 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
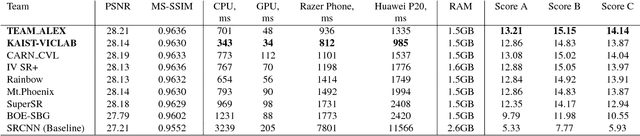

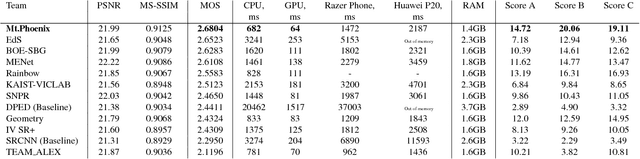
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.
Convolutional Networks with MuxOut Layers as Multi-rate Systems for Image Upscaling
May 22, 2017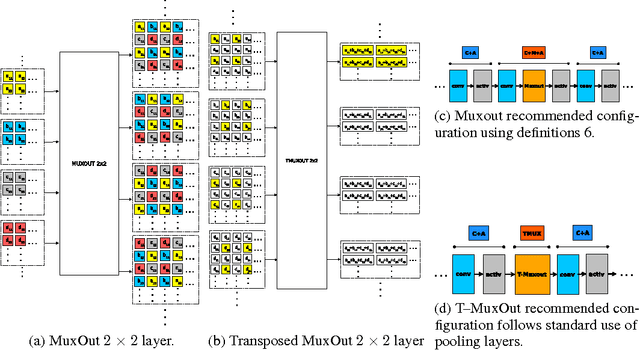

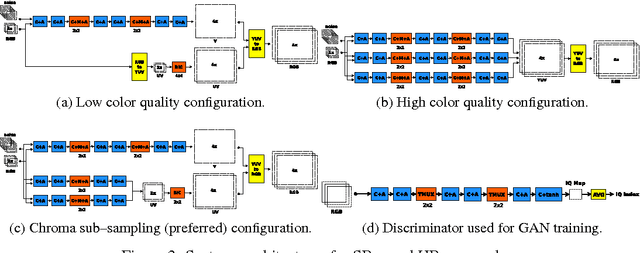
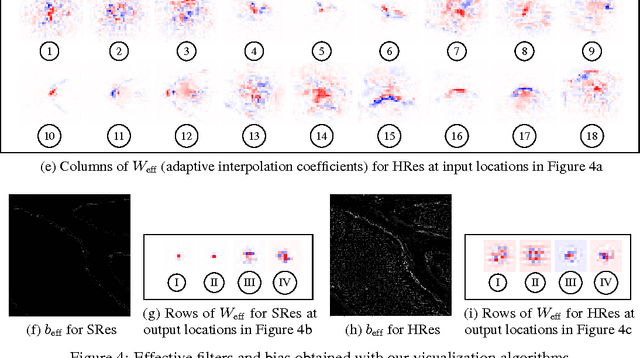
We interpret convolutional networks as adaptive filters and combine them with so-called MuxOut layers to efficiently upscale low resolution images. We formalize this interpretation by deriving a linear and space-variant structure of a convolutional network when its activations are fixed. We introduce general purpose algorithms to analyze a network and show its overall filter effect for each given location. We use this analysis to evaluate two types of image upscalers: deterministic upscalers that target the recovery of details from original content; and second, a new generation of upscalers that can sample the distribution of upscale aliases (images that share the same downscale version) that look like real content.