 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers
Nov 27, 2020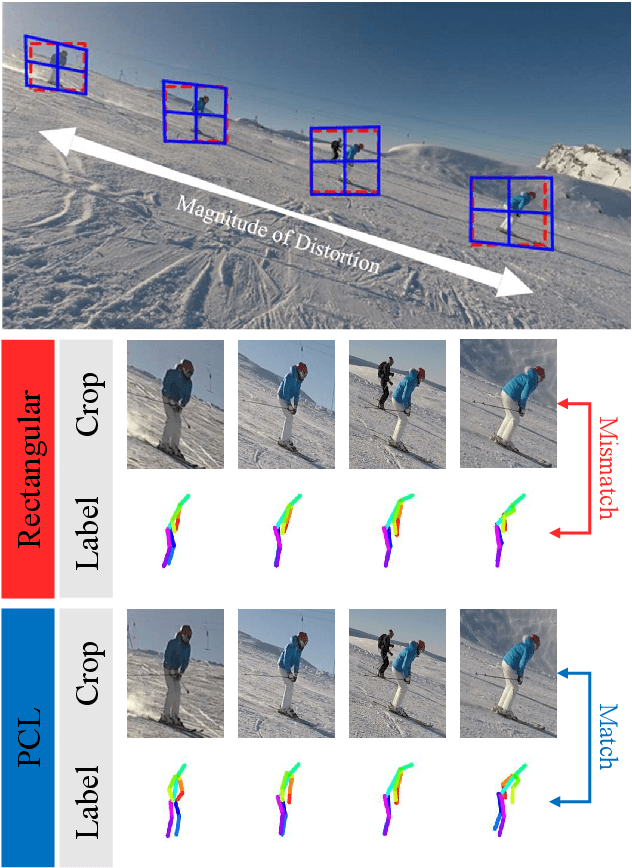
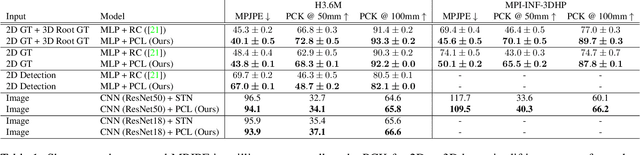
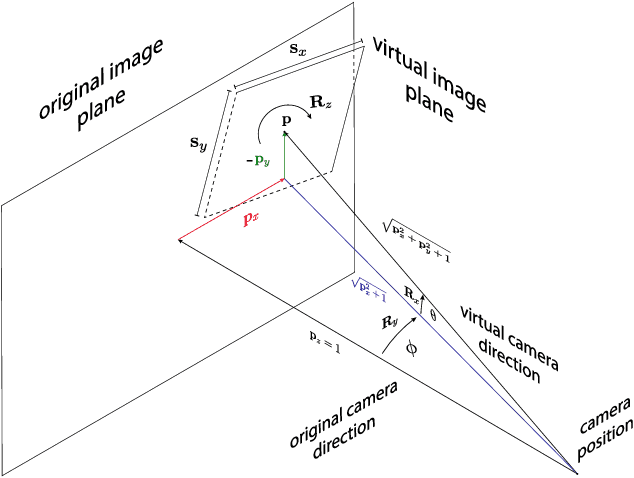

Local processing is an essential feature of CNNs and other neural network architectures - it is one of the reasons why they work so well on images where relevant information is, to a large extent, local. However, perspective effects stemming from the projection in a conventional camera vary for different global positions in the image. We introduce Perspective Crop Layers (PCLs) - a form of perspective crop of the region of interest based on the camera geometry - and show that accounting for the perspective consistently improves the accuracy of state-of-the-art 3D pose reconstruction methods. PCLs are modular neural network layers, which, when inserted into existing CNN and MLP architectures, deterministically remove the location-dependent perspective effects while leaving end-to-end training and the number of parameters of the underlying neural network unchanged. We demonstrate that PCL leads to improved 3D human pose reconstruction accuracy for CNN architectures that use cropping operations, such as spatial transformer networks (STN), and, somewhat surprisingly, MLPs used for 2D-to-3D keypoint lifting. Our conclusion is that it is important to utilize camera calibration information when available, for classical and deep-learning-based computer vision alike. PCL offers an easy way to improve the accuracy of existing 3D reconstruction networks by making them geometry-aware.
A Closed-Form Solution to Local Non-Rigid Structure-from-Motion
Nov 23, 2020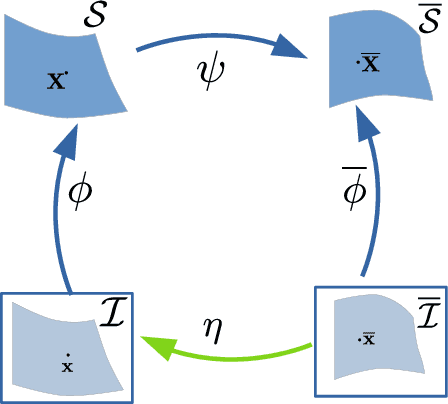
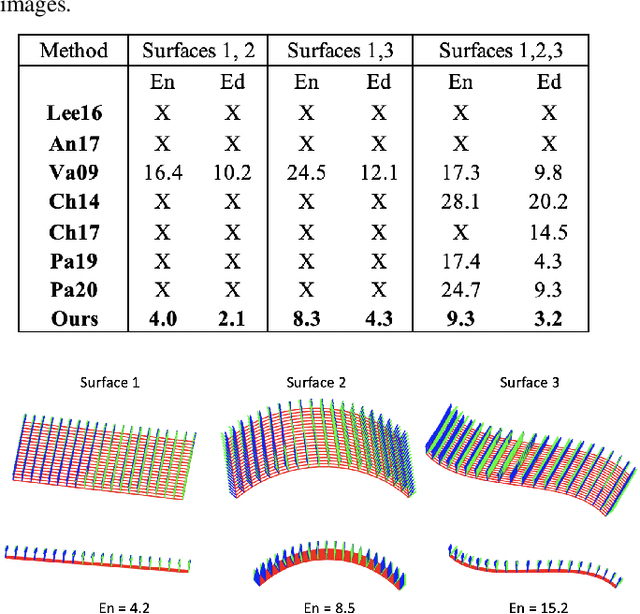

A recent trend in Non-Rigid Structure-from-Motion (NRSfM) is to express local, differential constraints between pairs of images, from which the surface normal at any point can be obtained by solving a system of polynomial equations. The systems of equations derived in previous work, however, are of high degree, having up to five real solutions, thus requiring a computationally expensive strategy to select a unique solution. Furthermore, they suffer from degeneracies that make the resulting estimates unreliable, without any mechanism to identify this situation. In this paper, we show that, under widely applicable assumptions, we can derive a new system of equation in terms of the surface normals whose two solutions can be obtained in closed-form and can easily be disambiguated locally. Our formalism further allows us to assess how reliable the estimated local normals are and, hence, to discard them if they are not. Our experiments show that our reconstructions, obtained from two or more views, are significantly more accurate than those of state-of-the-art methods, while also being faster.
Deep Active Surface Models
Nov 20, 2020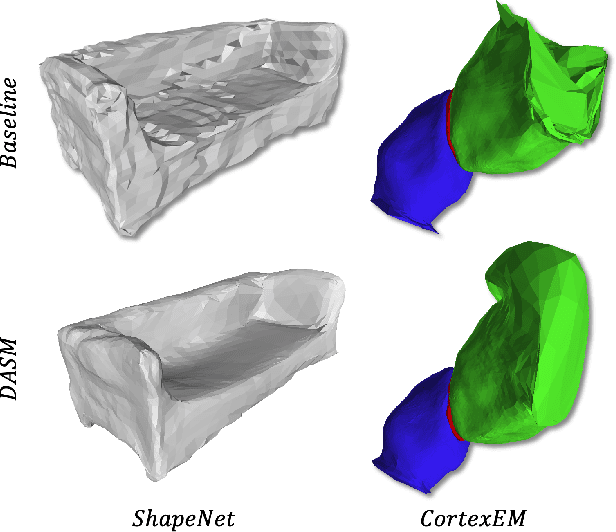
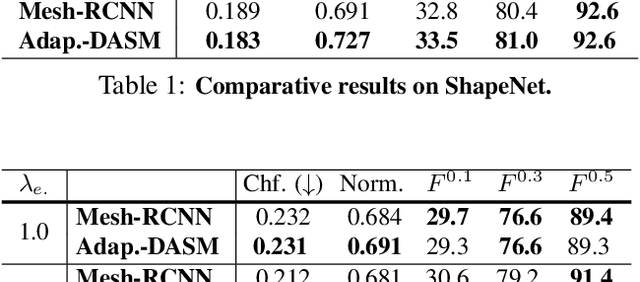
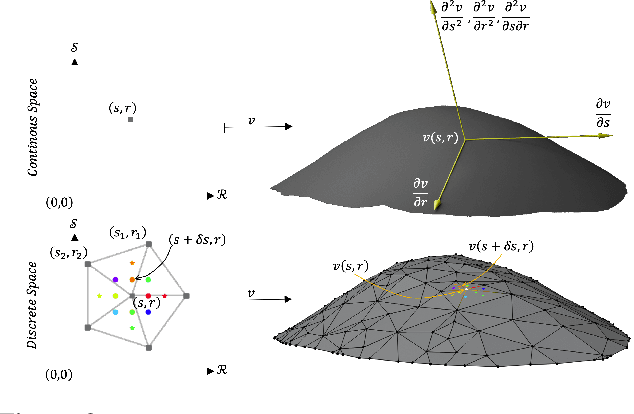
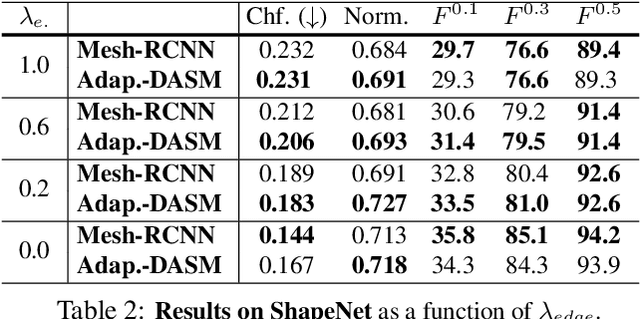
Active Surface Models have a long history of being useful to model complex 3D surfaces but only Active Contours have been used in conjunction with deep networks, and then only to produce the data term as well as meta-parameter maps controlling them. In this paper, we advocate a much tighter integration. We introduce layers that implement them that can be integrated seamlessly into Graph Convolutional Networks to enforce sophisticated smoothness priors at an acceptable computational cost. We will show that the resulting Deep Active Surface Models outperform equivalent architectures that use traditional regularization loss terms to impose smoothness priors for 3D surface reconstruction from 2D images and for 3D volume segmentation.
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
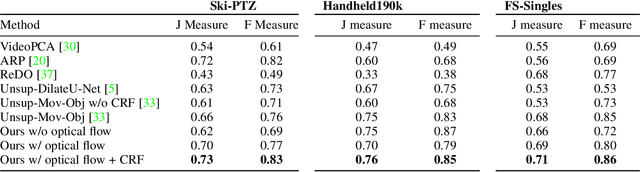
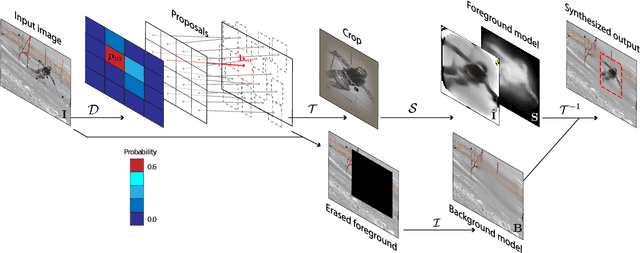

While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
Better Patch Stitching for Parametric Surface Reconstruction
Oct 14, 2020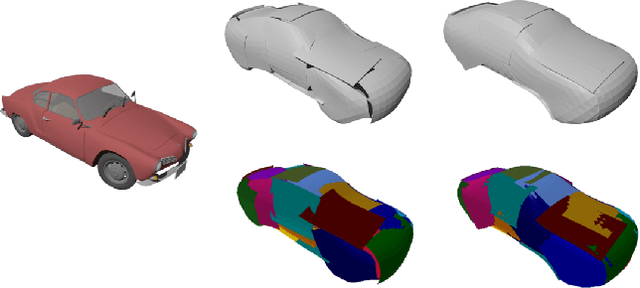
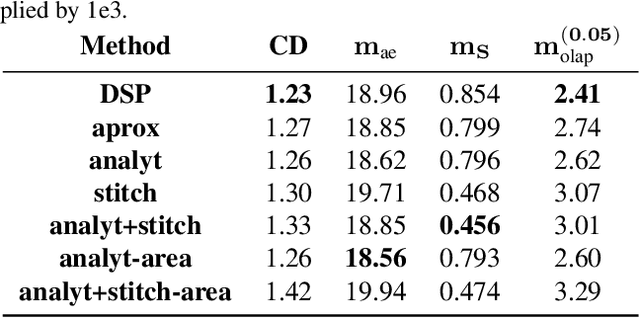
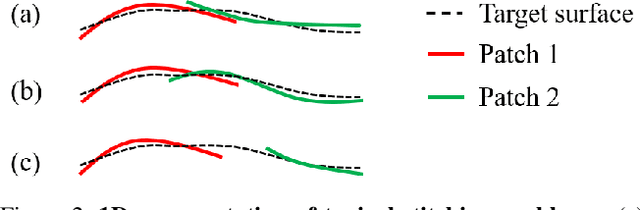
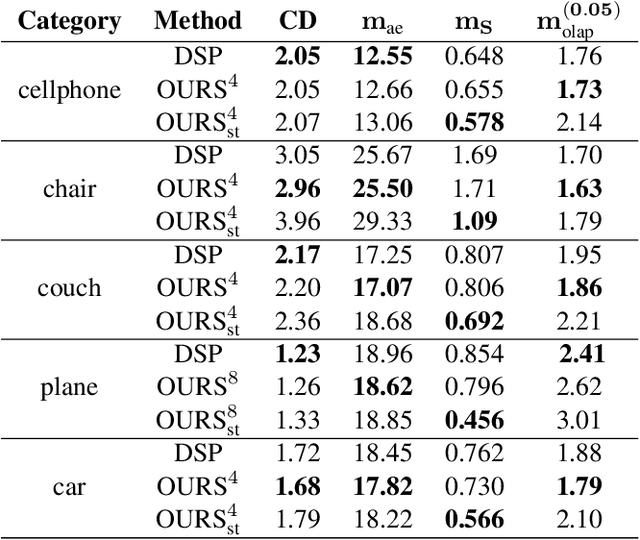
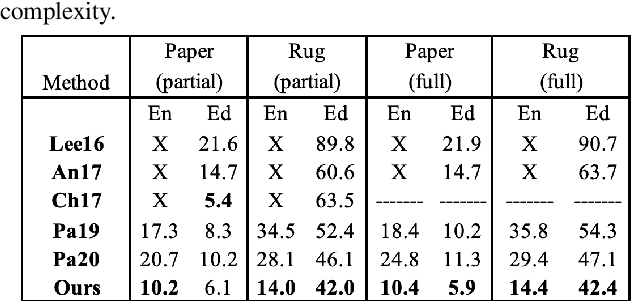
Recently, parametric mappings have emerged as highly effective surface representations, yielding low reconstruction error. In particular, the latest works represent the target shape as an atlas of multiple mappings, which can closely encode object parts. Atlas representations, however, suffer from one major drawback: The individual mappings are not guaranteed to be consistent, which results in holes in the reconstructed shape or in jagged surface areas. We introduce an approach that explicitly encourages global consistency of the local mappings. To this end, we introduce two novel loss terms. The first term exploits the surface normals and requires that they remain locally consistent when estimated within and across the individual mappings. The second term further encourages better spatial configuration of the mappings by minimizing novel stitching error. We show on standard benchmarks that the use of normal consistency requirement outperforms the baselines quantitatively while enforcing better stitching leads to much better visual quality of the reconstructed objects as compared to the state-of-the-art.
Motion Prediction Using Temporal Inception Module
Oct 06, 2020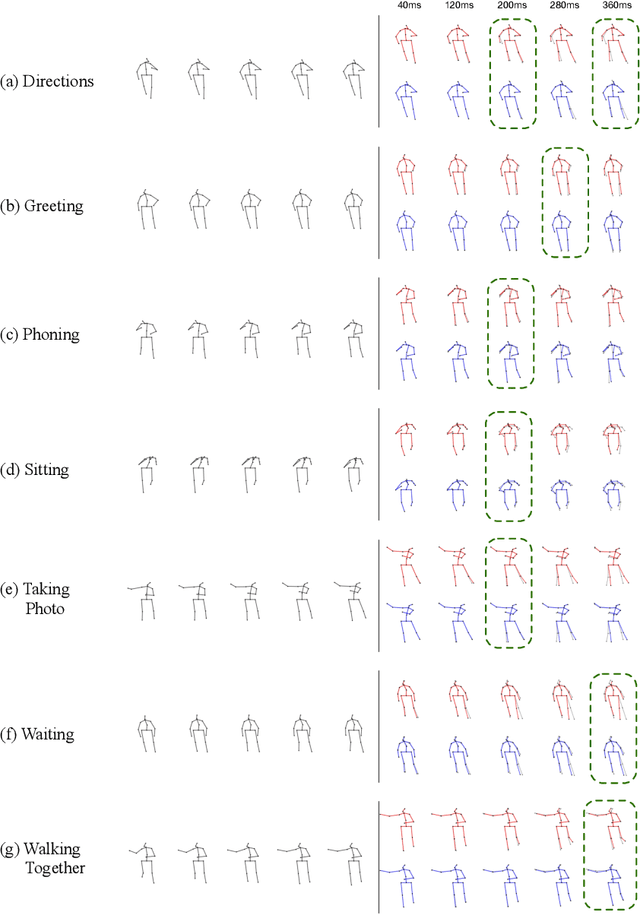
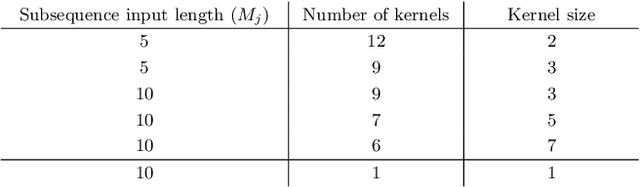
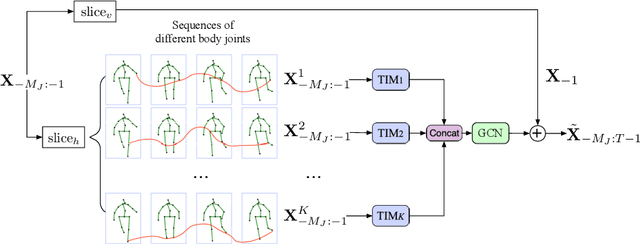
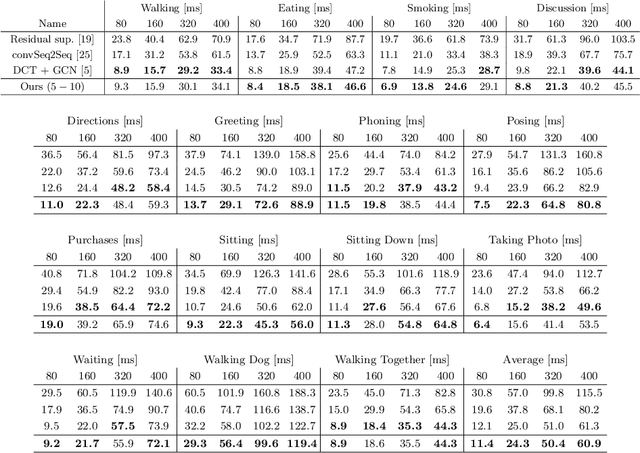
Human motion prediction is a necessary component for many applications in robotics and autonomous driving. Recent methods propose using sequence-to-sequence deep learning models to tackle this problem. However, they do not focus on exploiting different temporal scales for different length inputs. We argue that the diverse temporal scales are important as they allow us to look at the past frames with different receptive fields, which can lead to better predictions. In this paper, we propose a Temporal Inception Module (TIM) to encode human motion. Making use of TIM, our framework produces input embeddings using convolutional layers, by using different kernel sizes for different input lengths. The experimental results on standard motion prediction benchmark datasets Human3.6M and CMU motion capture dataset show that our approach consistently outperforms the state of the art methods.
Promoting Connectivity of Network-Like Structures by Enforcing Region Separation
Sep 15, 2020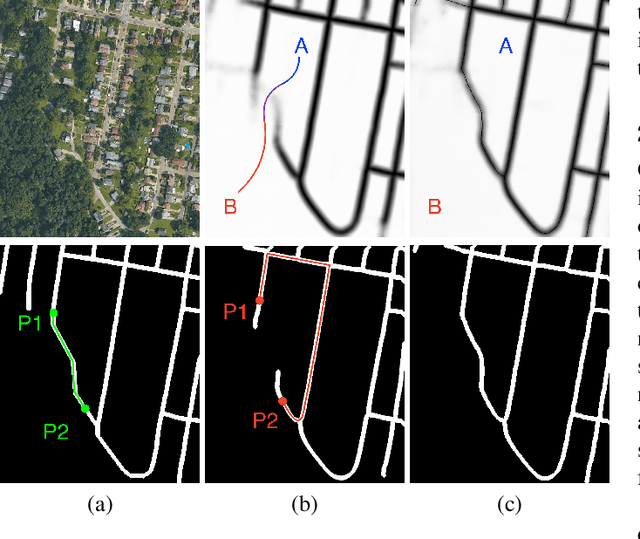
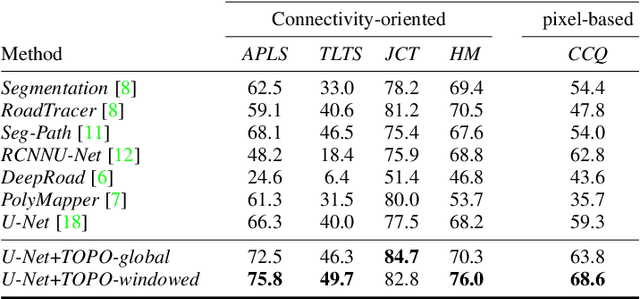
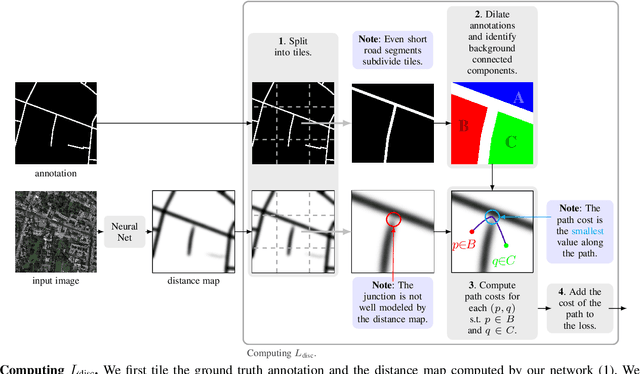
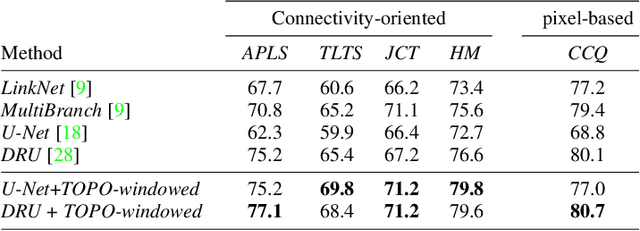
We propose a novel, connectivity-oriented loss function for training deep convolutional networks to reconstruct network-like structures, like roads and irrigation canals, from aerial images. The main idea behind our loss is to express the connectivity of roads, or canals, in terms of disconnections that they create between background regions of the image. In simple terms, a gap in the predicted road causes two background regions, that lie on the opposite sides of a ground truth road, to touch in prediction. Our loss function is designed to prevent such unwanted connections between background regions, and therefore close the gaps in predicted roads. It also prevents predicting false positive roads and canals by penalizing unwarranted disconnections of background regions. In order to capture even short, dead-ending road segments, we evaluate the loss in small image crops. We show, in experiments on two standard road benchmarks and a new data set of irrigation canals, that convnets trained with our loss function recover road connectivity so well, that it suffices to skeletonize their output to produce state of the art maps. A distinct advantage of our approach is that the loss can be plugged in to any existing training setup without further modifications.
GarNet++: Improving Fast and Accurate Static3D Cloth Draping by Curvature Loss
Jul 20, 2020
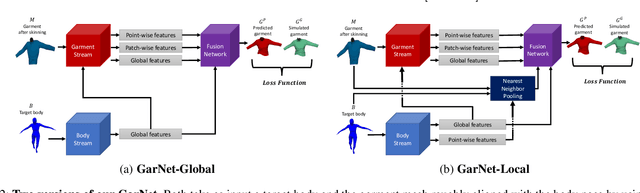
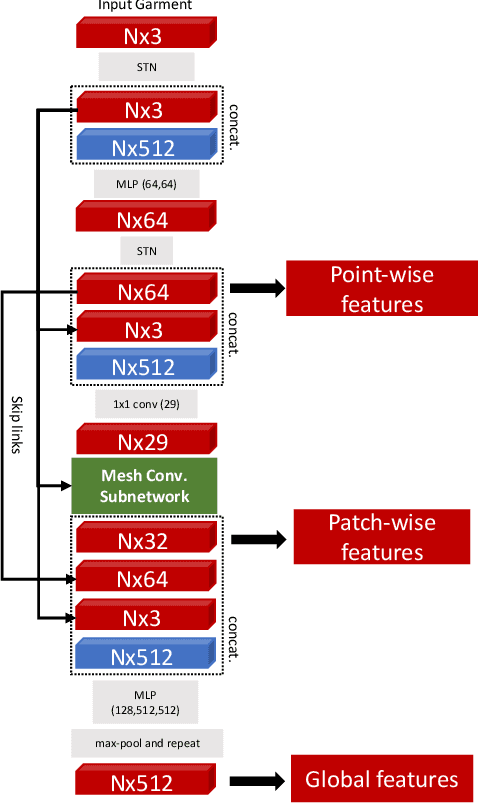
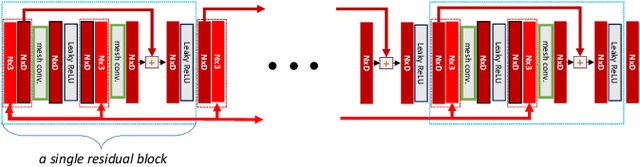
In this paper, we tackle the problem of static 3D cloth draping on virtual human bodies. We introduce a two-stream deep network model that produces a visually plausible draping of a template cloth on virtual 3D bodies by extracting features from both the body and garment shapes. Our network learns to mimic a Physics-Based Simulation (PBS) method while requiring two orders of magnitude less computation time. To train the network, we introduce loss terms inspired by PBS to produce plausible results and make the model collision-aware. To increase the details of the draped garment, we introduce two loss functions that penalize the difference between the curvature of the predicted cloth and PBS. Particularly, we study the impact of mean curvature normal and a novel detail-preserving loss both qualitatively and quantitatively. Our new curvature loss computes the local covariance matrices of the 3D points, and compares the Rayleigh quotients of the prediction and PBS. This leads to more details while performing favorably or comparably against the loss that considers mean curvature normal vectors in the 3D triangulated meshes. We validate our framework on four garment types for various body shapes and poses. Finally, we achieve superior performance against a recently proposed data-driven method.
TopoAL: An Adversarial Learning Approach for Topology-Aware Road Segmentation
Jul 17, 2020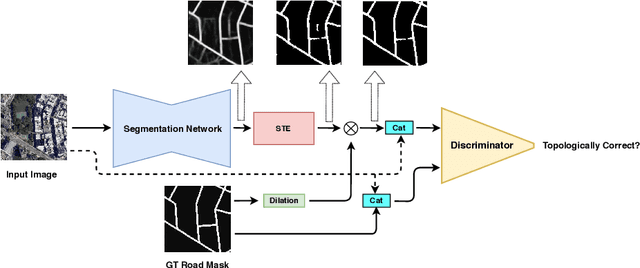
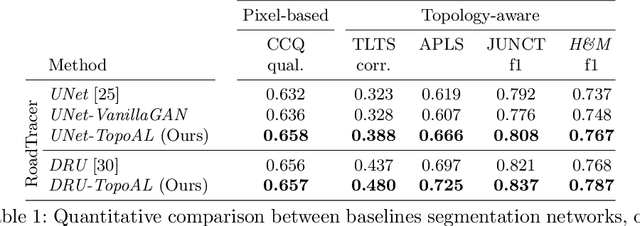

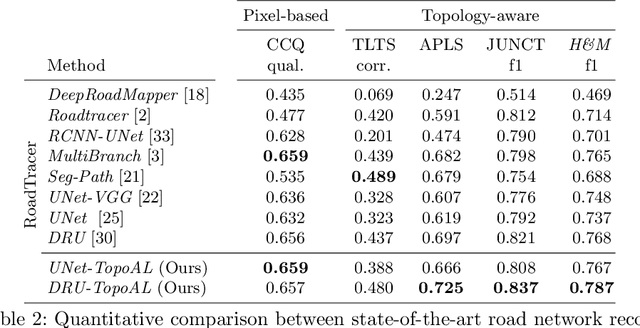
Most state-of-the-art approaches to road extraction from aerial images rely on a CNN trained to label road pixels as foreground and remainder of the image as background. The CNN is usually trained by minimizing pixel-wise losses, which is less than ideal to produce binary masks that preserve the road network's global connectivity. To address this issue, we introduce an Adversarial Learning (AL) strategy tailored for our purposes. A naive one would treat the segmentation network as a generator and would feed its output along with ground-truth segmentations to a discriminator. It would then train the generator and discriminator jointly. We will show that this is not enough because it does not capture the fact that most errors are local and need to be treated as such. Instead, we use a more sophisticated discriminator that returns a label pyramid describing what portions of the road network are correct at several different scales. This discriminator and the structured labels it returns are what gives our approach its edge and we will show that it outperforms state-of-the-art ones on the challenging RoadTracer dataset.
DISK: Learning local features with policy gradient
Jun 24, 2020
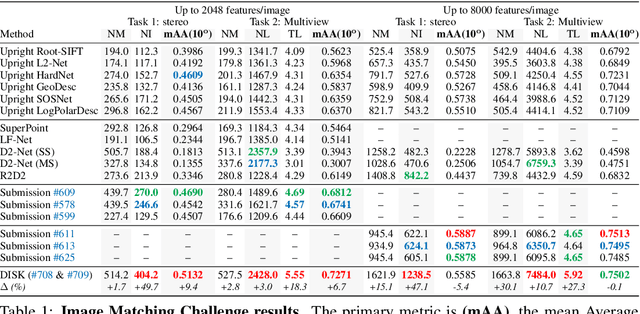

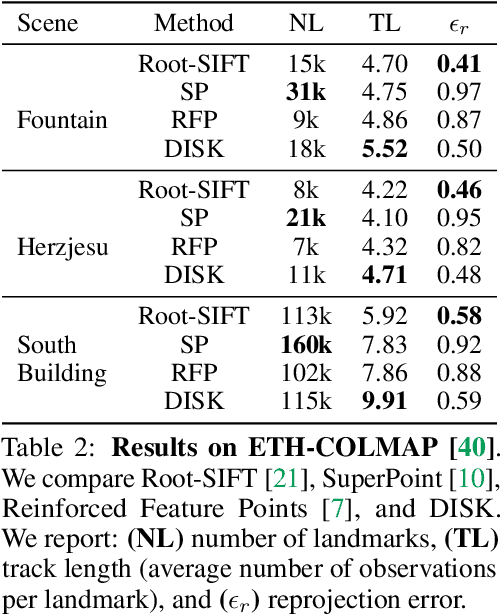
Local feature frameworks are difficult to learn in an end-to-end fashion, due to the discreteness inherent to the selection and matching of sparse keypoints. We introduce DISK (DIScrete Keypoints), a novel method that overcomes these obstacles by leveraging principles from Reinforcement Learning (RL), optimizing end-to-end for a high number of correct feature matches. Our simple yet expressive probabilistic model lets us keep the training and inference regimes close, while maintaining good enough convergence properties to reliably train from scratch. Our features can be extracted very densely while remaining discriminative, challenging commonly held assumptions about what constitutes a good keypoint, as showcased in Fig. 1, and deliver state-of-the-art results on three public benchmarks.