 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Transformers for Diverse Response Generation
Mar 28, 2020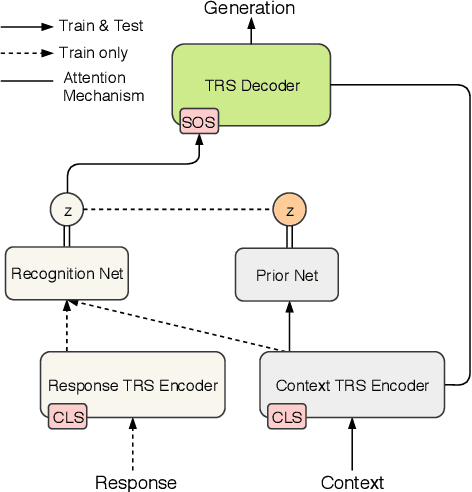
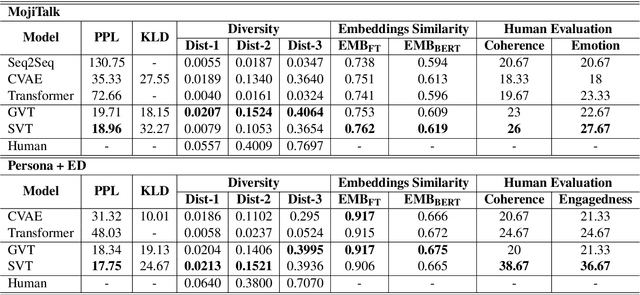
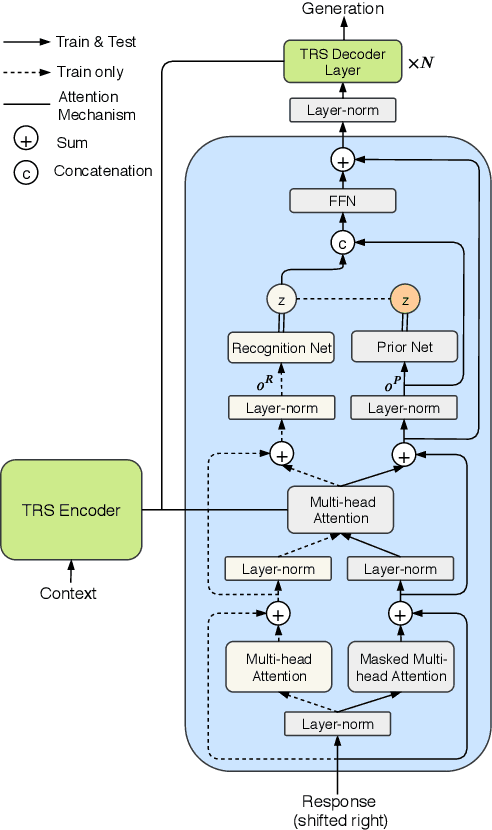
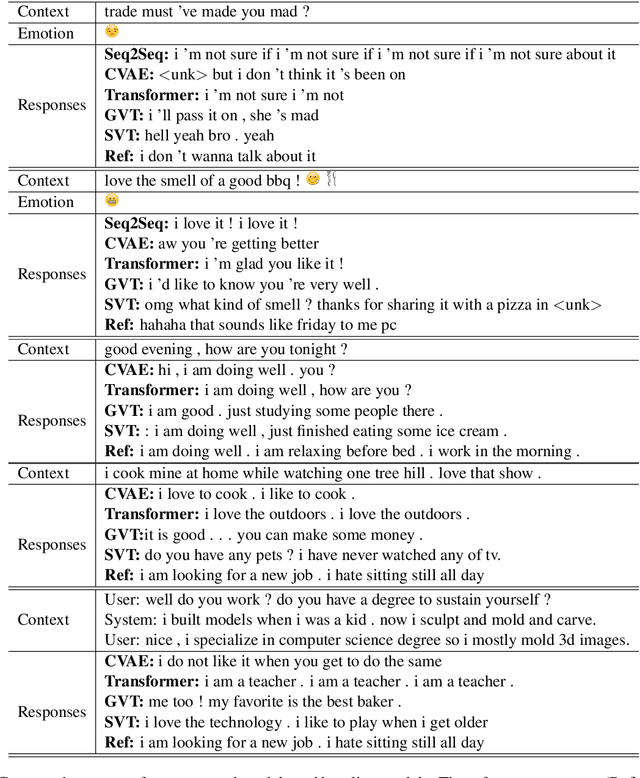
Despite the great promise of Transformers in many sequence modeling tasks (e.g., machine translation), their deterministic nature hinders them from generalizing to high entropy tasks such as dialogue response generation. Previous work proposes to capture the variability of dialogue responses with a recurrent neural network (RNN)-based conditional variational autoencoder (CVAE). However, the autoregressive computation of the RNN limits the training efficiency. Therefore, we propose the Variational Transformer (VT), a variational self-attentive feed-forward sequence model. The VT combines the parallelizability and global receptive field of the Transformer with the variational nature of the CVAE by incorporating stochastic latent variables into Transformers. We explore two types of the VT: 1) modeling the discourse-level diversity with a global latent variable; and 2) augmenting the Transformer decoder with a sequence of fine-grained latent variables. Then, the proposed models are evaluated on three conversational datasets with both automatic metric and human evaluation. The experimental results show that our models improve standard Transformers and other baselines in terms of diversity, semantic relevance, and human judgment.
Do We Need Word Order Information for Cross-lingual Sequence Labeling
Feb 26, 2020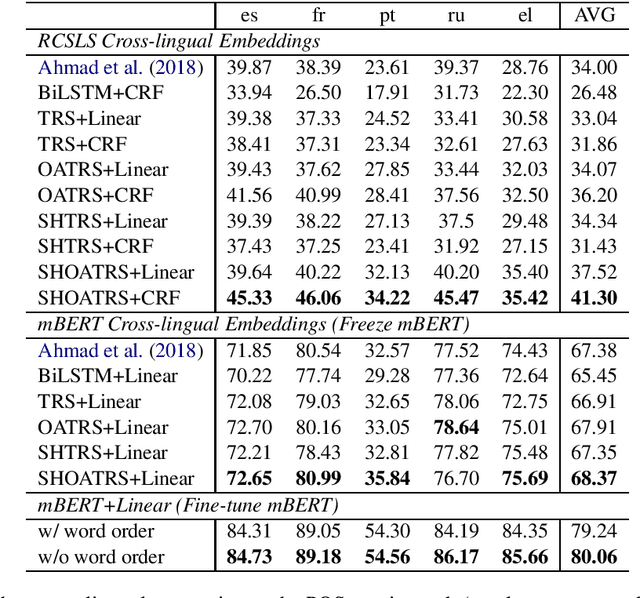
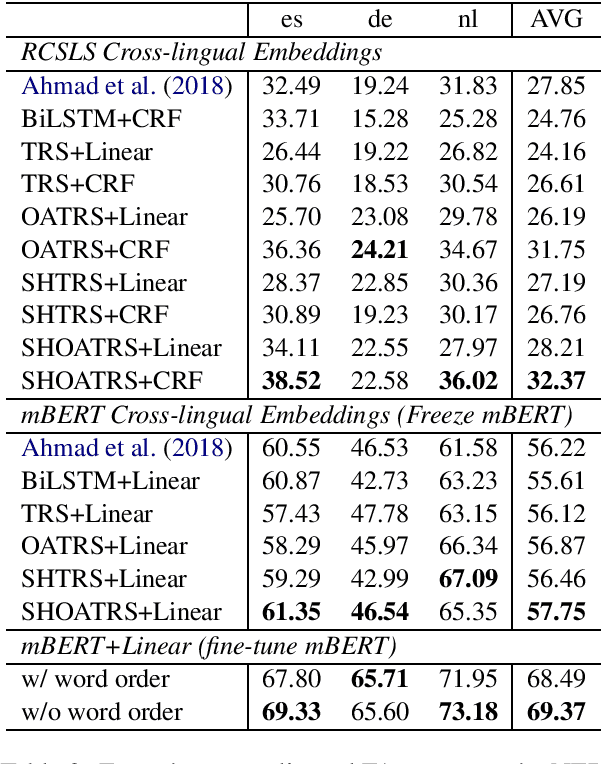
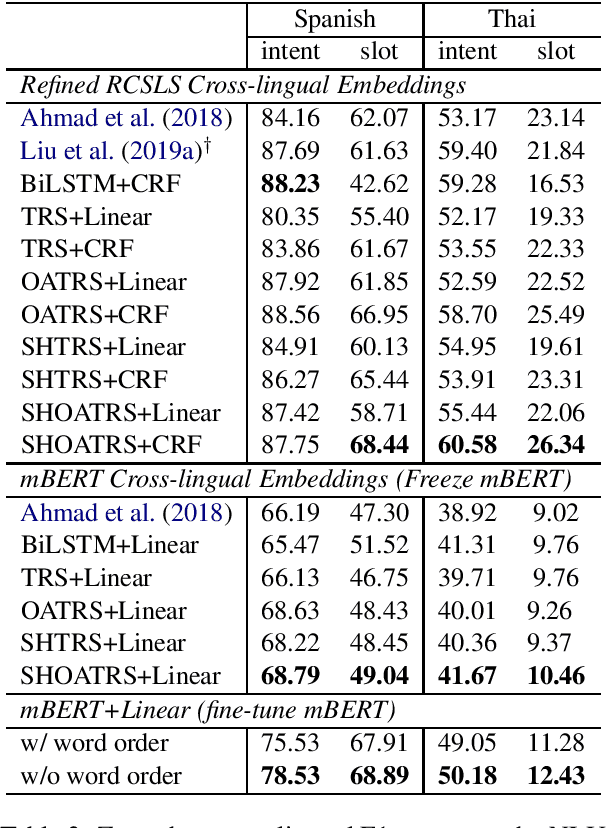
Most of the recent work in cross-lingual adaptation does not consider the word order variances in different languages. We hypothesize that cross-lingual models that fit into the source language word order might fail to handle target languages whose word orders are different. To test our conjecture, we build an order-agnostic model for cross-lingual sequence labeling tasks. Our model does not encode the word order information of the input sequences, and the predictions for each token are based on the attention on the whole sequence. Experimental results on dialogue natural language understanding, part-of-speech tagging, and named entity recognition tasks show that getting rid of word order information is able to achieve better zero-shot cross-lingual performance than baseline models.
Zero-Resource Cross-Domain Named Entity Recognition
Feb 14, 2020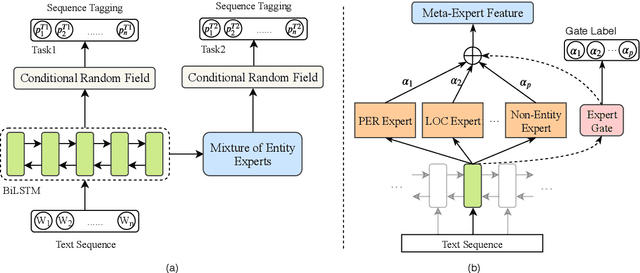
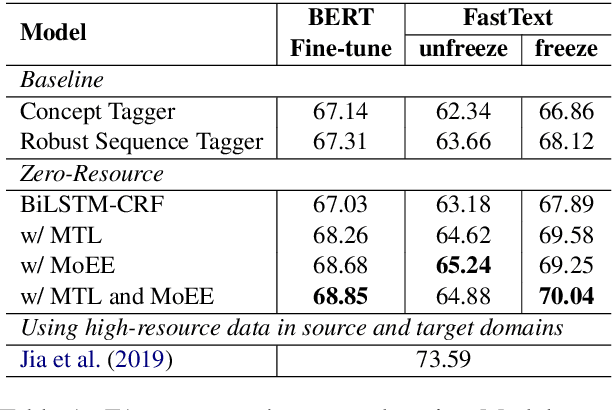
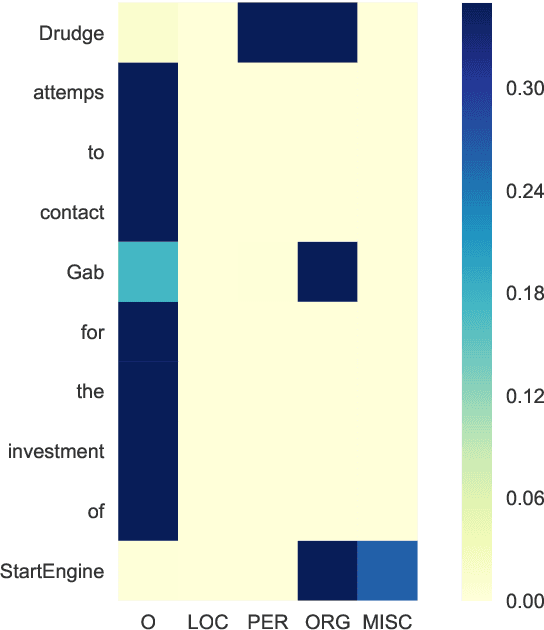
Existing models for cross-domain named entity recognition (NER) rely on numerous unlabeled corpus or labeled NER training data in target domains. However, collecting data for low-resource target domains is not only expensive but also time-consuming. Hence, we propose a cross-domain NER model that does not use any external resources. We first introduce Multi-Task Learning (MTL) by adding a new objective function to detect whether tokens are named entities or not. We then introduce a framework called Mixture of Entity Experts (MoEE) to improve the robustness for zero-resource domain adaptation. Finally, experimental results show that our model outperforms strong unsupervised cross-domain sequence labeling models, and the performance of our model is close to that of the state-of-the-art model which leverages extensive resources.
Attention over Parameters for Dialogue Systems
Jan 07, 2020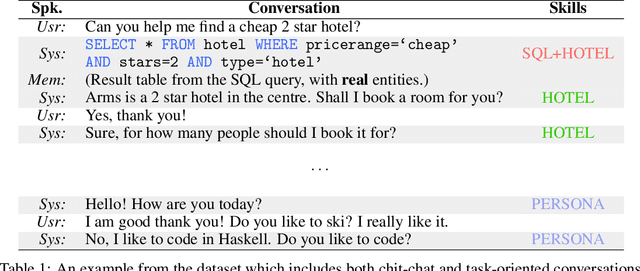
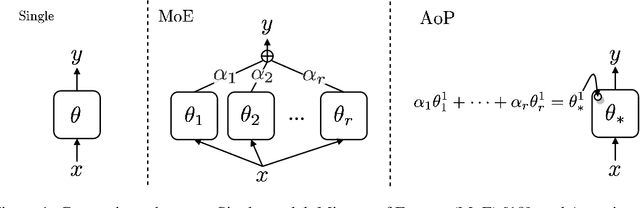
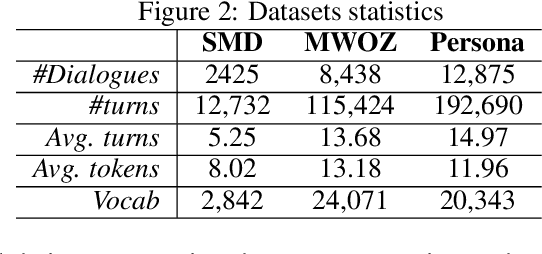
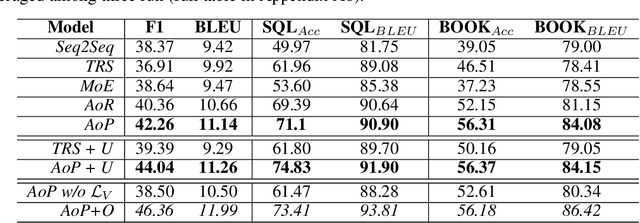
Dialogue systems require a great deal of different but complementary expertise to assist, inform, and entertain humans. For example, different domains (e.g., restaurant reservation, train ticket booking) of goal-oriented dialogue systems can be viewed as different skills, and so does ordinary chatting abilities of chit-chat dialogue systems. In this paper, we propose to learn a dialogue system that independently parameterizes different dialogue skills, and learns to select and combine each of them through Attention over Parameters (AoP). The experimental results show that this approach achieves competitive performance on a combined dataset of MultiWOZ, In-Car Assistant, and Persona-Chat. Finally, we demonstrate that each dialogue skill is effectively learned and can be combined with other skills to produce selective responses.
Attention-Informed Mixed-Language Training for Zero-shot Cross-lingual Task-oriented Dialogue Systems
Nov 21, 2019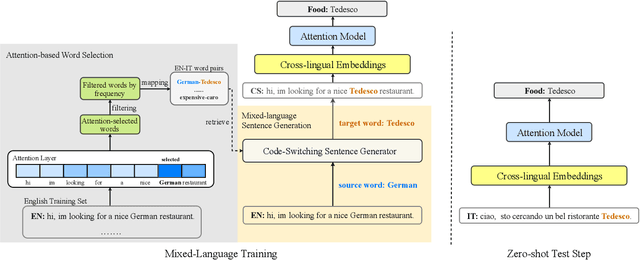
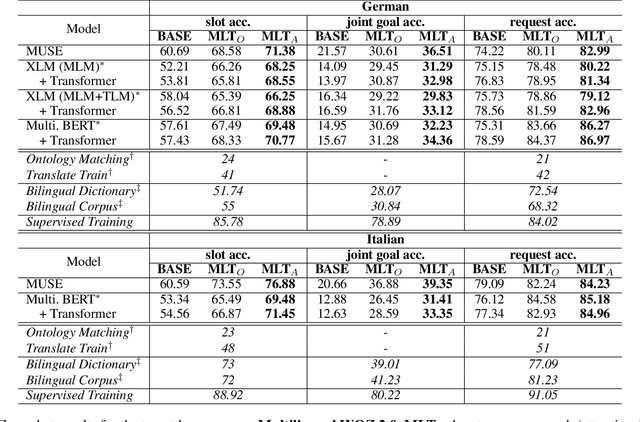
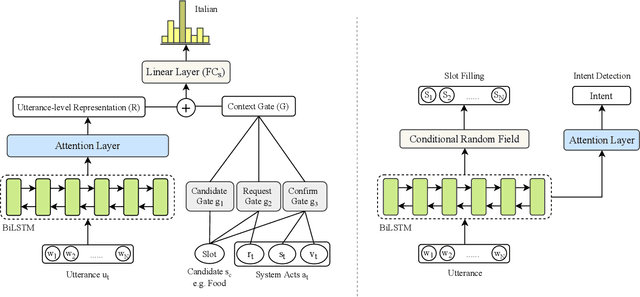
Recently, data-driven task-oriented dialogue systems have achieved promising performance in English. However, developing dialogue systems that support low-resource languages remains a long-standing challenge due to the absence of high-quality data. In order to circumvent the expensive and time-consuming data collection, we introduce Attention-Informed Mixed-Language Training (MLT), a novel zero-shot adaptation method for cross-lingual task-oriented dialogue systems. It leverages very few task-related parallel word pairs to generate code-switching sentences for learning the inter-lingual semantics across languages. Instead of manually selecting the word pairs, we propose to extract source words based on the scores computed by the attention layer of a trained English task-related model and then generate word pairs using existing bilingual dictionaries. Furthermore, intensive experiments with different cross-lingual embeddings demonstrate the effectiveness of our approach. Finally, with very few word pairs, our model achieves significant zero-shot adaptation performance improvements in both cross-lingual dialogue state tracking and natural language understanding (i.e., intent detection and slot filling) tasks compared to the current state-of-the-art approaches, which utilize a much larger amount of bilingual data.
Zero-shot Cross-lingual Dialogue Systems with Transferable Latent Variables
Nov 11, 2019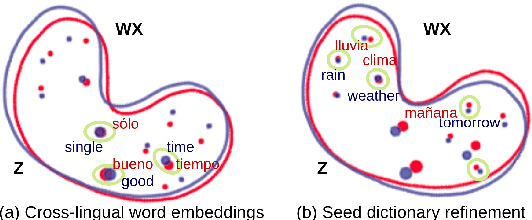
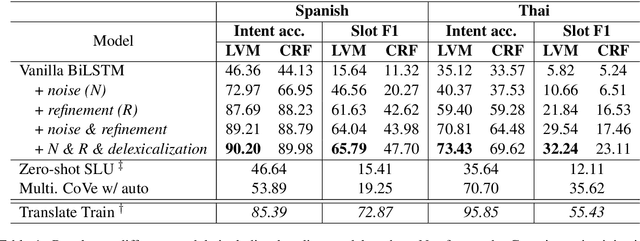
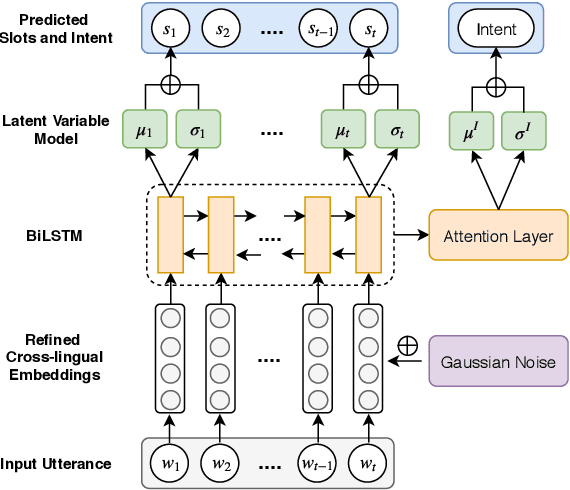
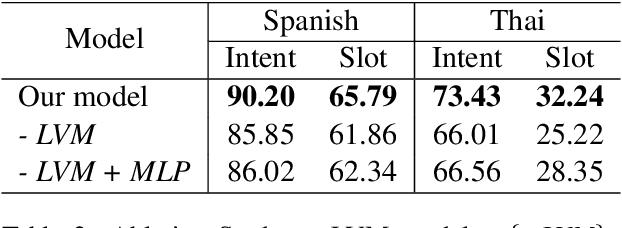
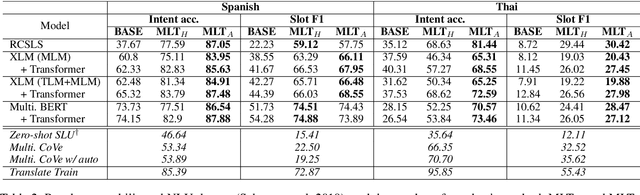
Despite the surging demands for multilingual task-oriented dialog systems (e.g., Alexa, Google Home), there has been less research done in multilingual or cross-lingual scenarios. Hence, we propose a zero-shot adaptation of task-oriented dialogue system to low-resource languages. To tackle this challenge, we first use a set of very few parallel word pairs to refine the aligned cross-lingual word-level representations. We then employ a latent variable model to cope with the variance of similar sentences across different languages, which is induced by imperfect cross-lingual alignments and inherent differences in languages. Finally, the experimental results show that even though we utilize much less external resources, our model achieves better adaptation performance for natural language understanding task (i.e., the intent detection and slot filling) compared to the current state-of-the-art model in the zero-shot scenario.
Lightweight and Efficient End-to-End Speech Recognition Using Low-Rank Transformer
Oct 30, 2019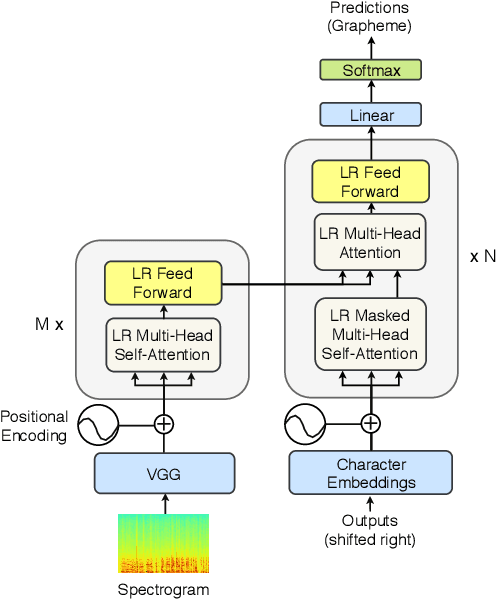
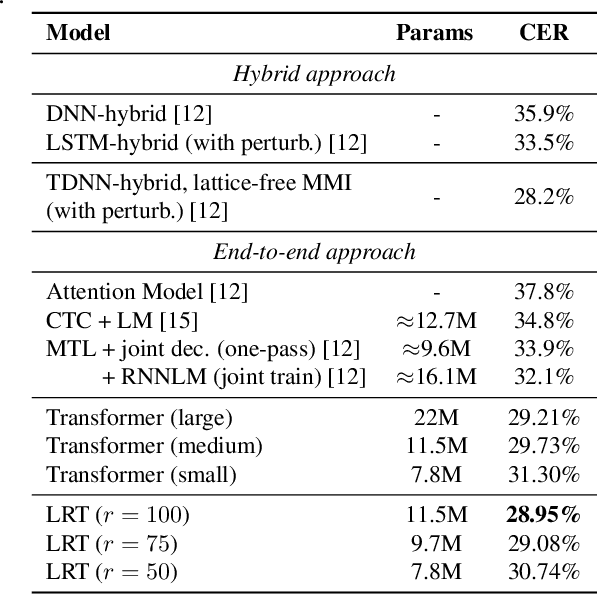
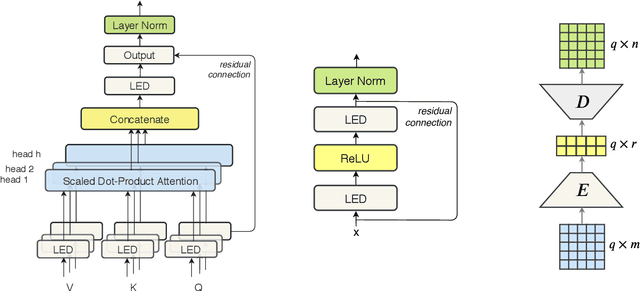
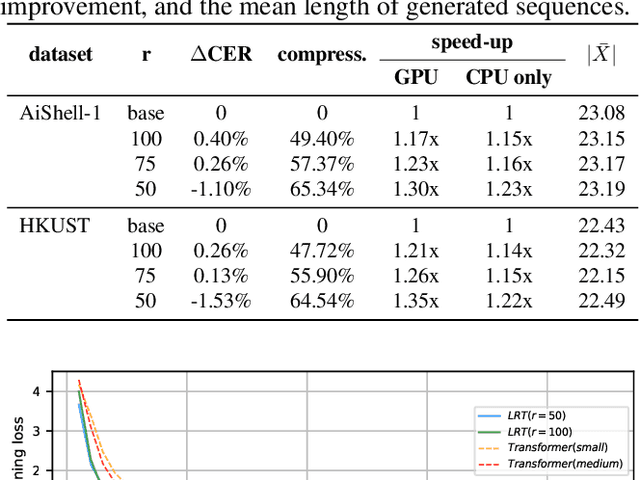
High performing deep neural networks come at the cost of computational complexity that limits its practicality for deployment on portable devices. We propose Low-Rank Transformer (LRT), a memory-efficient and fast neural architecture that significantly reduces the parameters and boosts the speed in training and inference for end-to-end speech recognition. Our approach reduces the number of parameters of the network by more than 50% parameters and speed-up the inference time by around 1.26x compared to the baseline transformer model. The experiments show that LRT models generalize better and yield lower error rates on both validation and test sets compared to the uncompressed transformer model. LRT models outperform existing works on several datasets in an end-to-end setting without using any external language model and acoustic data.
Code-Switched Language Models Using Neural Based Synthetic Data from Parallel Sentences
Sep 18, 2019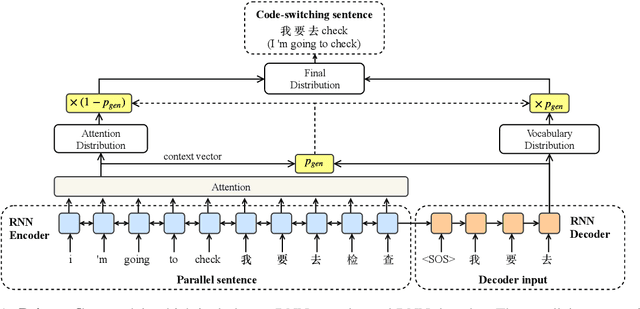
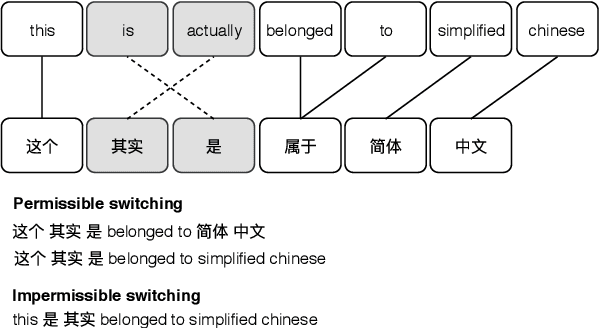
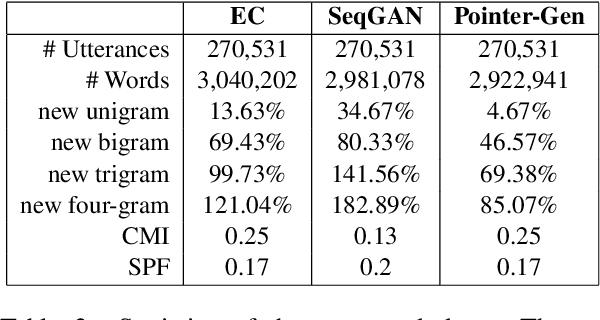
Training code-switched language models is difficult due to lack of data and complexity in the grammatical structure. Linguistic constraint theories have been used for decades to generate artificial code-switching sentences to cope with this issue. However, this require external word alignments or constituency parsers that create erroneous results on distant languages. We propose a sequence-to-sequence model using a copy mechanism to generate code-switching data by leveraging parallel monolingual translations from a limited source of code-switching data. The model learns how to combine words from parallel sentences and identifies when to switch one language to the other. Moreover, it captures code-switching constraints by attending and aligning the words in inputs, without requiring any external knowledge. Based on experimental results, the language model trained with the generated sentences achieves state-of-the-art performance and improves end-to-end automatic speech recognition.
Hierarchical Meta-Embeddings for Code-Switching Named Entity Recognition
Sep 18, 2019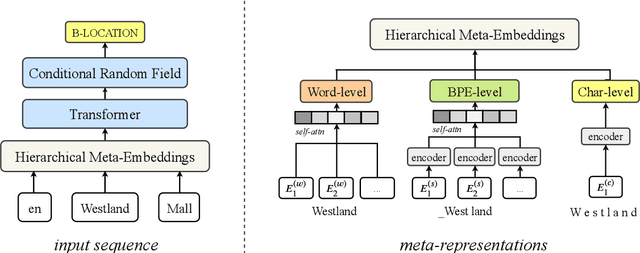
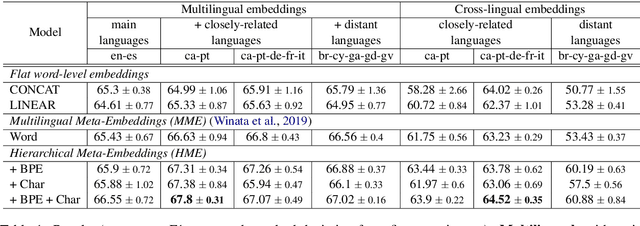
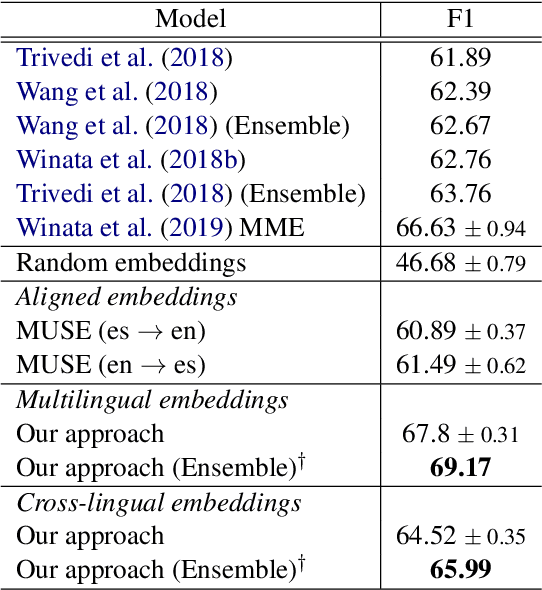
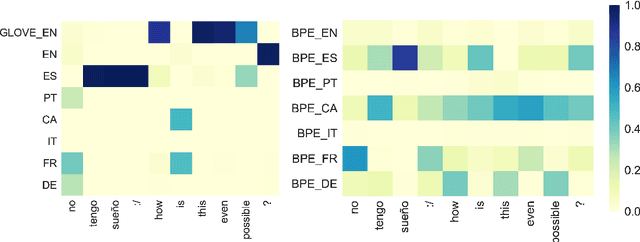
In countries that speak multiple main languages, mixing up different languages within a conversation is commonly called code-switching. Previous works addressing this challenge mainly focused on word-level aspects such as word embeddings. However, in many cases, languages share common subwords, especially for closely related languages, but also for languages that are seemingly irrelevant. Therefore, we propose Hierarchical Meta-Embeddings (HME) that learn to combine multiple monolingual word-level and subword-level embeddings to create language-agnostic lexical representations. On the task of Named Entity Recognition for English-Spanish code-switching data, our model achieves the state-of-the-art performance in the multilingual settings. We also show that, in cross-lingual settings, our model not only leverages closely related languages, but also learns from languages with different roots. Finally, we show that combining different subunits are crucial for capturing code-switching entities.
Clickbait? Sensational Headline Generation with Auto-tuned Reinforcement Learning
Sep 09, 2019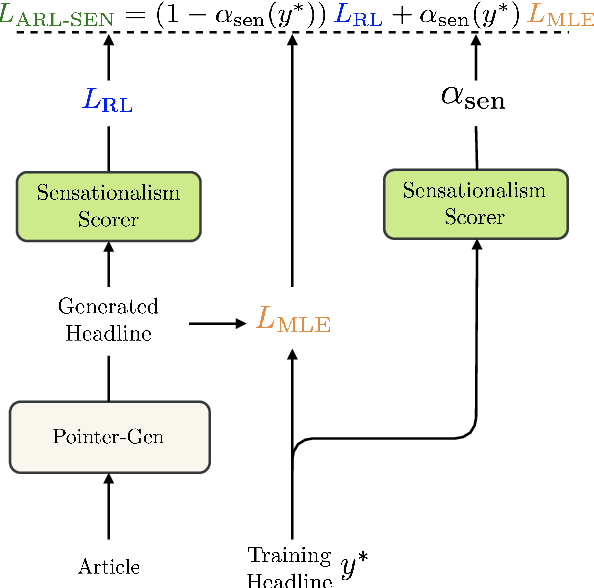
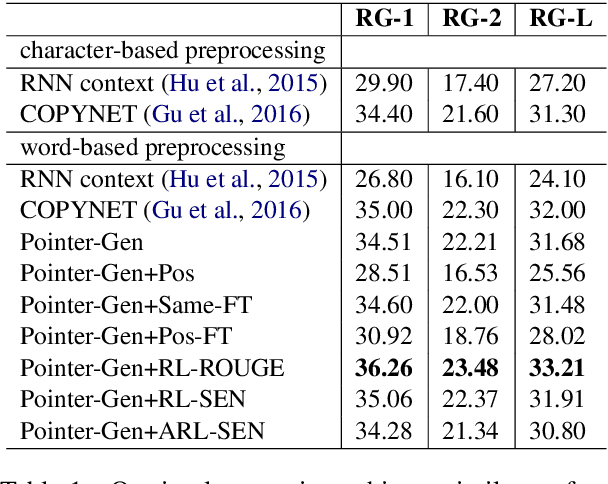
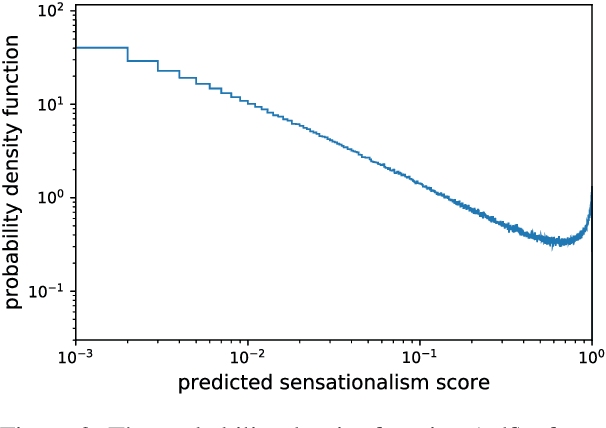
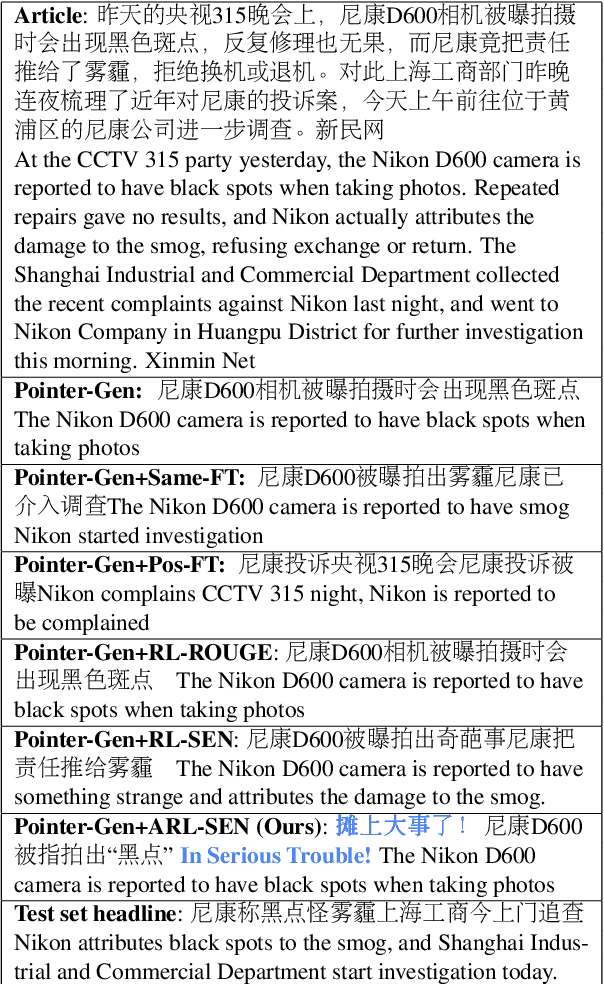
Sensational headlines are headlines that capture people's attention and generate reader interest. Conventional abstractive headline generation methods, unlike human writers, do not optimize for maximal reader attention. In this paper, we propose a model that generates sensational headlines without labeled data. We first train a sensationalism scorer by classifying online headlines with many comments ("clickbait") against a baseline of headlines generated from a summarization model. The score from the sensationalism scorer is used as the reward for a reinforcement learner. However, maximizing the noisy sensationalism reward will generate unnatural phrases instead of sensational headlines. To effectively leverage this noisy reward, we propose a novel loss function, Auto-tuned Reinforcement Learning (ARL), to dynamically balance reinforcement learning (RL) with maximum likelihood estimation (MLE). Human evaluation shows that 60.8% of samples generated by our model are sensational, which is significantly better than the Pointer-Gen baseline and other RL models.