 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanagiotis Tzirakis
An Overview of Affective Speech Synthesis and Conversion in the Deep Learning Era
Oct 06, 2022
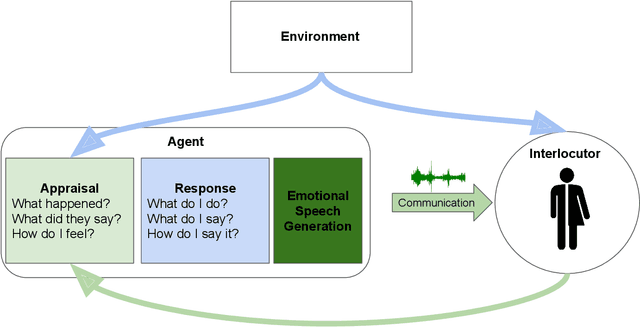
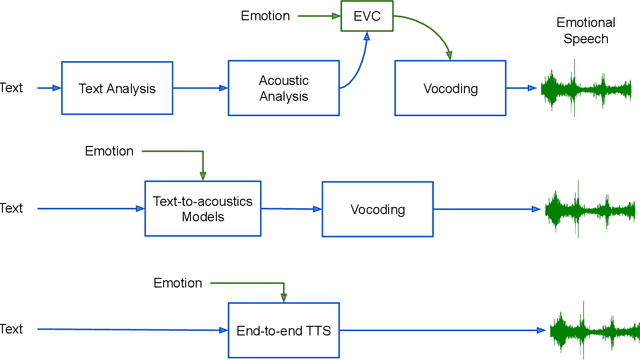
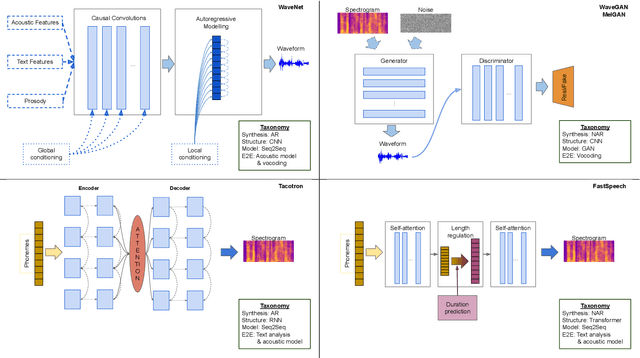
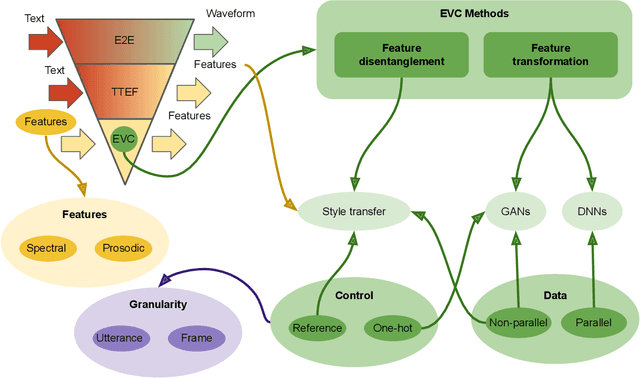
Speech is the fundamental mode of human communication, and its synthesis has long been a core priority in human-computer interaction research. In recent years, machines have managed to master the art of generating speech that is understandable by humans. But the linguistic content of an utterance encompasses only a part of its meaning. Affect, or expressivity, has the capacity to turn speech into a medium capable of conveying intimate thoughts, feelings, and emotions -- aspects that are essential for engaging and naturalistic interpersonal communication. While the goal of imparting expressivity to synthesised utterances has so far remained elusive, following recent advances in text-to-speech synthesis, a paradigm shift is well under way in the fields of affective speech synthesis and conversion as well. Deep learning, as the technology which underlies most of the recent advances in artificial intelligence, is spearheading these efforts. In the present overview, we outline ongoing trends and summarise state-of-the-art approaches in an attempt to provide a comprehensive overview of this exciting field.
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022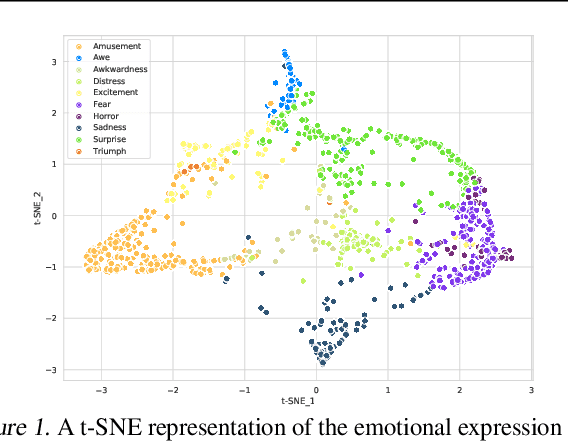
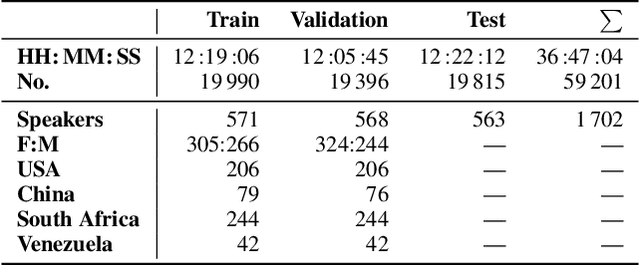
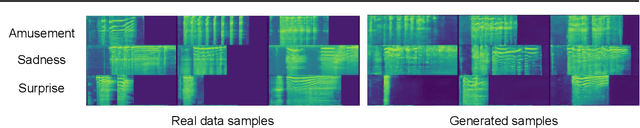
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.
The ACII 2022 Affective Vocal Bursts Workshop & Competition: Understanding a critically understudied modality of emotional expression
Jul 07, 2022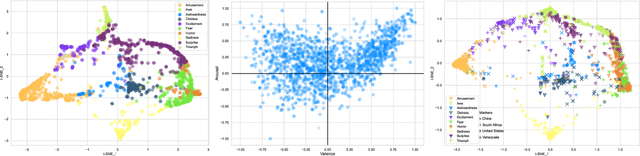
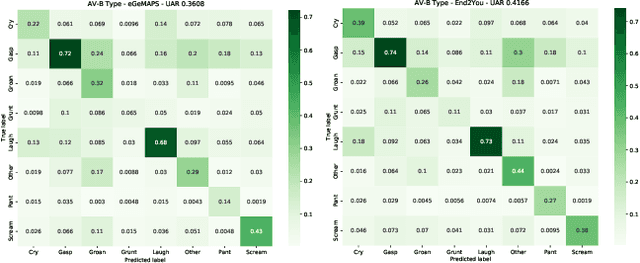
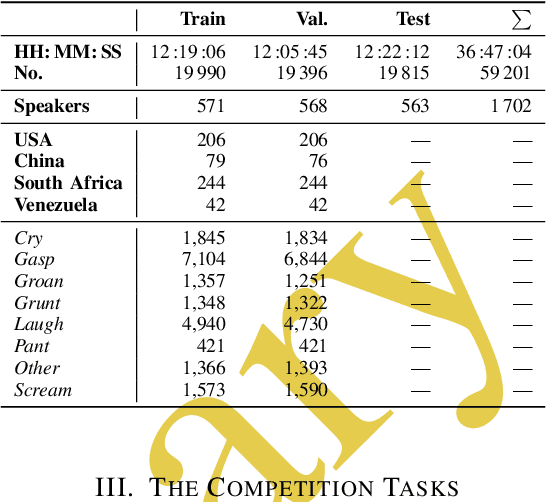
The ACII Affective Vocal Bursts Workshop & Competition is focused on understanding multiple affective dimensions of vocal bursts: laughs, gasps, cries, screams, and many other non-linguistic vocalizations central to the expression of emotion and to human communication more generally. This year's competition comprises four tracks using a large-scale and in-the-wild dataset of 59,299 vocalizations from 1,702 speakers. The first, the A-VB-High task, requires competition participants to perform a multi-label regression on a novel model for emotion, utilizing ten classes of richly annotated emotional expression intensities, including; Awe, Fear, and Surprise. The second, the A-VB-Two task, utilizes the more conventional 2-dimensional model for emotion, arousal, and valence. The third, the A-VB-Culture task, requires participants to explore the cultural aspects of the dataset, training native-country dependent models. Finally, for the fourth task, A-VB-Type, participants should recognize the type of vocal burst (e.g., laughter, cry, grunt) as an 8-class classification. This paper describes the four tracks and baseline systems, which use state-of-the-art machine learning methods. The baseline performance for each track is obtained by utilizing an end-to-end deep learning model and is as follows: for A-VB-High, a mean (over the 10-dimensions) Concordance Correlation Coefficient (CCC) of 0.5687 CCC is obtained; for A-VB-Two, a mean (over the 2-dimensions) CCC of 0.5084 is obtained; for A-VB-Culture, a mean CCC from the four cultures of 0.4401 is obtained; and for A-VB-Type, the baseline Unweighted Average Recall (UAR) from the 8-classes is 0.4172 UAR.
The ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
May 03, 2022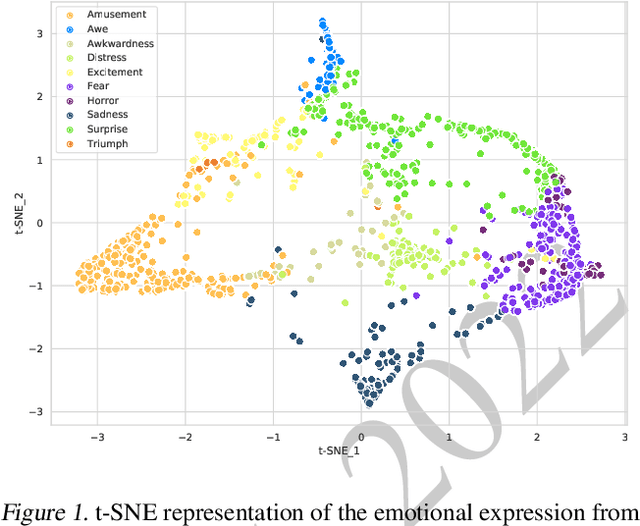
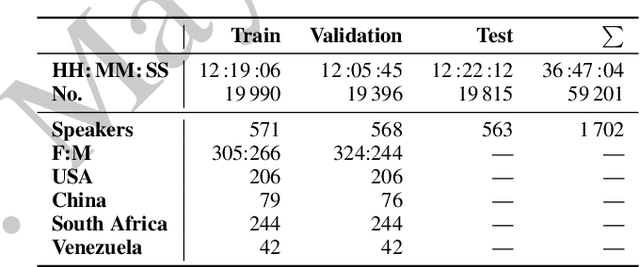
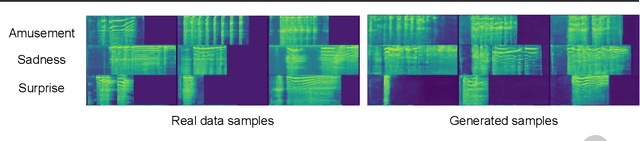
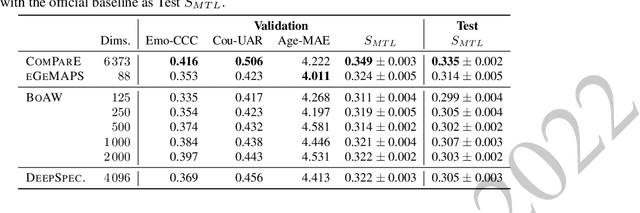
The ICML Expressive Vocalization (ExVo) Competition is focused on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, includes three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts. This paper describes the three tracks and provides performance measures for baseline models using state-of-the-art machine learning strategies. The baseline for each track is as follows, for ExVo-MultiTask, a combined score, computing the harmonic mean of Concordance Correlation Coefficient (CCC), Unweighted Average Recall (UAR), and inverted Mean Absolute Error (MAE) ($S_{MTL}$) is at best, 0.335 $S_{MTL}$; for ExVo-Generate, we report Fr\'echet inception distance (FID) scores ranging from 4.81 to 8.27 (depending on the emotion) between the training set and generated samples. We then combine the inverted FID with perceptual ratings of the generated samples ($S_{Gen}$) and obtain 0.174 $S_{Gen}$; and for ExVo-FewShot, a mean CCC of 0.444 is obtained.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022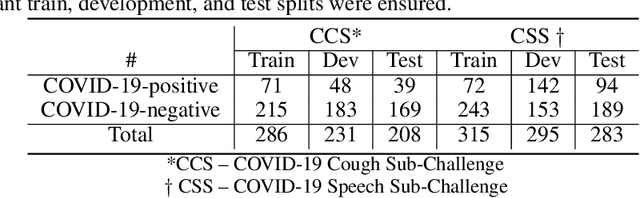
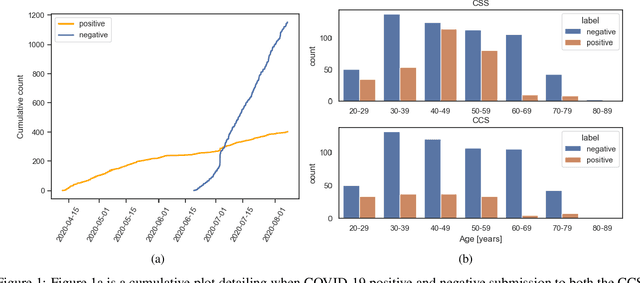
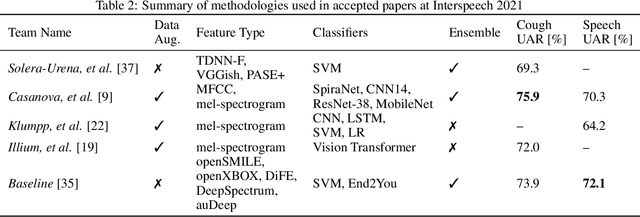
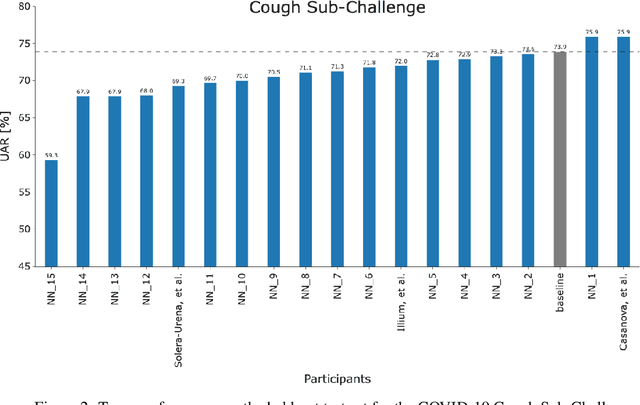
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
Facial Emotion Recognition using Deep Residual Networks in Real-World Environments
Nov 04, 2021
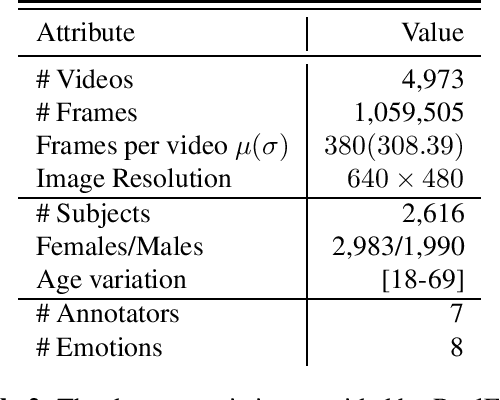
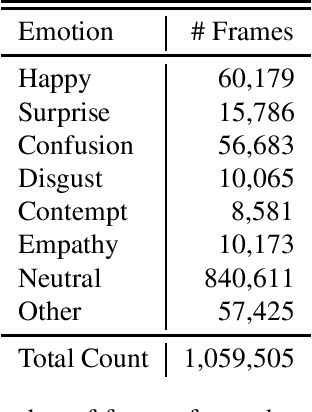
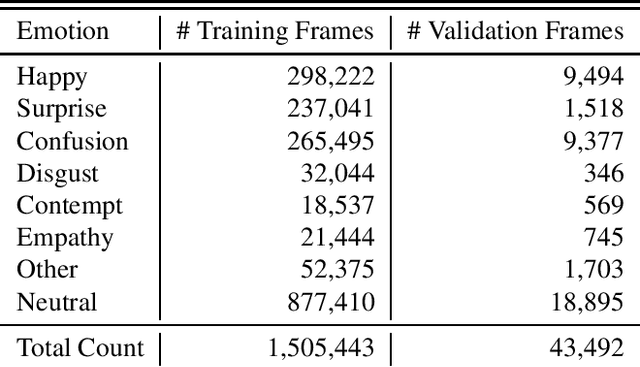
Automatic affect recognition using visual cues is an important task towards a complete interaction between humans and machines. Applications can be found in tutoring systems and human computer interaction. A critical step towards that direction is facial feature extraction. In this paper, we propose a facial feature extractor model trained on an in-the-wild and massively collected video dataset provided by the RealEyes company. The dataset consists of a million labelled frames and 2,616 thousand subjects. As temporal information is important to the emotion recognition domain, we utilise LSTM cells to capture the temporal dynamics in the data. To show the favourable properties of our pre-trained model on modelling facial affect, we use the RECOLA database, and compare with the current state-of-the-art approach. Our model provides the best results in terms of concordance correlation coefficient.
Evaluating the COVID-19 Identification ResNet (CIdeR) on the INTERSPEECH COVID-19 from Audio Challenges
Jul 30, 2021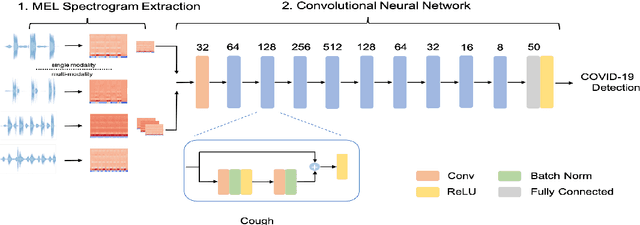

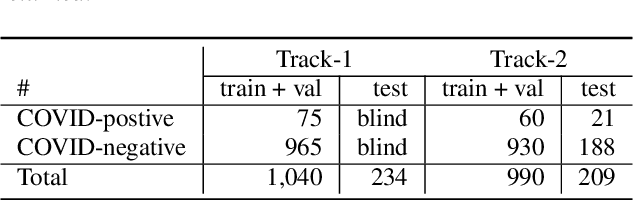
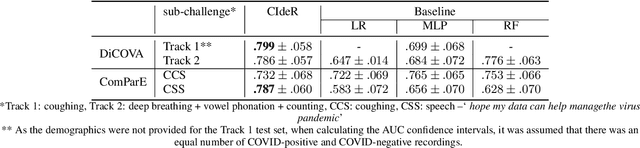
We report on cross-running the recent COVID-19 Identification ResNet (CIdeR) on the two Interspeech 2021 COVID-19 diagnosis from cough and speech audio challenges: ComParE and DiCOVA. CIdeR is an end-to-end deep learning neural network originally designed to classify whether an individual is COVID-positive or COVID-negative based on coughing and breathing audio recordings from a published crowdsourced dataset. In the current study, we demonstrate the potential of CIdeR at binary COVID-19 diagnosis from both the COVID-19 Cough and Speech Sub-Challenges of INTERSPEECH 2021, ComParE and DiCOVA. CIdeR achieves significant improvements over several baselines.
Speech Emotion Recognition using Semantic Information
Mar 04, 2021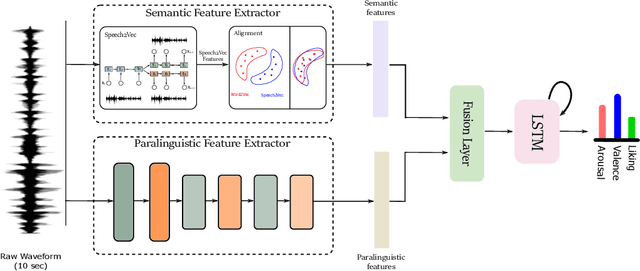

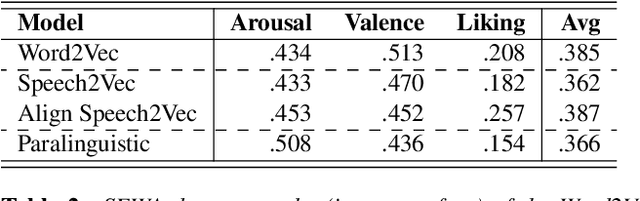

Speech emotion recognition is a crucial problem manifesting in a multitude of applications such as human computer interaction and education. Although several advancements have been made in the recent years, especially with the advent of Deep Neural Networks (DNN), most of the studies in the literature fail to consider the semantic information in the speech signal. In this paper, we propose a novel framework that can capture both the semantic and the paralinguistic information in the signal. In particular, our framework is comprised of a semantic feature extractor, that captures the semantic information, and a paralinguistic feature extractor, that captures the paralinguistic information. Both semantic and paraliguistic features are then combined to a unified representation using a novel attention mechanism. The unified feature vector is passed through a LSTM to capture the temporal dynamics in the signal, before the final prediction. To validate the effectiveness of our framework, we use the popular SEWA dataset of the AVEC challenge series and compare with the three winning papers. Our model provides state-of-the-art results in the valence and liking dimensions.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021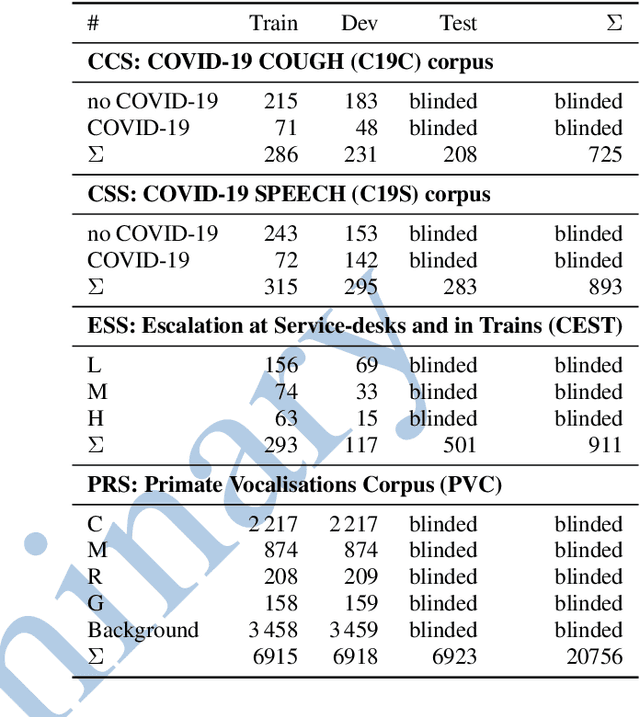
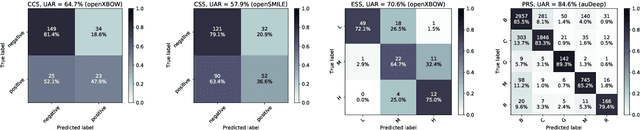
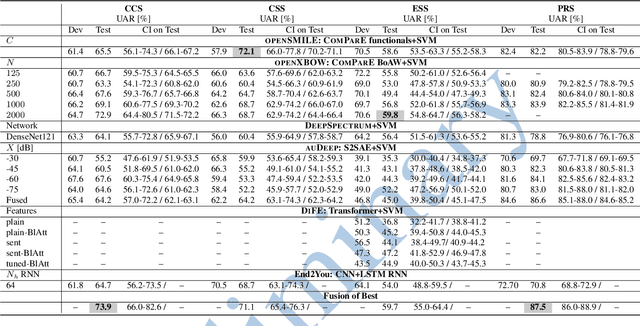
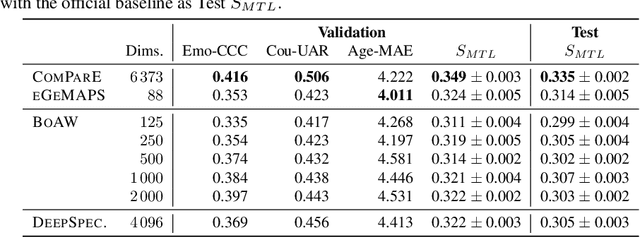
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
Multi-Channel Speech Enhancement using Graph Neural Networks
Feb 13, 2021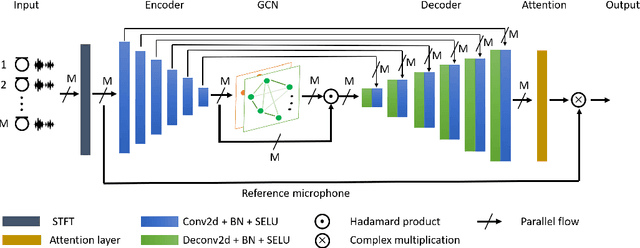
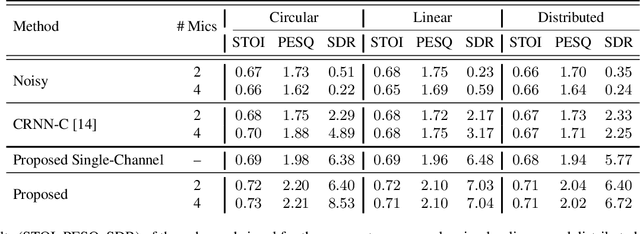

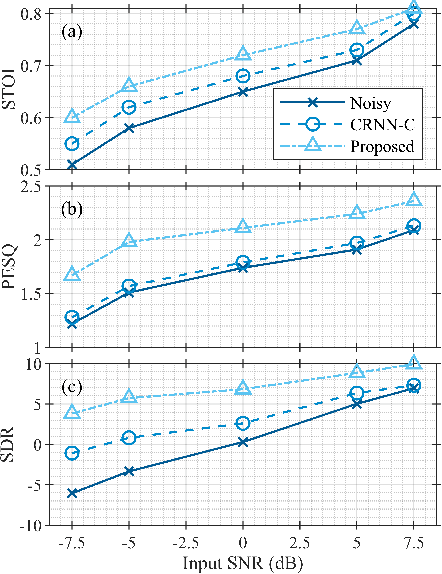
Multi-channel speech enhancement aims to extract clean speech from a noisy mixture using signals captured from multiple microphones. Recently proposed methods tackle this problem by incorporating deep neural network models with spatial filtering techniques such as the minimum variance distortionless response (MVDR) beamformer. In this paper, we introduce a different research direction by viewing each audio channel as a node lying in a non-Euclidean space and, specifically, a graph. This formulation allows us to apply graph neural networks (GNN) to find spatial correlations among the different channels (nodes). We utilize graph convolution networks (GCN) by incorporating them in the embedding space of a U-Net architecture. We use LibriSpeech dataset and simulate room acoustics data to extensively experiment with our approach using different array types, and number of microphones. Results indicate the superiority of our approach when compared to prior state-of-the-art method.