 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOM: Learning Policy-Aware Models for Model-Based Reinforcement Learning via Transition Occupancy Matching
May 22, 2023Standard model-based reinforcement learning (MBRL) approaches fit a transition model of the environment to all past experience, but this wastes model capacity on data that is irrelevant for policy improvement. We instead propose a new "transition occupancy matching" (TOM) objective for MBRL model learning: a model is good to the extent that the current policy experiences the same distribution of transitions inside the model as in the real environment. We derive TOM directly from a novel lower bound on the standard reinforcement learning objective. To optimize TOM, we show how to reduce it to a form of importance weighted maximum-likelihood estimation, where the automatically computed importance weights identify policy-relevant past experiences from a replay buffer, enabling stable optimization. TOM thus offers a plug-and-play model learning sub-routine that is compatible with any backbone MBRL algorithm. On various Mujoco continuous robotic control tasks, we show that TOM successfully focuses model learning on policy-relevant experience and drives policies faster to higher task rewards than alternative model learning approaches.
PAC Prediction Sets for Large Language Models of Code
Feb 17, 2023Prediction sets have recently been shown to be a promising strategy for quantifying the uncertainty of deep neural networks in a way that provides theoretical guarantees. However, existing techniques have largely targeted settings where the space of labels is simple, so prediction sets can be arbitrary subsets of labels. For structured prediction problems where the space of labels is exponential in size, even prediction sets containing a small fraction of all labels can be exponentially large. In the context of code generation, we propose a solution that considers a restricted set of prediction sets that can compactly be represented as partial programs, which are programs with portions replaced with holes. Given a trained code generation model, our algorithm leverages a programming language's abstract syntax tree to generate a set of programs such that the correct program is in the set with high-confidence. Valuable applications of our algorithm include a Codex-style code generator with holes in uncertain parts of the generated code, which provides a partial program with theoretical guarantees. We evaluate our approach on PICARD (a T5 model for SQL semantic parsing) and Codex (a GPT model for over a dozen programming languages, including Python), demonstrating that our approach generates compact PAC prediction sets. This is the first research contribution that generates PAC prediction sets for generative code models.
Robust Subtask Learning for Compositional Generalization
Feb 06, 2023Compositional reinforcement learning is a promising approach for training policies to perform complex long-horizon tasks. Typically, a high-level task is decomposed into a sequence of subtasks and a separate policy is trained to perform each subtask. In this paper, we focus on the problem of training subtask policies in a way that they can be used to perform any task; here, a task is given by a sequence of subtasks. We aim to maximize the worst-case performance over all tasks as opposed to the average-case performance. We formulate the problem as a two agent zero-sum game in which the adversary picks the sequence of subtasks. We propose two RL algorithms to solve this game: one is an adaptation of existing multi-agent RL algorithms to our setting and the other is an asynchronous version which enables parallel training of subtask policies. We evaluate our approach on two multi-task environments with continuous states and actions and demonstrate that our algorithms outperform state-of-the-art baselines.
SPARLING: Learning Latent Representations with Extremely Sparse Activations
Feb 03, 2023Real-world processes often contain intermediate state that can be modeled as an extremely sparse tensor. We introduce Sparling, a new kind of informational bottleneck that explicitly models this state by enforcing extreme activation sparsity. We additionally demonstrate that this technique can be used to learn the true intermediate representation with no additional supervision (i.e., from only end-to-end labeled examples), and thus improve the interpretability of the resulting models. On our DigitCircle domain, we are able to get an intermediate state prediction accuracy of 98.84%, even as we only train end-to-end.
ACon$^2$: Adaptive Conformal Consensus for Provable Blockchain Oracles
Nov 17, 2022



Blockchains with smart contracts are distributed ledger systems which achieve block state consistency among distributed nodes by only allowing deterministic operations of smart contracts. However, the power of smart contracts is enabled by interacting with stochastic off-chain data, which in turn opens the possibility to undermine the block state consistency. To address this issue, an oracle smart contract is used to provide a single consistent source of external data; but, simultaneously this introduces a single point of failure, which is called the oracle problem. To address the oracle problem, we propose an adaptive conformal consensus (ACon$^2$) algorithm, which derives consensus from multiple oracle contracts via the recent advance in online uncertainty quantification learning. In particular, the proposed algorithm returns a consensus set, which quantifies the uncertainty of data and achieves a desired correctness guarantee in the presence of Byzantine adversaries and distribution shift. We demonstrate the efficacy of the proposed algorithm on two price datasets and an Ethereum case study. In particular, the Solidity implementation of the proposed algorithm shows the practicality of the proposed algorithm, implying that online machine learning algorithms are applicable to address issues in blockchains.
Decision-Aware Learning for Optimizing Health Supply Chains
Nov 15, 2022



We study the problem of allocating limited supply of medical resources in developing countries, in particular, Sierra Leone. We address this problem by combining machine learning (to predict demand) with optimization (to optimize allocations). A key challenge is the need to align the loss function used to train the machine learning model with the decision loss associated with the downstream optimization problem. Traditional solutions have limited flexibility in the model architecture and scale poorly to large datasets. We propose a decision-aware learning algorithm that uses a novel Taylor expansion of the optimal decision loss to derive the machine learning loss. Importantly, our approach only requires a simple re-weighting of the training data, ensuring it is both flexible and scalable, e.g., we incorporate it into a random forest trained using a multitask learning framework. We apply our framework to optimize the distribution of essential medicines in collaboration with policymakers in Sierra Leone; highly uncertain demand and limited budgets currently result in excessive unmet demand. Out-of-sample results demonstrate that our end-to-end approach can significantly reduce unmet demand across 1040 health facilities throughout Sierra Leone.
Bandits for Online Calibration: An Application to Content Moderation on Social Media Platforms
Nov 11, 2022


We describe the current content moderation strategy employed by Meta to remove policy-violating content from its platforms. Meta relies on both handcrafted and learned risk models to flag potentially violating content for human review. Our approach aggregates these risk models into a single ranking score, calibrating them to prioritize more reliable risk models. A key challenge is that violation trends change over time, affecting which risk models are most reliable. Our system additionally handles production challenges such as changing risk models and novel risk models. We use a contextual bandit to update the calibration in response to such trends. Our approach increases Meta's top-line metric for measuring the effectiveness of its content moderation strategy by 13%.
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Sep 30, 2022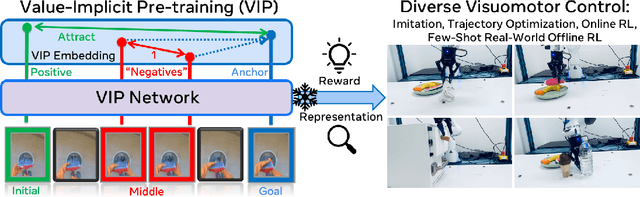

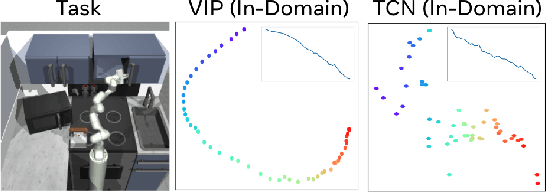
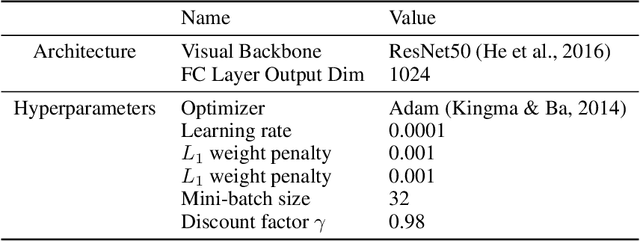
Reward and representation learning are two long-standing challenges for learning an expanding set of robot manipulation skills from sensory observations. Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question. We introduce $\textbf{V}$alue-$\textbf{I}$mplicit $\textbf{P}$re-training (VIP), a self-supervised pre-trained visual representation capable of generating dense and smooth reward functions for unseen robotic tasks. VIP casts representation learning from human videos as an offline goal-conditioned reinforcement learning problem and derives a self-supervised dual goal-conditioned value-function objective that does not depend on actions, enabling pre-training on unlabeled human videos. Theoretically, VIP can be understood as a novel implicit time contrastive objective that generates a temporally smooth embedding, enabling the value function to be implicitly defined via the embedding distance, which can then be used to construct the reward for any goal-image specified downstream task. Trained on large-scale Ego4D human videos and without any fine-tuning on in-domain, task-specific data, VIP's frozen representation can provide dense visual reward for an extensive set of simulated and $\textbf{real-robot}$ tasks, enabling diverse reward-based visual control methods and significantly outperforming all prior pre-trained representations. Notably, VIP can enable simple, $\textbf{few-shot}$ offline RL on a suite of real-world robot tasks with as few as 20 trajectories.
PAC Prediction Sets for Meta-Learning
Jul 06, 2022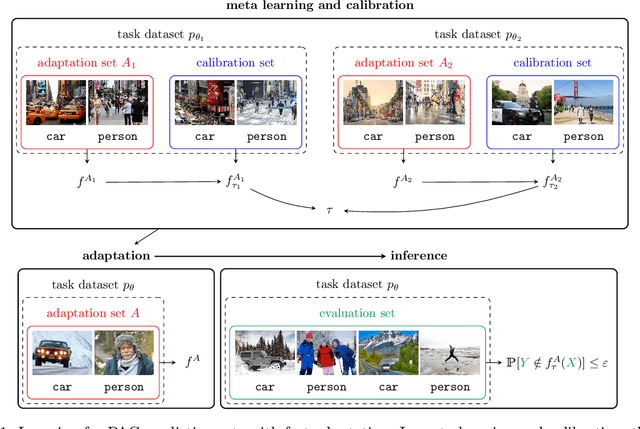
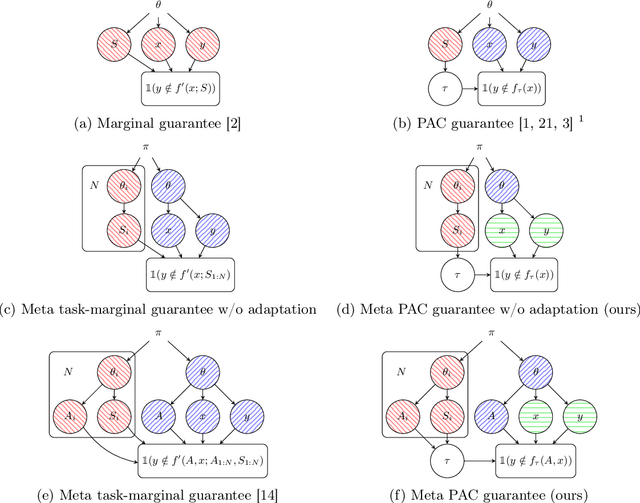
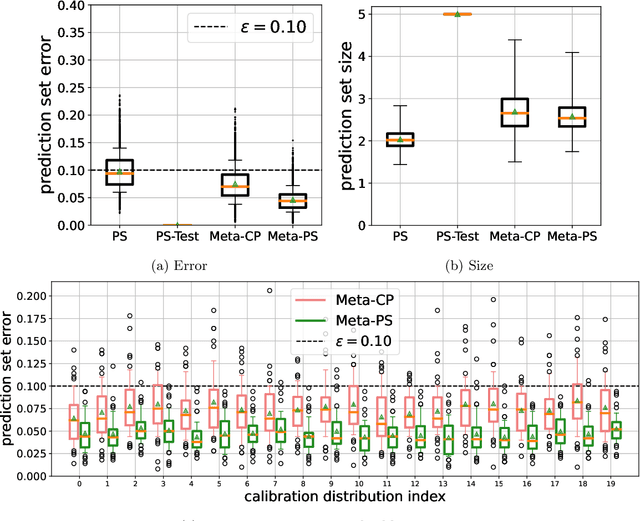
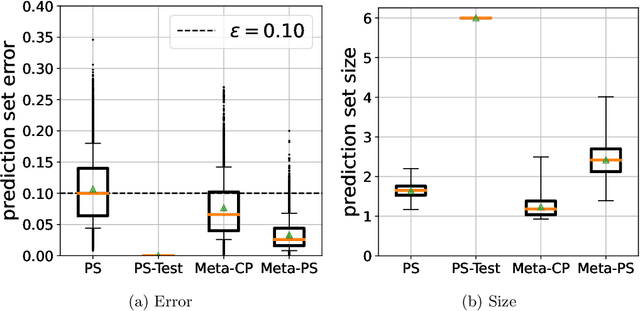
Uncertainty quantification is a key component of machine learning models targeted at safety-critical systems such as in healthcare or autonomous vehicles. We study this problem in the context of meta learning, where the goal is to quickly adapt a predictor to new tasks. In particular, we propose a novel algorithm to construct \emph{PAC prediction sets}, which capture uncertainty via sets of labels, that can be adapted to new tasks with only a few training examples. These prediction sets satisfy an extension of the typical PAC guarantee to the meta learning setting; in particular, the PAC guarantee holds with high probability over future tasks. We demonstrate the efficacy of our approach on four datasets across three application domains: mini-ImageNet and CIFAR10-C in the visual domain, FewRel in the language domain, and the CDC Heart Dataset in the medical domain. In particular, our prediction sets satisfy the PAC guarantee while having smaller size compared to other baselines that also satisfy this guarantee.
How Far I'll Go: Offline Goal-Conditioned Reinforcement Learning via $f$-Advantage Regression
Jun 07, 2022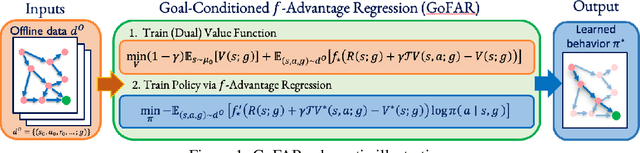
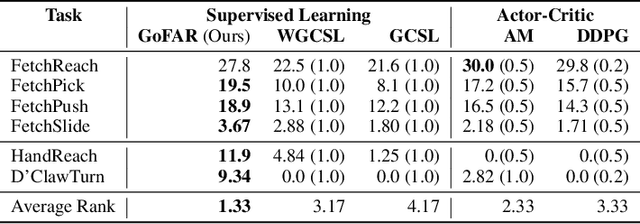

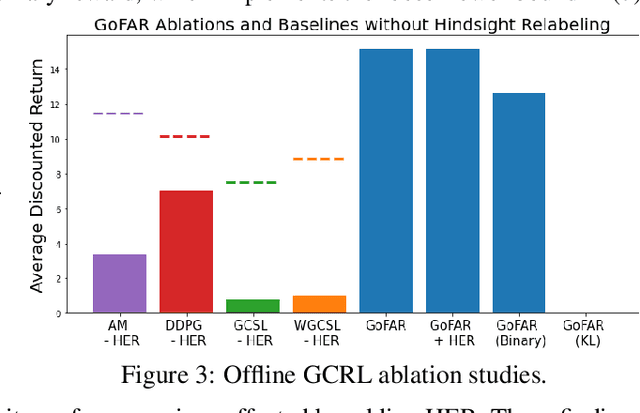
Offline goal-conditioned reinforcement learning (GCRL) promises general-purpose skill learning in the form of reaching diverse goals from purely offline datasets. We propose $\textbf{Go}$al-conditioned $f$-$\textbf{A}$dvantage $\textbf{R}$egression (GoFAR), a novel regression-based offline GCRL algorithm derived from a state-occupancy matching perspective; the key intuition is that the goal-reaching task can be formulated as a state-occupancy matching problem between a dynamics-abiding imitator agent and an expert agent that directly teleports to the goal. In contrast to prior approaches, GoFAR does not require any hindsight relabeling and enjoys uninterleaved optimization for its value and policy networks. These distinct features confer GoFAR with much better offline performance and stability as well as statistical performance guarantee that is unattainable for prior methods. Furthermore, we demonstrate that GoFAR's training objectives can be re-purposed to learn an agent-independent goal-conditioned planner from purely offline source-domain data, which enables zero-shot transfer to new target domains. Through extensive experiments, we validate GoFAR's effectiveness in various problem settings and tasks, significantly outperforming prior state-of-art. Notably, on a real robotic dexterous manipulation task, while no other method makes meaningful progress, GoFAR acquires complex manipulation behavior that successfully accomplishes diverse goals.