 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of lyrics lines conditioned on music audio clips
Sep 30, 2020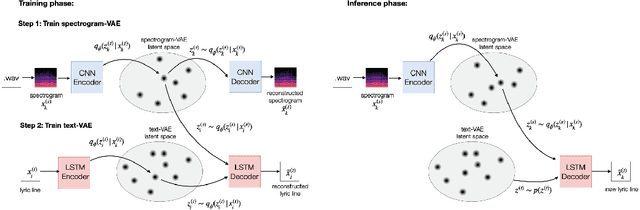
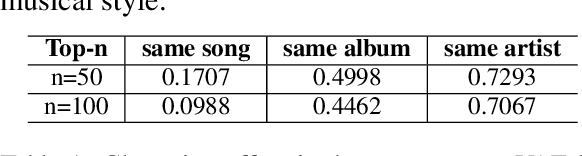
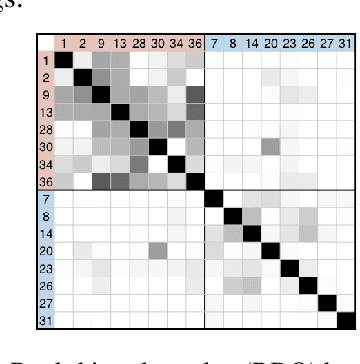
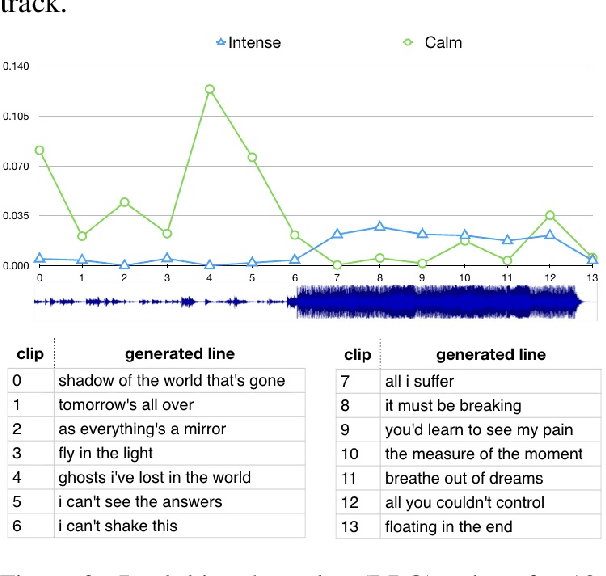
We present a system for generating novel lyrics lines conditioned on music audio. A bimodal neural network model learns to generate lines conditioned on any given short audio clip. The model consists of a spectrogram variational autoencoder (VAE) and a text VAE. Both automatic and human evaluations demonstrate effectiveness of our model in generating lines that have an emotional impact matching a given audio clip. The system is intended to serve as a creativity tool for songwriters.
Iterative Edit-Based Unsupervised Sentence Simplification
Jun 17, 2020
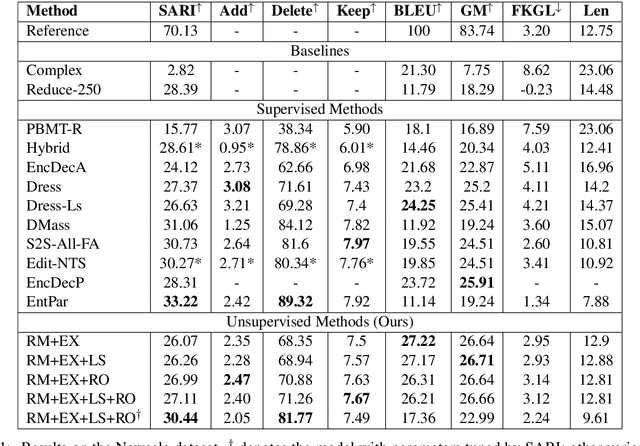
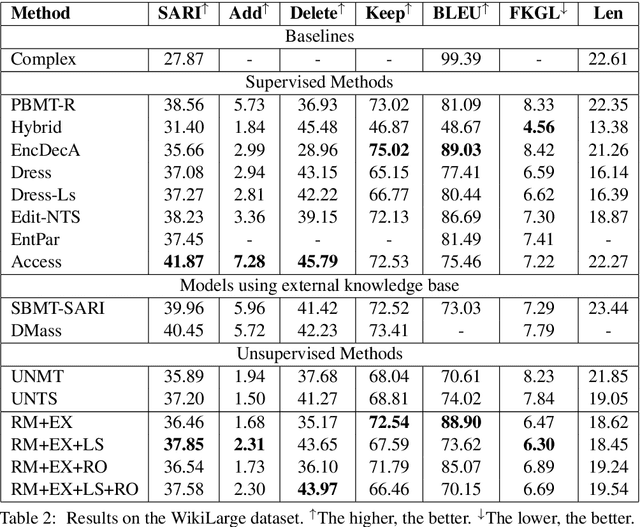
We present a novel iterative, edit-based approach to unsupervised sentence simplification. Our model is guided by a scoring function involving fluency, simplicity, and meaning preservation. Then, we iteratively perform word and phrase-level edits on the complex sentence. Compared with previous approaches, our model does not require a parallel training set, but is more controllable and interpretable. Experiments on Newsela and WikiLarge datasets show that our approach is nearly as effective as state-of-the-art supervised approaches.
Discrete Optimization for Unsupervised Sentence Summarization with Word-Level Extraction
May 04, 2020
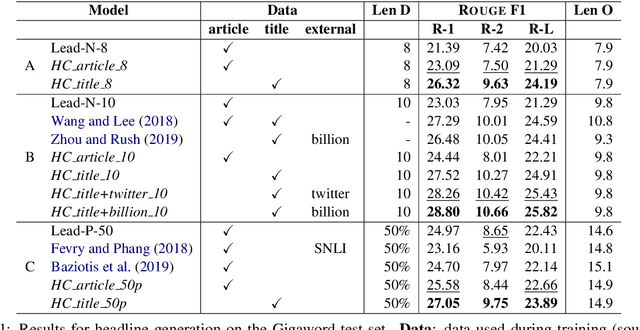
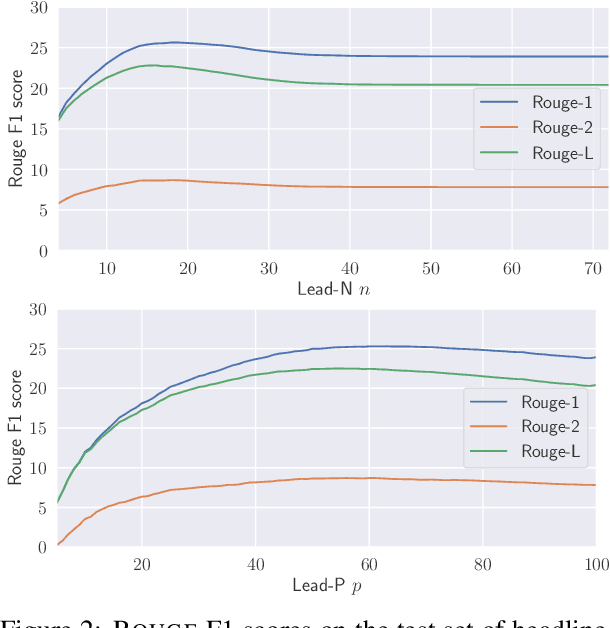
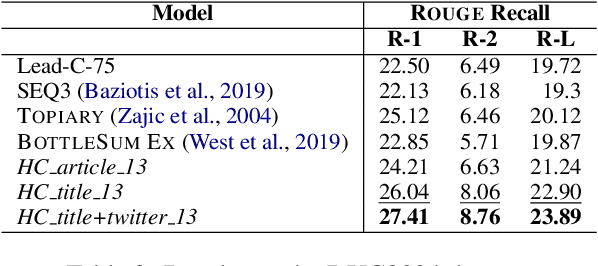
Automatic sentence summarization produces a shorter version of a sentence, while preserving its most important information. A good summary is characterized by language fluency and high information overlap with the source sentence. We model these two aspects in an unsupervised objective function, consisting of language modeling and semantic similarity metrics. We search for a high-scoring summary by discrete optimization. Our proposed method achieves a new state-of-the art for unsupervised sentence summarization according to ROUGE scores. Additionally, we demonstrate that the commonly reported ROUGE F1 metric is sensitive to summary length. Since this is unwillingly exploited in recent work, we emphasize that future evaluation should explicitly group summarization systems by output length brackets.
Polarized-VAE: Proximity Based Disentangled Representation Learning for Text Generation
Apr 22, 2020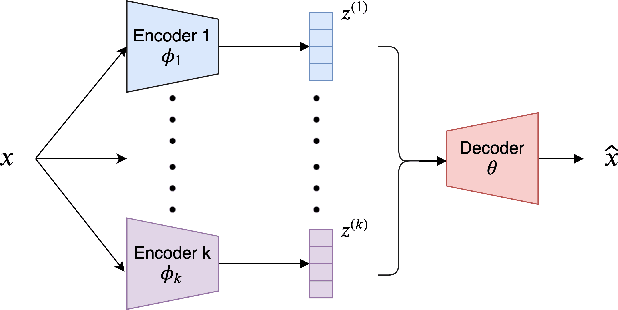
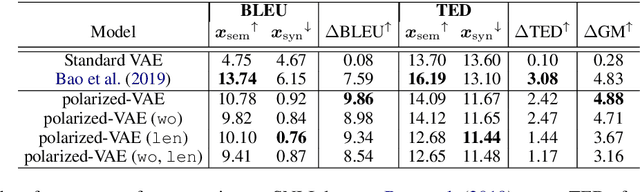
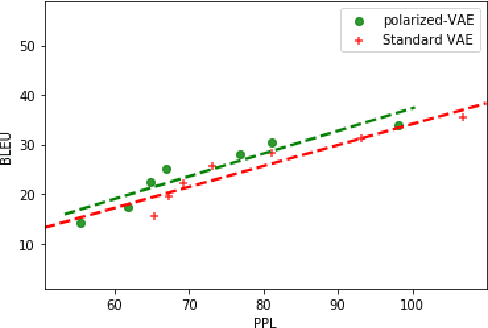

Learning disentangled representations of real world data is a challenging open problem. Most previous methods have focused on either fully supervised approaches which use attribute labels or unsupervised approaches that manipulate the factorization in the latent space of models such as the variational autoencoder (VAE), by training with task-specific losses. In this work we propose polarized-VAE, a novel approach that disentangles selected attributes in the latent space based on proximity measures reflecting the similarity between data points with respect to these attributes. We apply our method to disentangle the semantics and syntax of a sentence and carry out transfer experiments. Polarized-VAE significantly outperforms the VAE baseline and is competitive with the state-of-the-art approaches, while being more a general framework that is applicable to other attribute disentanglement tasks.
Stylized Text Generation Using Wasserstein Autoencoders with a Mixture of Gaussian Prior
Nov 10, 2019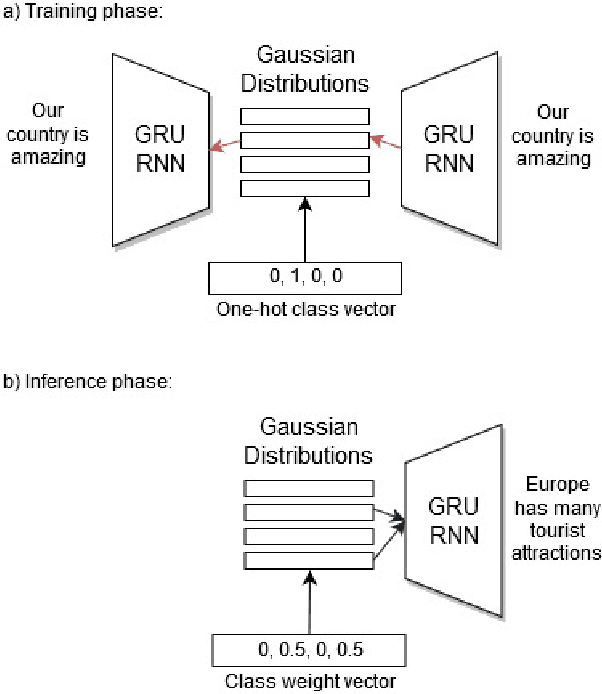
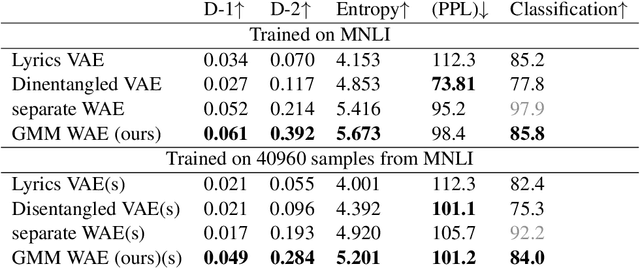

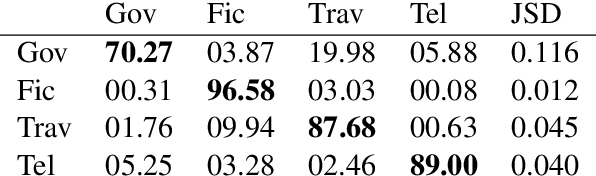
Wasserstein autoencoders are effective for text generation. They do not however provide any control over the style and topic of the generated sentences if the dataset has multiple classes and includes different topics. In this work, we present a semi-supervised approach for generating stylized sentences. Our model is trained on a multi-class dataset and learns the latent representation of the sentences using a mixture of Gaussian prior without any adversarial losses. This allows us to generate sentences in the style of a specified class or multiple classes by sampling from their corresponding prior distributions. Moreover, we can train our model on relatively small datasets and learn the latent representation of a specified class by adding external data with other styles/classes to our dataset. While a simple WAE or VAE cannot generate diverse sentences in this case, generated sentences with our approach are diverse, fluent, and preserve the style and the content of the desired classes.
Dynamic Fusion for Multimodal Data
Nov 10, 2019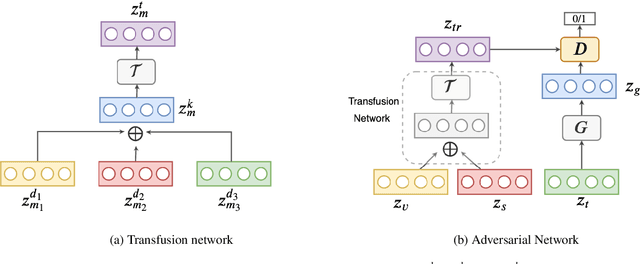
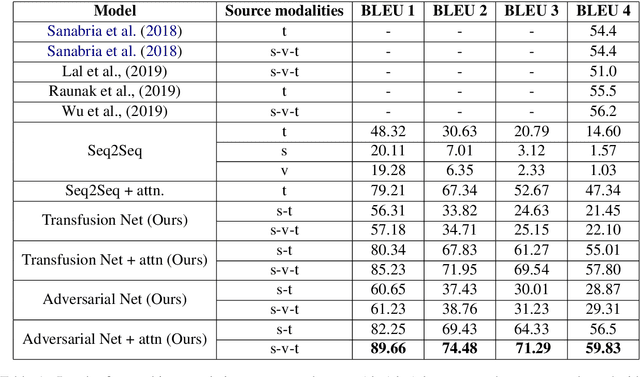
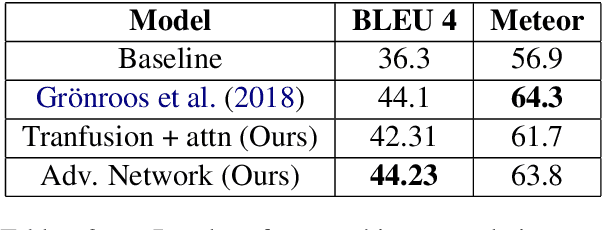
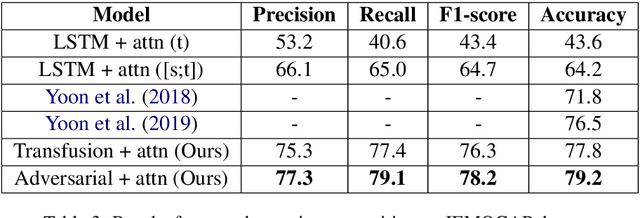
Effective fusion of data from multiple modalities, such as video, speech, and text, is challenging pertaining to the heterogeneous nature of multimodal data. In this paper, we propose dynamic fusion techniques that model context from different modalities efficiently. Instead of defining a deterministic fusion operation, such as concatenation, for the network, we let the network decide "how" to combine given multimodal features in the most optimal way. We propose two networks: 1) transfusion network, which learns to compress information from different modalities while preserving the context, and 2) a GAN-based network, which regularizes the learned latent space given context from complimenting modalities. A quantitative evaluation on the tasks of machine translation, and emotion recognition suggest that such adaptive networks are able to model context better than all existing methods.
Conditional Response Generation Using Variational Alignment
Nov 10, 2019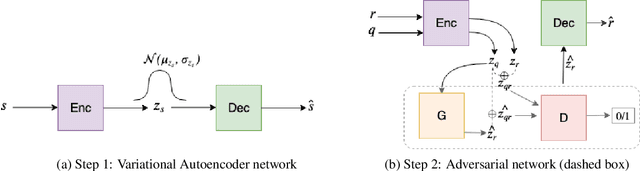
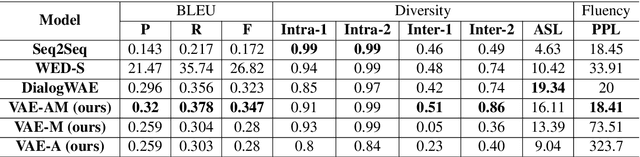
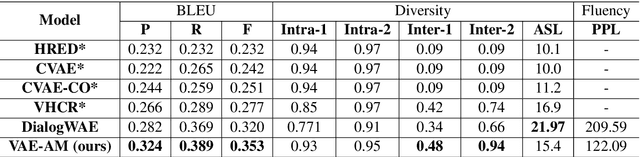
Generating relevant/conditioned responses in dialog is challenging, and requires not only proper modelling of context in the conversation, but also the ability to generate fluent sentences during inference. In this paper, we propose a two-step framework based on generative adversarial nets for generating conditioned responses. Our model first learns meaningful representations of sentences, and then uses a generator to \textit{match} the query with the response distribution. Latent codes from the latter are then used to generate responses. Both quantitative and qualitative evaluations show that our model generates more fluent, relevant and diverse responses than the existing state-of-the-art methods.
Generating Sentences from Disentangled Syntactic and Semantic Spaces
Jul 06, 2019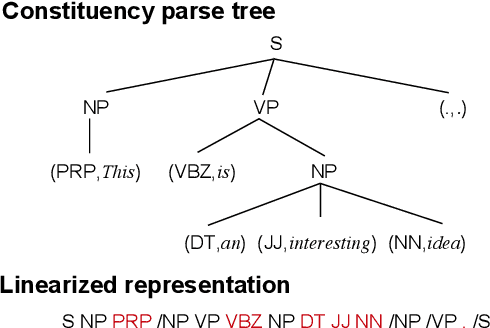
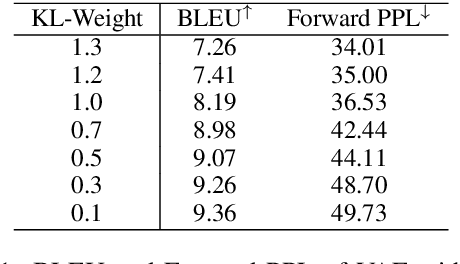
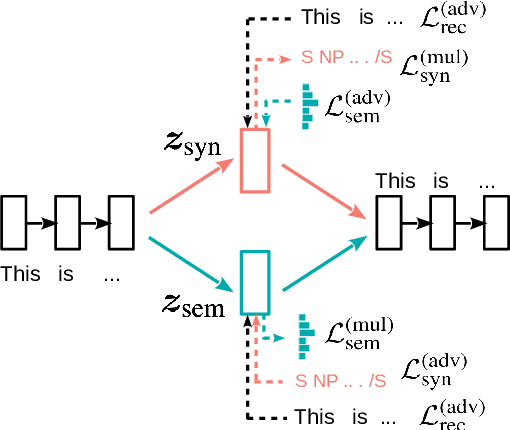
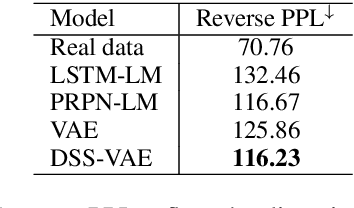
Variational auto-encoders (VAEs) are widely used in natural language generation due to the regularization of the latent space. However, generating sentences from the continuous latent space does not explicitly model the syntactic information. In this paper, we propose to generate sentences from disentangled syntactic and semantic spaces. Our proposed method explicitly models syntactic information in the VAE's latent space by using the linearized tree sequence, leading to better performance of language generation. Additionally, the advantage of sampling in the disentangled syntactic and semantic latent spaces enables us to perform novel applications, such as the unsupervised paraphrase generation and syntax-transfer generation. Experimental results show that our proposed model achieves similar or better performance in various tasks, compared with state-of-the-art related work.
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
Mar 28, 2019
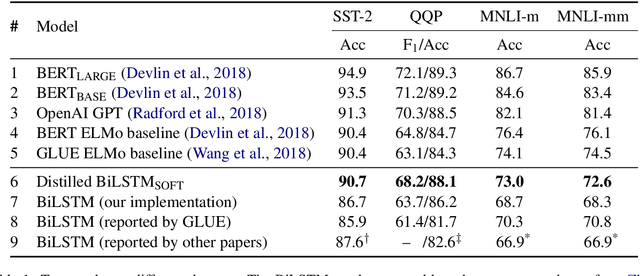
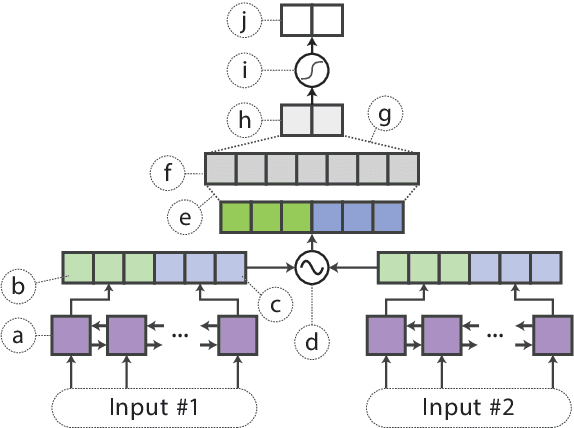
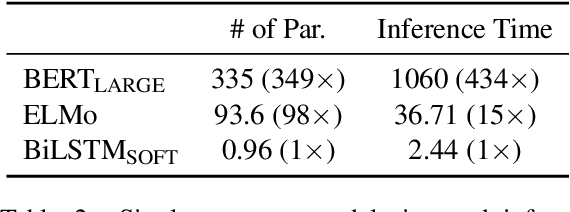
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent poster child of this trend is the deep language representation model, which includes BERT, ELMo, and GPT. These developments have led to the conviction that previous-generation, shallower neural networks for language understanding are obsolete. In this paper, however, we demonstrate that rudimentary, lightweight neural networks can still be made competitive without architecture changes, external training data, or additional input features. We propose to distill knowledge from BERT, a state-of-the-art language representation model, into a single-layer BiLSTM, as well as its siamese counterpart for sentence-pair tasks. Across multiple datasets in paraphrasing, natural language inference, and sentiment classification, we achieve comparable results with ELMo, while using roughly 100 times fewer parameters and 15 times less inference time.
Generating lyrics with variational autoencoder and multi-modal artist embeddings
Dec 20, 2018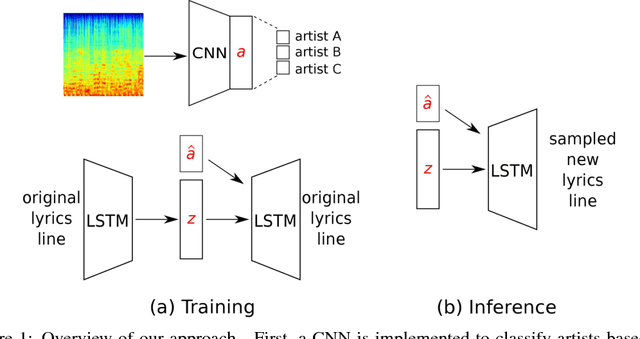
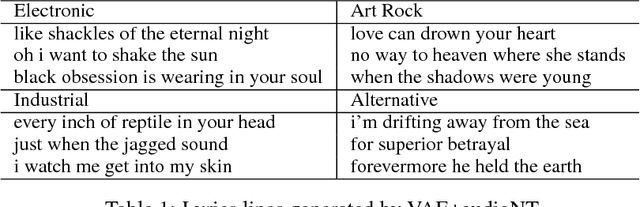
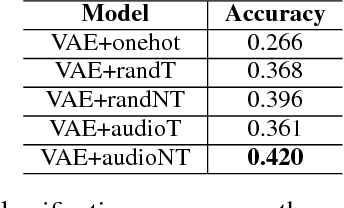
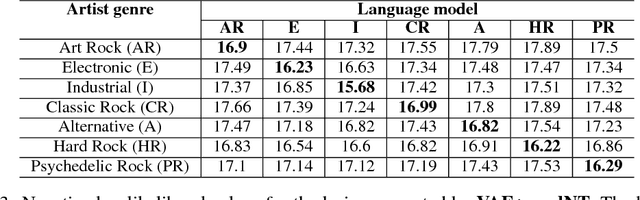
We present a system for generating song lyrics lines conditioned on the style of a specified artist. The system uses a variational autoencoder with artist embeddings. We propose the pre-training of artist embeddings with the representations learned by a CNN classifier, which is trained to predict artists based on MEL spectrograms of their song clips. This work is the first step towards combining audio and text modalities of songs for generating lyrics conditioned on the artist's style. Our preliminary results suggest that there is a benefit in initializing artists' embeddings with the representations learned by a spectrogram classifier.