 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackpropagation-Friendly Eigendecomposition
Jun 27, 2019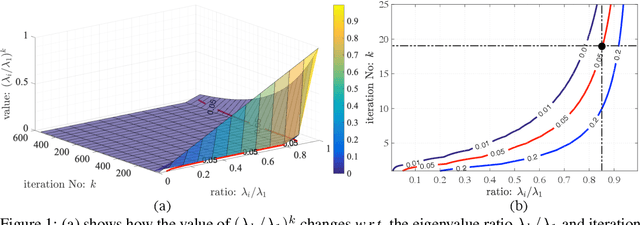
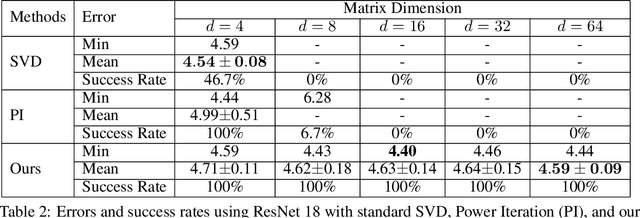
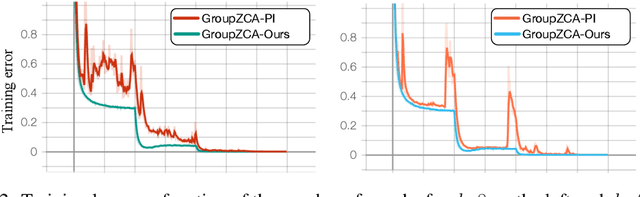

Eigendecomposition (ED) is widely used in deep networks. However, the backpropagation of its results tends to be numerically unstable, whether using ED directly or approximating it with the Power Iteration method, particularly when dealing with large matrices. While this can be mitigated by partitioning the data in small and arbitrary groups, doing so has no theoretical basis and makes its impossible to exploit the power of ED to the full. In this paper, we introduce a numerically stable and differentiable approach to leveraging eigenvectors in deep networks. It can handle large matrices without requiring to split them. We demonstrate the better robustness of our approach over standard ED and PI for ZCA whitening, an alternative to batch normalization, and for PCA denoising, which we introduce as a new normalization strategy for deep networks, aiming to further denoise the network's features.
Recurrent U-Net for Resource-Constrained Segmentation
Jun 11, 2019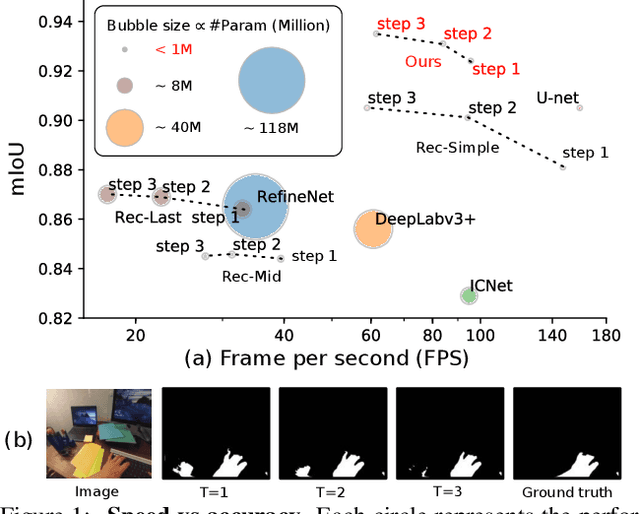
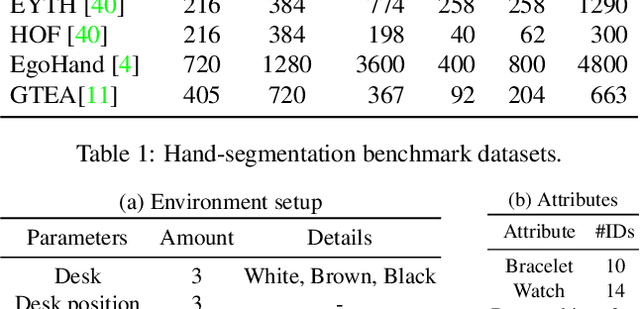
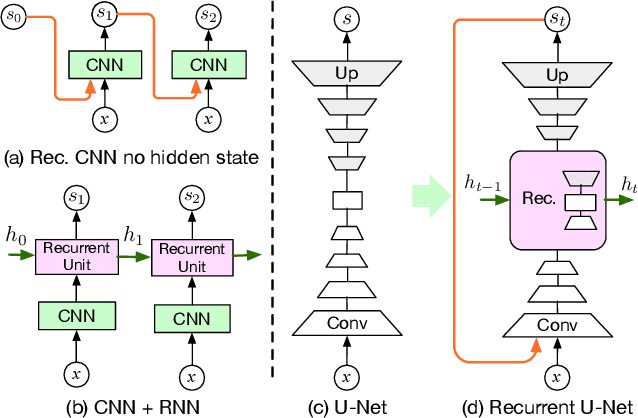

State-of-the-art segmentation methods rely on very deep networks that are not always easy to train without very large training datasets and tend to be relatively slow to run on standard GPUs. In this paper, we introduce a novel recurrent U-Net architecture that preserves the compactness of the original U-Net, while substantially increasing its performance to the point where it outperforms the state of the art on several benchmarks. We will demonstrate its effectiveness for several tasks, including hand segmentation, retina vessel segmentation, and road segmentation. We also introduce a large-scale dataset for hand segmentation.
Joint Segmentation and Path Classification of Curvilinear Structures
May 09, 2019
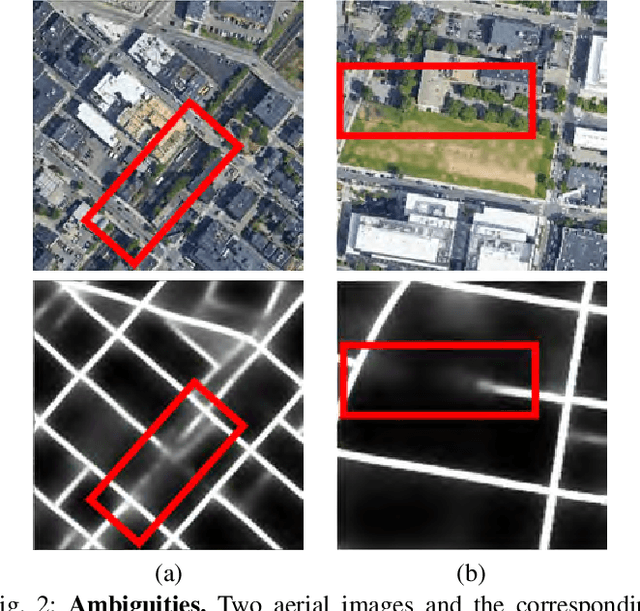
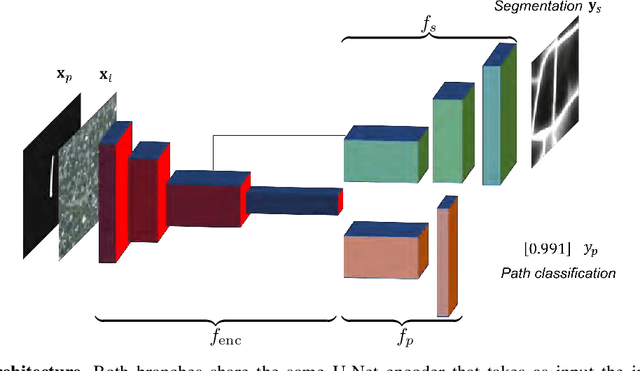
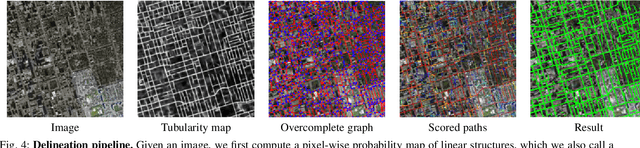
Detection of curvilinear structures in images has long been of interest. One of the most challenging aspects of this problem is inferring the graph representation of the curvilinear network. Most existing delineation approaches first perform binary segmentation of the image and then refine it using either a set of hand-designed heuristics or a separate classifier that assigns likelihood to paths extracted from the pixel-wise prediction. In our work, we bridge the gap between segmentation and path classification by training a deep network that performs those two tasks simultaneously. We show that this approach is beneficial because it enforces consistency across the whole processing pipeline. We apply our approach on roads and neurons datasets.
Detecting the Unexpected via Image Resynthesis
Apr 17, 2019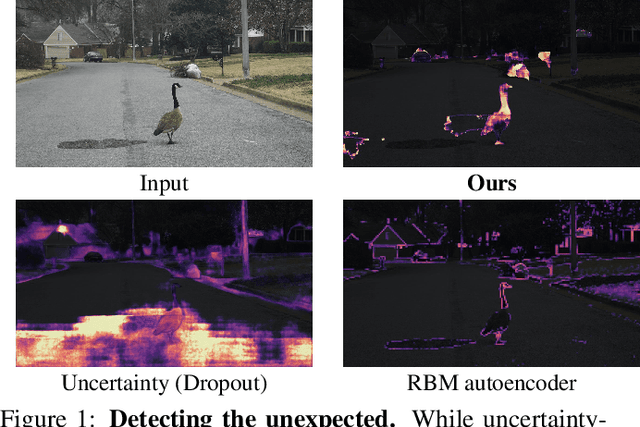
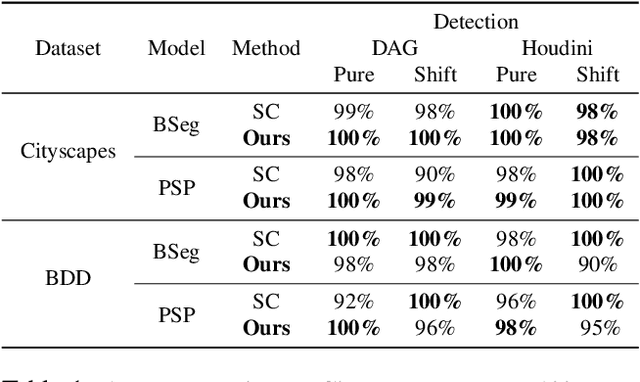
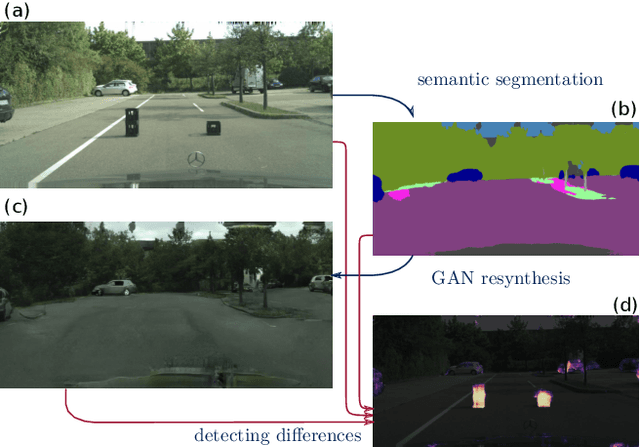
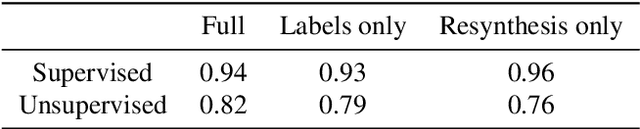
Classical semantic segmentation methods, including the recent deep learning ones, assume that all classes observed at test time have been seen during training. In this paper, we tackle the more realistic scenario where unexpected objects of unknown classes can appear at test time. The main trends in this area either leverage the notion of prediction uncertainty to flag the regions with low confidence as unknown, or rely on autoencoders and highlight poorly-decoded regions. Having observed that, in both cases, the detected regions typically do not correspond to unexpected objects, in this paper, we introduce a drastically different strategy: It relies on the intuition that the network will produce spurious labels in regions depicting unexpected objects. Therefore, resynthesizing the image from the resulting semantic map will yield significant appearance differences with respect to the input image. In other words, we translate the problem of detecting unknown classes to one of identifying poorly-resynthesized image regions. We show that this outperforms both uncertainty- and autoencoder-based methods.
Neural Scene Decomposition for Multi-Person Motion Capture
Mar 13, 2019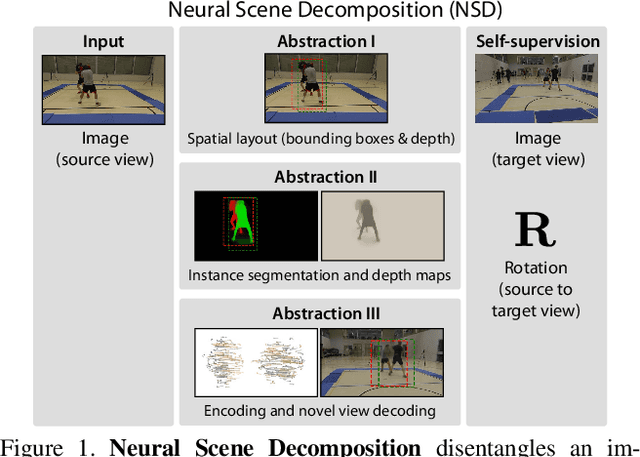
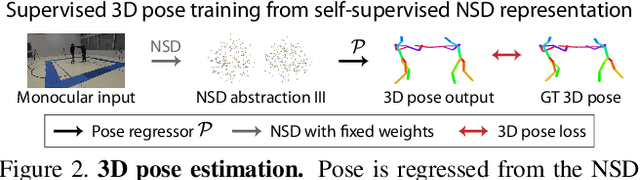
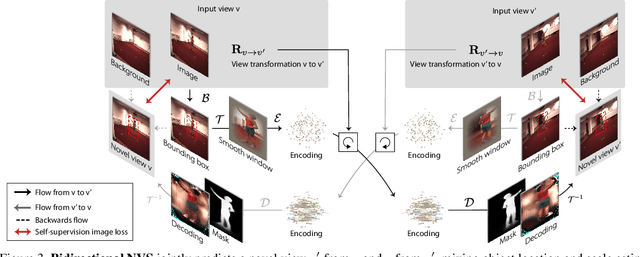

Learning general image representations has proven key to the success of many computer vision tasks. For example, many approaches to image understanding problems rely on deep networks that were initially trained on ImageNet, mostly because the learned features are a valuable starting point to learn from limited labeled data. However, when it comes to 3D motion capture of multiple people, these features are only of limited use. In this paper, we therefore propose an approach to learning features that are useful for this purpose. To this end, we introduce a self-supervised approach to learning what we call a neural scene decomposition (NSD) that can be exploited for 3D pose estimation. NSD comprises three layers of abstraction to represent human subjects: spatial layout in terms of bounding-boxes and relative depth; a 2D shape representation in terms of an instance segmentation mask; and subject-specific appearance and 3D pose information. By exploiting self-supervision coming from multiview data, our NSD model can be trained end-to-end without any 2D or 3D supervision. In contrast to previous approaches, it works for multiple persons and full-frame images. Because it encodes 3D geometry, NSD can then be effectively leveraged to train a 3D pose estimation network from small amounts of annotated data.
NeuralSampler: Euclidean Point Cloud Auto-Encoder and Sampler
Jan 27, 2019
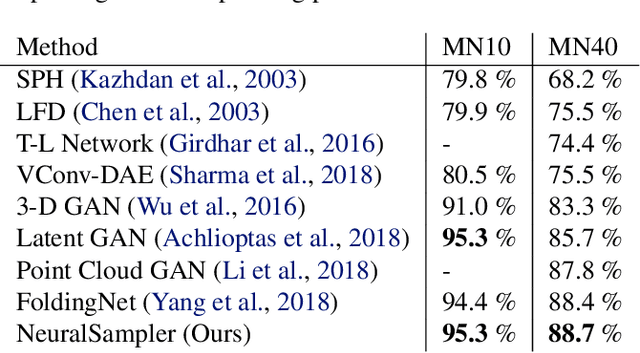
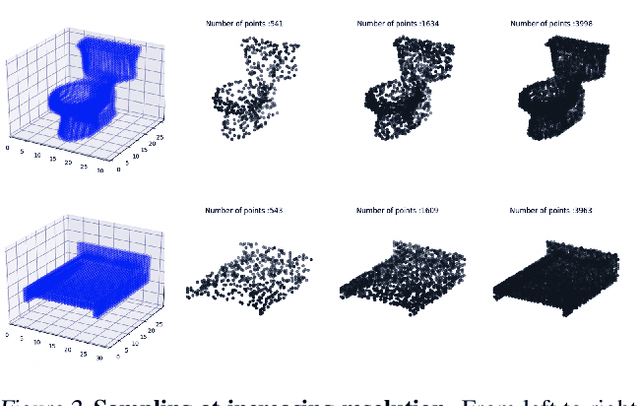
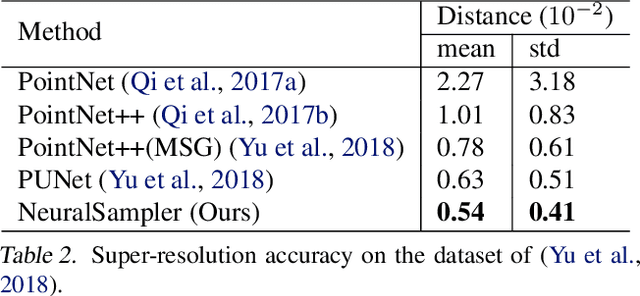
Most algorithms that rely on deep learning-based approaches to generate 3D point sets can only produce clouds containing fixed number of points. Furthermore, they typically require large networks parameterized by many weights, which makes them hard to train. In this paper, we propose an auto-encoder architecture that can both encode and decode clouds of arbitrary size and demonstrate its effectiveness at upsampling sparse point clouds. Interestingly, we can do so using less than half as many parameters as state-of-the-art architectures while still delivering better performance. We will make our code base fully available.
Segmentation-driven 6D Object Pose Estimation
Jan 08, 2019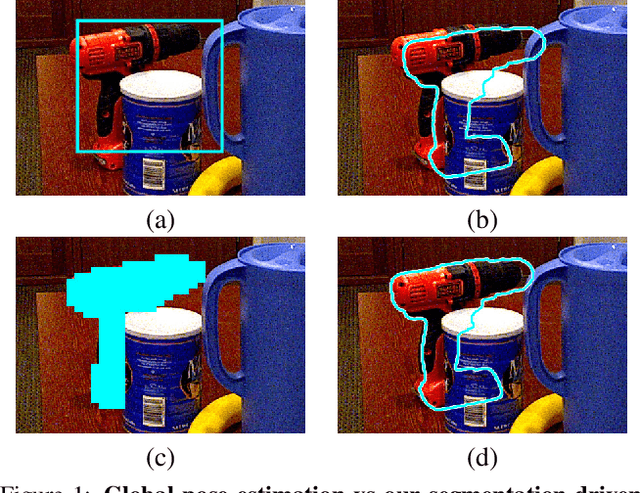
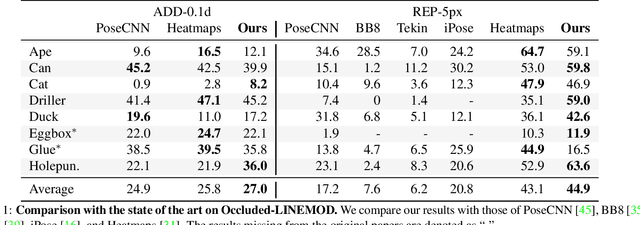
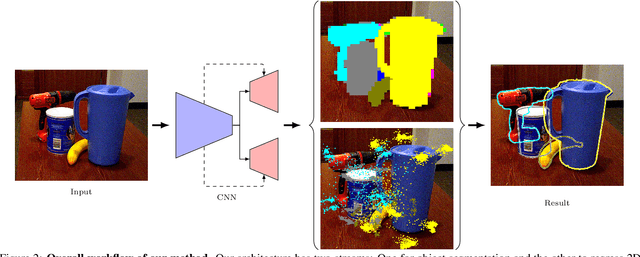

The most recent trend in estimating the 6D pose of rigid objects has been to train deep networks to either directly regress the pose from the image or to predict the 2D locations of 3D keypoints, from which the pose can be obtained using a PnP algorithm. In both cases, the object is treated as a global entity, and a single pose estimate is computed. As a consequence, the resulting techniques can be vulnerable to large occlusions. In this paper, we introduce a segmentation-driven 6D pose estimation framework where each visible part of the objects contributes a local pose prediction in the form of 2D keypoint locations. We then use a predicted measure of confidence to combine these pose candidates into a robust set of 3D-to-2D correspondences, from which a reliable pose estimate can be obtained. We outperform the state-of-the-art on the challenging Occluded-LINEMOD and YCB-Video datasets, which is evidence that our approach deals well with multiple poorly-textured objects occluding each other. Furthermore, it relies on a simple enough architecture to achieve real-time performance.
Beyond One Glance: Gated Recurrent Architecture for Hand Segmentation
Dec 12, 2018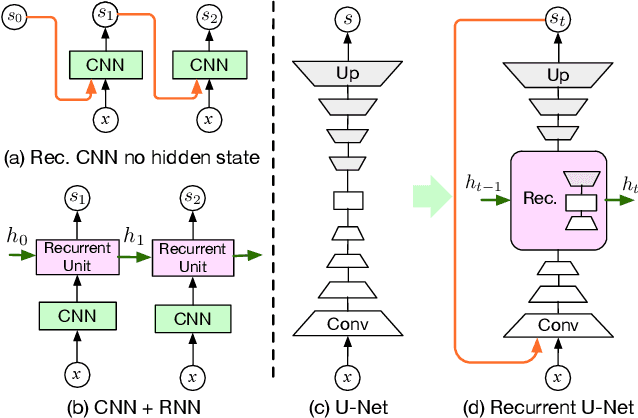
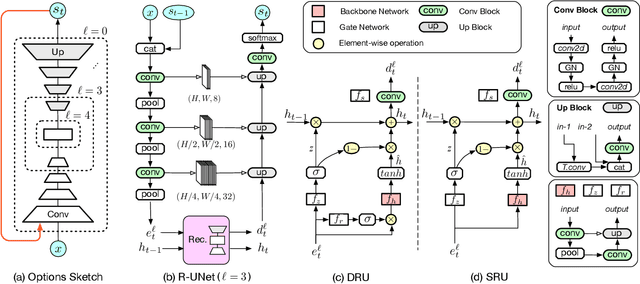

As mixed reality is gaining increased momentum, the development of effective and efficient solutions to egocentric hand segmentation is becoming critical. Traditional segmentation techniques typically follow a one-shot approach, where the image is passed forward only once through a model that produces a segmentation mask. This strategy, however, does not reflect the perception of humans, who continuously refine their representation of the world. In this paper, we therefore introduce a novel gated recurrent architecture. It goes beyond both iteratively passing the predicted segmentation mask through the network and adding a standard recurrent unit to it. Instead, it incorporates multiple encoder-decoder layers of the segmentation network, so as to keep track of its internal state in the refinement process. As evidenced by our results on standard hand segmentation benchmarks and on our own dataset, our approach outperforms these other, simpler recurrent segmentation techniques, as well as the state-of-the-art hand segmentation one. Furthermore, we demonstrate the generality of our approach by applying it to road segmentation, where it also outperforms other baseline methods.
Eliminating Exposure Bias and Loss-Evaluation Mismatch in Multiple Object Tracking
Nov 27, 2018
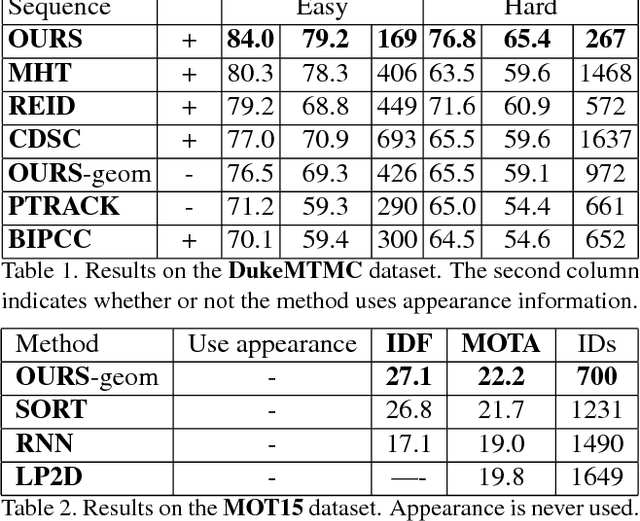
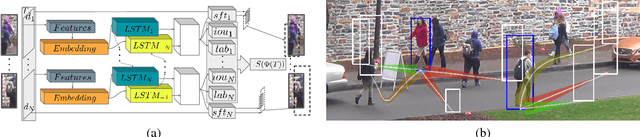
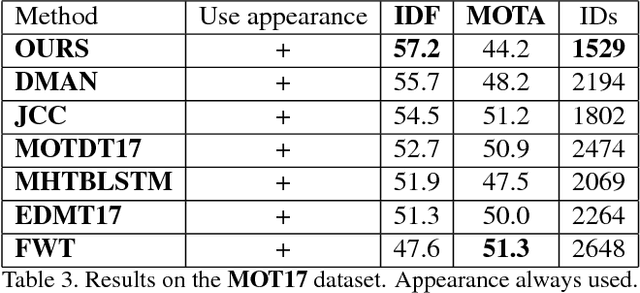
Identity Switching remains one of the main difficulties Multiple Object Tracking (MOT) algorithms have to deal with. Many state-of-the-art approaches now use sequence models to solve this problem but their training can be affected by biases that decrease their efficiency. In this paper, we introduce a new training procedure that confronts the algorithm to its own mistakes while explicitly attempting to minimize the number of switches, which results in better training. We propose an iterative scheme of building a rich training set and using it to learn a scoring function that is an explicit proxy for the target tracking metric. Whether using only simple geometric features or more sophisticated ones that also take appearance into account, our approach outperforms the state-of-the-art on several MOT benchmarks.
GarNet: A Two-stream Network for Fast and Accurate 3D Cloth Draping
Nov 27, 2018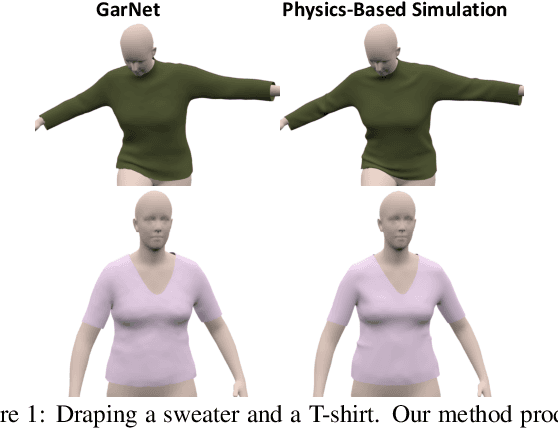
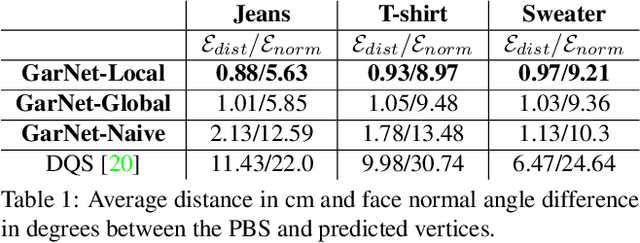
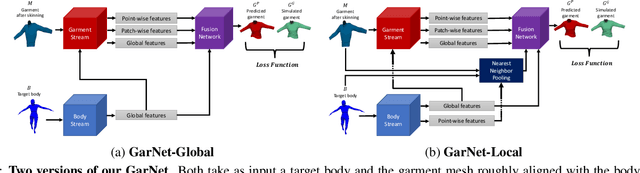
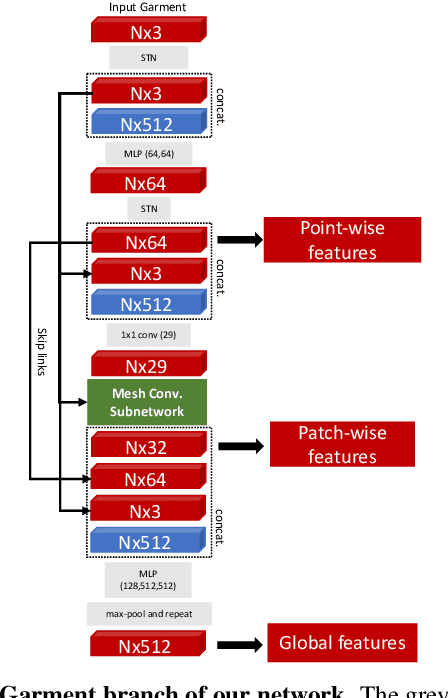
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. In this paper, we leverage this property and introduce a novel architecture to fit a 3D garment template to a 3D body model. Specifically, we build upon the recent progress in 3D point-cloud processing with deep networks to extract garment features at varying levels of detail, including point-wise, patch-wise and global features. We then fuse these features with those extracted in parallel from the 3D body, so as to model the cloth-body interactions. The resulting two-stream architecture is trained with a loss function inspired by physics-based modeling, and delivers realistic garment shapes whose 3D points are, on average, less than 1.5cm away from those of a PBS method, while running 40 times faster.