 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMNet: Fully Convolutional Model for Fast Segmentation of Anatomical Structures in Ultrasound Volumes
Jan 21, 2019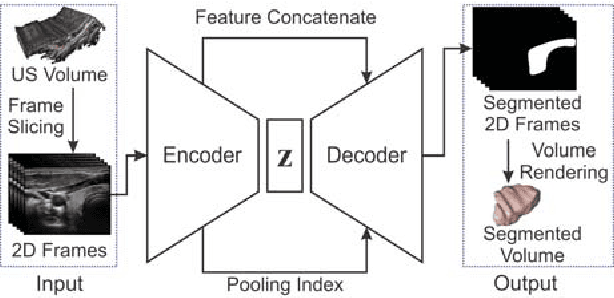

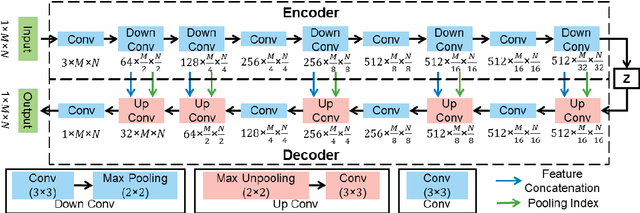
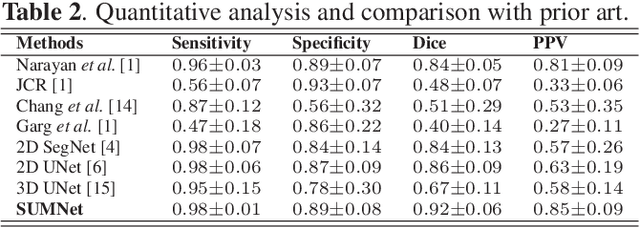
Ultrasound imaging is generally employed for real-time investigation of internal anatomy of the human body for disease identification. Delineation of the anatomical boundary of organs and pathological lesions is quite challenging due to the stochastic nature of speckle intensity in the images, which also introduces visual fatigue for the observer. This paper introduces a fully convolutional neural network based method to segment organ and pathologies in ultrasound volume by learning the spatial-relationship between closely related classes in the presence of stochastically varying speckle intensity. We propose a convolutional encoder-decoder like framework with (i) feature concatenation across matched layers in encoder and decoder and (ii) index passing based unpooling at the decoder for semantic segmentation of ultrasound volumes. We have experimentally evaluated the performance on publicly available datasets consisting of $10$ intravascular ultrasound pullback acquired at $20$ MHz and $16$ freehand thyroid ultrasound volumes acquired $11 - 16$ MHz. We have obtained a dice score of $0.93 \pm 0.08$ and $0.92 \pm 0.06$ respectively, following a $10$-fold cross-validation experiment while processing frame of $256 \times 384$ pixel in $0.035$s and a volume of $256 \times 384 \times 384$ voxel in $13.44$s.
UltraCompression: Framework for High Density Compression of Ultrasound Volumes using Physics Modeling Deep Neural Networks
Jan 17, 2019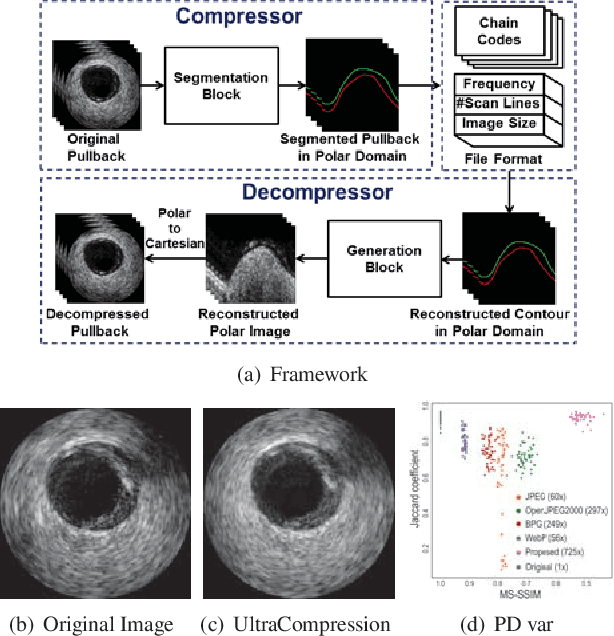
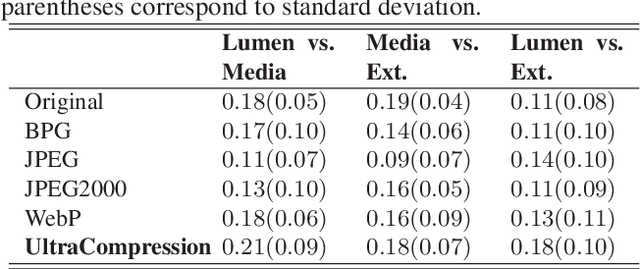
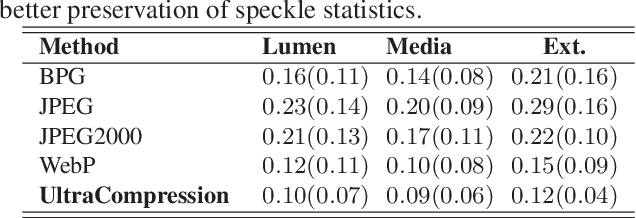

Ultrasound image compression by preserving speckle-based key information is a challenging task. In this paper, we introduce an ultrasound image compression framework with the ability to retain realism of speckle appearance despite achieving very high-density compression factors. The compressor employs a tissue segmentation method, transmitting segments along with transducer frequency, number of samples and image size as essential information required for decompression. The decompressor is based on a convolutional network trained to generate patho-realistic ultrasound images which convey essential information pertinent to tissue pathology visible in the images. We demonstrate generalizability of the building blocks using two variants to build the compressor. We have evaluated the quality of decompressed images using distortion losses as well as perception loss and compared it with other off the shelf solutions. The proposed method achieves a compression ratio of $725:1$ while preserving the statistical distribution of speckles. This enables image segmentation on decompressed images to achieve dice score of $0.89 \pm 0.11$, which evidently is not so accurately achievable when images are compressed with current standards like JPEG, JPEG 2000, WebP and BPG. We envision this frame work to serve as a roadmap for speckle image compression standards.
Visual Attention for Behavioral Cloning in Autonomous Driving
Dec 05, 2018The goal of our work is to use visual attention to enhance autonomous driving performance. We present two methods of predicting visual attention maps. The first method is a supervised learning approach in which we collect eye-gaze data for the task of driving and use this to train a model for predicting the attention map. The second method is a novel unsupervised approach where we train a model to learn to predict attention as it learns to drive a car. Finally, we present a comparative study of our results and show that the supervised approach for predicting attention when incorporated performs better than other approaches.
Improving Consistency and Correctness of Sequence Inpainting using Semantically Guided Generative Adversarial Network
Nov 17, 2017
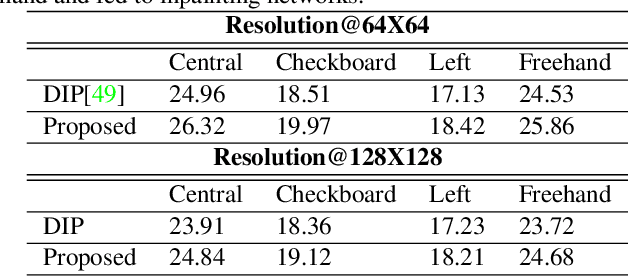
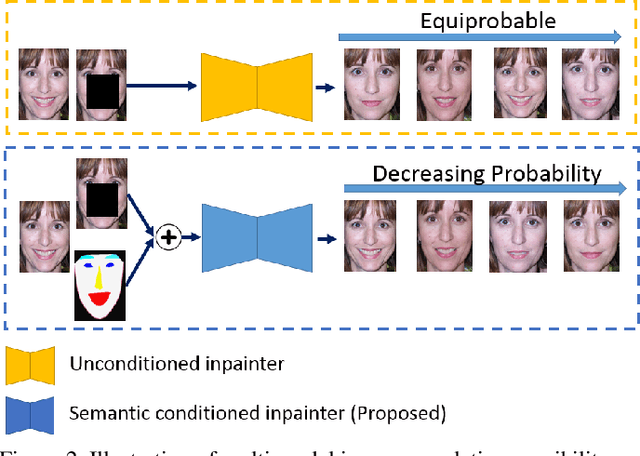

Contemporary benchmark methods for image inpainting are based on deep generative models and specifically leverage adversarial loss for yielding realistic reconstructions. However, these models cannot be directly applied on image/video sequences because of an intrinsic drawback- the reconstructions might be independently realistic, but, when visualized as a sequence, often lacks fidelity to the original uncorrupted sequence. The fundamental reason is that these methods try to find the best matching latent space representation near to natural image manifold without any explicit distance based loss. In this paper, we present a semantically conditioned Generative Adversarial Network (GAN) for sequence inpainting. The conditional information constrains the GAN to map a latent representation to a point in image manifold respecting the underlying pose and semantics of the scene. To the best of our knowledge, this is the first work which simultaneously addresses consistency and correctness of generative model based inpainting. We show that our generative model learns to disentangle pose and appearance information; this independence is exploited by our model to generate highly consistent reconstructions. The conditional information also aids the generator network in GAN to produce sharper images compared to the original GAN formulation. This helps in achieving more appealing inpainting performance. Though generic, our algorithm was targeted for inpainting on faces. When applied on CelebA and Youtube Faces datasets, the proposed method results in a significant improvement over the current benchmark, both in terms of quantitative evaluation (Peak Signal to Noise Ratio) and human visual scoring over diversified combinations of resolutions and deformations.
Recurrent Memory Addressing for describing videos
Mar 23, 2017
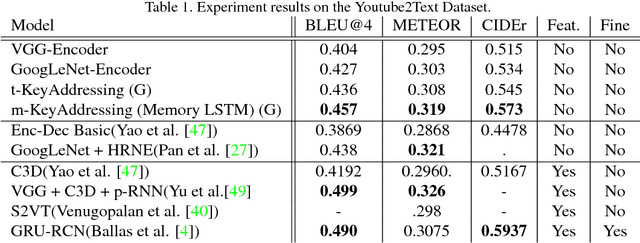
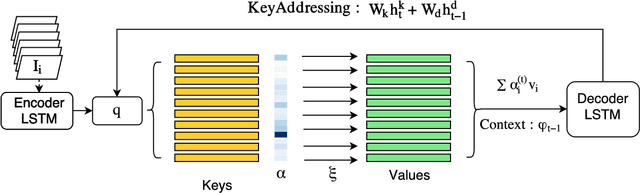
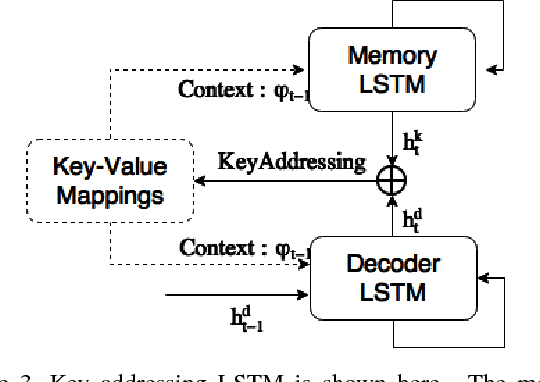
In this paper, we introduce Key-Value Memory Networks to a multimodal setting and a novel key-addressing mechanism to deal with sequence-to-sequence models. The proposed model naturally decomposes the problem of video captioning into vision and language segments, dealing with them as key-value pairs. More specifically, we learn a semantic embedding (v) corresponding to each frame (k) in the video, thereby creating (k, v) memory slots. We propose to find the next step attention weights conditioned on the previous attention distributions for the key-value memory slots in the memory addressing schema. Exploiting this flexibility of the framework, we additionally capture spatial dependencies while mapping from the visual to semantic embedding. Experiments done on the Youtube2Text dataset demonstrate usefulness of recurrent key-addressing, while achieving competitive scores on BLEU@4, METEOR metrics against state-of-the-art models.
Visualization Regularizers for Neural Network based Image Recognition
Jan 03, 2017
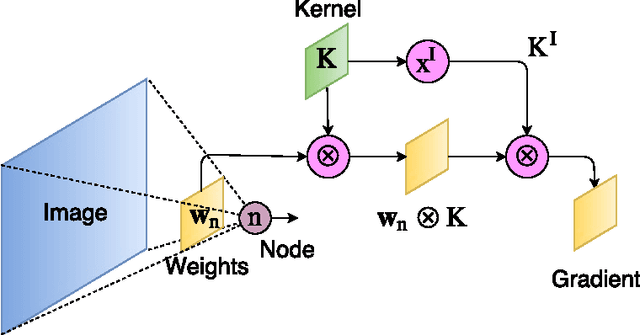

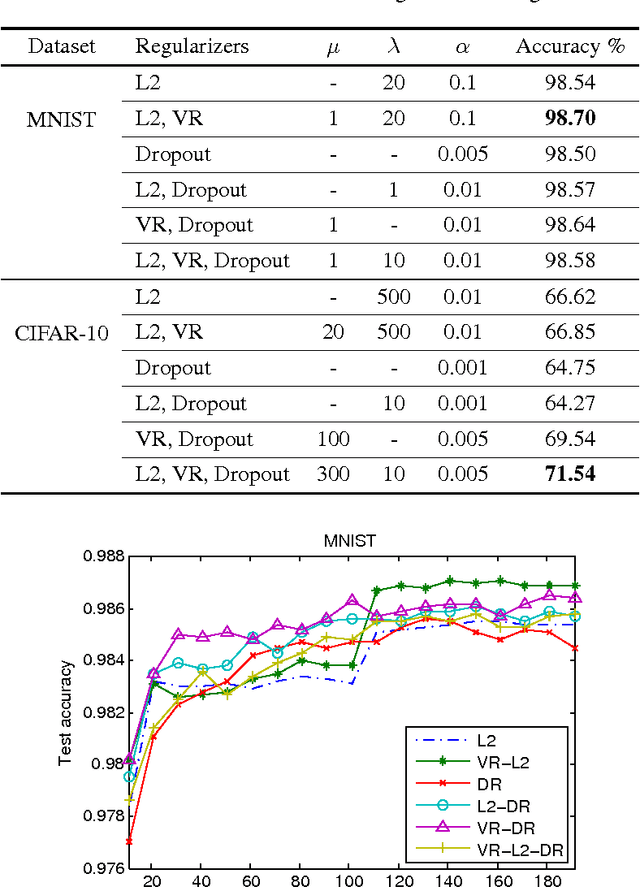
The success of deep neural networks is mostly due their ability to learn meaningful features from the data. Features learned in the hidden layers of deep neural networks trained in computer vision tasks have been shown to be similar to mid-level vision features. We leverage this fact in this work and propose the visualization regularizer for image tasks. The proposed regularization technique enforces smoothness of the features learned by hidden nodes and turns out to be a special case of Tikhonov regularization. We achieve higher classification accuracy as compared to existing regularizers such as the L2 norm regularizer and dropout, on benchmark datasets without changing the training computational complexity.
BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification
Dec 02, 2016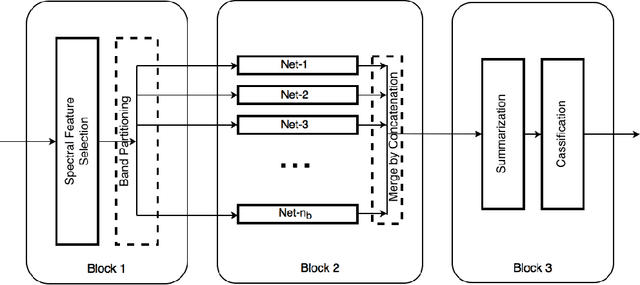
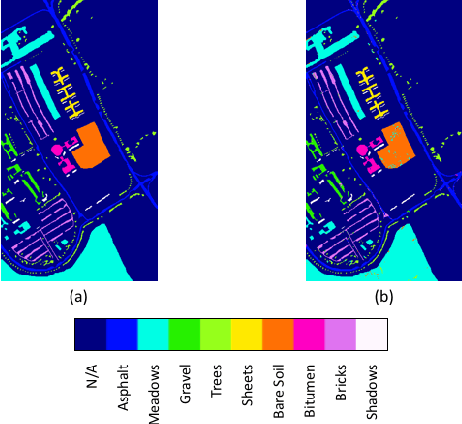
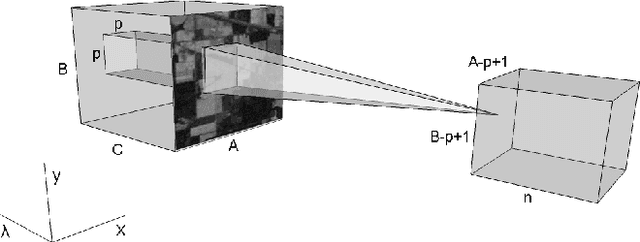
Deep learning based landcover classification algorithms have recently been proposed in literature. In hyperspectral images (HSI) they face the challenges of large dimensionality, spatial variability of spectral signatures and scarcity of labeled data. In this article we propose an end-to-end deep learning architecture that extracts band specific spectral-spatial features and performs landcover classification. The architecture has fewer independent connection weights and thus requires lesser number of training data. The method is found to outperform the highest reported accuracies on popular hyperspectral image data sets.
WEPSAM: Weakly Pre-Learnt Saliency Model
May 03, 2016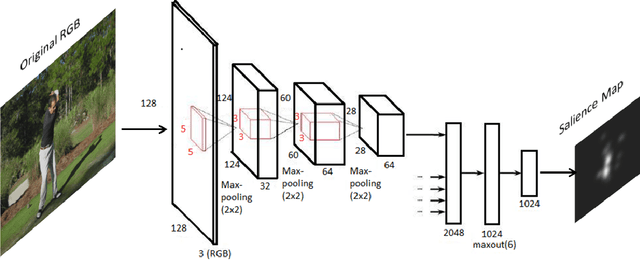
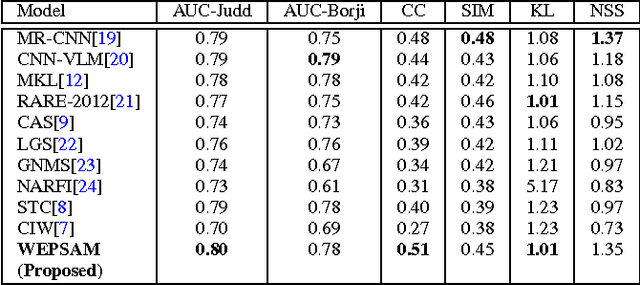
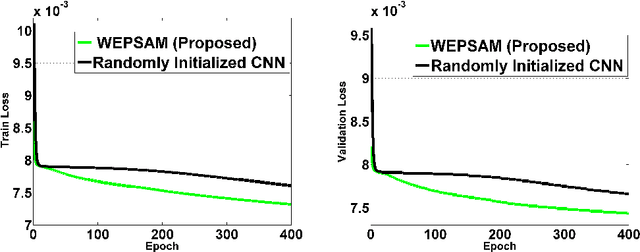
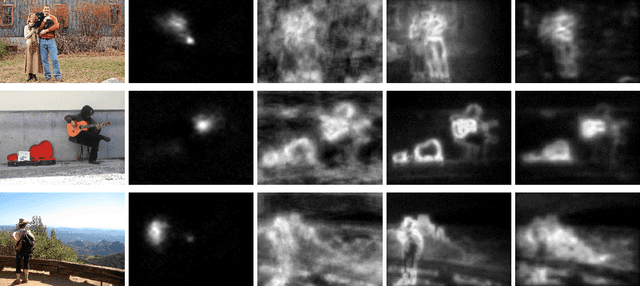
Visual saliency detection tries to mimic human vision psychology which concentrates on sparse, important areas in natural image. Saliency prediction research has been traditionally based on low level features such as contrast, edge, etc. Recent thrust in saliency prediction research is to learn high level semantics using ground truth eye fixation datasets. In this paper we present, WEPSAM : Weakly Pre-Learnt Saliency Model as a pioneering effort of using domain specific pre-learing on ImageNet for saliency prediction using a light weight CNN architecture. The paper proposes a two step hierarchical learning, in which the first step is to develop a framework for weakly pre-training on a large scale dataset such as ImageNet which is void of human eye fixation maps. The second step refines the pre-trained model on a limited set of ground truth fixations. Analysis of loss on iSUN and SALICON datasets reveal that pre-trained network converges much faster compared to randomly initialized network. WEPSAM also outperforms some recent state-of-the-art saliency prediction models on the challenging MIT300 dataset.
Visual saliency detection: a Kalman filter based approach
Apr 17, 2016

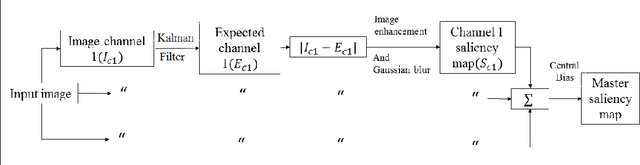
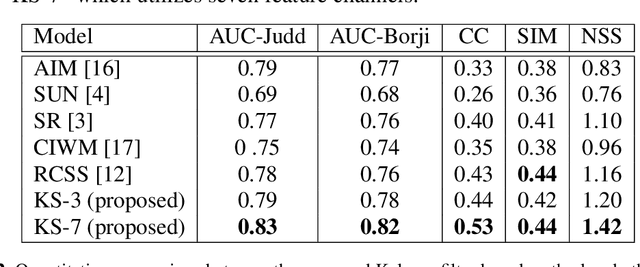
In this paper we propose a Kalman filter aided saliency detection model which is based on the conjecture that salient regions are considerably different from our "visual expectation" or they are "visually surprising" in nature. In this work, we have structured our model with an immediate objective to predict saliency in static images. However, the proposed model can be easily extended for space-time saliency prediction. Our approach was evaluated using two publicly available benchmark data sets and results have been compared with other existing saliency models. The results clearly illustrate the superior performance of the proposed model over other approaches.
Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images
Mar 15, 2016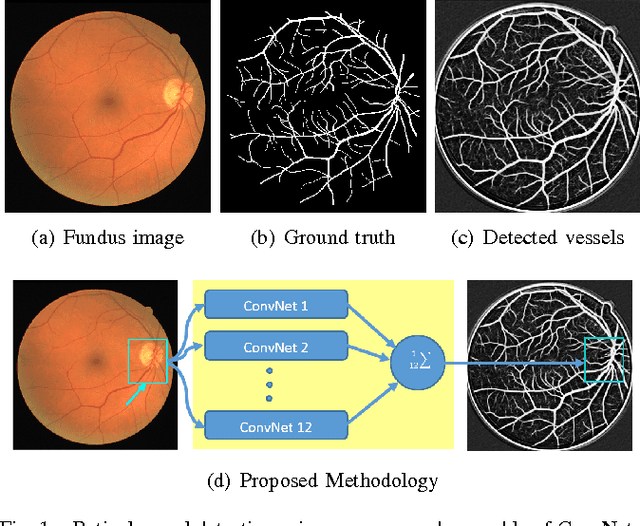
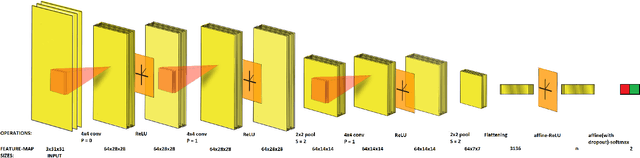
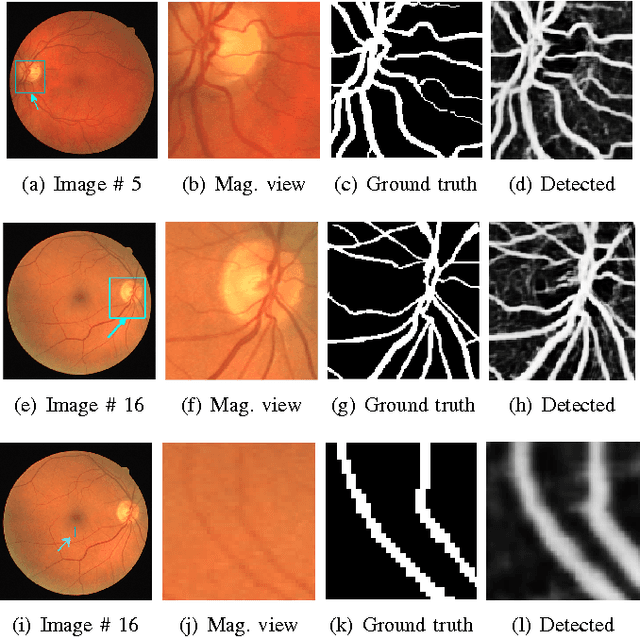
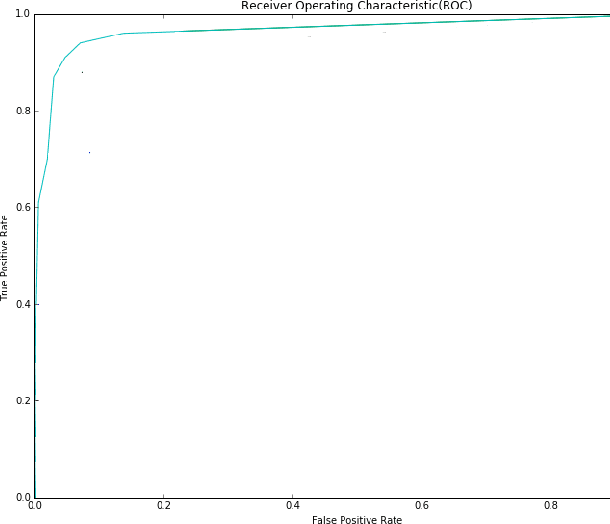
Vision impairment due to pathological damage of the retina can largely be prevented through periodic screening using fundus color imaging. However the challenge with large scale screening is the inability to exhaustively detect fine blood vessels crucial to disease diagnosis. In this work we present a computational imaging framework using deep and ensemble learning for reliable detection of blood vessels in fundus color images. An ensemble of deep convolutional neural networks is trained to segment vessel and non-vessel areas of a color fundus image. During inference, the responses of the individual ConvNets of the ensemble are averaged to form the final segmentation. In experimental evaluation with the DRIVE database, we achieve the objective of vessel detection with maximum average accuracy of 94.7\% and area under ROC curve of 0.9283.