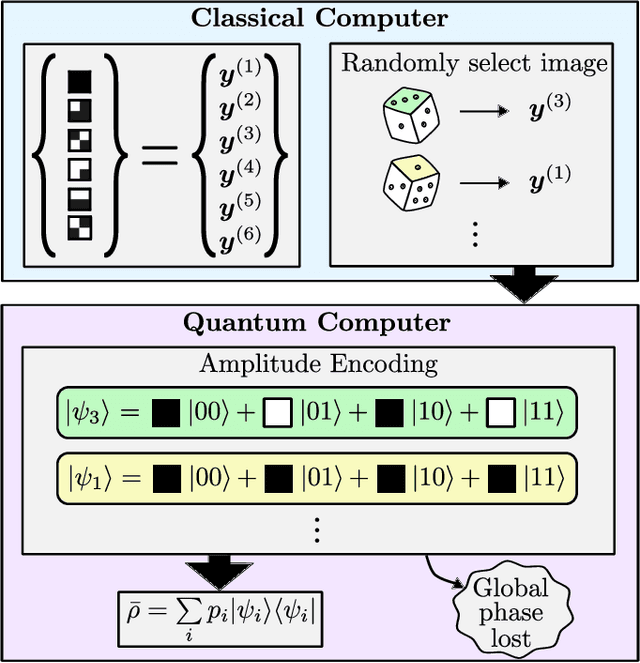
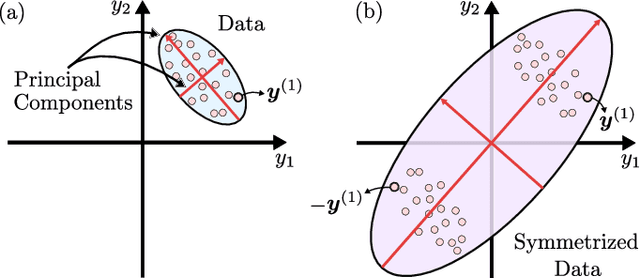
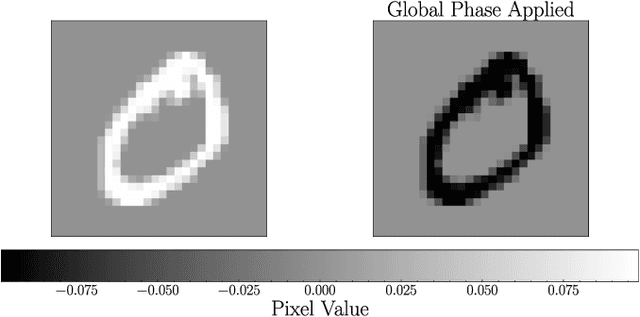
Principal component analysis (PCA) is a dimensionality reduction method in data analysis that involves diagonalizing the covariance matrix of the dataset. Recently, quantum algorithms have been formulated for PCA based on diagonalizing a density matrix. These algorithms assume that the covariance matrix can be encoded in a density matrix, but a concrete protocol for this encoding has been lacking. Our work aims to address this gap. Assuming amplitude encoding of the data, with the data given by the ensemble $\{p_i,| \psi_i \rangle\}$, then one can easily prepare the ensemble average density matrix $\overline{\rho} = \sum_i p_i |\psi_i\rangle \langle \psi_i |$. We first show that $\overline{\rho}$ is precisely the covariance matrix whenever the dataset is centered. For quantum datasets, we exploit global phase symmetry to argue that there always exists a centered dataset consistent with $\overline{\rho}$, and hence $\overline{\rho}$ can always be interpreted as a covariance matrix. This provides a simple means for preparing the covariance matrix for arbitrary quantum datasets or centered classical datasets. For uncentered classical datasets, our method is so-called "PCA without centering", which we interpret as PCA on a symmetrized dataset. We argue that this closely corresponds to standard PCA, and we derive equations and inequalities that bound the deviation of the spectrum obtained with our method from that of standard PCA. We numerically illustrate our method for the MNIST handwritten digit dataset. We also argue that PCA on quantum datasets is natural and meaningful, and we numerically implement our method for molecular ground-state datasets.
The quantum low-rank approximation problem
Apr 01, 2022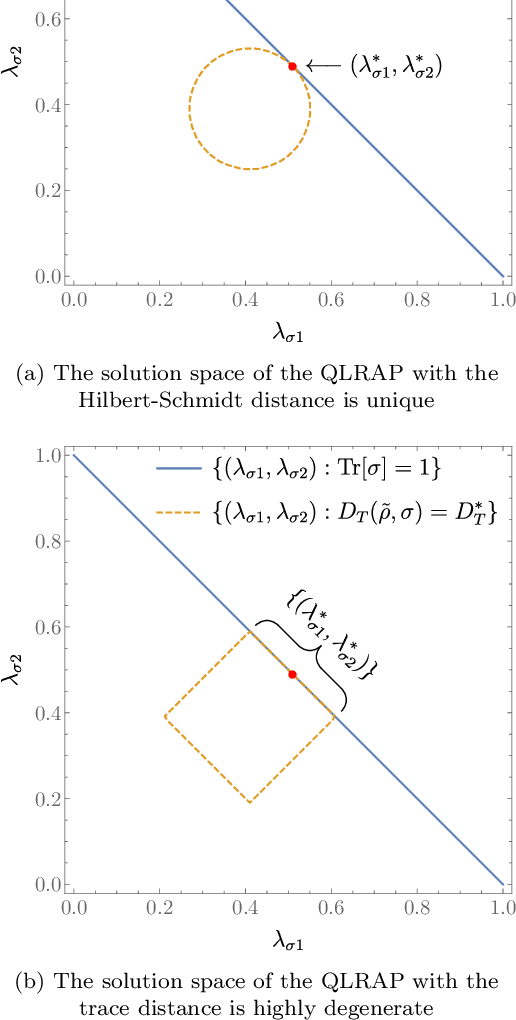
We consider a quantum version of the famous low-rank approximation problem. Specifically, we consider the distance $D(\rho,\sigma)$ between two normalized quantum states, $\rho$ and $\sigma$, where the rank of $\sigma$ is constrained to be at most $R$. For both the trace distance and Hilbert-Schmidt distance, we analytically solve for the optimal state $\sigma$ that minimizes this distance. For the Hilbert-Schmidt distance, the unique optimal state is $\sigma = \tau_R +N_R$, where $\tau_R = \Pi_R \rho \Pi_R$ is given by projecting $\rho$ onto its $R$ principal components with projector $\Pi_R$, and $N_R$ is a normalization factor given by $N_R = \frac{1- \text{Tr}(\tau_R)}{R}\Pi_R$. For the trace distance, this state is also optimal but not uniquely optimal, and we provide the full set of states that are optimal. We briefly discuss how our results have application for performing principal component analysis (PCA) via variational optimization on quantum computers.
Generalization in quantum machine learning from few training data
Nov 09, 2021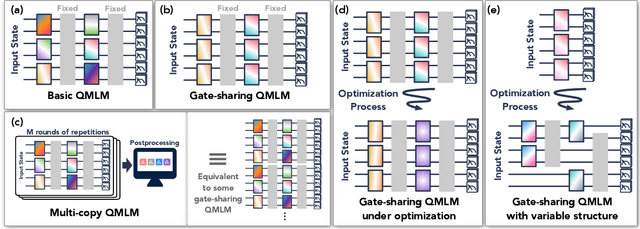
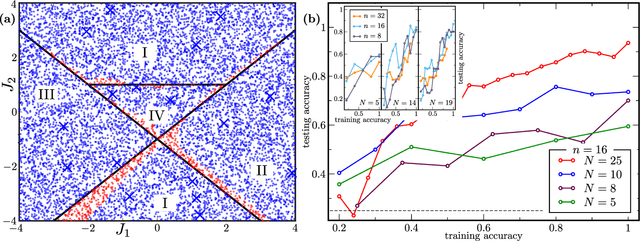
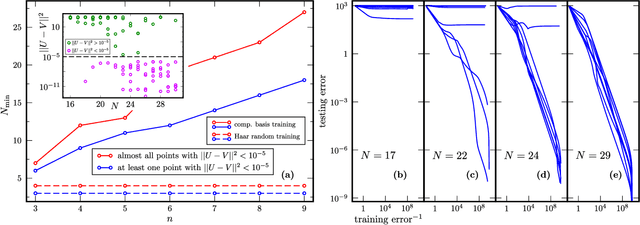
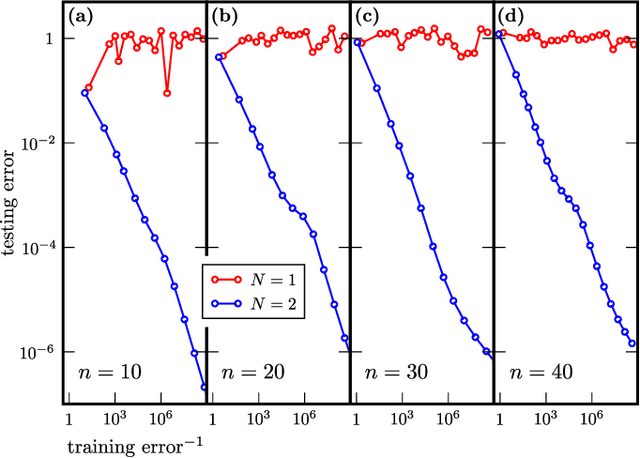
Modern quantum machine learning (QML) methods involve variationally optimizing a parameterized quantum circuit on a training data set, and subsequently making predictions on a testing data set (i.e., generalizing). In this work, we provide a comprehensive study of generalization performance in QML after training on a limited number $N$ of training data points. We show that the generalization error of a quantum machine learning model with $T$ trainable gates scales at worst as $\sqrt{T/N}$. When only $K \ll T$ gates have undergone substantial change in the optimization process, we prove that the generalization error improves to $\sqrt{K / N}$. Our results imply that the compiling of unitaries into a polynomial number of native gates, a crucial application for the quantum computing industry that typically uses exponential-size training data, can be sped up significantly. We also show that classification of quantum states across a phase transition with a quantum convolutional neural network requires only a very small training data set. Other potential applications include learning quantum error correcting codes or quantum dynamical simulation. Our work injects new hope into the field of QML, as good generalization is guaranteed from few training data.