 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Rivalry in Reinforcement Learning for a Competitive Game
Nov 02, 2020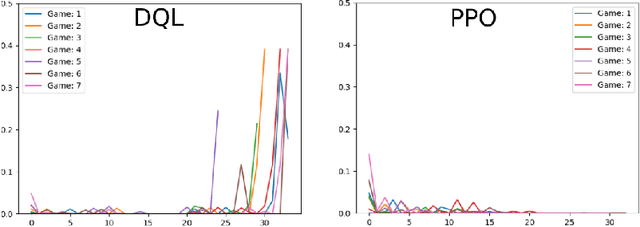
Recent advances in reinforcement learning with social agents have allowed us to achieve human-level performance on some interaction tasks. However, most interactive scenarios do not have as end-goal performance alone; instead, the social impact of these agents when interacting with humans is as important and, in most cases, never explored properly. This preregistration study focuses on providing a novel learning mechanism based on a rivalry social impact. Our scenario explored different reinforcement learning-based agents playing a competitive card game against human players. Based on the concept of competitive rivalry, our analysis aims to investigate if we can change the assessment of these agents from a human perspective.
Affect-Driven Modelling of Robot Personality for Collaborative Human-Robot Interactions
Oct 14, 2020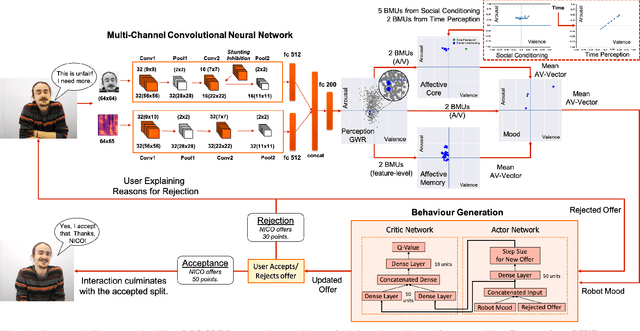
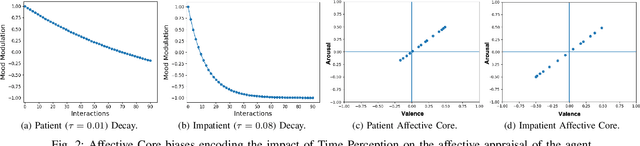
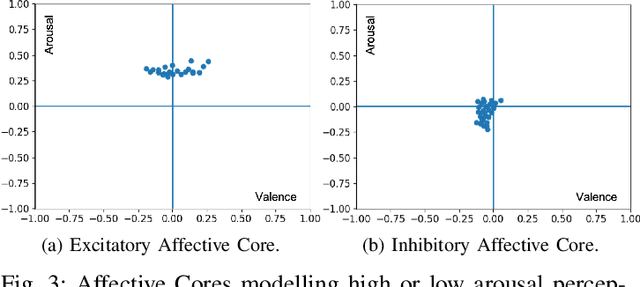

Collaborative interactions require social robots to adapt to the dynamics of human affective behaviour. Yet, current approaches for affective behaviour generation in robots focus on instantaneous perception to generate a one-to-one mapping between observed human expressions and static robot actions. In this paper, we propose a novel framework for personality-driven behaviour generation in social robots. The framework consists of (i) a hybrid neural model for evaluating facial expressions and speech, forming intrinsic affective representations in the robot, (ii) an Affective Core, that employs self-organising neural models to embed robot personality traits like patience and emotional actuation, and (iii) a Reinforcement Learning model that uses the robot's affective appraisal to learn interaction behaviour. For evaluation, we conduct a user study (n = 31) where the NICO robot acts as a proposer in the Ultimatum Game. The effect of robot personality on its negotiation strategy is witnessed by participants, who rank a patient robot with high emotional actuation higher on persistence, while an inert and impatient robot higher on its generosity and altruistic behaviour.
The FaceChannelS: Strike of the Sequences for the AffWild 2 Challenge
Oct 04, 2020

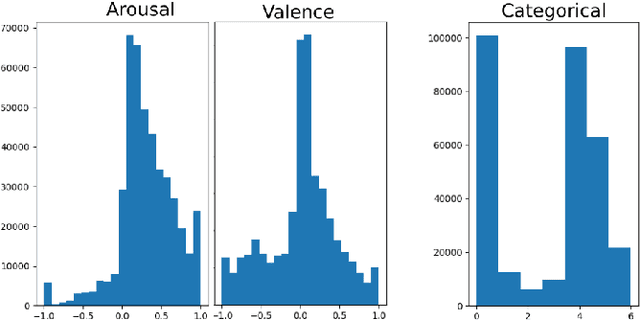
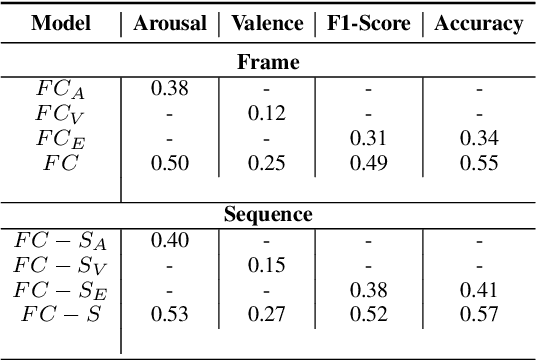
Predicting affective information from human faces became a popular task for most of the machine learning community in the past years. The development of immense and dense deep neural networks was backed by the availability of numerous labeled datasets. These models, most of the time, present state-of-the-art results in such benchmarks, but are very difficult to adapt to other scenarios. In this paper, we present one more chapter of benchmarking different versions of the FaceChannel neural network: we demonstrate how our little model can predict affective information from the facial expression on the novel AffWild2 dataset.
The FaceChannel: A Fast & Furious Deep Neural Network for Facial Expression Recognition
Sep 15, 2020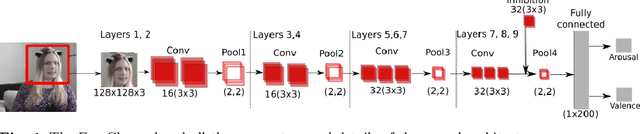
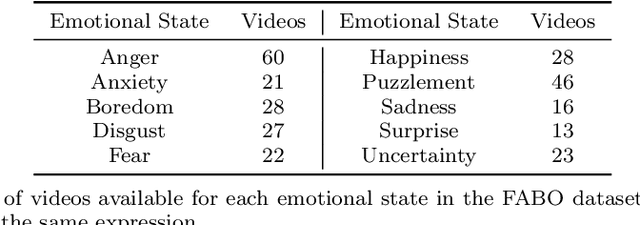
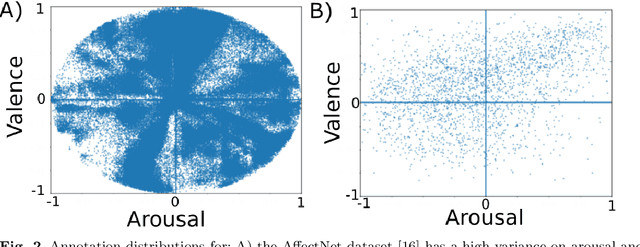
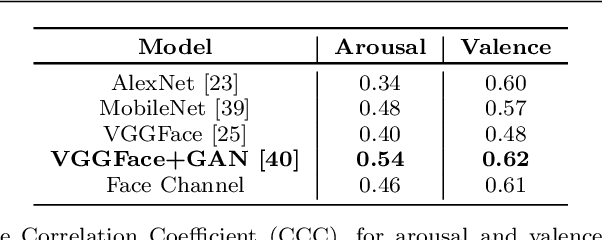
Current state-of-the-art models for automatic Facial Expression Recognition (FER) are based on very deep neural networks that are effective but rather expensive to train. Given the dynamic conditions of FER, this characteristic hinders such models of been used as a general affect recognition. In this paper, we address this problem by formalizing the FaceChannel, a light-weight neural network that has much fewer parameters than common deep neural networks. We introduce an inhibitory layer that helps to shape the learning of facial features in the last layer of the network and thus improving performance while reducing the number of trainable parameters. To evaluate our model, we perform a series of experiments on different benchmark datasets and demonstrate how the FaceChannel achieves a comparable, if not better, performance to the current state-of-the-art in FER. Our experiments include cross-dataset analysis, to estimate how our model behaves on different affective recognition conditions. We conclude our paper with an analysis of how FaceChannel learns and adapt the learned facial features towards the different datasets.
Analysis of Social Robotic Navigation approaches: CNN Encoder and Incremental Learning as an alternative to Deep Reinforcement Learning
Sep 05, 2020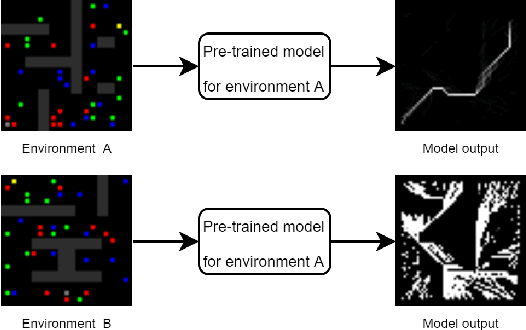
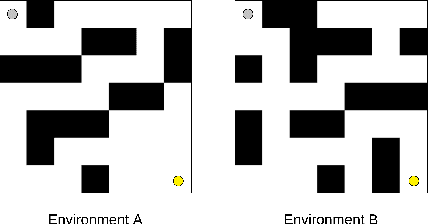
Dealing with social tasks in robotic scenarios is difficult, as having humans in the learning loop is incompatible with most of the state-of-the-art machine learning algorithms. This is the case when exploring Incremental learning models, in particular the ones involving reinforcement learning. In this work, we discuss this problem and possible solutions by analysing a previous study on adaptive convolutional encoders for a social navigation task.
Performance Improvement of Path Planning algorithms with Deep Learning Encoder Model
Aug 05, 2020
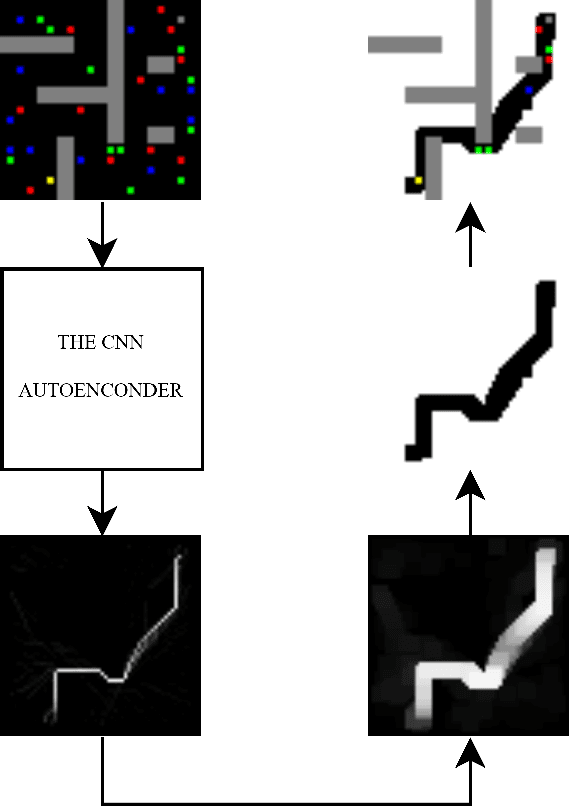
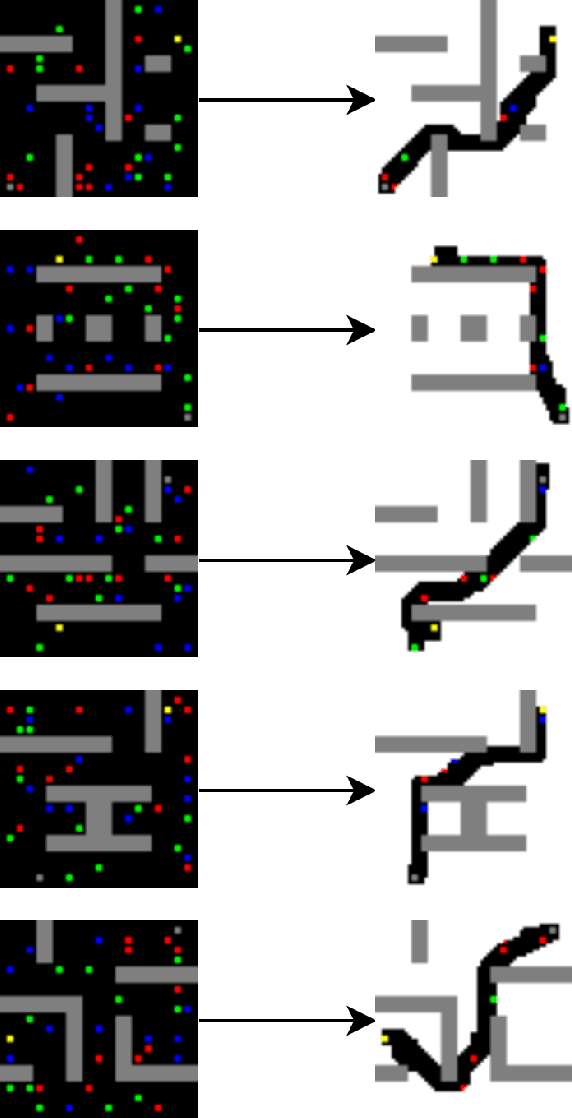
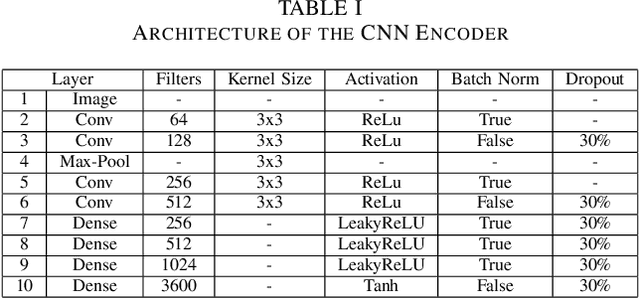
Currently, path planning algorithms are used in many daily tasks. They are relevant to find the best route in traffic and make autonomous robots able to navigate. The use of path planning presents some issues in large and dynamic environments. Large environments make these algorithms spend much time finding the shortest path. On the other hand, dynamic environments request a new execution of the algorithm each time a change occurs in the environment, and it increases the execution time. The dimensionality reduction appears as a solution to this problem, which in this context means removing useless paths present in those environments. Most of the algorithms that reduce dimensionality are limited to the linear correlation of the input data. Recently, a Convolutional Neural Network (CNN) Encoder was used to overcome this situation since it can use both linear and non-linear information to data reduction. This paper analyzes in-depth the performance to eliminate the useless paths using this CNN Encoder model. To measure the mentioned model efficiency, we combined it with different path planning algorithms. Next, the final algorithms (combined and not combined) are checked in a database that is composed of five scenarios. Each scenario contains fixed and dynamic obstacles. Their proposed model, the CNN Encoder, associated to other existent path planning algorithms in the literature, was able to obtain a time decrease to find the shortest path in comparison to all path planning algorithms analyzed. the average decreased time was 54.43 %.
Moody Learners -- Explaining Competitive Behaviour of Reinforcement Learning Agents
Jul 30, 2020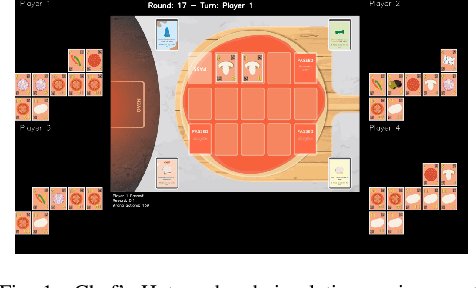
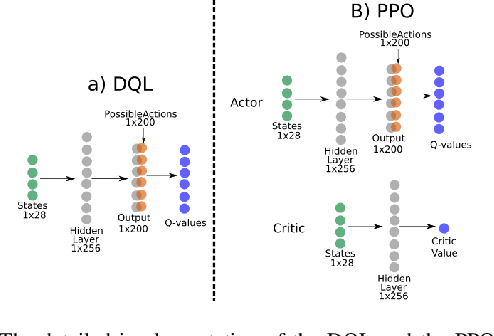
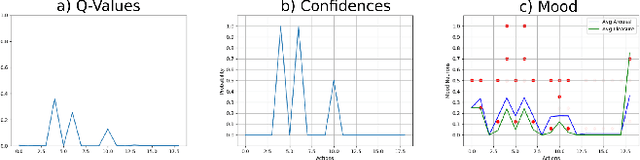
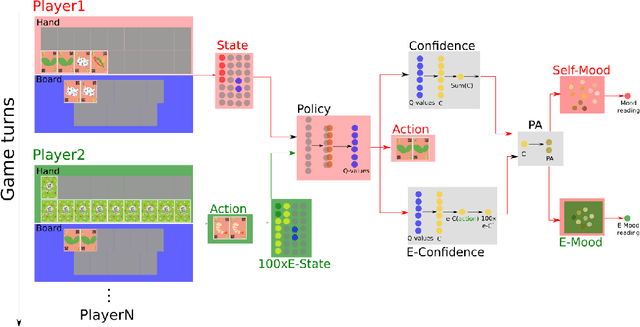
Designing the decision-making processes of artificial agents that are involved in competitive interactions is a challenging task. In a competitive scenario, the agent does not only have a dynamic environment but also is directly affected by the opponents' actions. Observing the Q-values of the agent is usually a way of explaining its behavior, however, do not show the temporal-relation between the selected actions. We address this problem by proposing the \emph{Moody framework}. We evaluate our model by performing a series of experiments using the competitive multiplayer Chef's Hat card game and discuss how our model allows the agents' to obtain a holistic representation of the competitive dynamics within the game.
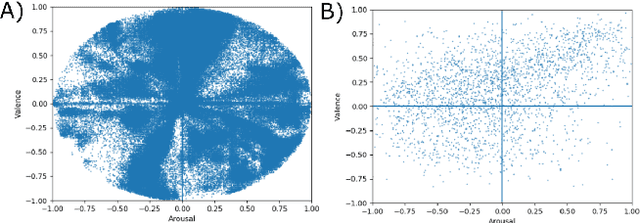
Facial Expression Editing with Continuous Emotion Labels
Jun 22, 2020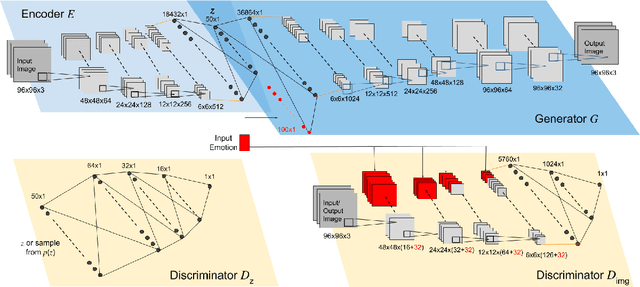



Recently deep generative models have achieved impressive results in the field of automated facial expression editing. However, the approaches presented so far presume a discrete representation of human emotions and are therefore limited in the modelling of non-discrete emotional expressions. To overcome this limitation, we explore how continuous emotion representations can be used to control automated expression editing. We propose a deep generative model that can be used to manipulate facial expressions in facial images according to continuous two-dimensional emotion labels. One dimension represents an emotion's valence, the other represents its degree of arousal. We demonstrate the functionality of our model with a quantitative analysis using classifier networks as well as with a qualitative analysis.
The FaceChannel: A Light-weight Deep Neural Network for Facial Expression Recognition
Apr 17, 2020

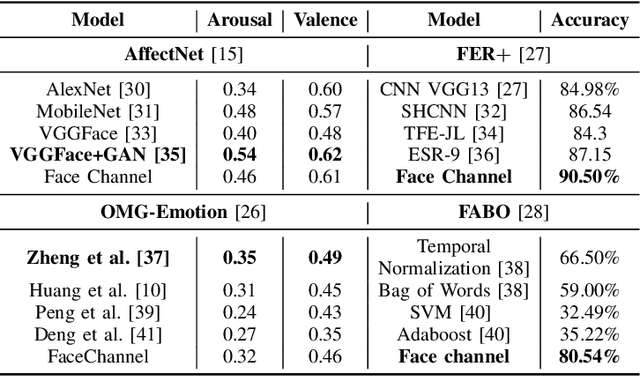
Current state-of-the-art models for automatic FER are based on very deep neural networks that are difficult to train. This makes it challenging to adapt these models to changing conditions, a requirement from FER models given the subjective nature of affect perception and understanding. In this paper, we address this problem by formalizing the FaceChannel, a light-weight neural network that has much fewer parameters than common deep neural networks. We perform a series of experiments on different benchmark datasets to demonstrate how the FaceChannel achieves a comparable, if not better, performance, as compared to the current state-of-the-art in FER.
CNN Encoder to Reduce the Dimensionality of Data Image for Motion Planning
Apr 10, 2020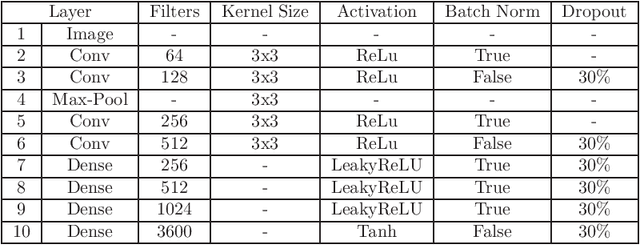
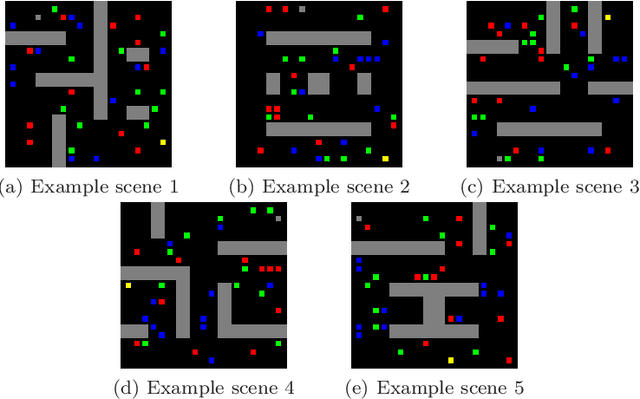
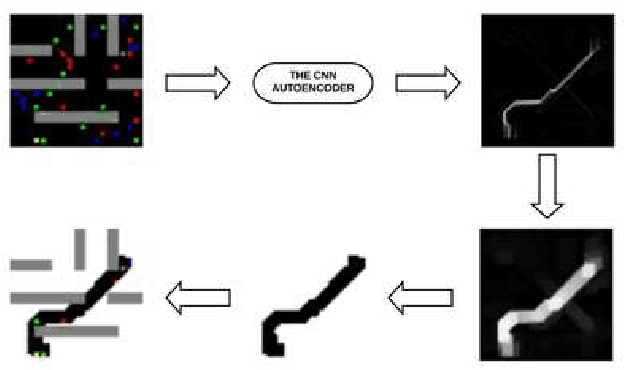
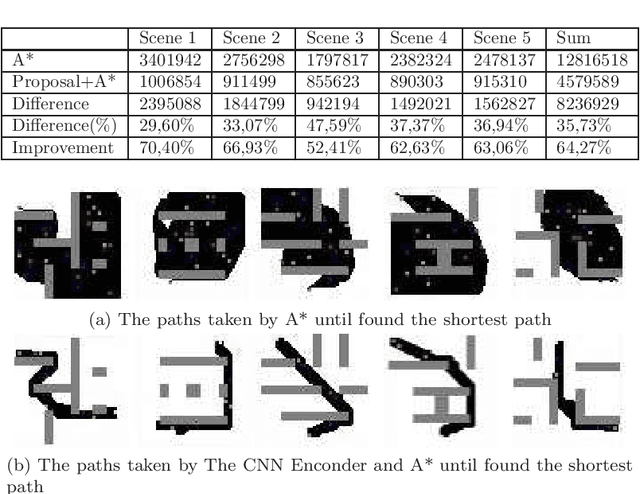
Many real-world applications need path planning algorithms to solve tasks in different areas, such as social applications, autonomous cars, and tracking activities. And most importantly motion planning. Although the use of path planning is sufficient in most motion planning scenarios, they represent potential bottlenecks in large environments with dynamic changes. To tackle this problem, the number of possible routes could be reduced to make it easier for path planning algorithms to find the shortest path with less efforts. An traditional algorithm for path planning is the A*, it uses an heuristic to work faster than other solutions. In this work, we propose a CNN encoder capable of eliminating useless routes for motion planning problems, then we combine the proposed neural network output with A*. To measure the efficiency of our solution, we propose a database with different scenarios of motion planning problems. The evaluated metric is the number of the iterations to find the shortest path. The A* was compared with the CNN Encoder (proposal) with A*. In all evaluated scenarios, our solution reduced the number of iterations by more than 60\%.