 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Low-Rank Matrix Factorization for LSTM Model Compression
Aug 27, 2019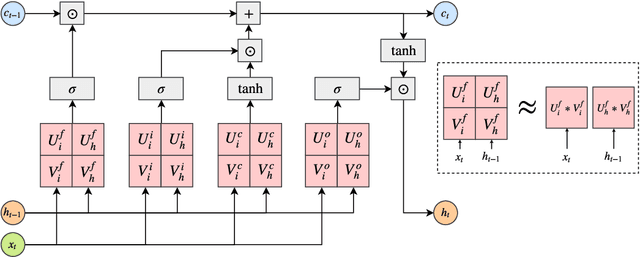
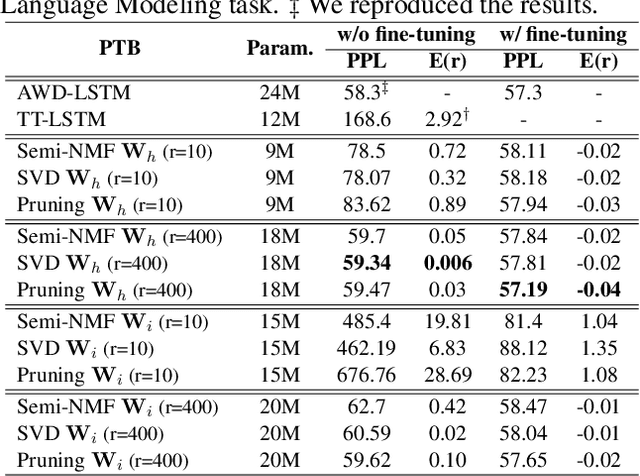
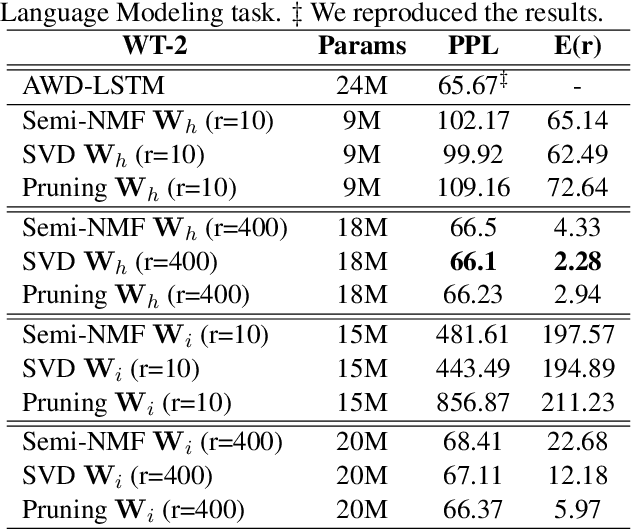
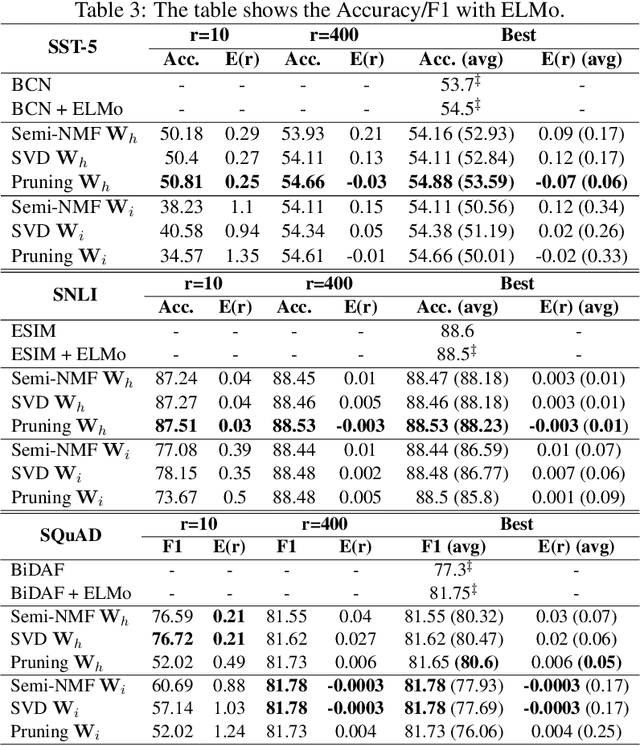
Despite their ubiquity in NLP tasks, Long Short-Term Memory (LSTM) networks suffer from computational inefficiencies caused by inherent unparallelizable recurrences, which further aggravates as LSTMs require more parameters for larger memory capacity. In this paper, we propose to apply low-rank matrix factorization (MF) algorithms to different recurrences in LSTMs, and explore the effectiveness on different NLP tasks and model components. We discover that additive recurrence is more important than multiplicative recurrence, and explain this by identifying meaningful correlations between matrix norms and compression performance. We compare our approach across two settings: 1) compressing core LSTM recurrences in language models, 2) compressing biLSTM layers of ELMo evaluated in three downstream NLP tasks.
MoEL: Mixture of Empathetic Listeners
Aug 21, 2019Previous research on empathetic dialogue systems has mostly focused on generating responses given certain emotions. However, being empathetic not only requires the ability of generating emotional responses, but more importantly, requires the understanding of user emotions and replying appropriately. In this paper, we propose a novel end-to-end approach for modeling empathy in dialogue systems: Mixture of Empathetic Listeners (MoEL). Our model first captures the user emotions and outputs an emotion distribution. Based on this, MoEL will softly combine the output states of the appropriate Listener(s), which are each optimized to react to certain emotions, and generate an empathetic response. Human evaluations on empathetic-dialogues (Rashkin et al., 2018) dataset confirm that MoEL outperforms multitask training baseline in terms of empathy, relevance, and fluency. Furthermore, the case study on generated responses of different Listeners shows high interpretability of our model.
Incorporating Word and Subword Units in Unsupervised Machine Translation Using Language Model Rescoring
Aug 16, 2019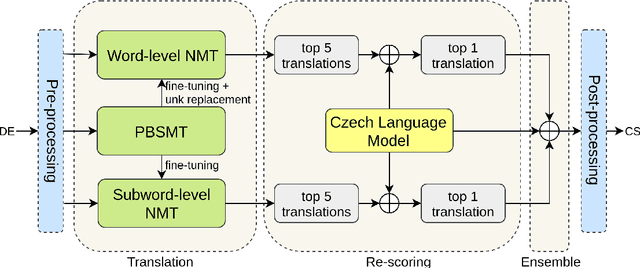
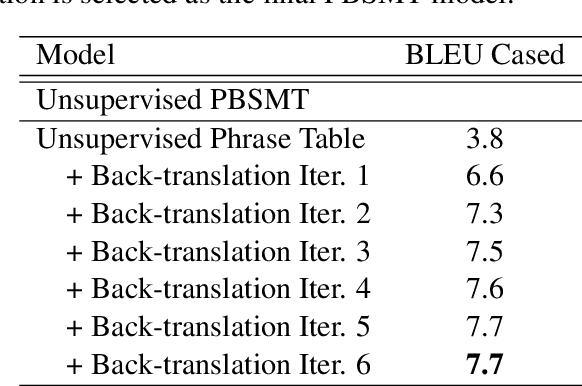
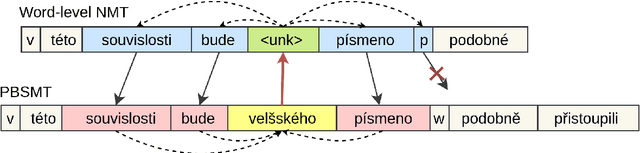
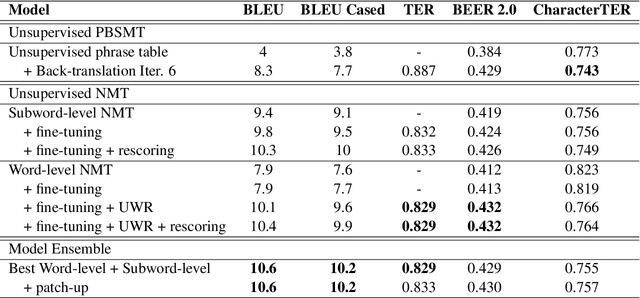
This paper describes CAiRE's submission to the unsupervised machine translation track of the WMT'19 news shared task from German to Czech. We leverage a phrase-based statistical machine translation (PBSMT) model and a pre-trained language model to combine word-level neural machine translation (NMT) and subword-level NMT models without using any parallel data. We propose to solve the morphological richness problem of languages by training byte-pair encoding (BPE) embeddings for German and Czech separately, and they are aligned using MUSE (Conneau et al., 2018). To ensure the fluency and consistency of translations, a rescoring mechanism is proposed that reuses the pre-trained language model to select the translation candidates generated through beam search. Moreover, a series of pre-processing and post-processing approaches are applied to improve the quality of final translations.
Getting To Know You: User Attribute Extraction from Dialogues
Aug 13, 2019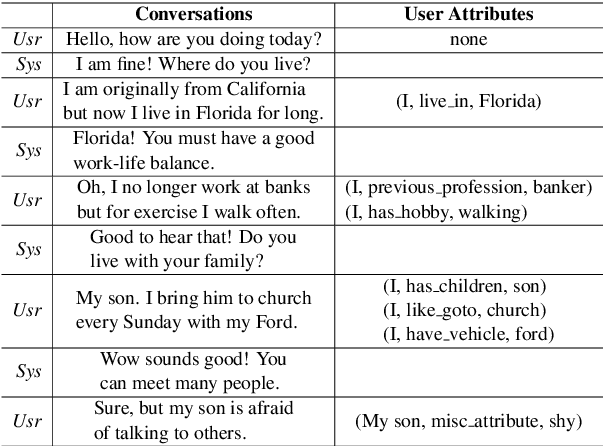
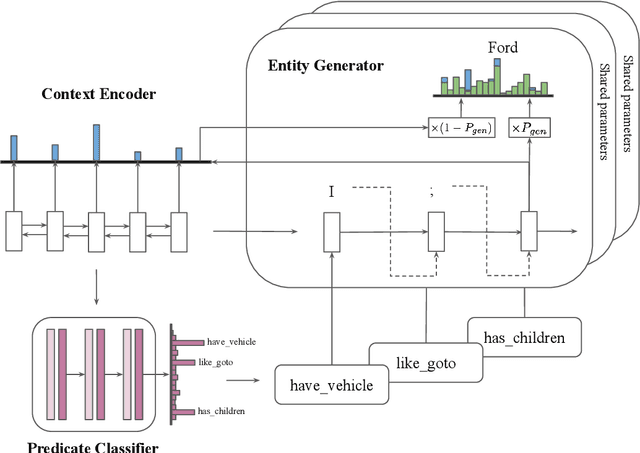

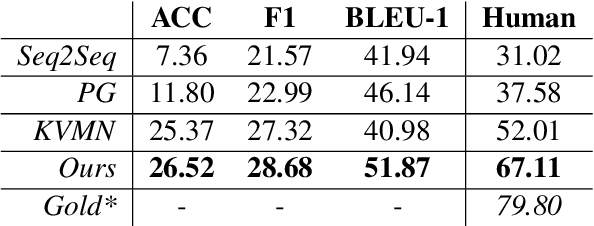
User attributes provide rich and useful information for user understanding, yet structured and easy-to-use attributes are often sparsely populated. In this paper, we leverage dialogues with conversational agents, which contain strong suggestions of user information, to automatically extract user attributes. Since no existing dataset is available for this purpose, we apply distant supervision to train our proposed two-stage attribute extractor, which surpasses several retrieval and generation baselines on human evaluation. Meanwhile, we discuss potential applications (e.g., personalized recommendation and dialogue systems) of such extracted user attributes, and point out current limitations to cast light on future work.
CAiRE: An End-to-End Empathetic Chatbot
Jul 28, 2019
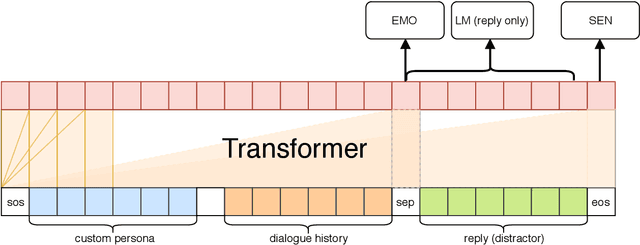
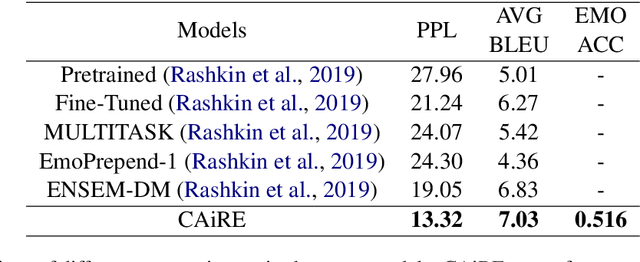

In this paper, we present an end-to-end empathetic conversation agent CAiRE. Our system adapts TransferTransfo (Wolf et al., 2019) learning approach that fine-tunes a large-scale pre-trained language model with multi-task objectives: response language modeling, response prediction and dialogue emotion detection. We evaluate our model on the recently proposed empathetic-dialogues dataset (Rashkin et al., 2019), the experiment results show that CAiRE achieves state-of-the-art performance on dialogue emotion detection and empathetic response generation.
HappyBot: Generating Empathetic Dialogue Responses by Improving User Experience Look-ahead
Jun 20, 2019
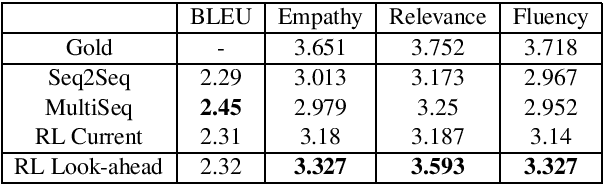

Recent neural conversation models that attempted to incorporate emotion and generate empathetic responses either focused on conditioning the output to a given emotion, or incorporating the current user emotional state. While these approaches have been successful to some extent in generating more diverse and seemingly engaging utterances, they do not factor in how the user would feel towards the generated dialogue response. Hence, in this paper, we advocate such look-ahead of user emotion as the key to modeling and generating empathetic dialogue responses. We thus train a Sentiment Predictor to estimate the user sentiment look-ahead towards the generated system responses, which is then used as the reward function for generating more empathetic responses. Human evaluation results show that our model outperforms other baselines in empathy, relevance, and fluency.
CAiRE_HKUST at SemEval-2019 Task 3: Hierarchical Attention for Dialogue Emotion Classification
Jun 10, 2019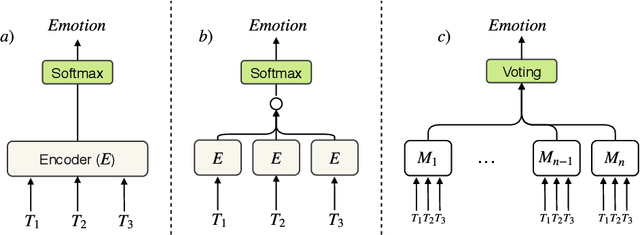
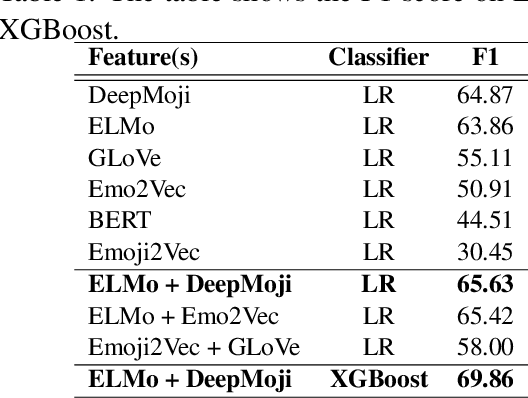
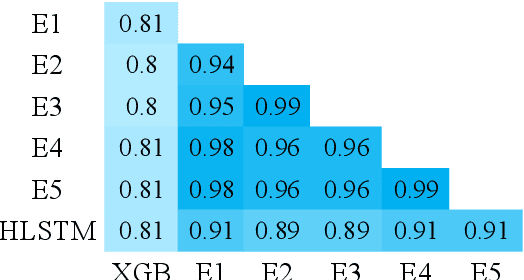
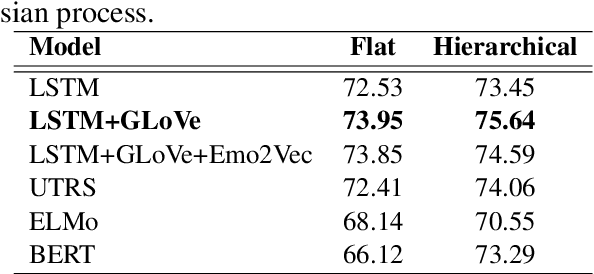
Detecting emotion from dialogue is a challenge that has not yet been extensively surveyed. One could consider the emotion of each dialogue turn to be independent, but in this paper, we introduce a hierarchical approach to classify emotion, hypothesizing that the current emotional state depends on previous latent emotions. We benchmark several feature-based classifiers using pre-trained word and emotion embeddings, state-of-the-art end-to-end neural network models, and Gaussian processes for automatic hyper-parameter search. In our experiments, hierarchical architectures consistently give significant improvements, and our best model achieves a 76.77% F1-score on the test set.
Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
May 26, 2019
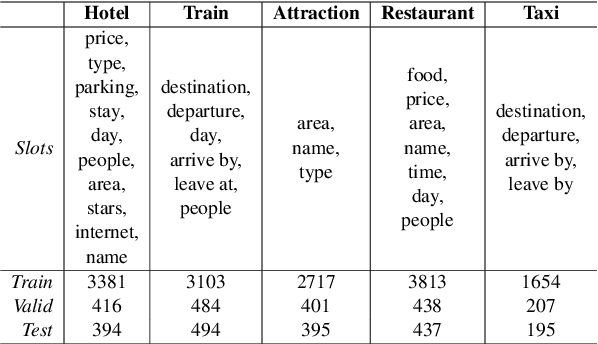
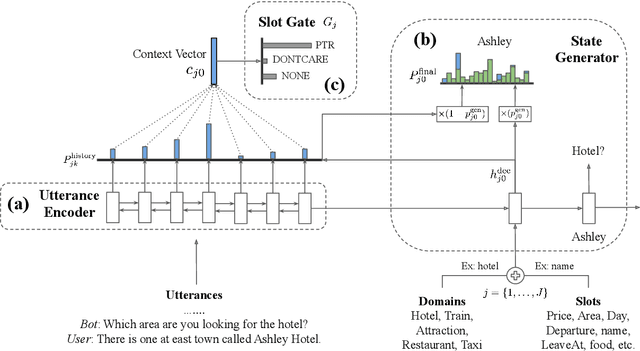
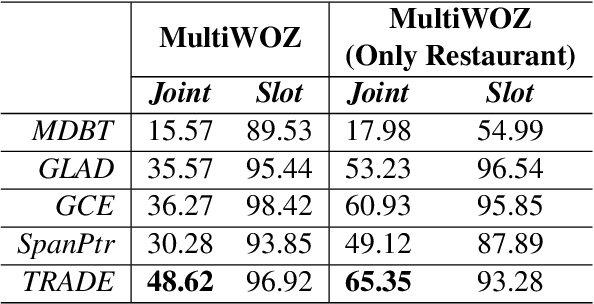
Over-dependence on domain ontology and lack of knowledge sharing across domains are two practical and yet less studied problems of dialogue state tracking. Existing approaches generally fall short in tracking unknown slot values during inference and often have difficulties in adapting to new domains. In this paper, we propose a Transferable Dialogue State Generator (TRADE) that generates dialogue states from utterances using a copy mechanism, facilitating knowledge transfer when predicting (domain, slot, value) triplets not encountered during training. Our model is composed of an utterance encoder, a slot gate, and a state generator, which are shared across domains. Empirical results demonstrate that TRADE achieves state-of-the-art joint goal accuracy of 48.62% for the five domains of MultiWOZ, a human-human dialogue dataset. In addition, we show its transferring ability by simulating zero-shot and few-shot dialogue state tracking for unseen domains. TRADE achieves 60.58% joint goal accuracy in one of the zero-shot domains, and is able to adapt to few-shot cases without forgetting already trained domains.
Personalizing Dialogue Agents via Meta-Learning
May 24, 2019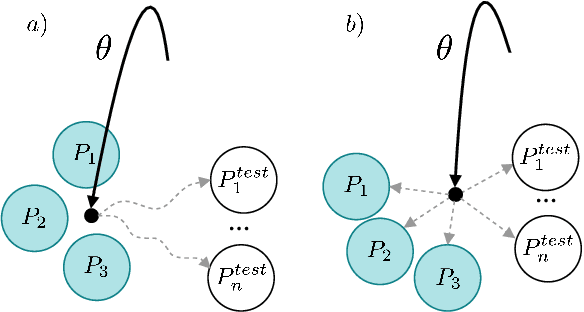
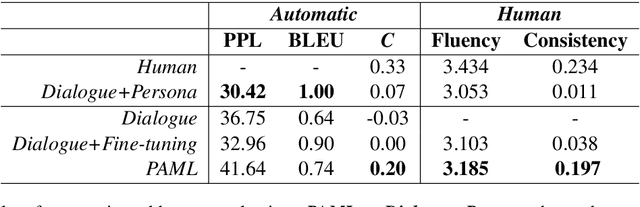
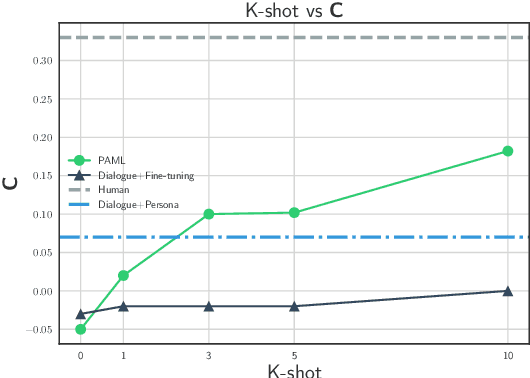
Existing personalized dialogue models use human designed persona descriptions to improve dialogue consistency. Collecting such descriptions from existing dialogues is expensive and requires hand-crafted feature designs. In this paper, we propose to extend Model-Agnostic Meta-Learning (MAML)(Finn et al., 2017) to personalized dialogue learning without using any persona descriptions. Our model learns to quickly adapt to new personas by leveraging only a few dialogue samples collected from the same user, which is fundamentally different from conditioning the response on the persona descriptions. Empirical results on Persona-chat dataset (Zhang et al., 2018) indicate that our solution outperforms non-meta-learning baselines using automatic evaluation metrics, and in terms of human-evaluated fluency and consistency.
A novel repetition normalized adversarial reward for headline generation
Feb 19, 2019



While reinforcement learning can effectively improve language generation models, it often suffers from generating incoherent and repetitive phrases \cite{paulus2017deep}. In this paper, we propose a novel repetition normalized adversarial reward to mitigate these problems. Our repetition penalized reward can greatly reduce the repetition rate and adversarial training mitigates generating incoherent phrases. Our model significantly outperforms the baseline model on ROUGE-1\,(+3.24), ROUGE-L\,(+2.25), and a decreased repetition-rate (-4.98\%).