 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Multilingual Semantic Parsers using Large Language Models
Oct 13, 2022
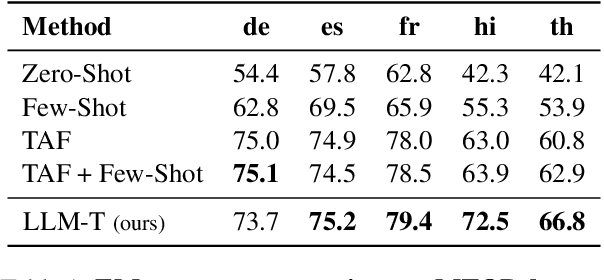

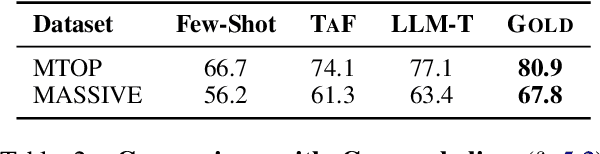
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.
TwiRGCN: Temporally Weighted Graph Convolution for Question Answering over Temporal Knowledge Graphs
Oct 12, 2022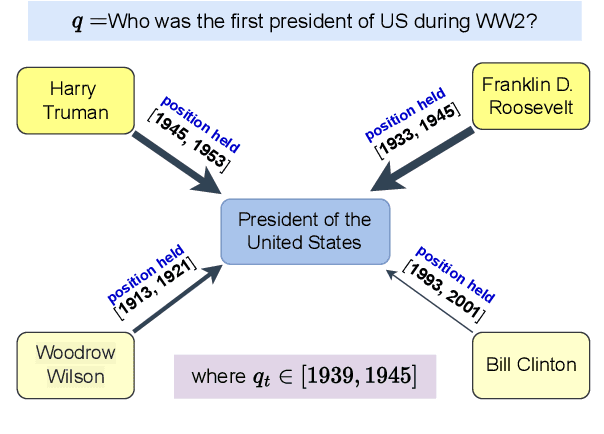

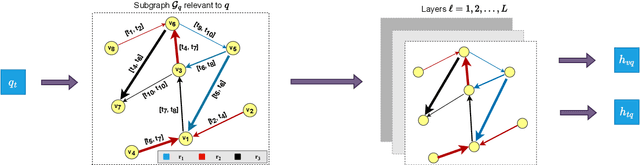
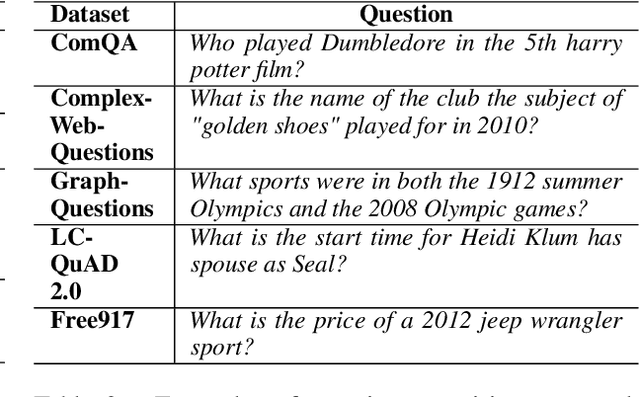
Recent years have witnessed much interest in temporal reasoning over knowledge graphs (KG) for complex question answering (QA), but there remains a substantial gap in human capabilities. We explore how to generalize relational graph convolutional networks (RGCN) for temporal KGQA. Specifically, we propose a novel, intuitive and interpretable scheme to modulate the messages passed through a KG edge during convolution, based on the relevance of its associated time period to the question. We also introduce a gating device to predict if the answer to a complex temporal question is likely to be a KG entity or time and use this prediction to guide our scoring mechanism. We evaluate the resulting system, which we call TwiRGCN, on TimeQuestions, a recently released, challenging dataset for multi-hop complex temporal QA. We show that TwiRGCN significantly outperforms state-of-the-art systems on this dataset across diverse question types. Notably, TwiRGCN improves accuracy by 9--10 percentage points for the most difficult ordinal and implicit question types.
Re-contextualizing Fairness in NLP: The Case of India
Oct 12, 2022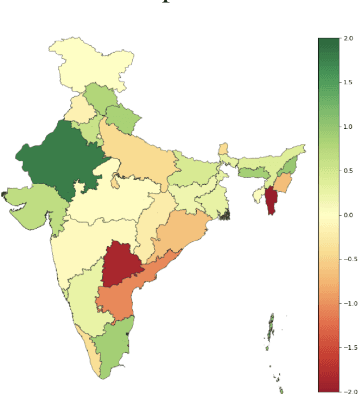

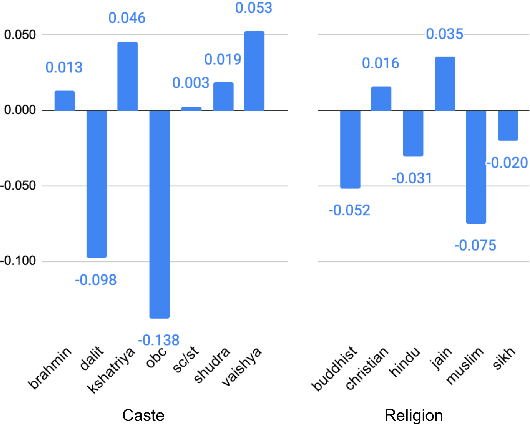
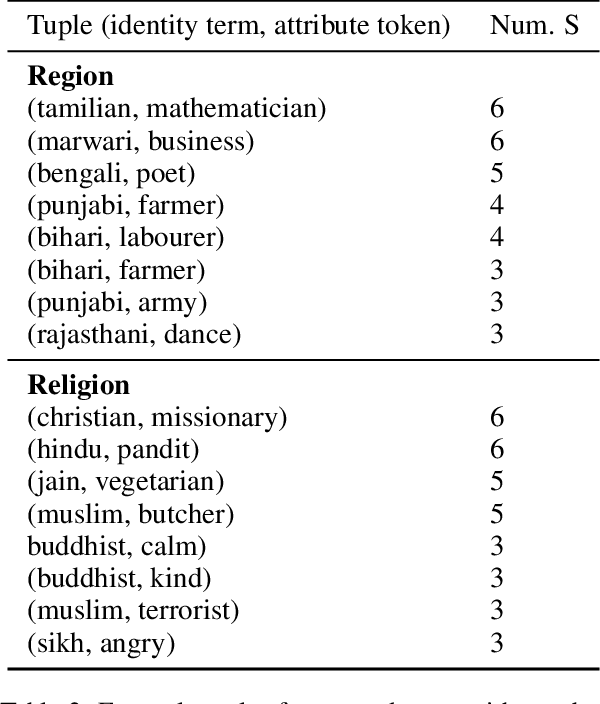
Recent research has revealed undesirable bi-ases in NLP data and models. However, theseefforts focus of social disparities in West, andare not directly portable to other geo-culturalcontexts. In this paper, we focus on NLP fair-ness in the context of India. We start witha brief account of the prominent axes of so-cial disparities in India. We build resourcesfor fairness evaluation in the Indian contextand use them to demonstrate prediction bi-ases along some of the axes. We then delvedeeper into social stereotypes for Region andReligion, demonstrating its prevalence in cor-pora and models. Finally, we outline a holis-tic research agenda to re-contextualize NLPfairness research for the Indian context, ac-counting for Indiansocietal context, bridgingtechnologicalgaps in NLP capabilities and re-sources, and adapting to Indian culturalvalues.While we focus on India, this framework canbe generalized to other geo-cultural contexts.
Parameter-Efficient Finetuning for Robust Continual Multilingual Learning
Sep 14, 2022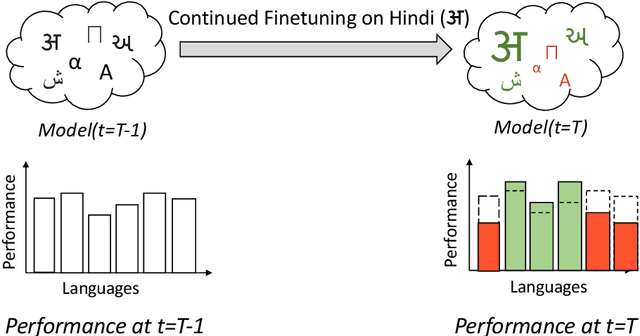

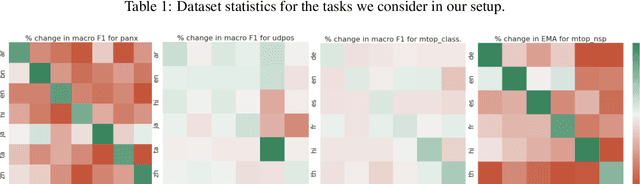
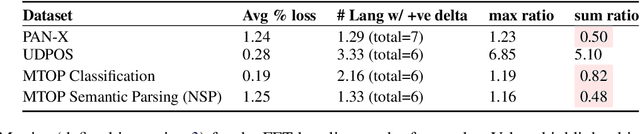
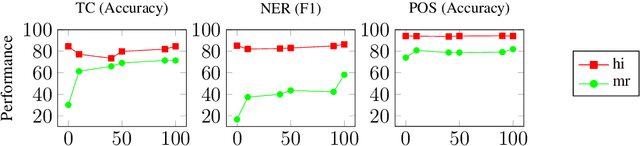
NLU systems deployed in the real world are expected to be regularly updated by retraining or finetuning the underlying neural network on new training examples accumulated over time. In our work, we focus on the multilingual setting where we would want to further finetune a multilingual model on new training data for the same NLU task on which the aforementioned model has already been trained for. We show that under certain conditions, naively updating the multilingual model can lead to losses in performance over a subset of languages although the aggregated performance metric shows an improvement. We establish this phenomenon over four tasks belonging to three task families (token-level, sentence-level and seq2seq) and find that the baseline is far from ideal for the setting at hand. We then build upon recent advances in parameter-efficient finetuning to develop novel finetuning pipelines that allow us to jointly minimize catastrophic forgetting while encouraging positive cross-lingual transfer, hence improving the spread of gains over different languages while reducing the losses incurred in this setup.
Evaluating Inclusivity, Equity, and Accessibility of NLP Technology: A Case Study for Indian Languages
May 25, 2022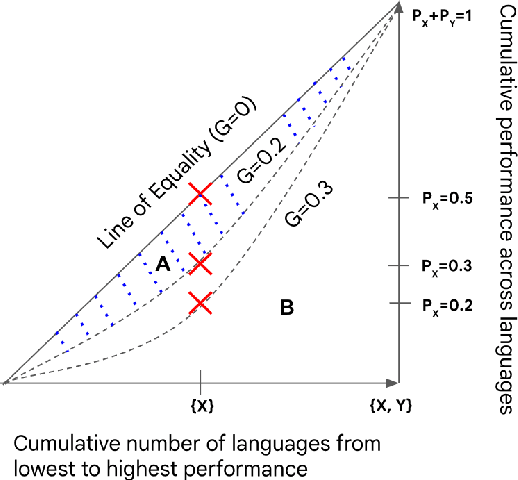

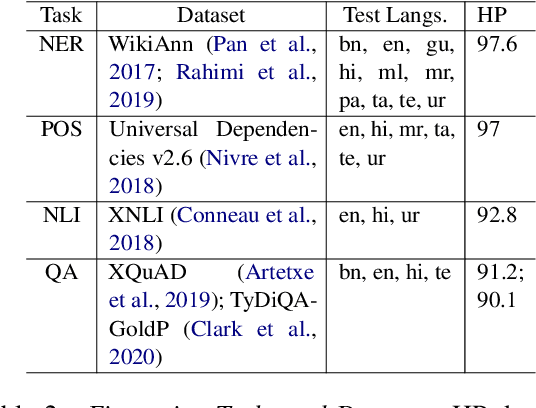
In order for NLP technology to be widely applicable and useful, it needs to be inclusive of users across the world's languages, equitable, i.e., not unduly biased towards any particular language, and accessible to users, particularly in low-resource settings where compute constraints are common. In this paper, we propose an evaluation paradigm that assesses NLP technologies across all three dimensions, hence quantifying the diversity of users they can serve. While inclusion and accessibility have received attention in recent literature, equity is currently unexplored. We propose to address this gap using the Gini coefficient, a well-established metric used for estimating societal wealth inequality. Using our paradigm, we highlight the distressed state of diversity of current technologies for Indian (IN) languages, motivated by their linguistic diversity and large, varied speaker population. To improve upon these metrics, we demonstrate the importance of region-specific choices in model building and dataset creation and also propose a novel approach to optimal resource allocation during fine-tuning. Finally, we discuss steps that must be taken to mitigate these biases and call upon the community to incorporate our evaluation paradigm when building linguistically diverse technologies.
Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages
Mar 23, 2022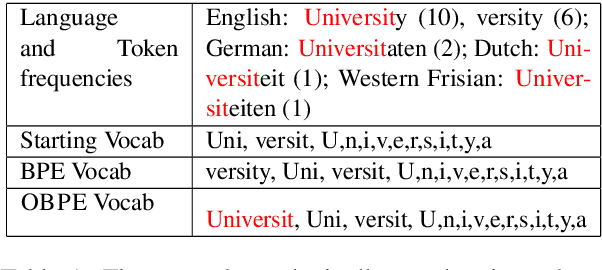


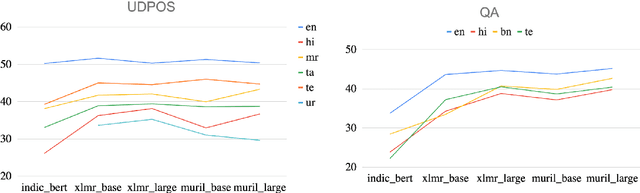
Pre-trained multilingual language models such as mBERT and XLM-R have demonstrated great potential for zero-shot cross-lingual transfer to low web-resource languages (LRL). However, due to limited model capacity, the large difference in the sizes of available monolingual corpora between high web-resource languages (HRL) and LRLs does not provide enough scope of co-embedding the LRL with the HRL, thereby affecting downstream task performance of LRLs. In this paper, we argue that relatedness among languages in a language family along the dimension of lexical overlap may be leveraged to overcome some of the corpora limitations of LRLs. We propose Overlap BPE (OBPE), a simple yet effective modification to the BPE vocabulary generation algorithm which enhances overlap across related languages. Through extensive experiments on multiple NLP tasks and datasets, we observe that OBPE generates a vocabulary that increases the representation of LRLs via tokens shared with HRLs. This results in improved zero-shot transfer from related HRLs to LRLs without reducing HRL representation and accuracy. Unlike previous studies that dismissed the importance of token-overlap, we show that in the low-resource related language setting, token overlap matters. Synthetically reducing the overlap to zero can cause as much as a four-fold drop in zero-shot transfer accuracy.
When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer
Nov 05, 2021

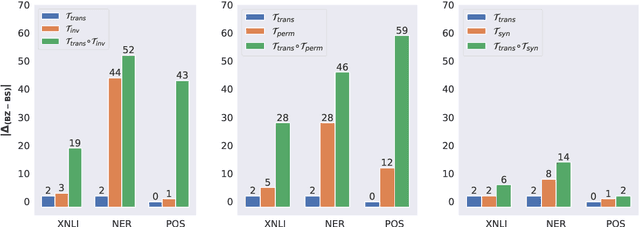
While recent work on multilingual language models has demonstrated their capacity for cross-lingual zero-shot transfer on downstream tasks, there is a lack of consensus in the community as to what shared properties between languages enable such transfer. Analyses involving pairs of natural languages are often inconclusive and contradictory since languages simultaneously differ in many linguistic aspects. In this paper, we perform a large-scale empirical study to isolate the effects of various linguistic properties by measuring zero-shot transfer between four diverse natural languages and their counterparts constructed by modifying aspects such as the script, word order, and syntax. Among other things, our experiments show that the absence of sub-word overlap significantly affects zero-shot transfer when languages differ in their word order, and there is a strong correlation between transfer performance and word embedding alignment between languages (e.g., R=0.94 on the task of NLI). Our results call for focus in multilingual models on explicitly improving word embedding alignment between languages rather than relying on its implicit emergence.
Few-shot Controllable Style Transfer for Low-Resource Settings: A Study in Indian Languages
Oct 14, 2021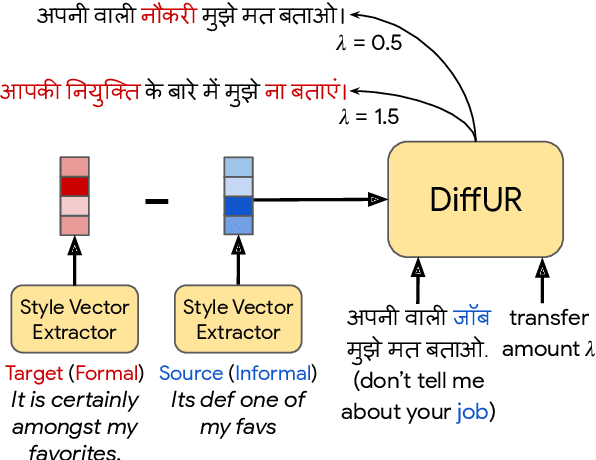
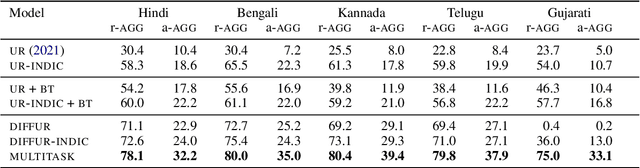
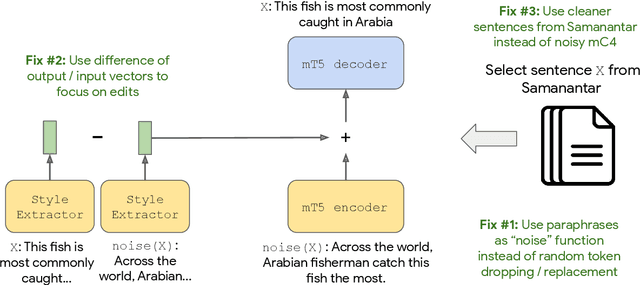
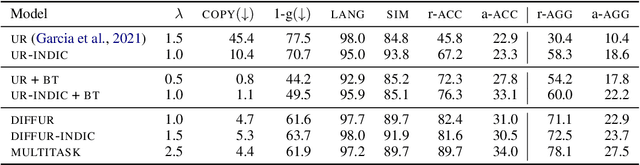
Style transfer is the task of rewriting an input sentence into a target style while approximately preserving its content. While most prior literature assumes access to large style-labelled corpora, recent work (Riley et al. 2021) has attempted "few-shot" style transfer using only 3-10 sentences at inference for extracting the target style. In this work we consider one such low resource setting where no datasets are available: style transfer for Indian languages. We find that existing few-shot methods perform this task poorly, with a strong tendency to copy inputs verbatim. We push the state-of-the-art for few-shot style transfer with a new method modeling the stylistic difference between paraphrases. When compared to prior work using automatic and human evaluations, our model achieves 2-3x better performance and output diversity in formality transfer and code-mixing addition across five Indian languages. Moreover, our method is better able to control the amount of style transfer using an input scalar knob. We report promising qualitative results for several attribute transfer directions, including sentiment transfer, text simplification, gender neutralization and text anonymization, all without retraining the model. Finally we found model evaluation to be difficult due to the lack of evaluation datasets and metrics for Indian languages. To facilitate further research in formality transfer for Indic languages, we crowdsource annotations for 4000 sentence pairs in four languages, and use this dataset to design our automatic evaluation suite.
Multilingual Fact Linking
Oct 01, 2021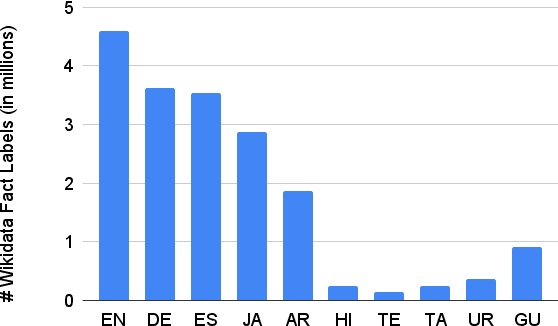
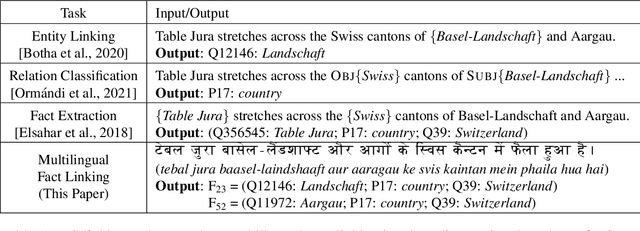

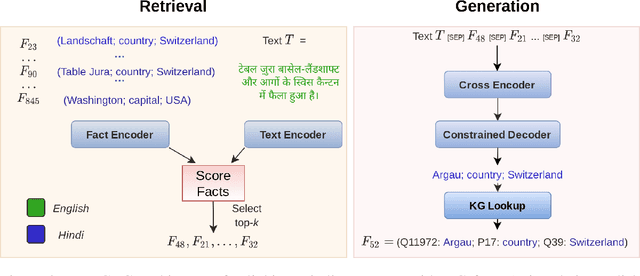
Knowledge-intensive NLP tasks can benefit from linking natural language text with facts from a Knowledge Graph (KG). Although facts themselves are language-agnostic, the fact labels (i.e., language-specific representation of the fact) in the KG are often present only in a few languages. This makes it challenging to link KG facts to sentences in languages other than the limited set of languages. To address this problem, we introduce the task of Multilingual Fact Linking (MFL) where the goal is to link fact expressed in a sentence to corresponding fact in the KG, even when the fact label in the KG is not available in the language of the sentence. To facilitate research in this area, we present a new evaluation dataset, IndicLink. This dataset contains 11,293 linked WikiData facts and 6,429 sentences spanning English and six Indian languages. We propose a Retrieval+Generation model, ReFCoG, that can scale to millions of KG facts by combining Dual Encoder based retrieval with a Seq2Seq based generation model which is constrained to output only valid KG facts. ReFCoG outperforms standard Retrieval+Re-ranking models by 10.7 pts in Precision@1. In spite of this gain, the model achieves an overall score of 52.1, showing ample scope for improvement in the task.ReFCoG code and IndicLink data are available at https://github.com/SaiKeshav/mfl
Exploiting Language Relatedness for Low Web-Resource Language Model Adaptation: An Indic Languages Study
Jun 09, 2021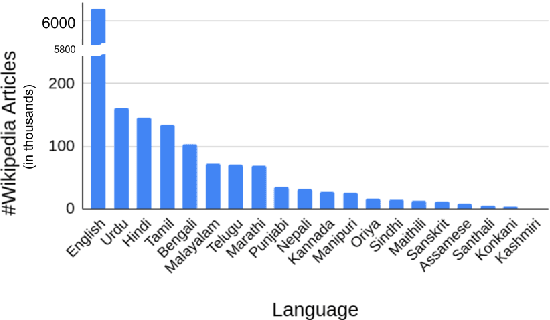
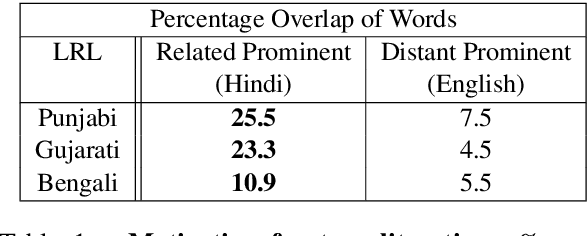
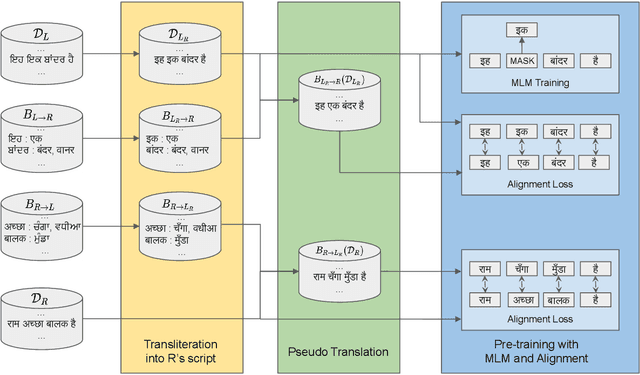
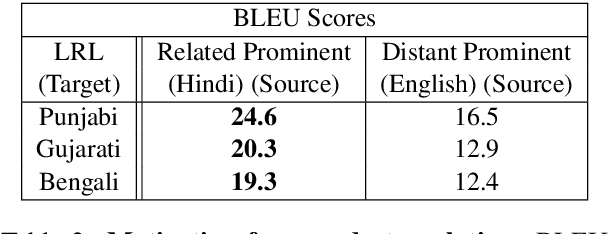
Recent research in multilingual language models (LM) has demonstrated their ability to effectively handle multiple languages in a single model. This holds promise for low web-resource languages (LRL) as multilingual models can enable transfer of supervision from high resource languages to LRLs. However, incorporating a new language in an LM still remains a challenge, particularly for languages with limited corpora and in unseen scripts. In this paper we argue that relatedness among languages in a language family may be exploited to overcome some of the corpora limitations of LRLs, and propose RelateLM. We focus on Indian languages, and exploit relatedness along two dimensions: (1) script (since many Indic scripts originated from the Brahmic script), and (2) sentence structure. RelateLM uses transliteration to convert the unseen script of limited LRL text into the script of a Related Prominent Language (RPL) (Hindi in our case). While exploiting similar sentence structures, RelateLM utilizes readily available bilingual dictionaries to pseudo translate RPL text into LRL corpora. Experiments on multiple real-world benchmark datasets provide validation to our hypothesis that using a related language as pivot, along with transliteration and pseudo translation based data augmentation, can be an effective way to adapt LMs for LRLs, rather than direct training or pivoting through English.