 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Graph Neural Networks
Jun 11, 2020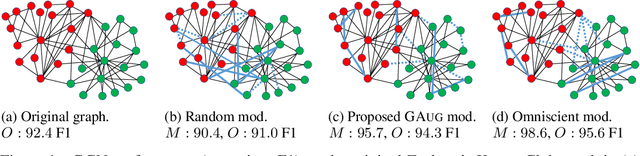
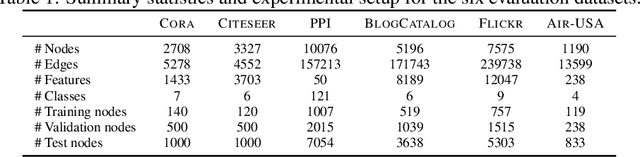
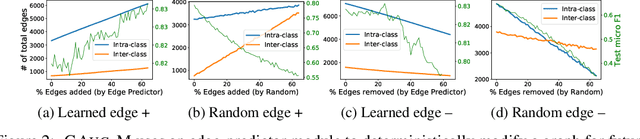
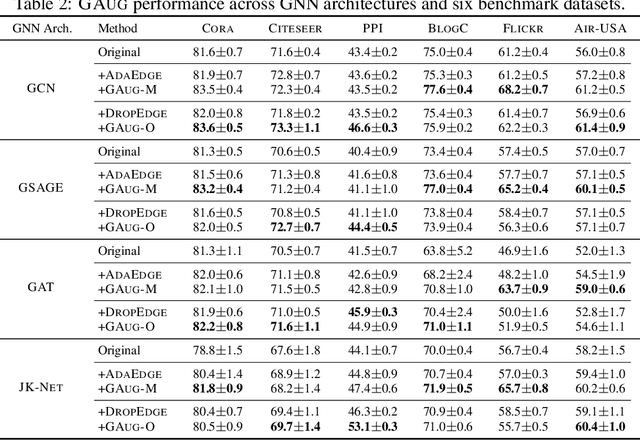
Data augmentation has been widely used to improve generalizability of machine learning models. However, comparatively little work studies data augmentation for graphs. This is largely due to the complex, non-Euclidean structure of graphs, which limits possible manipulation operations. Augmentation operations commonly used in vision and language have no analogs for graphs. Our work studies graph data augmentation for graph neural networks (GNNs) in the context of improving semi-supervised node-classification. We discuss practical and theoretical motivations, considerations and strategies for graph data augmentation. Our work shows that neural edge predictors can effectively encode class-homophilic structure to promote intra-class edges and demote inter-class edges in given graph structure, and our main contribution introduces the GAug graph data augmentation framework, which leverages these insights to improve performance in GNN-based node classification via edge prediction. Extensive experiments on multiple benchmarks show that augmentation via GAug improves performance across GNN architectures and datasets.
Transformable Bottleneck Networks
Apr 23, 2019
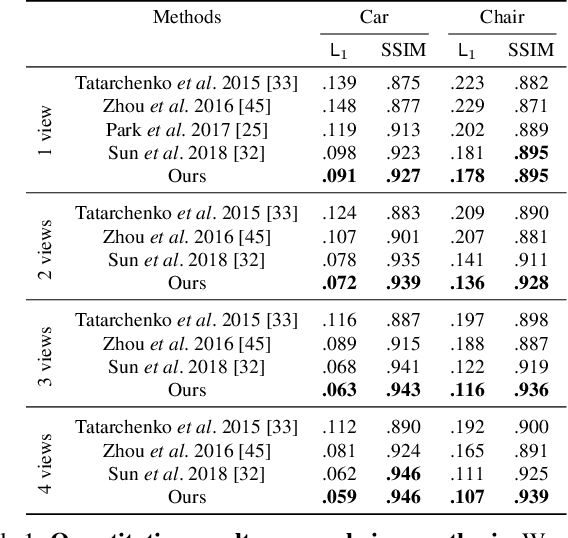
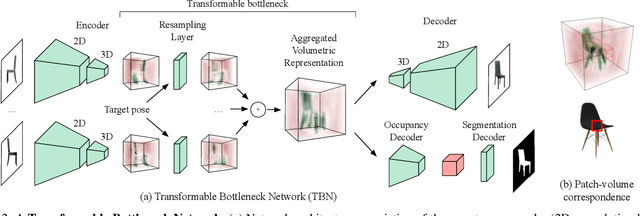
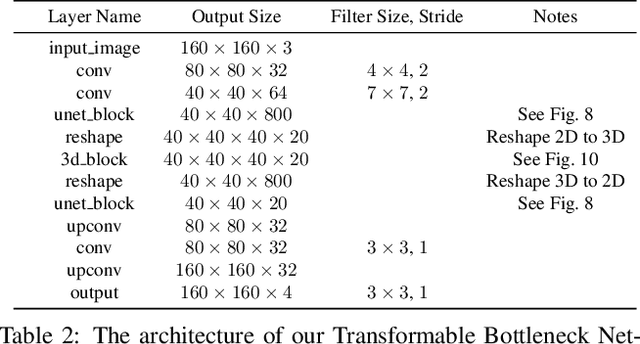
We propose a novel approach to performing fine-grained 3D manipulation of image content via a convolutional neural network, which we call the Transformable Bottleneck Network (TBN). It applies given spatial transformations directly to a volumetric bottleneck within our encoder-bottleneck-decoder architecture. Multi-view supervision encourages the network to learn to spatially disentangle the feature space within the bottleneck. The resulting spatial structure can be manipulated with arbitrary spatial transformations. We demonstrate the efficacy of TBNs for novel view synthesis, achieving state-of-the-art results on a challenging benchmark. We demonstrate that the bottlenecks produced by networks trained for this task contain meaningful spatial structure that allows us to intuitively perform a variety of image manipulations in 3D, well beyond the rigid transformations seen during training. These manipulations include non-uniform scaling, non-rigid warping, and combining content from different images. Finally, we extract explicit 3D structure from the bottleneck, performing impressive 3D reconstruction from a single input image.